해당 내용은 CSAPP의 내용을 정리하는 부분입니다.
9.9.6 묵시적 가용 리스트(implicit free lists)
실용적인 allocator는 블록 경계를 구분하고, 할당된 블록과 가용 블록을 구분하는 데이터 구조를 필요로 함
그리고 대부분의 allocator는 이 정보를 블록 내에 내장
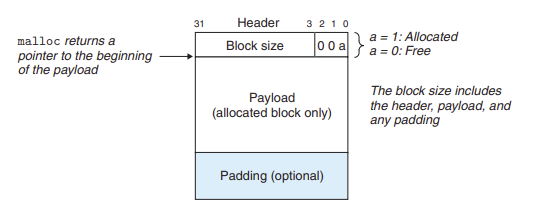 그림 - 힙 블록 포맷
그림 - 힙 블록 포맷
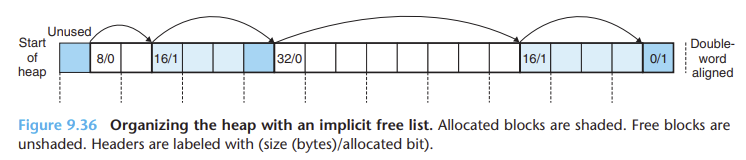 그림- 가용 리스트를 사용해서 힙 구성하기
그림- 가용 리스트를 사용해서 힙 구성하기
힙 블록 포맷을 확인하면 Header 는 블록크기(헤더와 추가적인 패딩 포함)와 블록의 할당 여부에 대해 확인할 수 있다.
ex) 더블 워드 정렬 제한 조건을 가진다면 - 블록 크기는 항상 8의 배수 - 하위 3bit는 항상 0 - 3bit는 다른 정보를 인코드하기 위해 남겨둠 - 그 중 1bit는 header가 블록의 가용 여부에 대해 사용
ex)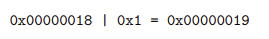
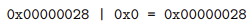
위 이미지중 헤더가 0x1인 이미지는 현재 할당된 블록이다.
따라서 bit가 1 증가한 것을 확인할 수 있다.
아래 이미지는 헤더가 0x0이고 현재 가용블록인 상태이다.
따라서 bit가 증가하지 않고 블록의 크기가 그대로 나온 것을 확인할 수 있다.
padding의 필요성
- 외부 단편화를 극복하기 위한 할당기 전략의 일부분
- 정렬 요구사항을 만족하기 위해 필요할 수 있음
묵시적 가용 리스트의 장단점
장점 : 단순하다.
단점 : 연산 비용(할당된 블록을 배치하는 것과 같이 가용리스트 탐색에 드는 비용)이 전체 할당된 블록과 가용 블록의 수에 비례한다.
최소 블록 크기를 결정하는데 중요한 부분
- 시스템의 정렬 요구 조건과 할당기의 블록 포맷 선택
할당되거나 반환된 블록 모두 이 최소값보다 더 작을 수 없음
ex) 더블 워드 정렬 요구조건 하에 각 블록의 크기는 2워드의 배수여야 함
9.9.7 할당한 블록의 배치
allocator 가 검색을 수행하는 방법은 배치 정책(placement policy)에 의해 결정
주로 사용되는 정책은
- first fit : 가용 리스트를 처음부터 검색해서 크기가 맞는 첫번째 가용 블록을 선택
장점 - 마지막에 가장 큰 가용 블록들을 남겨두는 경향이 있음
단점 - 큰 블록을 찾는 경우에 검색 시간이 늘어남- next fit : first fit과 유사하지만 검색을 처음부터 시작하는 대신 이전 검색이 종료된 지점에서 검색을 시작,
장점 - first fit 보다 빠름
단점 - first fit보다 조금 더 빠르나 최악의 메모리 이용도를 가짐- best fit : 일반적으로 first fit, next fit 보다 더 좋은 메모리 이용도를 가짐, 하지만, 묵시적 가용 리스트 같은 단순한 가용 리스트 구성을 사용할 경우 힙을 완전히 다 검색해야 한다는 단점이 있음
9.9.8 가용 블록의 분할
할당기가 크기가 맞는 가용 블록을 찾았다면 가용 블록의 어느 정도를 할당할 지에 대해 결정을 내려야함
한 가지 옵션은 가용 블록 전체를 사용하는 것
장점 : 간단하고 빠름
단점 : 내부 단편화 발생 - 하지만 배치정책으로 인해 크기가 잘 맞는다면, 일부 추가적인 내부 단편화는 수용할 수 있음
9.9.9 추가적인 힙 메모리 획득하기
할당기가 요청한 블록을 찾을 수 없는 경우
1. 메모리에서 물리적으로 인접한 가용 블록들을 합쳐서 더 큰 가용 블록을 만듦 (이렇게 해도 충분한 크기가 확보가 안될 경우)
2. 커널에서 sork 함수를 호출해서 추가적인 힙 메모리를 요청함
할당기는 추가 메모리를 한 개의 더 큰 가용 블록으로 변환하고, 이 블록을 가용 리스트에 삽입한 후에 요청한 블록을 이 새로운 가용 블록에 배치함
9.9.10 가용 블록 연결하기
할당기가 할당한 블록을 반환할 때, 새롭게 반환하는 블록에 인접한 다른 가용 블록들이 있을 수 있음.
이런 인접 가용 블록들은 오류 단편화(false fragmentation) 라는 현상을 유발할 수 있음
이를 해결하기 위해 연결(coalescing)이라는 과정으로 인접 가용 블록들을 통합해야 함
--> 언제 연결을 수행해야 할지에 관한 결정을 해야함
- 블록이 반환될 때마다 인접 블록을 통합해서 즉시 연결
- 일정 시간 후에 가용 블록들을 연결하기 위해 기다리는 지연 연결
즉시 연결
- 간단하고 상수 시간 내에 수행할 수 있음
- 일부 요청 패턴에 대해서는 블록이 연속적으로 연결되고 잠시 후에 분할되는 쓰래싱(Thrashing)의 형태를 유발할 수 있음
- 위 이유로 빠른 allocator들은 종종 지연 연결의 형태를 선택함
