[강연 리뷰] Multimodal Representation Learning: How to Narrow Heterogeneity gap (1)
강연링크: [DMQA Open Seminar] Multimodal Representation Learning
1. Modality 개념과 Multimodal Model 의 중요성
멀티모달에 대해 공부하기 전 우선 모달리티(Modality) 의 개념부터 알아보자. 모달리티란 정보를 인코딩하는 양식이라고 할 수 있다. 이미지, 비디오, 텍스트, 오디오는 서로 다른 형식으로 존재하지만 모두 정보를 담고 있다. 이렇게 정보를 담고 있는 양식을 모달리티라고 한다.
그렇다면 Unimodal Model과 Multimodal Model의 차이는 무엇일까? 두 가지 개념의 정의는 아래와 같다.
-
Unimodal Model: 하나의 모달리티만 활용하여 풀고자 하는 문제를 해결하는 모델
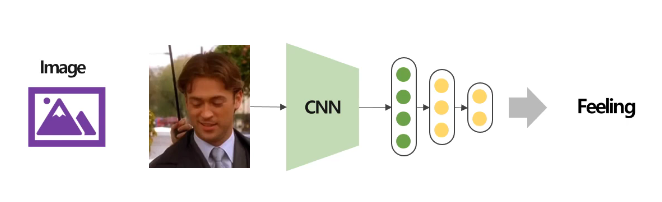
이렇게 이미지만을 가지고 감정을 판단하는 모델이나,
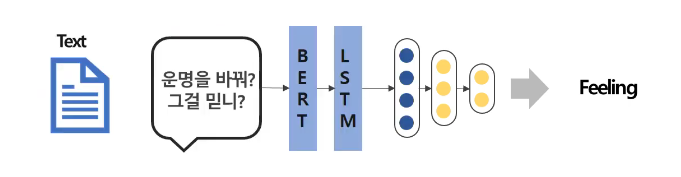
위와 같이 주어진 텍스트만을 가지고 감정을 판단하는 모델을 Unimodal Model이라고 할 수 있다. -
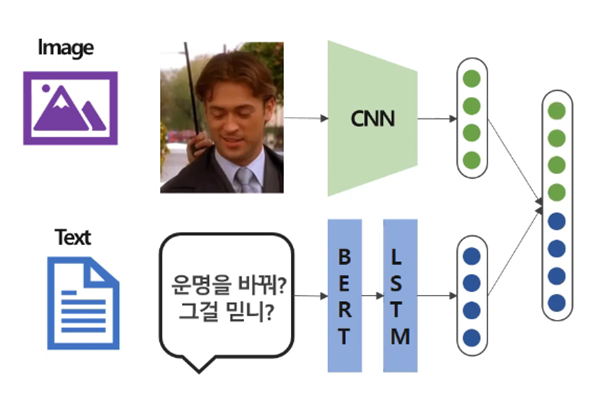
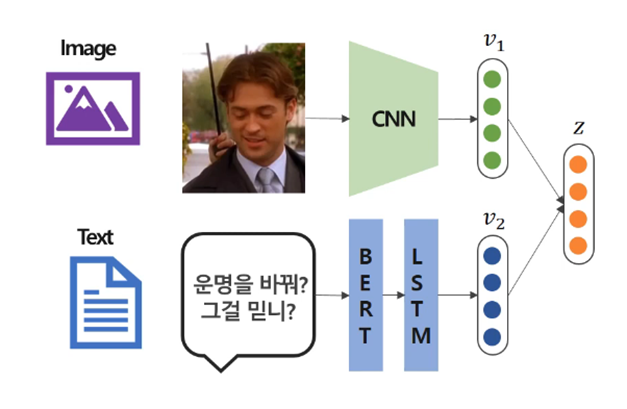
Multimodal Model: 두 개 이상의 모달리티를 활용하여 풀고자 하는 문제를 해결하는 모델는 모델
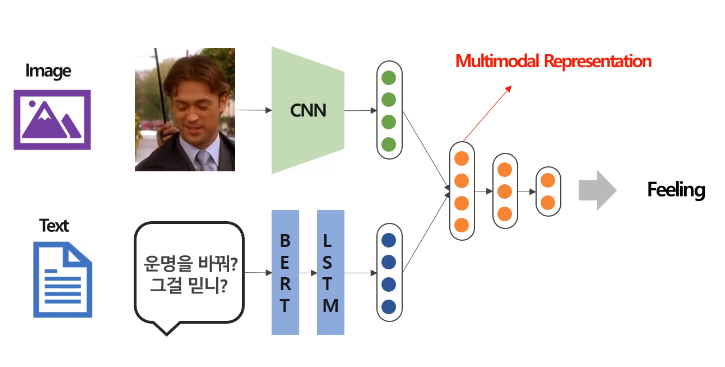
위 그림은 멀티모달 모델을 표현한다. 이미지와 텍스트를 모두 입력으로 받아 두 모달리티의 정보를 고려해서 판단을 하는 모델이다. 이때, 여러 모달리티 정보가 결합되어있는 Representation Vector를 Multimodal Representation이라고 한다.
우리는 오감을 활용하여 세상의 정보를 받아들인다. 예를 들어, 실수해서 엄마에게 '아이고, 잘~ 한다!' 라는 말을 들었다고 하자. '아이고, 잘 한다.' 라는 텍스트만을 통해 감정을 추론한다면, 단일 모달리티 AI는 '칭찬을 받는 상황'이라고 해석할 것이다. 하지만 사람들은 엄마의 말투(예: '잘~'을 길게 늘이는 말투)나 표정을 보고, 이 말이 칭찬이 아니라는 것을 알 수 있다. 이처럼 멀티모달 모델은 마치 인간이 세상을 받아들이는 방식과 비슷하다. 따라서 멀티모달 모델은 상호 보완적인 정보를 공유하는 데 유리하며, 더 정확한 특징 추출을 가능하게 한다는 점에서 매우 혁신적이다.
2. Multimodal Representation의 생성
그렇다면 서로 다른 모달리티 데이터를 어떻게 결합할 수 있는가? 이 문제는 꽤나 막막하게 느껴진다. 마치 3 + 5 같이 숫자 도메인 내에서의 계산은 쉽지만, 3 + 고양이처럼 전혀 다른 성질의 데이터를 더하는 방법이 명확하지 않은 것과 비슷하다. 이런 모달리티간의 표현방식 차이(상이함)를 Heterogeneity Gap이라고 한다. 이렇게 Heterogeneity Gap을 가지는 표현방식을 그대로 사용하면 멀티모달 데이터를 포괄적으로 사용하는데 방해가 된다. 따라서 Heterogeneity Gap을 최대한 줄이면서 서로 다른 모달리티를 공통으로 표현하는 양식인 Multimodal Representation을 정의하는 것이 매우 중요하다.
강의에서는 Heterogeneity Gap을 줄이는 세 가지 방법 Joint Representation, Coordinated Representation, Encoder-Decoder를 소개한다.
2.1 Joint Representation
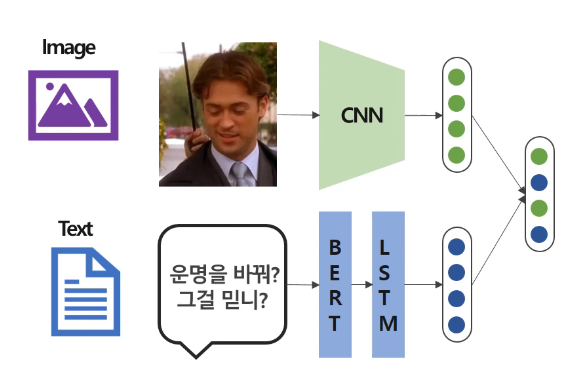
Joint Representation이란 각 모달리티별로 representation을 학습하고, 이를 결합하여 Common Subspace에 하나의 representation으로 매핑하는 방식이다. Concatenate, Additive Approach, Multiplicative Approach가 있다.
- Concatenate
Concatenate 방식은 각 모달리티의 벡터를 단순히 이어 붙여 결합하는 방식이다.
- Additive Approach는 각 모달리티의 가중합을 하나의 벡터로 결합하는 방식이다.
Additive Approach
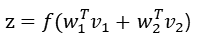
- Multiplicative Approach는 각 모달리티 representation을 외적하여 하나의 벡터로 결합하는 방식이다.
Additive Approach
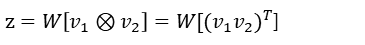
2.1.1 Joint Representation에 관한 연구 소개
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding 논문에서는 이미지와 텍스트이 Joint Representation을 활용한 두 가지 Task를 정의하여 Joint Representation 방식 중 Multiplicative Approach 방식의 장점을 활용하면서, 단점을 개선한 방법론을 제안한다. 정의된 Task 두 가지는 아래와 같다.
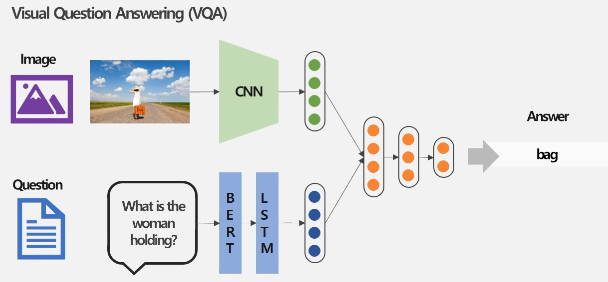
Task 1: Visual Question Answering(VQA)
VQA는 이미지와 이미지에 대한 질문이 주어졌을 때, 해당 질문에 맞는 올바른 답변을 만들어내는 Task이다.
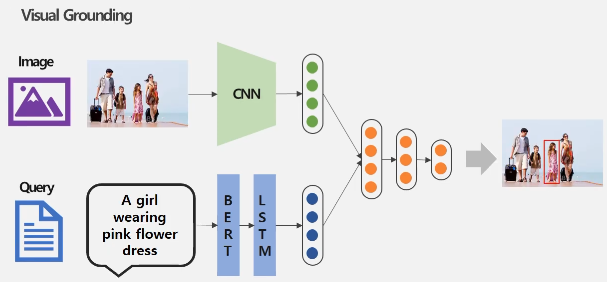
Taks 2: Visual Grounding Task
Visual Grounding은 query가 이미지 내에서 묘사하고 있는 부분을 bounding box로 표시하는 Task이다.
두 가지 Task 모두 이미지와 텍스트 모달리티의 포괄적 정보를 담는 Multimodal Representation 추출히 중요하다. 논문에서는 Joint Representation 방법 중 Multiplicative Approach 방식으로 Multimodal Representation을 생성했다.
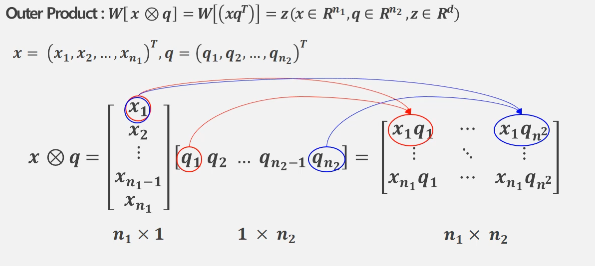
위 그림은 기존의 외적을 이용한 Multiplicative Approach의 계산 과정을 나타낸다. 이 방식은 각 요소가 모두 한 번씩 곱해지기 때문에 모든 요소들간의 상호작용을 가능하게 하는 장점을 갖는다. 하지만 이 방법은 모든 요소를 곱하면서 많은 메모리와 계산 시간을 소비하기 때문에 비효율적이다.

각 모달리티 벡터를 외적하면 n1 × n2 차원의 행렬이 생긴다. 그 후에는 이를 flatten 시킨 벡터를 d 차원의 Representation Vector로 변환하기 위해서 W라는 fully-connected layer가 하나 더 필요하다. 따라서 d × n1 × n2 라는 매우 많은 파라미터를 필요로 한다.

계산 시간 역시 위 수식처럼 매우 많아진다.
2.1.2 Count Sketch Projection을 적용한 Multimodal Compact Bilinear(MCB)
그래서 이 연구는 기존의 Multiplicative Approach를 개선한 Multimodal Compact Bilinear(MCB)를 제안한다. 외적에 Count Sketch Projection Function(Ψ)을 취해 메모리 사용과 계산 시간을 절감하면서 모든 요소를 반영할 수 있다고 한다.

Count Sketch Projection Function(Ψ)에 대해 더 자세히 알아보자.
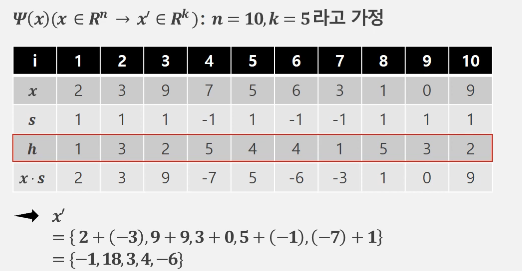
Count Sketch는 해시 함수와 연관된 방식으로 고차원 벡터(n차원)를 저차원 벡터(m차원)로 임베딩(embedding)하는 기법이다. 특정 벡터의 특징을 유지하면서 메모리 사용을 줄이기 위해 데이터를 확률적으로 축약하는데, 랜덤 해시 함수 h와 s를 통해 벡터 값을 축약하는 과정을 따른다. 이때, h: [n] → [m]은 데이터 벡터의 각 차원을 임의의 인덱스로 매핑하는 함수이고, s: [n] → {-1, 1}는 각 차원의 부호를 랜덤하게 결정하는 함수이다.
위 그림은 10차원의 x를 5차원의 x'로 변환하는 과정에 대한 예시이다. 주어진 x와 랜덤하게 결정된 s, h가 있을 때 미리 x·s를 구해 표에 적는다. h[i] = 1인 인덱스의 x·s는 i=1일때의 2와 i=7일때의 -3이므로 x'의 첫 번째 요소는 2+(-3)=-1이다. h[i]가 같은 값을 갖는 인덱스끼리 이런 식으로 계산하면 최종적으로 m차원 (이 예시에서 m=5) 벡터를 얻을 수 있다.
결과적으로 Count Sketch Projection Function을 사용하면 계산 횟수와 파라미터 갯수를 이렇게 효과적으로 줄일 수 있다.


2.1.3 Multimodal Compact Bilinear(MCB)의 실제 Task 적용 과정
2.1.1의 연구는 Count Sketch Projection을 적용하여 Multimodal Representaion을 생성하여 메모리와 계산량을 효과적으로 줄였다. 구체적인 방법은 다음과 같다.
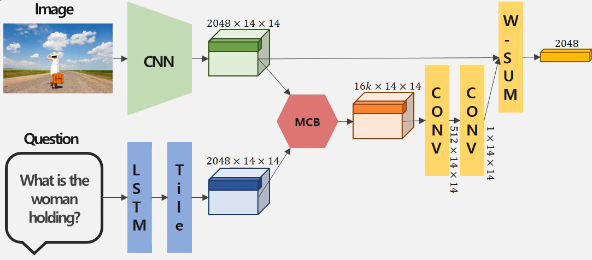
1) 이미지 데이터를 CNN에 통과시켜 2048×14×14 차원의 Representation Vector를 생성한다. 이는 이미지를 14×14 영역으로 분할해서 각 영역을 설명하는 Representation Vector를 생성한 것으로 해석할 수 있다.
2) 질문 데이터는 LSTM에 통과시켜 2048차원의 Representation Vector를 생성하고, 차원을 맞추기 위해 14×14만큼 쌓아준다.
3) 두 representation vector에 Multimodal Compact Bilinear(MCB) pooling을 적용해서 문장과 각 이미지 영역간의 연관성을 계산한다.
4) 이렇게 형성된 주황색 벡터를 Convolution Layer에 통과시켜 1×14×14 차원의 attention map을 생성한다.
5) 이 attention map의 값들을 weight로 하고, 이미지 부분들에 대한 Representation Vector를 가중합하여 Image representation vector를 추출한다.
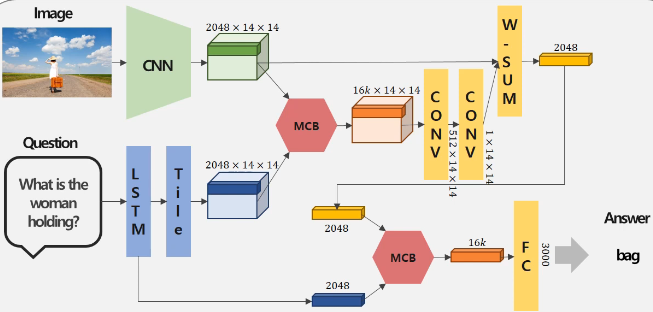
6) 5에서 구한 Image representation vector와, 2에서 구한 representation vector에 MCB pooling을 적용해서 Multimodal Representation Vector 를 생성한다.
7) 이 Multimodal Representation Vector 를 Fully-Connected Layer에 통과시켜 3000개의 class를 가진 classification을 수행할 수 있게끔 만들어준다.
2.1.4 MCB를 활용한 Multimodality Task 실험결과
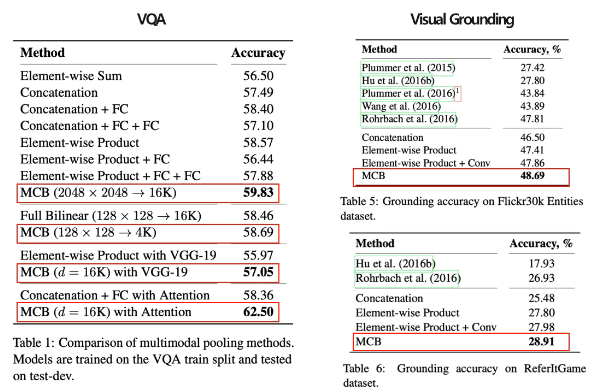
VQA와 Visual Grounding 모두 MCB pooling이 다른 Joint Representation 방법론들에 비해 좋은 성능을 보였다.
2.1.5 Joint Representation의 장단점
Joint Representation은 모달리티의 갯수와 상관없이 정보 융합이 편리하다는 장점이 있다. 하지만 융합된 차원인 Common Space에서 일부 모달리티 정보가 손실된 상황에서는 추론이 어렵다는 단점을 갖는다.
이어서는 Joint Representation을 대체할 수 있는 Coordinated Representation, Encoder-Decoder 방식에 대해 설명하고자 한다.
