RAG 구조 도입 배경과 설계 개요
GPT, LLaMA 등의 대형 언어 모델(LLM)은 질문에 자연스럽게 답을 생성하는 데 매우 강력한 도구다.
비정형 텍스트를 요약하거나, 광고 문구처럼 표현 방식이 다양한 문장을 해석할 수 있다는 점에서 그린워싱 탐지에도 적용 가능성이 있다.
하지만 LLM은 본질적으로 환각(hallucination) 문제를 갖고 있다.
존재하지 않는 정보를 실제처럼 만들어내는 현상이다.
환각(hallucination)
LLM은 학습된 정적인 데이터만을 기반으로 다음 단어를 예측하는 방식으로 응답을 생성한다.
이 과정에서 실제 사실이 아닌 정보도 자연스럽게 말하는 경우가 생기고, 특히 기준이 명확해야 하는 환경 규제나 법적 판단 영역에서는 이런 오류가 치명적일 수 있다.
실제로 ‘세종대왕이 맥북을 던졌다’는 식의 말도 안 되는 응답이 인터넷 밈으로 유행했던 사례도 있다.
이는 LLM이 문맥상 말이 되는 문장을 만들 수는 있어도 그것이 진짜인지 아닌지를 구분하지 못한다는 것을 보여준다.
그래서 검색을 붙였다: RAG 구조
이러한 한계를 보완하기 위해, 검색 증강 생성(Retrieval-Augmented Generation, RAG) 구조가 사용된다.
RAG는 사용자의 입력에 대해 먼저 외부 벡터 데이터베이스에서 관련 문서를 검색한 후,
그 문서들을 기반으로 LLM이 응답을 생성하도록 유도하는 방식이다.
이 구조는 다음과 같은 장점을 가진다:
- 모델이 알지 못하는 정보도 검색으로 보완 가능
- 출처가 명확한 문서 기반 응답 생성
- 학습 없이도 외부 지식에 기반한 정밀 판단 가능
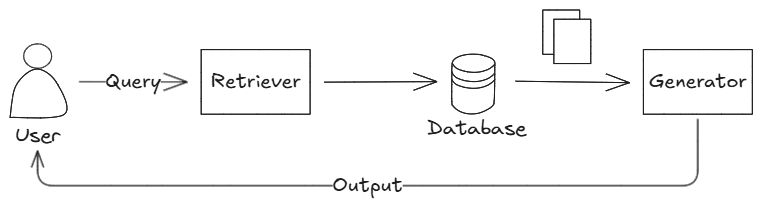
내 시스템에서의 적용 방식
내가 구축한 그린워싱 탐지 시스템은
다음과 같은 RAG 구조로 구성된다.
- 입력 문장: 기업의 친환경 마케팅 문구
- 임베딩: KoSimCSE로 벡터화
- 벡터 검색: Chroma DB에서 관련 법률/가이드라인 문서 검색
- 재정렬(Reranker): 관련성이 높은 문서 순서로 정렬
- 응답 생성: LLM(Llama3 기반 모델)이 판단 및 설명 생성
사용한 주요 구성 요소
| 구성 요소 | 선택 모델 | 이유 |
|---|---|---|
| 임베딩 모델 | KoSimCSE | 한국어 환경에 특화되어 있어 의미 유사도 계산에 유리함 |
| 벡터 DB | Chroma + FAISS | 로컬 실행 가능, 문서 확장 시 효율적 관리 가능 |
| LLM | ktds-llama3.1 | 한국어 기반 모델 중 구조화된 프롬프트에 안정적으로 반응함 |
요약
LLM은 강력하지만 불완전하다.
특히 규제 문서처럼 신뢰성과 정밀함이 요구되는 경우, 모델이 “아는 척”하지 않도록 구조적인 보완이 필요하다.
