data_structure_and_Pintos
1.05_week_C_RB_tree
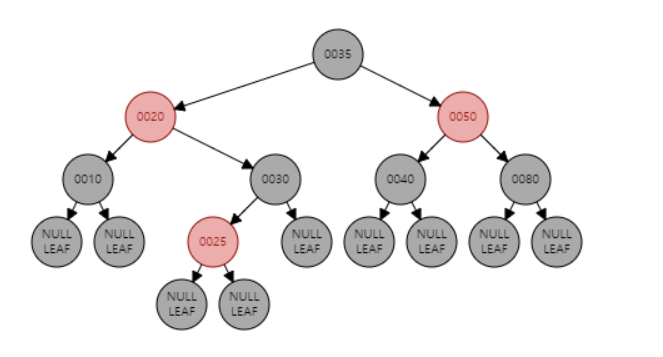
RB 트리BST (이진 탐색 트리) 의 한 종류양쪽의 균형을 맞추면서 만들어진다장점 : 시간 복잡도가 O(LogN) 이 됨 (그냥 이진트리는 최악의 경우 시간 복잡도 O(N))속성 - RB Tree의 규칙(무조건 지켜져야함)1\. 모든 노드는 red 혹은 black2\
2.05_week_C_single linked list
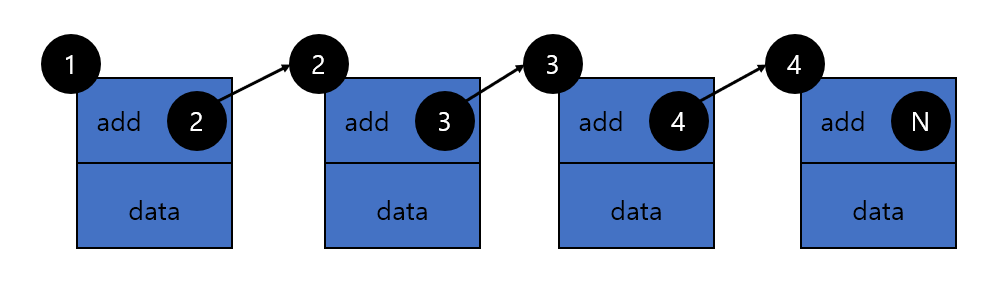
단방향 linked list한 구조체에값과 다음 구조체로 이어지는 주소를 갖는다아래 그림과 같다single linked list header filesingle linked list c filesingle linked list main.c file
3.05_week_C_BST

BST = binary search tree이진 탐색트리이진 트리에서 search, insert, delete 가 가능하다delete는 3가지 경우로 나눠진다.1\. 자식 노드가 없는 경우2\. 자식 노드가 1인 경우3\. 자식 노드가 2인 경우코드는 아래 참조BST_
4.05_week_C_RB_tree_구현

앞의 RB_tree 이후에서 내용을 이어감Nil 노드의 필요성Nil 은 한계조건을 간단하게 해주는 역할을 함Root의 parent 도 nil로 연결되고가장 마지막 자식의 child도 nil로 처리됨이를 이용하여 head의 정보와 끝나는 정보를 가질 수 있음즉, 한계조건
5.06_week_C_malloc
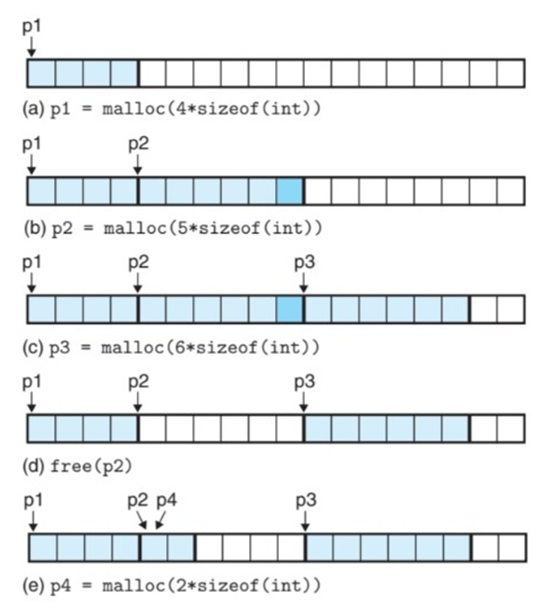
가상 메모리 영역을 저수준의 mmap(생성)과 munmap(삭제) 함수를 사용해서 생성하고 삭제 가능C programmer들은 대개 추가적인 가상메모리를 런타임에 획득할 필요가 있을 때, 동적 메모리 할당기(dynamic memory allocator)를 사용하는 것을
6.06_week_C_malloc_2
해당 정리 내용은 CSAPP를 정리하는 부분입니다.동적메모리를 사용하지 않는 가장 간단한 방법은 최대 배열 크기를 갖는 정적 배열로 정의하는 것이는 때로는 나쁜 방법이 될 수 있음만일 프로그램의 사용자가 정해진 배열의 크기보다 더 큰 파일을 읽으려고 한다면, 유일한 대
7.06_week_C_malloc_3
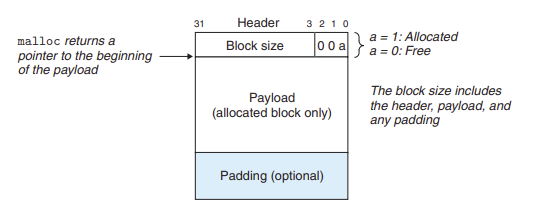
해당 내용은 CSAPP의 내용을 정리하는 부분입니다.실용적인 allocator는 블록 경계를 구분하고, 할당된 블록과 가용 블록을 구분하는 데이터 구조를 필요로 함그리고 대부분의 allocator는 이 정보를 블록 내에 내장그림 - 힙 블록 포맷그림- 가용 리스트를 사
8.06_week_C_malloc_4
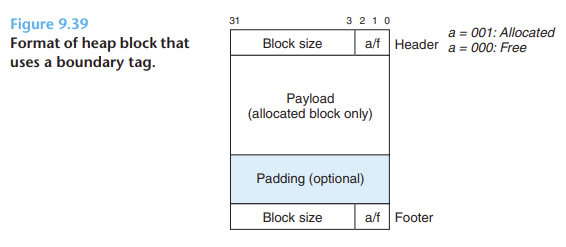
현재 블록 : 반환하려는 블록다음 가용 블록이 있으면 바로 연결하는 것은 쉽고 효율적임현재 블록의 헤더는 다음 블록의 헤더를 가리키고 있으며, 이것은 다음 블록이 가용한지 결정하기 위해 체크될 수 있음(Linked list concept?)\-->이렇게 된다면 크기는
9.06_week_C_malloc_implicit_구현
해당 코드를 구현하면서 주의해야할 점heap 에서 bp의 움직임을 생각해야함current block에서 previous block으로 또는 next block으로그리고 각각의 block의 할당여부와 크기를 확인할 수 있는 방법을 감안해야함CSAPP 를 토대로 구현하였음
10.06_week_C_malloc_5
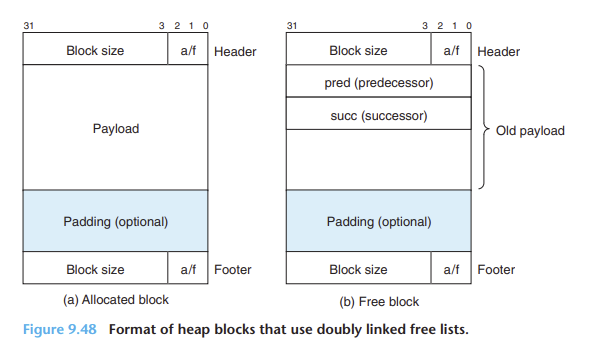
9.9.13 명시적 가용 리스트 묵시적 가용 리스트는 할당 시간이 전체 힙 블록의 수에 비례하기 때문에 범용 할당기에는 적합하지 않음 (힙 블록의 수가 사전에 알려져 있고, 작고 특수한 경우에는 더 좋을 수도 있음) 가용 블록 본체는 프로그램에서 필요하지 않기 떄문에
11.06_week_C_malloc_implementation_명시적할당기+묵시적 가용리스트
단일 방향 탐색을 진행하며항상 탐색은 제일 앞부터 진행한다 (first fit)명시적 할당기 + 묵시적 가용 리스트 사용malloc으로 할당을하고 free로 해제를 해줘야함반대로 묵시적 할당기는garbage collector를 사용함으로써따로 free를 해주지 않아도
12.06_week_C_malloc_implementation_명시적할당기+명시적 가용 리스트
명시적 할당기 + 명시적 가용리스트 Explicit free list Address order주소순 정렬을 사용한 방법주소순 정렬후 first fit을 사용하면 메모리 이용도에서 보다 좋은 결과를 얻을 수 있음implicit free list와 다른점은 heap lis
13.06_week_C_malloc_segregated_list

묵시적 할당기 + segregated list가용 리스트를 size class로 관리함heap 을 요청하면서 블록 크기를 전부 잘라서 관리함 (동일한 크기)즉 2 워드 크기를 갖는 heap 하나3워드 크기를 갖는 heap 하나 ...9~inf 까지 관리하는 heap (
14.07_week_C_webserver_hostinfo
CSAPP 내용은 추후 업데이트해당 내용들을 이해하기 위해선 socket, DNS, IP address에 대한 내용을 이해해야함또한 해당 부분에서 이용하는 함수들에 대해서도 이해하여야 함getaddrinfogetnameinfohostinfo - 내가 요청하는 domai
15.07_week_C_webserver_echo
csapp.c 에 대한 내용은 이전 hostinfo 를 참고echo 는 client가 server에 보낸 정보를 server가 받고 다시 client에게 돌려줌그래서 echo임아래는 echo 관련 코드 분석echoserveri.cechoclient.cecho.c
16.07_week_C_proxy
proxy서버 1:1 구현에서Poxis thread를 사용한 동시성까지 구현됨cache는 구현되지 않았음 아직
17.07_week_C_tiny
해당 내용은 CSAPP 와 cmu 문제를 기반으로 작성됨webserver 구현 연습을 위한 tiny server 만들기tiny 는 서버 구현부csapp.c 와 csapp.h 는 git 에서 확인 가능내 gitub
18.07_week_C_adder
adder 파일을 이용하여 HTML에서 adder가 동작하게 하기html과 adder.c file을 이용함adder.c의 파일 위치는 cgi-bin 폴더 안에 있음해당 내용은 웹서버의 동적 컨텐츠에 대한 이해를 돕기위한 부분코드의 전체 부분은 git에서 확인 가능git
19.07_week_C_Proxy_(concurrency and cache)
해당 방법은캐시를 구조체 형태로 저장하고 구조체를 리스트로 관리하는 방법을 사용하였습니다.먼저 프록시 서버를 만들때 중요했던 점소캣이 어디서 어디로 연결되는 파일인지 헷갈리지 말 것uri를 parsing할때 꼼꼼히 볼 것Header를 구성 서버에 전송하면 respons
20.08_week_C_Pintos

Pintos 1주차
21.08_week_C_pintos_systemcall-1
Project 1 에서는 lib에 존재하는 systemcall (write, exit, halt 등)을 사용하였기 때문에 우린 kernel 부만 작업하면됐었다.이제는 kernel 에서 user로 이어지는 부분을 작업한다.순서는Argument passing --> sys
22.08_week_C_pintos_systemcall-2
여기서부터는 system call을 구현할 예정이다(halt, exit, wait, close, create, remove, seek, tell)syscall을 구현하기 전에 pml4 에 빨간줄이 계속 생겨서 불편하다면 아래와 같은 방법으로 해결하면된다. (Ctrl +
23.08_week_C_pintos_systemcall-3
이어서구현된 부분(exec, open, file size, read, write)file을 실행가능한 파일로 변경함 - 성공하면 아무것도 return 안하고 실패하면 -1을 returnprocess_exec 는 앞에서 load를 구현할때 사용하였다. load에 문제가
24.08_week_C_pintos_systemcall-4
마지막 구현인 fork이다systemcall 구현중 가장 복잡한 부분이다fork를 구현할때 가장 중요한 부분은 부모의 모든 process를 복사해서 저장한다부모의 process에서 열려있던 file에 대한 정보도 전부 상속 받는다관련된 함수(process_fork, \
25.09_pintos_3_VM
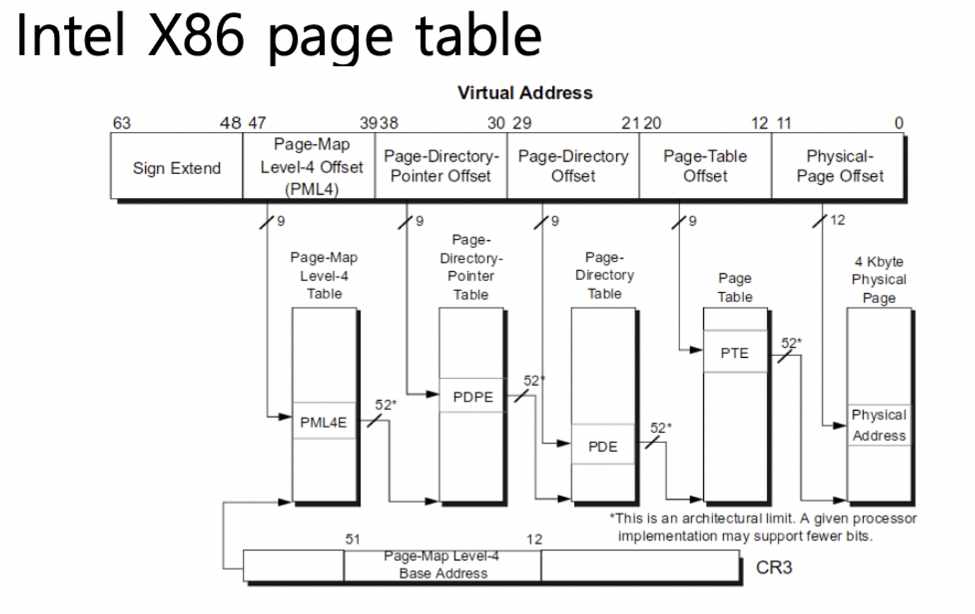
pintos VM을 진행하기에 앞서 먼저 필요한 내용들을 다시한번 정리해보려고 한다.우리 pintos 기준 가상메모리와 물리메모리의 관계CR3 참고자료page : 가상메모리를 일정한 크기로 나눈 블록frame : 물리메모리를 일정한 크기로 나눈 블록기존 pml4를 사용
26.09_pintos_VM
Pintos project 1~3까지 진행이 됐다.project 2 - system call을 할땐 system call이 제일 힘든건줄 알았는데 project 3- vm을 하니 vm이 가장 힘든거라는걸 알게 됐다.project 4 는 더 힘들 것인가...일단 결과를
27.09_pintos_VM_hash
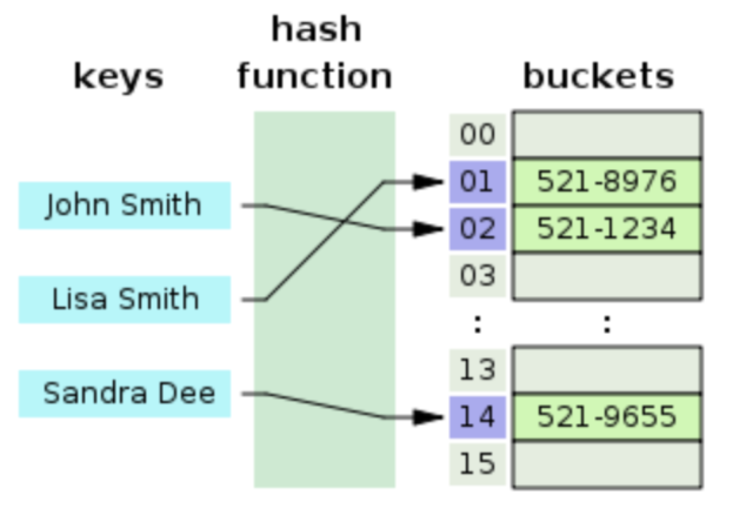
우리는 pintos에서 hash table을 사용할 것이다.pintos 안에는 이미 hash.c, hash.h 을 통해서 함수가 구현되어 있는 것을 확인할 수 있다.여기서는 hash를 간단하게 정리하고 코드 정리를 하겠다.hash table이란데이터를 저장하는 자료구조
28.09_pintos_VM_memory_management
우리는 가상메모리 혹은 물리메모리를 누가 사용했고 무슨 목적으로 사용했는지를 기억하고 있어야함이를 위해서 우리는 supplemental page table을 사용할 것이고 이후에 물리 메모리를 다룰 예정이다.supplemental_page_table_init 우리는 h
29.09_pintos_VM_Anonymous_page

여기서는 anonymous page라고 불리는 디스크가 아닌 image를 구현함anonymous mapping에는 백업파일 혹은 장치가 없음익명 페이지는 실행가능한 파일에서 스택과 힙 영역에서 사용됨이 구간에서는 load_segment와 lazy_load_segment
30.09_pintos_VM_stack_growth
Project 2에서 스택은 USER_STACK 에서 시작하는 단일 페이지였으며, 프로그램은 이 크기(4KB)로 제한하여 실행했습니다. 이제 스택이 현재 크기를 초과하면 필요에 따라 추가 페이지를 할당합니다.stack 을 키우기 위해서 thread 구조체에 void \
31.09_pintos_VM_memory_mapped_file
Memory mapped page를 구현할 것입니다.anonymous page와 다르게 Memory mapped page는 file page 기반입니다.page fault가 발생하면 물리 프레임이 즉시 할당되고 content가 file에서 memory로 복사됨memor
32.09_pintos_VM_etc
x86_64 하드웨어는 각 페이지에 대한 페이지 테이블 엔트리(PTE)의 비트 쌍을 통해 페이지 대체 알고리즘을 구현하는 데 약간의 도움을 제공한다.페이지에 대한 읽기 또는 쓰기에서 CPU는 페이지의 PTE에서 액세스된 비트를 1로 설정하고, 쓰기에서 CPU는 더티 비
33.09_pintos_VM_Swap_In/Out
메모리 스와핑은 물리 메모리의 활용을 극대화하기 위한 메모리 회수기법입니다.메인 메모리의 프레임들이 모두 할당된다면, 시스템은 유저프로그램이 요청하는 메모리 할당 요청을 더 이상 처리할 수 없습니다.이에 대한 한 가지 해결 방법은 현재 사용되지 않고 있는 메모리 프레임
34.09_pintos_QnA_total

5개의 댓글문준호(정글5기) 2개월 전저도 stack alignment에 대한 내용 궁금합니다!!박선호(TA) 2개월 전안녕하세요, 조교 박선호입니다.패딩이 이뤄지는 이유가 더블 워드로 정렬이 되기 때문인지 질문 주셨는데, 제가 질문을 이해하기론 인과 관계가 거
35.10_pintos_file_systems
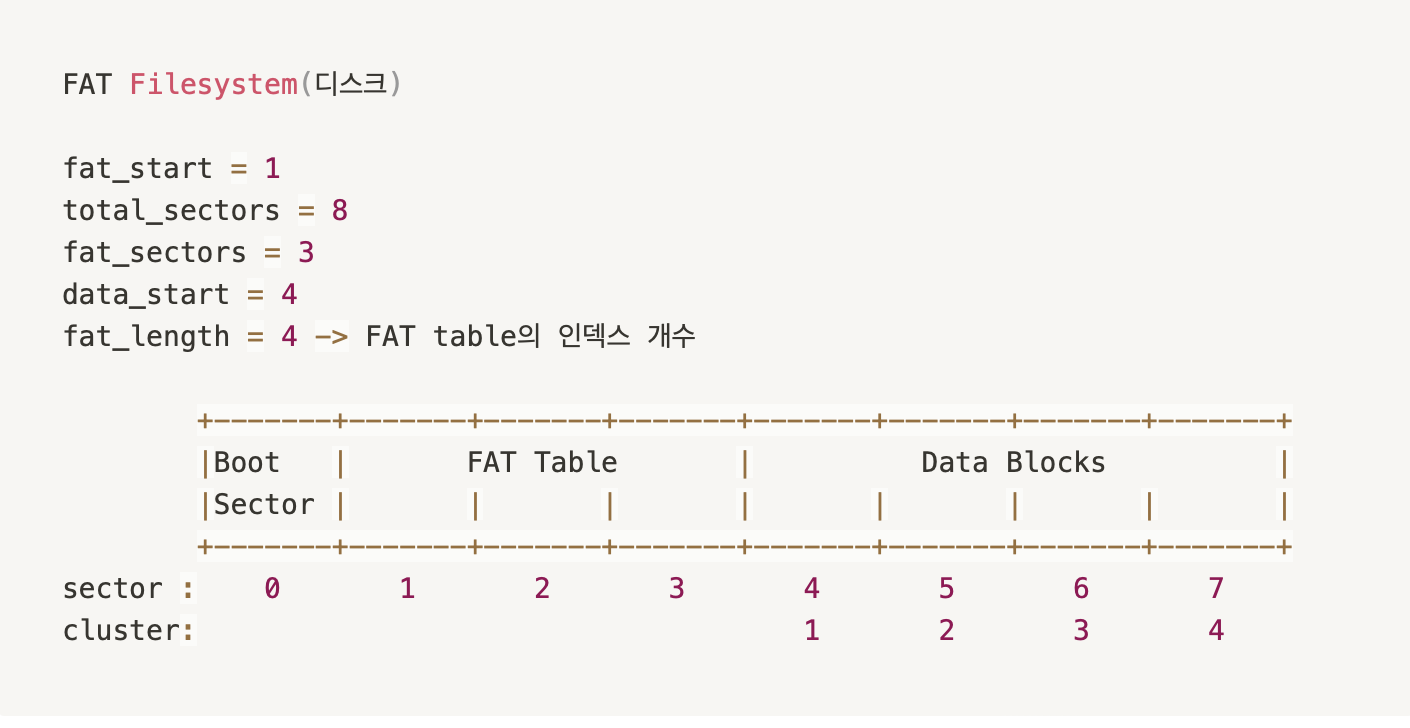
우리는 이전까지 virtual memory 까지 구현하였다.하지만 구현하면서 filesys 부분은 신경쓰지 않고 그냥 가져다 사용하였다.이제 우리는 filesys directory를 수정할 것입니다.project 2를 base로도 사용 가능하고project 3를 bas
36.01_week_computer_system
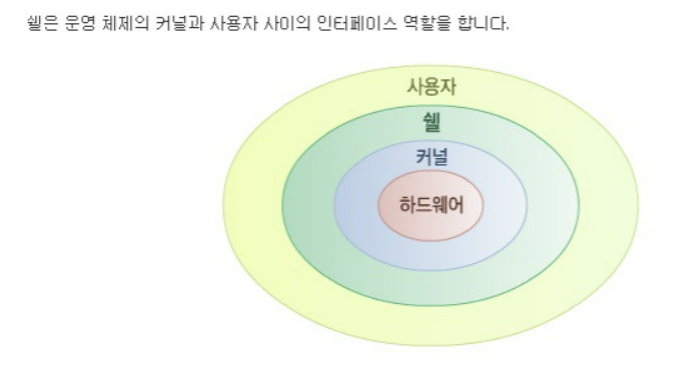
computer system 구성1\. HW2\. SWcomponentSW의 재사용의 중요성과 필요성을 위해 나온 기술텍스트 파일 : 오로지 아스키 문자로만 이뤄진 파일바이너리 파일 : 텍스트파일을 제외한 모든 파일contextHW : regitster, flag 등의