[강연 리뷰] Multimodal Representation Learning: How to Narrow Heterogeneity gap (2)
강연 링크: Multimodal Representation Learning: How to Narrow Heterogeneity gap
2.2 Coordinated Representation
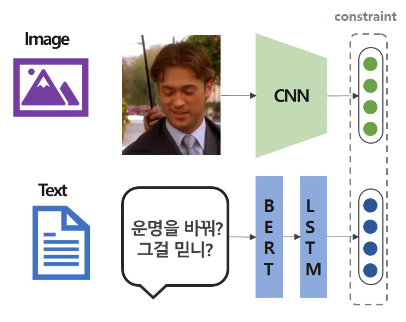
Coordinated Representation 방식이란 어떤 제약을 두어서 다른 모달리티이더라도 같은 의미를 가지면 common space에 가깝게 매핑하는 방식이다. Joint Representation과는 달리 각 Modality Representation을 분리해서 매핑하는 것이 특징이다. 제약을 주는 방법에 따라 Cross-modal Ranking, Euclid Distance 등으로 나눌 수 있다.
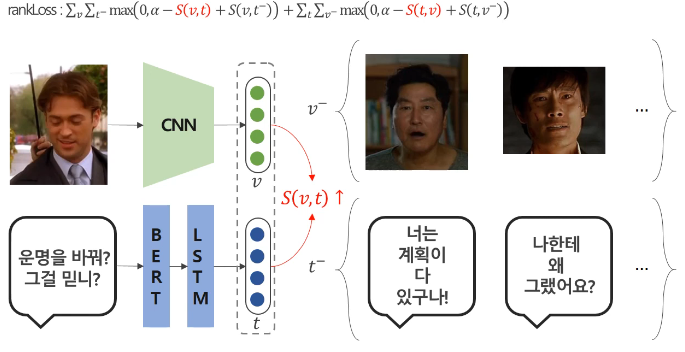
- Cross-modal Ranking 방식은 쌍을 이루는 모달리티끼리의 similarity는 크도록, 쌍이 아닌 다른 모달리티와의 similarity는 작도록 제약하는 방식이다.
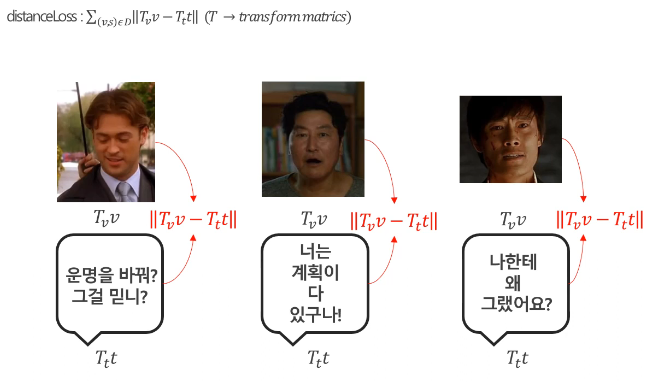
- Euclid Distance 방식은 쌍을 이루는 서로 다른 모달리티의 representation vector간의 거리를 최소하하는 제약을 두는 것이다.
2.2.1 Coordinated Representation을 활용한 연구
Deep Visual-Semantic Alignments for Generating Image Descriptions
이 연구는 Image Description Task를 수행하는 모델에 대한 연구인데, 이미지의 특정 부분과 문장의 단어들 사이의 관계를 고려하는 Coordinated Representation 방식을 적용했다.
해당 모델에서 Multimodal Representation을 생성하는 방법은 아래와 같다.

1) 200개의 class에 대해 학습된 RCNN을 통해 Image Representation Vector를 생성하고, 이미지 내에 객체가 존재할 만한 bounding box를 예측한다.
2) 객체가 있을 확률이 높은 상위 19개의 bounding box와 전체 이미지를 이미 학습된 CNN에 통과시켜 4096차원의 벡터 20개를 생성한다.
3) 4096차원의 벡터 20개를 각각 h차원의 representation vector로 임베딩한다.
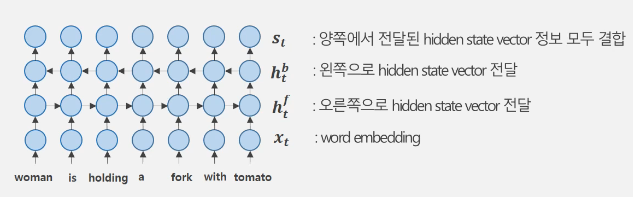
4) BRNN(Bidirectional RNN)을 활용하여 문장 내 단어들에 대한 h차원의 representation vector를 생성한다. 이때, BRNN은 문장의 양 방향에서 모두 학습이 이루어지는 모델이다.
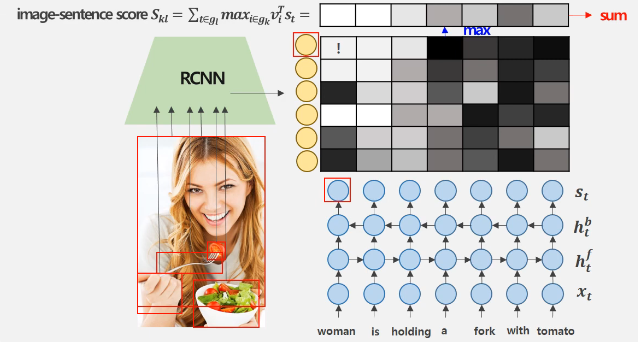
5) 이미지의 특정 영역들과 문장 내 단어들을 사이의 관련 정도를 스코어로 표현하는 Image-Sentence Score를 구한다.
6) 쌍을 이루는 이미지와 문장 간의 Image-Sentence Score가 최대가 되도록 제약을 두어 Multimodal Representation을 학습한다. 위 그림에서 노란 원은 각 bounding box에 대한 vector이고, 파란색 원은 단어들에 대한 vector이다. 이 벡터들의 내적을 통해 각 이미지 부분에 대한 Image-Sentence Score를 구하면 된다. 색깔이 흰색에 가까울수록 높은 연관성을 가지고, 검은색에 가까울수록 낮은 연관성을 갖는 것으로 해석할 수 있다.
7) 각 단어들에 대해 가장 높은 연관성을 갖는 bounding box를 추출하고, 이를 모두 더해 최종적인 Image-Sentence Score를 구한다.

8) 쌍을 이루는 이미지와 문장간의 Image-Sentence Score가 크도록 제약을 두어 Common Space를 학습한다.
2.2.2 Coordinated Representation을 활용한 연구 결과

각 bounding box가 나타내는 물체를 단어로 잘 표현하는 것으로 보인다.
2.2.3 Coordinated Representation의 장단점
Joint Representation과 달리 각 모달리티에 대해 분리된 representation을 학습할 수 있어서 Modality-Specific한 특징을 보존할 수 있다. 하지만, 2개보다 많은 모달리티가 존재하는 경우 어떻게 제약식을 설정할 것인가에 대한 기준을 정하기 쉽지 않다는 단점을 갖는다.
2.3 Encoder-Decoder Representation
Encoder-Decoder Representation 방식은 하나의 모달리티를 다른 모달리티의 Representation Space에 매핑하는 방식이다.
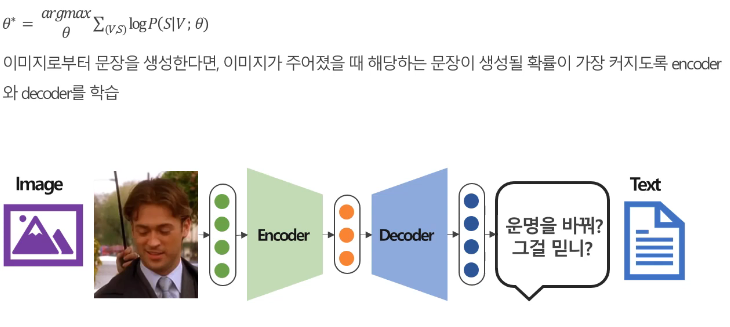
Source Modality를 인코더에 통과시켜서 잠재 벡터(Latent vector)를 추출하고, 이 잠재 벡터를 디코딩해서 Target Modality로 변환하는 원리이다. 따라서 Source Modality에 대응하는 정보를 Target Modality로 변환될 확률을 가장 높이는 Encoder, Decoder의 파라미터를 학습하는 과정이 이 과정의 핵심 목표라고 볼 수 있다.
2.3.1 Encoder-Decoder Representation의 장단점
Encoder-Decoder 방식은 Source Modality를 활용하여 Target Modality의 새로운 샘플을 생성 가능하다는 장점이 있다. 하지만 Encoder와 Decoder 모두 하나의 양식만을 지원한다는 점이 단점이다. 그래서 이미지로부터 텍스트를 생성하는 모델을 이 방식으로 학습했다면, 반대로 텍스트를 통해 이미지를 생성하는것은 불가능하다.
3. Conclusion
모달리티간의 상호보완적 정보 공유를 가능하게 하기 위해서는 Multimodal Representation Vector가 필요하다. Multimodal Representation Vector를 생성하는 방식으로는 크게 Joint Representation, Coordinated Representation, Encoder-Decoder Representation방식이 있다. 어떤 방식을 사용하느냐에 따라 저장 공간이나 계산량이 크게 달라질 수 있다. 또한 각 방식의 장단점을 잘 고려하여 풀고자 하는 Task에 적합한 방식을 활용하는 것이 중요하다. 최근에는 여러 방식을 동시에 사용해서 Representation Vector를 생성하는 방법들도 생겨나고 있는데, 이처럼 앞으로도 더 좋은 Multimodal Representation Vector를 생성하려는 연구가 활발하게 진행될 것으로 보인다.
멀티모달 AI 모델의 학습 방식에 대해 막연하게만 생각했었는데, 실제 계산식과 예시를 통해 설명을 듣고 나니 이해가 훨씬 잘 되어서 유익했다. 졸업 프로젝트 주제와 관련해서도 생각할 거리가 많았다. 서로 다른 모달리티 데이터 간의 Translation을 어떻게 효율적으로 할지 고민했었는데, 이 고민에 앞서 우리가 어떤 Task를 해결할 것인가를 먼저 정하는 것이 중요하다는 것을 깨달았다. Task의 목적과 특성에 따라 적합한 Multimodal Representation Vector를 생성하는 방식이 달라지기 때문이다. 또한, 어떤 모달리티 데이터를 사용할지에 대한 고민도 필요함을 알게 되었다. 이번 강의에서 다룬 예시는 주로 이미지와 텍스트 데이터를 사용했지만, 실제로는 더 다양한 모달리티 데이터를 다루기 때문에 이 부분에서 연구를 확장할 수 있을 것 같다.
- 이미지, 텍스트 이외의 다른 모달리티 데이터를 활용하여 각 멀티모달 표현 방식의 정확도를 비교하기
- 제한된 리소스 환경에서 연산을 줄일 수 있는 Modality Translation 방법 연구하기: Count Sketch Projection을 적용한 Multimodal Compact Bilinear(MCB)연구 예시와 비슷한 느낌으로 하면 좋을 것 같다. Count Sketch Projection 역시 엣지 AI환경에서는 무거운 연산이지 않을까 하는 의문이 들었다. 이 연산을 더 간략하게 만들어서 나만의 Function을 만들고 정확도와 리소스 사용의 trade-off를 구해서 엣지 AI 환경에 적합한 Representation 방식을 제안하는 것도 흥미로울 것 같다.
- 최근에는 여러 방식을 동시에 사용하여 표현 벡터를 생성하는 연구도 진행되고 있다고 한다. 졸업 프로젝트 주제의 핵심 키워드 중 하나는 아마도 '최적화'가 될 것 같은데, 각 표현 방식에서 연산이 무겁지 않은 부분을 적절히 융합해 새로운 멀티모달 표현 방식을 제안하는 것도 좋을 것 같다. (이게 가능할지는 아직 확신할 수 없지만...)
더 알아가고 싶은 부분을 정리해봤는데 일단 이 정도이다. 아는만큼 보인다고.. 공부를 더 해서 보다 다양한 아이디어를 내고 싶다.
