1
신치우(정글5기)
10월 27일, 오후 10:36
안녕하세요. 정글 5기 신치우 라고 합니다.
CSAPP 9장을 읽던 중에 궁금한 부분이 있어서 연락을 드립니다.
9.9 동적메모리 할당 811 page의 그림 9.34에 해당하는 내용입니다.
그림 9.34(b)에서 더블워드 경계에 정렬되도록 하기 위해서 블록에 추가적인 워드를 패딩하였다 부분입니다.
그림에 따르면 4워드, 5워드로 9워드를 할당 받고 10번째 워드를 패딩한 후 11번째 워드부터 다시 블록을 할당 받는 모습을 보여줍니다.
여기서 패딩이 이뤄지는 이유가 더블 워드로 정렬이 되기 때문에 5 워드 블록을 요청한 것을 패딩을 포함한 6워드로 할당되는 것이 맞는지 알고 싶습니다.
혹시 제가 맞게 생각을 하는 것인지 알고 싶습니다.
5개의 댓글
문준호(정글5기)
2개월 전
저도 stack alignment에 대한 내용 궁금합니다!!
박선호(TA)
2개월 전
안녕하세요, 조교 박선호입니다.
패딩이 이뤄지는 이유가 더블 워드로 정렬이 되기 때문인지 질문 주셨는데, 제가 질문을 이해하기론 인과 관계가 거꾸로 된 것 같습니다. 정확히 설명하자면, malloc이 항상 더블 워드로 정렬된 메모리 주소를 반환하기 위해서 패딩을 합니다.
Section 3.9.3의 data alignment 부분에 보면 데이터 타입에 따른 alignment 요구사항이 있는데, malloc함수 자체는 사용자가 이 메모리 주소에 어떠한 데이터를 저장할 지 모르기 때문에 더블 워드의 배수만큼의 크기를 할당해 줌으로써 모든 경우에 대응할 수 있게 해줍니다. (만약 (b)에서 패딩을 안하면 p3이 할당받은 메모리 주소에 long이나 double을 저장한다고 했을 때 alignment requirement에 맞지 않게 될 겁니다) (편집됨)
신치우(정글5기)
2개월 전
아 그러면
요청된 블록을 더블워드로 정렬하기 위해서 패딩을 하는 것이 아닌 malloc은 더블 워드로 정렬된 메모리 주소를 반환하기 때문에 5워드로 요청된 블록을 패딩을 포함한 6워드로 할당한다 가 맞다는 말씀이신가요?
또한 data alignment는 메모리 주소에 어떤 데이터를 저장할지 예상할 수 없기 때문에 모든 경우의 수에 대응할 수 있도록 더블 워드의 배수를 할당한다. 라고 이해하였는데 맞을까요?
박선호(TA)
2개월 전
malloc이 요청된 블록을 더블워드로 정렬하기 위해서 패딩을 한다는 전자의 설명이 맞는 것 같습니다. 더블워드로 정렬한다는 말은 반환하는 메모리의 크기가 더블워드의 배수라는 말이 아니고 반환하는 메모리 주소가 더블워드의 배수가 되어야 한다는 말인데, (b)에서 패딩을 해주면 다음 malloc call에서 쉽게 memory alignment에 맞는 메모리 주소를 반환할 수 있기 때문에 이러한 design choice를 합니다.
네 맞습니다.
(편집됨)
2
안녕하세요 구조체 data alignment 관련해서 문제를 풀어보다가 책의 답지와 제가 생각한 답이 다른 부분이 있는데, 도저히 이해가 안가서 질문 드립니다.
연습문제 3.44인데요.
문제 조건이 x86-64 이기 때문에 64bit mode -> pointer가 8바이트이고, 각 구조체 안에서 가장 큰 자료형의 size로 alignment하는 문제라고 이해 했습니다.
이해한대로 A에 대해서만 그림으로 그려본 내용
직접 컴파일해서 실행했을 때의 결과
테스트 코드
첨부한 이미지와 코드 블록은 위 내용입니다. 참고 부탁드립니다.
직접 실행했을 때는 제가 이해한 대로 나오는 것 같은데, 정오표에 해당 문제가 없어서 혹시 잘못이해한 건가 싶어 질문 드립니다.
#include <stdio.h>
#include <stdlib.h>
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
struct P1 {
short i;
int c;
int *j;
short *d;
};
struct P4 {
char w[16];
int *c[2];
};
struct P5 {
struct P4 a[2];
struct P1 t;
};
int main(void) {
printf("PI i:%zu\n", offsetof(struct P1, i));
printf("PI c:%zu\n", offsetof(struct P1, c));
printf("PI j:%zu\n", offsetof(struct P1, j));
printf("PI d:%zu\n", offsetof(struct P1, d));
printf("PI size:%zu\n\n", sizeof(struct P1));
printf("P4 w:%zu\n", offsetof(struct P4, w));
printf("P4 c:%zu\n", offsetof(struct P4, c));
printf("P4 size:%zu\n\n", sizeof(struct P4));
printf("P5 a:%zu\n", offsetof(struct P5, a));
printf("P5 t:%zu\n", offsetof(struct P5, t));
printf("P5 size:%zu\n\n", sizeof(struct P5));
}박선호(TA)
1개월 전
제가 생각하기로도 책에 실린 정답이 이상한 것 같네요. 원희님이 제대로 문제를 푸신 것 같습니다.
참고로, 이 교재의 홈페이지에서도 global edition에 실려 있는 문제에는 많은 오류가 포함되어 있다고 적혀 있네요..
Note on the Global Edition: Unfortunately, the publisher arranged for the generation of a different set of practice and homework problems in the global edition. The person doing this didn't do a very good job, and so these problems and their solutions have many errors.
3
기재민
10월 31일, 오후 10:36
안녕하십니까. 늦은 시간에 질문 드려 죄송합니다. (급한 건 아니니 천천히 답해주셔도 됩니다~)
p825에서 CHUNKSIZE를 2^12승으로 정의하고 있습니다. 왜 하필 2의 12승(4096)인지 궁금합니다. (다른 말로 왜 하필 extend_heap할 시 2^12승, 4kib만큼의 힙을 요청하는지요)
P776에보면 '가상 페이지는 대게 4KB~2MB까지 값을 가진다'라는 부분이 있던데 관습적으로 4kib만큼을 할당한다 정도로만 생각하면 될까요?
1개의 댓글
이융희(TA)
1개월 전
안녕하세요, 조교 이융희입니다.
4 KiB만큼의 heap을 요청하는 이유는 1 page가 4 KiB이기 때문이라고 생각하시면 될 것 같습니다. 컴퓨터 입장에서 페이지는 메모리를 묶어서 다루는 가장 자연스러운 단위입니다. 추후 PintOS를 구현하면서 OS가 어떻게 하드웨어와 발을 맞춰 페이지 단위로 메모리를 관리하는지 배우게 될 것입니다.
그렇다면 1 page는 왜 4 KiB일까요? 컴퓨터가 사용할 수 있는 메모리는 정해져 있습니다. 따라서 페이지가 너무 작으면 페이지의 개수가 매우 많아서 이들을 관리하는 데 불필요하게 많은 자원을 써야 할 것이고, 페이지가 너무 크면 페이지를 사용하지 않고 남기는 부분이 많아 메모리가 낭비될 것입니다. 따라서 컴퓨터를 설계할 때 적절한 페이지 크기를 골라야 합니다. 페이지를 사용한 최초의 CPU인 인텔 80386은 1 page = 4 KiB를 골랐고, 이 크기가 x86 아키텍처에 남아 지금까지 유지되어 왔다고 생각할 수 있겠습니다.
(https://stackoverflow.com/q/11543748 이 내용을 참고했습니다.)
Stack OverflowStack Overflow
Why is the page size of Linux (x86) 4 KB, how is that calculated?
The default memory page size of the Linux kernel on x86 architecture was 4 KB, I wonder how was that calculated, and why ?
4
정나린(정글 5기)
11월 1일, 오후 9:48
안녕하십니까. CSAPP 9.9.14 분리가용 리스트 (831p)를 공부하던 중 궁금한 점이 생겨 질문드립니다.
‘간단한 분리 저장장치’에 대한 설명에서 explicit 방식과 implicit 방식과 다르게 succ 포인터를 위한 1워드만 필요하고 따라서 최소 블록 크기는 1워드라고 나와있습니다.
그렇다면 임의의 한 블록을 free하면 해당 블록을 그 크기에 해당하는 메모리 블록의 시작 부분에 붙여서 반환할텐데, 그때 크기 정보를 알 수 없어 어느 메모리 블록에 붙여야 모른다는 문제가 있는 것 같습니다.
책에서는 블록의 크기는 “주소로부터 추정할 수 있다“고 나와 있는데 어떻게 주소로 부터 블록의 크기를 알 수 있을지 잘 모르겠습니다.
4개의 댓글
이융희(TA)
1개월 전
안녕하세요, 조교 이융희입니다.
Simple segregated storage에서 block들은 오직 OS에 fixed-size chunk를 요청하는 방식으로만 생성되고, 한 번 요청한 chunk 속의 block들은 모두 같은 크기를 갖고 있습니다. 따라서 요청한 chunk들을 어떤 크기의 block으로 나누었는지 기억하고 있으면, block의 주소를 통해 block이 속한 chunk를 찾아내고 block의 크기를 알 수 있습니다.
정나린(정글 5기)
1개월 전
늦은 시간에 친절한 답변 감사합니다!! 답변에 대한 새로운 질문이 생겨 추가 질문드립니다.
“어떤 크기의 block으로 나누었는지 기억하고 있다“고 말씀해주셨는데 어떠한 방식으로 크기를 “기억“해야 하는지 잘 모르겠습니다.
요청한 CHUNK의 시작주소에 헤더를 생성해 해당 CHUNK에 속한 블록의 크기를 저장하는 방법
요청한 CHUNK의 시작 주소와 해당 CHUNK에 속한 블록의 크기를 저장한 테이블을 만들어 기억하는 방법
현재까지는 위의 두 방법이 있을 것 같은데 “간단한” 분리 저장장치라는 것과 반대로 구현 방식이 복잡해지는 것 같아 다른 방법이 있는지 여쭤보고 싶습니다.
이융희(TA)
1개월 전
이 부분은 Implementation detail이라 정확히 어떻게 하는지는 정해져 있지 않습니다. 개인적으로는 제시해주신 두 방법 모두 크게 복잡하지는 않을 것 같습니다.
5
기재민
11월 3일, 오후 1:13
안녕하세요 두 가지 질문이 있습니다.
1. P818쪽 맨 상단, 'Next_fit은 first fit 보다 최악의 메모리 이용도를 갖는다' 라는 부분이 있는데 왜 더 나쁜 메모리 이용도를 갖게 되는건가요?
2. P830쪽 4번째 문단, '명시적 가용리스트에서 반환을 주소 순서로 하는 경우 LIFO방식보다 좋은 메모리 이용도를 갖는다'라는 부분이 있는데 왜 더 좋은 메모리 이용도를 갖게 되나요?
(리포 방식이 메모리 이용도가 낮아지는 이유는 가용 리스트의 앞부분에서 할당과 반환이 빈번하게 일어나다 보니 사용자가 1의 크기만을 요청했어도 100짜리 블록이 있으면 할당을 해버리기 때문이라고 이해하고 있습니다.)
(그렇다고 주소 순으로 반환하는 정책이 왜 메모리 이용도에 도움이 되는지는 모르겠습니다.)
이융희(TA)
1개월 전
안녕하세요, 조교 이융희입니다.
확인해보니 영어 CS:APP 본문에도 각각 "some studies suggest that next fit suffers from worse memory utilization than first fit", "address-ordered first fit enjoys better memory utilization than LIFO-ordered first fit"이라고만 나와 있습니다. 결국 memory utilization은 프로그램이 메모리를 어떤 패턴으로 요청하는지에 따라 달라지기 때문에, 실제 프로그램을 실행시켜서 실험적으로 확인하는 것이 여러 policy들의 memory utilization을 비교하는 가장 정확한 방법입니다. 따라서 "실험적으로 프로그램을 실행시켜 봤더니 일반적으로 그렇다"고 이해하시면 될 것 같습니다. 관련된 자료 링크를 첨부해드립니다.
First-fit, Next-fit, Best-fit의 memory efficiency를 비교한 연구 자료 https://dl.acm.org/doi/pdf/10.1145/359436.359453
Explicit free list의 LIFO와 Address-ordered를 비교한 강의 자료 (pdf 33쪽 참고) https://ocw.snu.ac.kr/sites/default/files/NOTE/7163.pdf
그럼에도 불구하고, 직관적인 해석을 시도해 볼 수는 있을 것입니다. (이하는 제 개인적인 의견으로, 참고만 해주시기 바랍니다.)
Next-fit의 경우 first-fit에 비해 조그만 메모리 조각(splinter)들이 메모리 전체적으로 더 골고루 퍼져서 만들어져서 최종적인 memory utilization이 줄어들 수 있습니다.
Address-ordered Explicit free list의 경우 free block들이 연결되어 있는 모습을 보면 implicit free list와 같습니다 (이중 연결 리스트가 메모리 순서대로 놓여 있습니다). 따라서 LIFO Explicit free list에서 생기는 fragmentation이 생기지 않기 때문에 상대적으로 memory utilization이 높을 수 있습니다.
기재민
1개월 전
이해했습니다 답변 감사합니다!
기재민
1개월 전
혼자 설명해보려하니 아직 막히네요 ㅎㅎ.. “따라서 LIFO Explicit free list에서 생기는 fragmentation이 생기지 않는다” 이 부분에서 리포 때 생기는 단편화는 어떤 단편화이고 왜 생기지 않는 건지 추가 설명 부탁드립니다!
이융희(TA)
1개월 전
처음 질문에서 "가용 리스트의 앞부분에서 할당과 반환이 빈번하게 일어나다 보니 ..."라고 설명해주신 것처럼, LIFO에서는 free block들 중 특정한 구역이 주로 액세스되기 때문에 해당 메모리 구역이 더 잘게 쪼개져서 utilization이 떨어질 수 있을 것 같습니다. (참고만 해주시기 바랍니다!)
기재민
1개월 전
아아 제가 예시로 든 상황을 말씀 주신거군요! 감사합니다!
6
기재민
11월 16일, 오후 5:35
안녕하세요. priority-sema를 하는 중 궁금한 사항이 생겨서 질문 드립니다.
세마 다운에서 세마 웨이팅 리스트에 우선순위대로 정렬해서 넣었고, 임계구역에서 스레드가 작업을 한 뒤
세마 업을 하는 상황입니다. 이때 스레드가 waiters list에 있는 동안 우선순위가 변경 되었을 경우를 고려하여 waiters list를 우선 순위 기준으로 정렬을 해야하는 이유가 궁금합니다. 어떤 상황에서 정렬 되어있던 우선 순위가 꼬일 수 있나요? (정렬을 안해줘도 priority-sema를 통과하긴 합니다.)
https://oslab.kaist.ac.kr/wp-content/uploads/esos_files/courseware/undergraduate/PINTOS/Pintos_all.pdf 참고하고 있는 자료는 211쪽 입니다.
2개의 댓글
이융희(TA)
26일 전
안녕하세요, 조교 이융희입니다.
priority donation이 일어나서 waiting 중인 thread의 priority가 변할 수 있습니다.
MLFQS가 구현된 경우, 시간에 따라 각 thread의 priority가 변할 수 있습니다.
그러므로 sema_down 시점에 waiters에 정렬해서 넣었더라도, sema_up 시점에는 정렬되어 있지 않을 수 있습니다.
7
문규성
11월 16일, 오후 10:55
안녕하세요 조교님. 우선순위 기부(priority donate)를 구현하는 중에 질문이 생겼습니다.
structure thread 의 멤버로 struct list donations, struct list_elem donation_elem을 만들었습니다.
나보다 우선순위가 높은 thread의 donation_elem을 받아 해당 쓰레드의 우선순위를 받아오는 과정을 구현 한 후, 이 과정을 다시 보니 굳이 donation_elem이 아니더라도 기존에 만들어 놓았던 쓰레드의 elem을 사용하여도 우선순위를 가져오는 데 문제가 없다고 생각하여 donation_elem을 모두 elem으로 바꿔주었더니 이전까지 pass했던 것들이 fail합니다. 어떠한 이유에서 이런 것인지 궁금합니다.
2개의 댓글
이융희(TA)
26일 전
안녕하세요, 조교 이융희입니다.
list_elem은 리스트의 다음 원소와 이전 원소를 가리키는 포인터를 담은 구조체입니다. 즉 thread 구조체가 특정한 list의 원소로서 어떤 위치인지 나타내 줍니다. 그러므로 서로 다른 list에 대해서는 서로 다른 list_elem을 사용하여야 합니다. donation_elem은 donations list에 대한 소속을 나타내고, elem은 waiter list에 대한 소속을 나타내므로, 하나로 합칠 수 없습니다.
8
안녕하세요 조교님 Argument Passing 깃북 'Program Startup Details'을 읽다가 질문이 생겼습니다.
5번을 보면, 해당 스택 프레임은 다른 스택 프레임들과 같은 구조를 가져야 한다고 하는데, 가짜 리턴 주소를 push한 것이 왜 다른 스택 프레임과 같은 구조를 갖게 하는 것인지 궁금합니다.
(주말 오후에 질문 드려 죄송합니다 ㅠㅠ..)

박선호(TA)
22일 전
안녕하세요 조교 박선호입니다.
fake return address를 넣어야 하는 이유는, 함수를 실행한 측(caller)에서 함수를 실행하면 stack의 맨 아랫쪽에 자동으로 return address를 넣어주는 기능이 있는데, 프로그램에서 처음 실행되는 함수는 caller가 없어서 return address가 안 들어있으므로 커널이 직접 넣어줘야 합니다.
왜 굳이 stack frame과 같은 구조를 만들어줘야 하는지 이유를 간략하게 설명하자면, stack alignment 규칙에 따르면 함수가 실행된 직후(return address가 들어있는 상태)에 (%rsp + 8)이 16의 배수가 되어야 한다는 것이므로, 이 조건을 맞추기 위해 fake return address를 넣는다고 보시면 될 것 같습니다.
더 궁금한 점이나 이해가 안가는 부분이 있으면 편하게 질문 주세요 (편집됨)
9
문규성
11월 21일, 오후 1:55
조교님, System Calls 공부를 하다가 질문이 생겼습니다.
유저가 시스템콜 halt()를 호출한 이후,
syscall0 (SYS_HALT);를 호출하게 되고 함수 syscall을 호출하게 된다는 것 까지는 흐름을 잡았습니다.
그런데 syscall(아래 코드)에 들어와보면 인라인 어셈블리가 있는데, 어떤 어셈블리 파일로 연결되는지를 모르겠습니다.
__attribute__((always_inline))
static __inline int64_t syscall (uint64_t num_, uint64_t a1_, uint64_t a2_,
uint64_t a3_, uint64_t a4_, uint64_t a5_, uint64_t a6_) {
int64_t ret;
register uint64_t *num asm ("rax") = (uint64_t *) num_;
register uint64_t *a1 asm ("rdi") = (uint64_t *) a1_;
register uint64_t *a2 asm ("rsi") = (uint64_t *) a2_;
register uint64_t *a3 asm ("rdx") = (uint64_t *) a3_;
register uint64_t *a4 asm ("r10") = (uint64_t *) a4_;
register uint64_t *a5 asm ("r8") = (uint64_t *) a5_;
register uint64_t *a6 asm ("r9") = (uint64_t *) a6_;
__asm __volatile(
"mov %1, %%rax\n"
"mov %2, %%rdi\n"
"mov %3, %%rsi\n"
"mov %4, %%rdx\n"
"mov %5, %%r10\n"
"mov %6, %%r8\n"
"mov %7, %%r9\n"
"syscall\n"
: "=a" (ret)
: "g" (num), "g" (a1), "g" (a2), "g" (a3), "g" (a4), "g" (a5), "g" (a6)
: "cc", "memory");
return ret;
}추측컨대, userprog/syscall-entry.S로 이어지는 게 아닐까 싶은데 어떻게 이어지는지 잘 모르겠습니다..
3개의 댓글
이융희(TA)
22일 전
안녕하세요, 조교 이융희입니다.
추측하신 바와 같이 userprog/syscall-entry.S의 syscall_entry flag로 이어지는 것이 맞습니다. 적으신 어셈블리에 있는 syscall 어셈블리 명령어는 시스템 콜 핸들러를 호출하는 특별한 명령어로, 미리 등록한 시스템 콜 헨들러로 점프하고 user mode에서 kernel mode로 전환하는 등 시스템 콜을 처리할 수 있도록 해 줍니다. userprog/syscall.c의 syscall_init 함수와 그 위에 있는 주석을 참고해주세요.
System call.
Previously system call services was handled by the interrupt handler
(e.g. int 0x80 in linux). However, in x86-64, the manufacturer supplies
efficient path for requesting the system call, the `syscall` instruction.
The syscall instruction works by reading the values from the the Model
Specific Register (MSR). For the details, see the manual.10
신종우 (정글 5기)
11월 21일, 오후 2:42
안녕하세요 조교님. printf() 관련해서 질문이 있습니다.
1. pintos에서 사용되는 printf() 는 모두 lib/stdio.c 의 printf() 가 아니라, glibc 의 printf()인 건가요? pintos의 printf()를 사용하려면, #include "lib/stdio.h" 가 있어야 할 것 같은데, 프로젝트를 전부 검색해도 #include <stdio.h> 만 확인할 수 있었습니다.
2. printf()는 내부 구현에서 write()를 호출하는 것으로 알고있습니다. printf() -> vprintf() -> vprintf() 순으로 호출이 되는 것은 확인했는데, vprintf()내부에서 write()를 호출하는 부분은 없는 것 같습니다. pintos의 printf()는 제가 구현할 시스템 콜 write()를 호출하지 않는 건가요?
4개의 댓글
이융희(TA)
21일 전
안녕하세요, 조교 이융희입니다.
lib/stdio.c의 것이 맞습니다. 컴파일러 설정으로 인해 표준 라이브러리 include가 lib 폴더의 함수들을 참조하도록 컴파일됩니다.
구현하실 system call write()를 호출하는 것이 맞습니다.
신종우 (정글 5기)
21일 전
컴파일러 설정은 예상 못했었네요! 답변 감사합니다.
2번 질문에 대해서 추가 질문이 있는데요. 제 생각에는 __vprintf() 내부에서 write()를 호출해야 할 것 같은데, 명시적으로 write() 를 호출하는 것을 확인하지 못하였습니다. 혹시 다른 방법으로 호출한다거나, 아니면 다른 함수에서 write()를 호출하는걸까요?
이융희(TA)
21일 전
정확히 말하면, pintos의 printf는 두 가지입니다.
user program을 컴파일할 때는 printf가 lib/user/console.c의 vprintf를 참조합니다. 이 함수가 실행되면, 결국 lib/user/console.c 의 flush 함수에서 lib/user/syscall.c의 write 함수를 호출하고, 이것이 system call을 일으킵니다. system call을 받은 kernel은 이것을 출력해야 합니다.
kernel을 컴파일할 때는 printf가 lib/kernel/console.c의 vprintf를 참조합니다. 이 함수가 실행되면 말씀하신 것처럼 __vprintf가 호출되고, 여기에 전달된 함수 포인터로 vprintf_helper가 호출되어 결국 serial_putc와 vga_putc를 통해 화면에 글자가 나타나게 됩니다.
따라서 user program이 호출한 printf는 구현하실 write system call을 호출하지만, kernel이 호출한 printf는 system call과 상관없습니다 (Project 1에서 printf가 작동했던 이유입니다).
신종우 (정글 5기)
21일 전
상세한 답변 감사합니다! user program과 kernel을 구분해서 컴파일하는 것은 생각 못했었네요. 개념 잡는데 많은 도움이 되었습니다
11
오유진 (정글 5기)
오후 5:04
조교님 안녕하세요! argument passing 부분 관련해서 질문을 드립니다.
현재 process_exec() 내에서 직접 argument를 파싱할 때는 문제 없이 테스트를 통과하는 상황입니다. 테스트 통과를 확인하고 나서 argument 파싱 부분을 별도의 함수로 분리했더니 커널패닉이 나는데 도저히 이유를 잘 모르겠어서 질문을 남깁니다. 인자 전달이 잘 안된건가 해서 process_exec에서_if.rsp 주소를 프린트해보고, 새 함수에서도 똑같이 주소를 프린트해보았더니 둘다 동일한 주소 값을 가지고 있는데 문제가 생기는 이유를 모르겠습니다..! 아래 답글로 기존 코드들을 함께 올리겠습니다. 혹시 놓치고 있는 부분이 있을까요 ?
이융희(TA)
20일 전
안녕하세요, 조교 이융희입니다.
직접적인 코드 디버깅은 도와드리고 있지 않은 점 알려드립니다. 다만 call-by-value와 call-by-reference를 검색해보시면 도움이 될 듯 합니다.
12
이강욱 (정글5기)
11월 22일, 오후 8:25
안녕하세요. threads/intr-stubs.S 를 읽다가 여쭤보고 싶은 것이 생겨 질문을 드립니다.
해당 파일의 68 번째 line부터 시작하는 주석에 대해서, 72번째 line을 읽어보면
It also puts the address of each of these functions in the correct spot in `intr_stubs', an array of function pointers.
라고 되있는 부분이 있는데, 해당 내용에 대한 코드는 어디있는 건가요..?? threads/intr-stubs.S 와 threads/interrupt.c 에서는 연관되는 부분을 찾지 못했습니다.
2. 일단 1번의 내용이 잘 구현되어 있는 상태라고 가정하고 인터럽트가 발생한다면,
발생한 인터럽트의 vec_no에 해당하는 gate를 IDT 에서 확인한 후, 해당 gate에 등록된 intrNN_stub (e.g. intr0e_stub) 함수를 실행하게 되고, 해당 함수에서 결국 intr_entry로 jump 하게 된다고 이해하였는데, 이 과정이 맞는건가요..?
3. 앞서 언급 드렸던 68번 line에서 시작하는 주석을 보면,
"frame_pointer in struct intr_frame" 이나 "%ebp" 등의 내용들이 현재 pintos-kaist 와 맞지 않는 것 같습니다.
(https://github.com/uchicago-cs/pintos/blob/master/src/threads/interrupt.h#L19-L56)
혹시 제가 놓친 부분이 있는지 궁금합니다.
답변 부탁드립니다. 감사합니다!
interrupt.h
/* Interrupt stack frame. */
struct intr_frame
{
/* Pushed by intr_entry in intr-stubs.S.
These are the interrupted task's saved registers. */자세히 표시
https://github.com/uchicago-cs/pintos|uchicago-cs/pintosuchicago-cs/pintos | 봇이 추가한 GitHub
4개의 댓글
박선호(TA)
20일 전
안녕하세요 조교 박선호입니다.
1. threads/intr_stubs.S 의 103번째 줄부터 보시면 .global intr_stubs 로 시작하는 영역이 있는데, 이것이 intr_stubs라는 global variable에 들어갈 데이터를 적어놓은 것입니다. 이 밑에서부터 쭉 STUB(NUMBER, TYPE) 와 같은 구문을 쭉 써놓음으로써 intr_stubs라는 전역변수를 직접 초기화하는 것 같습니다.
2. 네 맞게 이해한 것 같습니다.
3. 강욱님이 지금 사용하고 계신 repo가 제가 사용한 거랑 좀 다른 것 같습니다. https://github.com/casys-kaist/pintos-kaist/blob/master/include/threads/interrupt.h#L19 여기 보시면 제대로 64비트 아키텍처의 경우에 동작할 수 있도록 적혀 있습니다.
혹시 더 궁금한 점이나 이해 안되는 점이 있으면 편히 질문주세요
interrupt.h
struct gp_registers {
https://github.com/casys-kaist/pintos-kaist|casys-kaist/pintos-kaistcasys-kaist/pintos-kaist | 봇이 추가한 GitHub
이강욱 (정글5기)
20일 전
감사합니다!
3번에 대한 질문은
https://github.com/casys-kaist/pintos-kaist/blob/master/threads/intr-stubs.S#L68
에서 주석이 잘못된 것이 아닌가 하는 질문이었습니다..!
intr-stubs.S
/* Interrupt stubs.
https://github.com/casys-kaist/pintos-kaist|casys-kaist/pintos-kaistcasys-kaist/pintos-kaist | 봇이 추가한 GitHub
박선호(TA)
20일 전
아 그 질문이었군요. 확인해보니 말씀하신 대로
1. Push %ebp on the stack (frame pointer in struct intr_frame).
이 문장에 해당하는 부분은 현재 pintos-kaist에서는 더이상 사용되지 않는 부분인 것 같고, 잘 발견하셨습니다. 그러니 %ebp를 저장한다는 내용을 제외하고 나머지 내용을 읽으시면 될 것 같습니다.
13
김다엘 (정글 5기)
:jungledael_on_fire_faster: 11월 22일, 오후 11:57
안녕하세요. process.c의 process_exec()에서 실행되는 do_iret함수 (2번째 사진 참고관련해서 궁금한 사항이 있어 질문드립니다.
do_iret 함수를 통해 intr_frame if에 있던 데이터들이 레지스터에 저장되고 if->rip인 e_entry(3번째 사진 참고)가 레지스터의 rsp에 저장되는 것으로 이해하였습니다.
이후 실행되는 iretq함수를 실행되면 레지스터의 rsp에 저장된 주소로 이동(1번째 사진 참고)하는 것으로 이해하였습니다.
해당 내용을 맞게 이해한 것인지 궁금하고 또 load함수에서 if->rip를 e_entry로 지정(3번째 사진)하였는데, 해당 주소가 어디와 연결되는 것인지 궁금합니다.
https://files.slack.com/files-pri/T01FZU4LB4Y-F04C3UPGDMJ/image.png
https://files.slack.com/files-pri/T01FZU4LB4Y-F04C1C39GJX/image.png
https://files.slack.com/files-pri/T01FZU4LB4Y-F04BLUNKC87/image.png
2개의 댓글
{kind=link}
{kind=link}
{kind=link}
박선호(TA)
20일 전
안녕하세요 조교 박선호입니다.
사실 사진으로 올려주신 링크가 접속할 수 없어서 사진을 볼 수 없지만, if->rip 가 rsp 에 저장되어 그곳으로 점프하는 것은 아닙니다.
do_iret 함수 내에서는 https://github.com/kingdoctor123/pintos-kaist/blob/master/include/threads/interrupt.h#L40~L52 내에 저장된 값을 레지스터에 집어넣고, 현재의 rsp 값을 적절하게 변환시킵니다. 그 후 iretq 명령어를 실행시키면 하드웨어가 자동으로 if->rip, if->cs, ..., if->__pad8 까지의 데이터를 적절한 레지스터에 집어넣은 후 rip 레지스터에 담긴 위치로 점프하는 역할입니다.
e_entry 는 elf 형식의 바이너리 파일에서 응용 프로그램이 처음 시작되어야 하는 명령어의 위치가 담겨있습니다 (entry point 라고 불립니다) entry point에서 명령어가 실행되어서 간단한 셋업을 한 후 흔히 아는 main() 함수가 자동적으로 호출되어서 응용프로그램이 본격적으로 시작합니다.
더 궁금한 점이나 이해 안가는 부분이 있으면 편히 질문 주세요
14
오유진 (정글 5기)
11월 26일, 오전 1:26
안녕하세요 조교님!
유저 프로그램 실행에 사용되는 initd 함수를 보면 process_init (); 로 process_init이라는 함수가 호출되는데 이 함수의 정의를 보면 현재 실행중인 스레드를 저장하는 부분만 있습니다. 혹시 이 부분이 어떤 역할을 하는걸까요~?!?!
/* General process initializer for initd and other process. */
static void
process_init (void) {
struct thread *current = thread_current ();
}2개의 댓글
박선호(TA)
17일 전
안녕하세요 조교 박선호입니다.
process_init은 프로세스가 처음 만들어질 때 여러 가지 정보를 초기화하는 곳으로, 앞으로 과제하면서 초기화가 필요한 데이터를 여기서 초기화하시면 됩니다. 또한, 아직은 프로세스 생성하는 경우가 제한적이라 initd에서만 process_init()을 호출하지만, 앞으로 프로세스를 만들거나 복제할 때가 생기면 필요에 따라 process_init()을 적절히 호출해서 초기화 작업을 하시면 됩니다.
더 궁금한 점이 있으면 편히 추가 질문 주세요.
15
기재민
11월 26일, 오전 10:39
안녕하세요. fork를 구현할 때 두 가지 인터럽트 프레임 구조체가 있더군요. 하나는 thread parent가 가지고 있는 인터럽트 프레임 구조체 “tf” 가 있고 다른 하나는 시스템콜 헨들러가 processfork에게 인자로 넘기는 인터럽트 프레임 구조체 “f”가 있습니다. 둘 다 인터럽트 프레임 구조체인데 같지는 않은 것 같아서 각각의 역할에 대해 문의드립니다.
1. 둘이 같지 않다는 것을 알게 된 계기를 먼저 말씀드리면
_do_fork() 함수에서
struct intr_frame *parent_if = &parent->tf;
memcpy (&if, parentif, sizeof (struct intr_frame));
do_iret (&if);
으로 thread parent가 가지고 있는 인터럽트 프레임 구조체 “tf” 를 자식에게 복사해서 do_iret하면 아래와 같은 에러가 발생하고 아래 사진과 같은 에러가 뜹니다.
대신에 struct intr_frame *parent_if = &parent->tf; 이 부분에서 부모의 인터럽트 프레임 tf가 아니라 시스템콜 헨들러가 인자로 보낸 인터럽트 프레임 “f”를 parent_if라고 하고 그걸 자식에게 복사하면 fork-once테스트를 통과합니다. 이를 보고 부모의 인터럽트프레임 tf와 시스템콜 헨들러의 f가 같지 않다는 것을 알게 되었습니다.
2. 첫 번째로 궁금한것은
제가 자식에게 부모의 인터럽트 프레임을 넘겨줘야겠다고 생각한 이유는 포크가 부모를 복사하는거니까 ‘부모의 인터럽트프레임을 넘겨줘야지’ 라고 생각했기 때문입니다. 제 생각이 틀린 이유가 궁금합니다.
부모가 가지고 있는 인터럽트 프레임에는 어떤 정보가 있는지요. 그리고 그 인터럽트 프레임을 자식에게 넘겨줘야한다 vs 넘겨주면 오히려 안된다 vs 넘겨주든 말든 상관 없다 중 무엇인지요.
3. 두 번째로 궁금한 것은
결론적으로 시스템콜헨들러가 넘겨준 인터럽트 프레임을 자식이 복사하고 이를 활용해 do_iret 해야 테스트를 통과하는데 시스템콜 헨들러가 넘겨준 인터럽트 프레임은 누구(?)의 정보이고 어떤(?) 정보를 갖고 있는지 궁금합니다.
누구인지가 궁금한 이유는 (지금의 짧은 제 지식으로 볼 때) 포크로 생긴 자식 프로세스가 부모의 인터럽트 프레임 말고 다른 인터럽트 프레임을 복사하는데 대체 부모말고 누구의 것을 복사하는 것인지가 궁금해서 입니다. 비슷한 맥락으로 시스템콜이 인자로 넘기는 인터럽트 프레임 f에는 어떤 정보가 들어있는 건지도 궁금합니다. (편집됨)

6개의 댓글
박선호(TA)
17일 전
안녕하세요 조교 박선호입니다.
"부모의 인터럽트 프레임을 넘겨줘야지" 하는 생각 자체는 맞습니다. 다만 더 정확하게 말하자면 "부모의 user-level 정보가 담긴 인터럽트 프레임"을 넘겨줘야하고, 이건 f에 저장되어 있습니다. 인터럽트 프레임에는 무슨 정보가 담겨 있는지 질문을 주셨는데, 여기에는 실행할 때 사용하는 정보(주로 레지스터의 값)가 백업되어 있습니다.
tf는 부모 프로세스가 fork()를 수행하던 도중 context switch가 일어나서 다른 스레드가 실행이 될 경우, tf에는 fork()를 수행하던 커널이 어디까지 작업했는지 정보가 저장됩니다 (threads/thread.c의 thread_launch() 함수 참고). 하지만 f는 user-level에서의 부모 프로세스가 실행되던 정보가 항상 담겨있습니다. fork()해서 만든 자식 프로세스는 부모 프로세스의 user-level 정보를 이어받아 user-level에서 실행을 마저 해야하므로, f를 복사하는 것이 맞습니다.
이해가 안되거나 더 궁금한 점이 있으시면 편하게 질문 주세요. (편집됨)
기재민
16일 전
답변감사합니다.
가이드북에선가 fork에 대한 힌트로 “부모 스레드는 자식이 완전히 fork될 때까지 기다려야한다“는 문구를 본적이 있습니다.
process_fork 함수 내 tid_t pid = thread_create(name, PRI_DEFAULT, do_fork, parent);
를 분기로 한 개만 있던 스레드가 2개(fork-once인 경우)가 되려고 하는데, 이때 가이드북 힌트대로 부모 스레드가 자식은 만들어지지도 않았는데 먼저 cpu의 선택을 받아 실행되어 return pid하고 끝나버리는 경우를 막아야한다고 알고있습니다. (부모를 재워야함)
do_fork에서 제가 했던 잘못처럼 f를 복사하지 않고 tf를 복사하면 이때의 tf는 return pid하기 하지 않기 위해 부모 스레드가 잠들기 직전 정보를 자식에게 넘긴 꼴이 되는건지요? 아님 do_fork를 하는 순간인 tid_t pid = thread_create(name, PRI_DEFAULT, do_fork, parent); 까지 부모 스레드가 실행하고 있던 정보를 자식에게 넘긴 것이 되는건가요? 즉 제가 잘못 복사한 tf가 어느 시점에 쓰여진 tf인지 궁금합니다! (편집됨)
박선호(TA)
16일 전
tf를 복사하면 말씀하신 대로 return pid하지 않기 위해 부모 스레드가 잠들기 직전 정보를 자식에게 넘긴 꼴이 될 수도 있고, 그 전에 scheduler에 의해 context switch가 일어나면 그 전의 정보가 자식에게 넘어갈 수도 있습니다. thread_create의 구현에 따라 다를 수 있지만, 부모 thread는 반드시 그 순간에 잠들어 있을 것이고, 그 직전에 실행되던 정보가 저장되어 있습니다. (편집됨)
16
문규성
11월 30일, 오후 3:35
조교님 안녕하세요, 카이스트 깃북 Project 3: Virtual Memory을 읽다가 질문이 생겨 연락드립니다.
1. Introduction에서의 include/devices/block.h, devices/block.c 파일
2. Anonymous Page에서 (page.h 파일)
Also, see the struct page in include/vm/page.h, which contains generic information of a page. Note, for an anonymous page, struct anon_page anon is included in its page structure.
라는 부분을 보았을 때, block.h, page.h 파일을 Pintos 상에서는 찾을 수가 없는데 이 부분을 저희가 구현 해야하는 걸까요?
이융희(TA)
12일 전
안녕하세요, 조교 이융희입니다.
매뉴얼이 업데이트가 안 된 것 같네요... block. 대신 같은 경로의 disk.를, page.h 대신 같은 경로의 vm.h 로 생각해주시면 될 것 같습니다.
17
문규성
12월 1일, 오후 4:08
조교님 안녕하세요, exception.c에 있는 static void page_fault()를 공부하다가 질문이 생겼습니다.
bool not_present; /* True: not-present page, false: writing r/o page. */
bool write; /* True: access was write, false: access was read. */제가 이해한 바로는, not_present를 통해 true라면 존재하지 않는 페이지에 접근하려고 하여 page fault가 발생한 것이고, false라면 read only 페이지에 쓰기를 하여 발생한 page fault라고 생각하였습니다.
그런데 바로 그 아래 bool write; 가 있어서 헷갈리는 부분이 있습니다. 앞서 말한 bool not_present의 false인 경우와 write가 true인 경우의 발생한 에러가 다른 것인지 궁금합니다.
2개의 댓글
박선호(TA)
11일 전
안녕하세요 조교 박선호입니다.
두 개 변수를 독립적인 변수라고 보시면 더 쉽게 이해하실 수 있을 것 같습니다.
not_present: 접근한 메모리의 physical page가 존재하지 않은 경우
write: page fault를 일으킨 명령어가 write일 경우
이 경우에, not_present = true 이면 physical page가 없어서 page fault가 일어난 경우가 맞을 것이고, not_present = false이면 접근한 메모리의 physical page가 존재하지만 page fault가 일어났으므로 그 경우는 소거법에 의해 read-only page에 write를 한 경우가 될 것입니다. 그러므로 주석에 설명이 저렇게 적힌 것입니다.
이렇게 보시면 not_present = false 이면 write = true가 성립한다는 사실은 명백할 것이고, not_present = true 이면 write는 true이거나 false 둘 중 아무거나 되어도 된다는 사실도 알 수 있습니다.
더 궁금한 점이나 이해 안되는 점이 있으면 편하게 추가 질문 주세요
18
문준호(정글5기)
12월 1일, 오후 5:27
조교님 안녕하세요,
코드의 에러 확률과 관련된 질문이 생겨서 글을 올리게 되었습니다.
일정 확률로 page fault가 발생하는데, 확률이 미미하다면 이 코드를 그대로 사용해도 되는지에 대한 질문입니다.
Project 2에서 저희가 구현한 코드로 make check를 돌려봤을 때 All 95 tests passed 를 여러 번 받았기 때문에 잘 동작하는 코드라고 생각했었습니다.
이번 project 3에서 사용할 코드를 project 2 코드 위에 빌드해야 하기 때문에 project 2에서의 저희의 코드를 최종 확인하던 와중,
syn-read에서 page fault가 발생한다는 사실을 알게 되었습니다.
이 page fault는 lock_acquire 에서 발생하며 (특히 lock donation 관련 list에 list_push_back을 할 때), 그리고 평균적으로 테스트를 20번 돌렸을 때 한 번 꼴로 발생합니다.
syn-read에서만 오류가 나는 것을 볼 때, 자식 프로세스를 동시에 여러 개 만들고 file read를 시도하면서 lock_acquire를 자주 호출하는 tough한 케이스에서는 어떤 동시성 이슈가 간혹 생겨서 잘못된 포인터를 참조하는 상황이 생기는 것 같습니다.
이렇듯 tough한 case에서 낮은 확률로 fail하는 코드를 project 3에서 그대로 사용해도 괜찮은지가 궁금합니다…
더불어, 원래 정상적으로 동작하는 코드라도 낮은 확률로 page fault가 발생할 가능성이 있는지도 궁금합니다!
2개의 댓글
박선호(TA)
11일 전
안녕하세요 조교 박선호입니다.
제 조언은 그 코드에 버그가 있음이 확실하므로, 버그를 미리 수정하시길 추천드립니다. 대부분의 경우에 잘 작동하지만 아주 가끔이라도 에러가 관찰되면 그 코드 자체에 허점이 존재한다는 뜻이며, 굉장히 낮은 확률로 버그가 발생하는 이유는 operation이 특정 패턴으로 실행되었을 때 일어난다는 말인데 그 패턴이 scheduling policy나 timer interrupt가 일어나는 타이밍에 영향을 받기 때문입니다. 현재는 잘 관찰되지 않다고 하더라도 lab3나 lab4를 수행하시며 수많은 테스트케이스를 돌리다 보면 그 패턴이 자주 사용되는 경우가 있을 수가 있고, 이 경우에 디버깅 하기 매우 어려워집니다.
나중에 오류의 원인을 찾지 못해서 한참 고생하게 될 수 있으니 (제 경험담입니다...) lock 구현과 같이 비교적 초반에 구현하는 기능들은 완전히 잘 동작하는 것을 확실하게 보장하고 넘어가시길 추천드립니다.
19
오유진 (정글 5기)
12월 2일, 오전 12:34
안녕하세요! 페이지 할당기 부분에서 언급되는 유저풀과 커널풀은 가상 메모리영역에서 논리적으로 구분되는 영역인지, 물리 메모리의 영역인지 질문드립니다!
palloc_get_page 함수를 보면 ” Obtains a single free page and returns its kernel virtual address.” 라고 되어있는 것을 보면 가상메모리의 ‘페이지’를 할당한다고 생각되어 커널풀/유저풀이 가상메모리상의 공간이라고 생각되었는데, 그렇다면 이들은 어디에 존재하고 있는건지에 대해 궁금합니다!
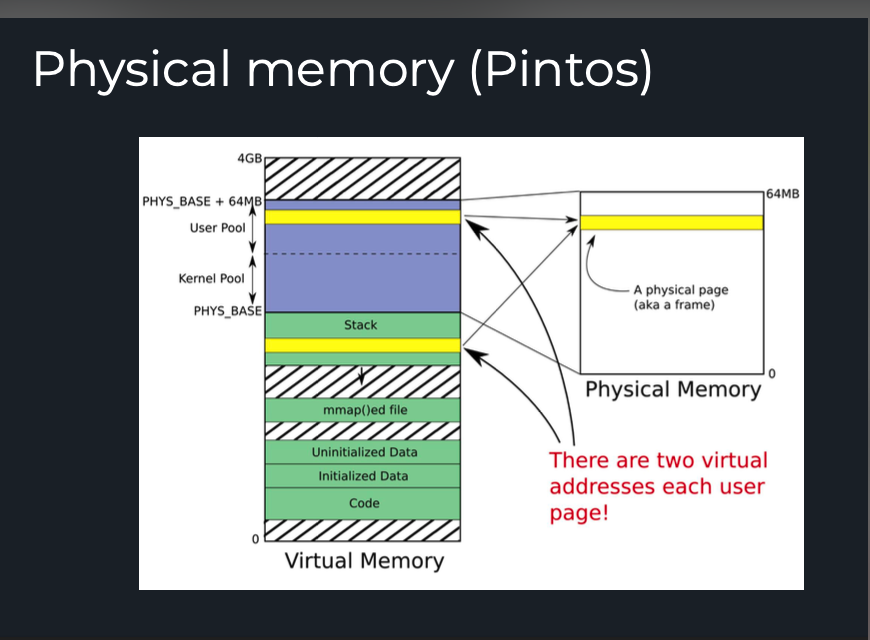
5개의 댓글
박선호(TA)
11일 전
안녕하세요 조교 박선호입니다.
user pool과 kernel pool은 물리 메모리에서 나뉘는 메모리 영역입니다. Pintos의 경우 전체 physical memory를 50:50으로 나누어서 user pool과 kernel pool로 지정해 놓았습니다.
"Obtains a single free page and returns its kernel virtual address"에서 "kernel virtual address"를 설명하려면 우선 pintos에서 virtual memory를 설명해야 합니다. 그림에 보이듯이 virtual memory에서 KERN_BASE (PHYS_BASE라고 보이는데 이것은 구버전 pintos 기준입니다) 위의 영역은 커널만 접근할 수 있는 virtual address이며, 이 부분의 매핑은 (virtual address) - KERN_BASE = (physical address) 라는 매우 단순한 1:1 매핑이 되어 있습니다. 그러므로 palloc.c에 적혀 있는 설명에서 returns its kernel virtual address 라는 말은, physical address에서 KERN_BASE 만큼 더한 값을 리턴한다는 뜻이고, 그러므로 page in/out이 필요한 virtual page를 할당하는 것이 아니라 바로 접근이 가능한 physical page를 할당해준다고 생각하시면 됩니다.
이해가 안 가거나 더 궁금한 점이 있으면 편히 추가 질문 주세요.
최다봄(정글5기)
11일 전
조교님 안녕하세요. 말씀해주신 내용 중에 "page in/out이 필요한 virtual page를 할당한다"는 부분에 대해 추가로 궁금한 부분이 생겨서 질문 드립니다.
1. page in/out이 swap in/out을 말씀하시는건지 궁금합니다.
2. palloc_get_page()로 physical page를 할당해준다고 하셨는데 그렇다면 virtual page라는 것을 어떻게 할당이 되는 것인지 궁금합니다.
항상 빠르고 친절한 답변 감사합니다.
박선호(TA)
11일 전
@최다봄(정글5기)
넵 맞습니다. 같은 말입니다.
그것은 lab3에서 구현하셔야 할 일입니다. virtual page는 말 그대로 "가상의" page 이므로, pintos 내의 어딘가에 특정 프로세스가 virtual page를 할당했다는 사실을 저장할 수 있는 구조체 (supplemental page table)를 만들어서 거기에 virtual page의 존재 여부를 기록하시는 것이 virtual page를 할당하는 것입니다. 어디까지나 "가상의" page이므로 실제로 접근 가능한 "physical" page를 할당하는 것과는 별개라는 사실에 주의하시면 좋을 것 같습니다.
20
이강욱 (정글5기)
12월 2일, 오후 4:24
안녕하세요 조교님 !
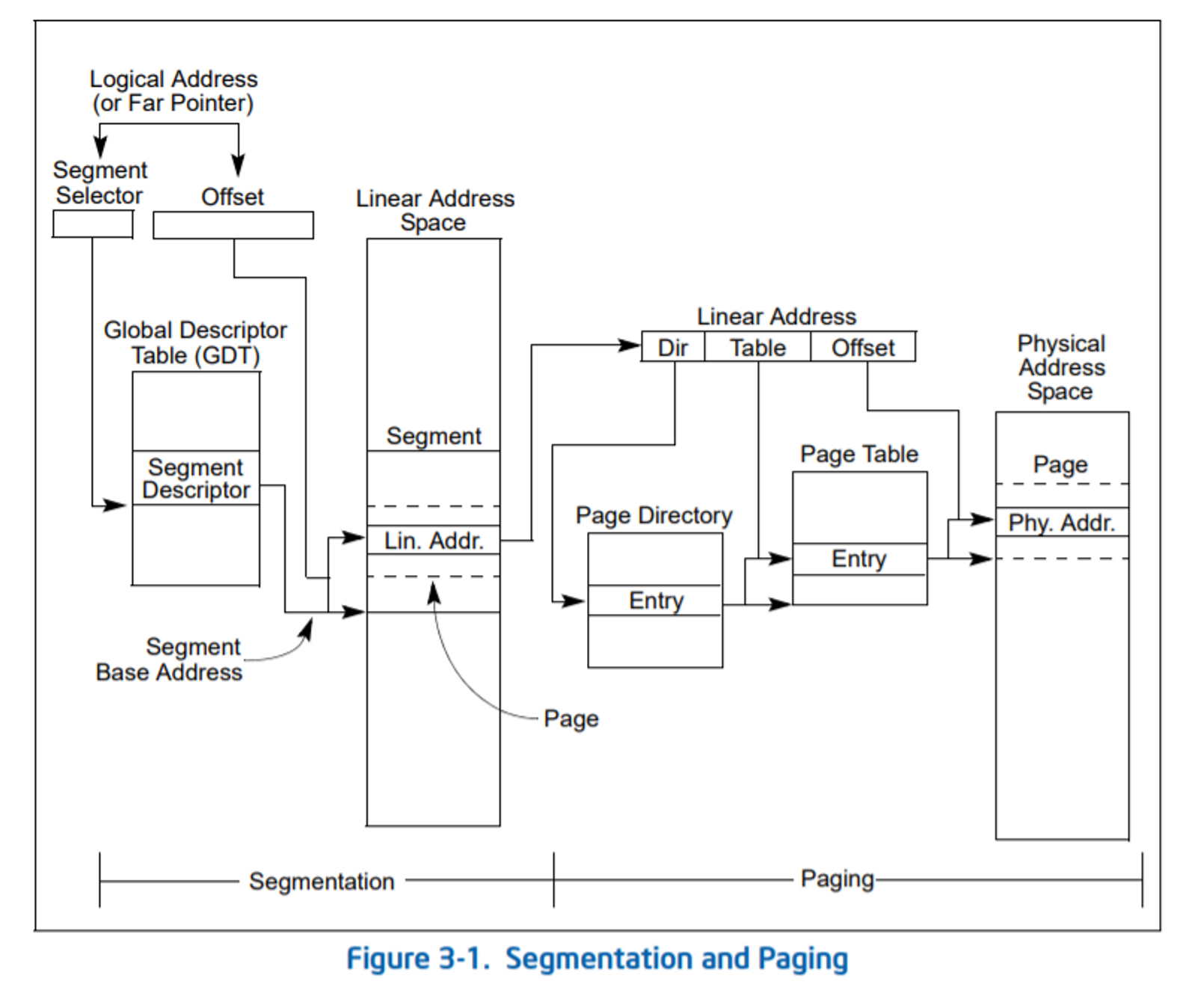
Segment Selector를 살펴보다가 궁금한 점이 생겨 질문을 드립니다.
첫 번째 그림에서 보면, Segment register에 저장된 Segment Selector를 통해 GDT에서 해당 Segment의 BaseAddress를 확인하고 Offset을 더해 Linear Address를 계산하고 있는데, 이 과정이 언제 일어나는 것인가요??
저희가 지금 다루고 있는 virtual memory의 address는 결국 Linear Address 인 건가요??
구글링을 통해(http://egloos.zum.com/anster/v/2135644) 두 번째 그림을 보게 되었는데, 한 segment의 최대 크기가 4GB가 된다면, 현재 가상주소에서 사용되는 256TB(48bit) 와 큰 차이가 나는 것 같아 잘 이해가 가지 않습니다.
답변 부탁드립니다 감사합니다!!!
2개 파일

egloos.zum.comegloos.zum.com
Memory Management : Segmentation 1
2011년 6월 16일 (22kB)
http://egloos.zum.com/anster/v/2135644
3개의 댓글
이융희(TA)
10일 전
안녕하세요, 조교 이융희입니다.
어떤 자료를 보고 계신지는 모르겠으나 x86_64 CPU에서 64비트 코드를 실행시킬 때는 segmentation이 주소 변환 역할을 하지 않습니다.
x86 CPU에서 32비트 코드를 실행하거나, x86_64 CPU에서 32비트 코드를 호환 모드로 실행할 때는 segmentation이 의미를 가집니다. 그러나 pintos-kaist에서는 이 부분을 고려하실 필요가 없습니다.
몇 가지 메모리 보호 메커니즘을 위해 GDT에 있는 정보가 사용되기는 하는데, 이 부분은 pintos-kaist가 다루는 범위 밖에 있습니다.
따라서 x86_64에서 virtual address == linear address입니다.
32bit CPU에서 최대로 이용할 수 있는 메모리가 4GiB라는 점을 생각해보면 당연한 제한사항입니다.
참고자료:
https://nixhacker.com/segmentation-in-intel-64-bit/
https://stackoverflow.com/q/57222727
Nixhacker - The Reverser's SpaceNixhacker - The Reverser's Space
Segmentation in Intel x64(IA-32e) architecture - explained using Linux
In this article we will go through Segmentation in basic and cover it for x64 (IA-32e) processors by extracting the details inside a Linux system.
Written by
Shubham Dubey
Filed under
Intel architecture, Firmware, Linux, Analysis
2020년 2월 21일
https://nixhacker.com/segmentation-in-intel-64-bit/
Stack OverflowStack Overflow
Is segmentation completely not used in x64?
In x86, when you want to access a memory address, you would specify an address that would be translated into a memory address through two stages: segmentation, and paging:
But is segmentation also...
21
유병수 (정글 5기)
12월 4일, 오후 5:04
조교님 안녕하세요! load_segment 쪽 코드를 보다가 질문이 생겨서 이렇게 질문 남깁니다.
load_segment로 파일을 읽을때는 파일 전체를 읽는게 아닌가요?
USERPROG 의 첫번째 테스트 (args-none)의 경우 file_length로 찍어본 파일 안의 비트는 51,312 이지만 load_sement에서 읽는 총 read_byte는 19738 이고 zero_byte는 742 라서 합이 20480 으로 차이가 있습니다. load_segment 에서 읽어 보는 정보는 어떤 정보인가요?
load_segment에서 마지막에 read_byte는 0이고 zero_byte가 4096인 페이지를 두번 읽는데, 이 페이지의 용도는 무엇인가요? lazy_load_segment에서 zero_byte 부분에 memset으로 0을 채워주는데, page_fault로 연결되어 무한 루프에 빠지고 있습니다.
동기들과 얘기해본바로 데이터를 읽는 것은 프로세서의 code영역이고 zero_byte로 이루어진 두페이지는 스택과 힙 영역으로 생각되는데 맞나요?
답변 부탁드립니다. 감사합니다
5개의 댓글
박선호(TA)
8일 전
안녕하세요 조교 박선호입니다.
CS:APP책에 실려 있듯이 응용 프로그램들은 ELF format에 맞게 저장되어 있으므로 pintos의 load()에서는 ELF format을 적절하게 읽어옵니다. ELF format을 보면 ELF header이나 .debug와 같은 메모리에 로드되지 않지만 ELF에는 존재하는 영역이 있습니다. 이런 부분은 load_segment를 통해 메모리를 할당하지 않을 것이고, 또한 .bss와 같은 uninitialized segment같은 경우는 파일에 세그먼트 헤더만 있지 내용은 없지만 메모리는 할당해 줍니다. 그러므로 단순히 응용프로그램의 크기와 load_segment에서 읽은 용량은 같지 않을 수 있습니다.
zero_byte로 이루어진 페이지는 스택과 힙 영역이라고 보기는 어렵습니다. 우선 pintos에서 스택 영역은 setup_stack()함수를 통해 직접 할당해줍니다. 힙 영역도 user program이 malloc을 통해 메모리를 할당할 때마다 필요에 따라 메모리를 할당하므로, 스택 영역과 마찬가지로 elf 파일로부터 읽어오는 정보는 아닙니다. 다만 zero_byte만으로 이루어진 페이지들로 가능한 후보를 생각하면 .bss 영역에 들어가는 정보가 생각나네요. uninitialized global variable이나 uninitialized static variable 등이 이 영역에 들어가며, 초기값이 중요하지 않으므로 elf 파일에는 값이 지정되어 있지 않으나 메모리 할당은 해줘야하므로 zero_byte = 4096으로 할당이 될 것입니다.
더 궁금한 점이 있으면 편하게 질문 주세요. (편집됨)
유병수 (정글 5기)
8일 전
추후에 궁금하게 생기면 더 여쭤보겠습니다 감사합니다!
유병수 (정글 5기)
8일 전
프로그램이 ELF format을 실제로 읽을때,(do_iret) 실제로 frame을 연결해주고 lazy_load 가 동작해서 안에 데이터를 써줍니다. zerobyte로 할당받은 va를 요청했을때, frame을 할당해주고 0으로 채워주었습니다. 둘다 frame이 할당되고 데이터가 들어간 것도 hex_dump를 통해서 확인했습니다. 그런데도 page_fault가 나는 경우가 있나요…? ELF format을 읽을때는 잘동작하다가 zerobyte로 채워준 부분은 계속 page_fault가 떠서 감이 안잡힙니다
박선호(TA)
8일 전
아마 frame을 할당한 후 page table에 등록하는 과정에서 문제가 생겼다거나 하는 가능성이 있는데, 에러의 원인이 무궁무진해서 정확하게 추측하기 어려운 점 양해 부탁드립니다. printf와 gdb를 활용하여 잘 해결하시길 바랍니다.
22
최창훈(정글5기)
12월 4일, 오후 6:58
안녕하세요 조교님
유저프로그램 실행 후 lazy_load_segment()가 실행되는 순서가 궁금하여 질문드립니다!
load_segment에서 uninit으로 유저페이지를
400000, 401000, 402000, 403000, 404000, 604000, 605000 할당하였습니다.
유저프로그램이 400000을 요청하여서 다음에는 401000을 요청할 줄 알았지만 (첫 PageFault요청) 이후 605000을 요청하였습니다. 유저프로그램의 행동방식을 어떻게 알 수 있을까요? (편집됨)
1개의 댓글
박선호(TA)
8일 전
안녕하세요 조교 박선호입니다.
한 프로세스 내에서 page fault가 일어나는 행동양상은 page fault가 일어나는 순서를 관찰하면 파악할 수 있습니다. 실제 운영체제에서는 스택의 위치가 프로그램을 켤 때마다 조금씩 바뀐다던가 하는 차이가 있지만 pintos에서는 그런 작업은 하지 않으므로 동일한 프로그램은 같은 순서로 page fault가 일어날 것입니다.
물론 fork()를 통해 여러 가지 프로세스가 실행되면 여러 개의 프로세스에서 동시에 page fault가 일어날 것이고, 이 때는 scheduling의 방식에 따라 미묘하게 page fault가 일어나는 양상이 달라지며, 일어나는 순서는 정해진 순서가 없기 때문에 이 경우에는 행동방식을 파악하기 어렵습니다.
답변이 도움이 되었길 바라며, 더 궁금한 점이 있으면 편하게 질문 주세요.
23
박경준 (정글 5기)
12월 5일, 오후 11:03
안녕하세요 조교님 질문이 있어서 연락드립니다.
프로그램이 process_exec 실행 시점에는
process_clean함수에서 SPT가 kill 되고 init되는데 load할 때 vm_alloc_page_with_initalizer에서 SPT를 찾았을때 null 값이 아닌 poge가 존재할 수 있는지 궁금합니다.
2개의 댓글
박선호(TA)
7일 전
안녕하세요 조교 박선호입니다.
process_cleanup()에서 supplemental_page_table_kill()을 하면 spt 상의 모든 mapping이 사라져야 하고, 그 이후 load()이 호출되어 응용 프로그램을 불러올 때까지 계속 커널 모드에서 실행되므로 spt는 아무 정보를 담고 있지 않고 있으므로 vm_alloc_page_with_initializer에서 null이 아닌 page를 spt로부터 찾아서 return false를 하는 상황은 예상하기 어려울 것 같습니다.
더 궁금한 점이 있으면 편하게 추가 질문 주세요.
24
이강욱 (정글5기)
12월 8일, 오전 10:05
안녕하세요 조교님 !
test 방법 관련해서 질문드리고 싶은게 있습니다.
pintos-kaist/tests/vm/Rubric.functionality 과 pintos-kaist/tests/vm/Rubric.robustness 파일을 보면, 프로젝트 내의 목차 별로 해당하는 test case들을 명시해주고 있는데, 혹시 이 목차 단위로 test를 실행할 수 있는 방법이 따로 있는건가요?? 아니면 그냥 text 파일에 불과한건가요..?
답변 부탁드립니다...! 감사합니다 (편집됨)
2개의 댓글
박선호(TA)
5일 전
안녕하세요 조교 박선호입니다.
말씀해주신 파일을 보기엔 단순한 텍스트 파일인 것 같으며, 적혀 있는 목차 별로 테스트를 따로 돌리는 방법은 따로 없는 것 같습니다. Linux shell script를 따로 짠다던가 하는 방식으로 목차 단위로 테스트를 실행하게 할 수도 있지만, 현재로써는 전체 테스트케이스를 모두 실행한다던가 아니면 개별 테스트케이스를 한개씩 진행하는 것이 전부인 것 같습니다.
더 궁금한 점이 있으면 편하게 추가 질문 주세요.
25
이강욱 (정글5기)
12월 8일, 오후 8:15
안녕하세요 조교님 !
mmap test 관련해서 궁금한게 있습니다.
유저 프로그램이 동일한 파일을 여러 번 open() 해서 각각 얻어진 fd로 동일한 파일에 여러 번 mmap()을 하는 test case는 존재하는 것 같은데,
유저 프로그램이 하나의 fd로 같은 파일에 대해 여러 번 mmap() 을 하는 경우도 따로 고려해야 하나요..??
답변 부탁드립니다...! 감사합니다
2개의 댓글
박선호(TA)
4일 전
안녕하세요 조교 박선호입니다.
그 경우도 고려해야 하는 것 같습니다. Linux mmap manual (https://man7.org/linux/man-pages/man2/mmap.2.html) 을 살펴보았을 때 동일한 fd로 열었을 때 에러가 발생한다는 얘기는 적혀 있지 않기도 하고, 그리고 gitbook을 읽어보아도
Closing or removing a file does not unmap any of its mappings. Once created, a mapping is valid until munmap is called or the process exits, following the Unix convention. See Removing an Open File for more information. You should use the file_reopen function to obtain a separate and independent reference to the file for each of its mappings.
이라고 적혀 있는데, mmap된 메모리는 기존 fd과 독립적으로 동작해야 한다고 적혀 있으므로 하나의 fd로 여러번 mmap을 하는 behavior는 허용해야 할 것 같습니다.
더 궁금한 점이 있으면 편하게 질문 주세요.
26
이강욱 (정글5기)
12월 9일, 오전 12:39
조교님 안녕하세요... ! loader.S 와 관련해서 여쭤보고 싶은 점이 있습니다.
제가 이해한 바로는, 현재의 loader setting 상으로는 CR0 레지스터의 PW bit가 set되지 않아서
kernel mode 일 때 페이지 테이블의 write-protect bit의 제한을 받지 않는 것 같은데,
특별히 이러한 setting을 적용하는 이유가 있나요..??
제가 사실 실수로 kernel code에서 read-only인 page에 계속 write를 하고 있었는데, 이 접근이 제한되지 않아 해당 사실을 인지하지 못하고 있었습니다.
문제가 없다면 loader.S 를 조금 수정해서 디버깅에 활용하고자 하는데 다른 test에 문제가 없을지 궁금합니다.
참조한 코드 부분 : https://github.com/casys-kaist/pintos-kaist/blob/master/threads/loader.S#L155
loader.S
Then we turn on the following bits in CR0:
https://github.com/casys-kaist/pintos-kaist|casys-kaist/pintos-kaistcasys-kaist/pintos-kaist | 봇이 추가한 GitHub
3개의 댓글
박선호(TA)
4일 전
안녕하세요 조교 박선호입니다.
커널이 write-protect bit 제한을 받지 않고 쓸 수 있도록 설계된 이유는 커널이 메모리 전체를 관리할 수 있어야 하기 때문일 것이라고 어렴풋이 생각은 드는데, 정확히는 잘 모르겠네요. 검색해도 잘 안나오던데,
@이융희(TA)
조교님은 알고 계신가요?
loader.S를 수정해본 적이 없어서 해도 되는지 안되는지는 잘 모르겠지만 해서 문제가 되지 않는다면 상관없을 것 같긴 합니다. 하지만 이 파일을 수정하는 것은 보통 권장되지 않습니다.
일단은 제가 말씀드릴 수 있는 것은 여기까지인 것 같습니다. 도움이 되셨기를 바랍니다.
p.s. 보통 lab3에서 커널 코드를 작성하실 때 user virtual address로 메모리 접근을 하기보다 kernel virtual address 으로 접근을 많이 할 것이고, 이 kernel virtual address는 writeable=true로 page table에 매핑이 저장되어있는데, cr0에서 wp bit을 설정하는 것이 크게 도움이 될 지는 잘 모르겠습니다. (편집됨)
이융희(TA)
4일 전
안녕하세요, 조교 이융희입니다.
커널은 유저 프로세스들의 supervisor입니다. user에게 read-only인 page도 supervisor는 필요하다면 읽고 쓸 수 있어야 합니다 (예시: lazy loading의 .text 영역). 그렇기 때문에 일반적으로는 WP bit가 set되어 있지 않습니다.
그런데 Copy on write를 구현하게 되면 사실은 read/write여야 하는 page가 read-only로 설정되어 있어서, supervisor mode에서도 이 영역에 쓰게 될 경우 PF를 일으키는 것이 편리한 경우가 있습니다. 리눅스에서는 이 경우를 처리하기 위해 WP bit을 set해 주고 있습니다.
loader.S를 수정하는 것은 권장드리지 않습니다. 다른 많은 기존 구현에 문제가 생길 수 있기 때문입니다.
참고자료: https://stackoverflow.com/q/15275059
Stack OverflowStack Overflow
whats the purpose of x86 cr0 WP bit?
in x86 CPU, there is control register number 0.
the 16'th bit of this register indicates "Write Protection" setting.
if this bit is cleared, CPU is able to overwrite Read Only data.
(configured in ...
27
문준호(정글5기)
12월 9일, 오후 11:25
조교님 안녕하세요!
Stack Growth 구현 중, page-merge-stk 케이스에서 막히는 부분이 있어서 질문 드립니다.
저는 page fault가 발생했을 때 stack growth 상황인지 확인하는 조건을
if (rsp - 8 == fault_address) 와 같은 형식으로 확인했습니다.
(스택포인터에서 8바이트 아래 지점을 확인하므로, 8바이트 아래 지점이 fault 발생 지점이면 stack growth 상황이라고 생각했습니다)
이 방법으로 대부분의 테스트 케이스는 통과했습니다.
그런데 page-merge-stk에서는 fault가 발생한 address가 rsp + 12 지점이었습니다.
(관련 이미지 첨부드립니다)
왜 rsp - 8 지점이 아닌 rsp + 12 지점에서 page fault가 발생하는지가 궁금합니다!
ps. 관련해서 제가 생각해본 가설이 있는데 맞는지도 봐주시면 감사하겠습니다!!
가설1. stack pointer가 word-size에 alignment 된 것이다.
정확한 근거는 없지만, rsp를 16으로 나눠 봤을때의 결과값을 보고 추론해 보았습니다…
rsp: 0x4745ff70 == 1195769712 (%16 == 0)
rsp-8: 0x4745ff68 == 1195769704 (%16 == 8)
faulted in: 0x4745ff7c == 1195769724 (%16 == 12)가설2. page fault가 발생한 시점과 intr_frame에 rsp가 저장되는 시점 사이에서, 어떤 이유로 인해 rsp가 감소했다. (i.e. synchronization issue…)

2개의 댓글
박선호(TA)
3일 전
안녕하세요 조교 박선호입니다.
이걸 설명하기 위해서는 어셈블리 코드에서 스택에 값을 어떻게 집어넣는지 방식을 설명해야 합니다.
pushq로 집어넣기: 예를 들어, pushq $rax 명령어를 실행하면, rsp-8위치에 $rax를 집어넣음과 동시에 rsp를 8 감소시킬 것입니다. 그러므로 page fault가 일어나면 rsp - 8 = fault_address 가 성립합니다 (pushq가 아직 종료되지 않았으므로 rsp의 값은 변경되기 전입니다.)
pushq로 집어넣지 않는 경우: 보통 스택에 배열을 할당할 때는 pushq로 집어넣지 않습니다. 그 대신, 우선 rsp를 조정하여 배열을 위한 충분한 공간을 마련하고, 그다음에 rsp+12, rsp+8, rsp+4, rsp+0 위치에 각각 데이터를 쓰는 방식을 적용합니다. 이때는 rsp+12에 page fault가 일어날 수 있습니다.
대부분의 테스트케이스에서는 pushq만 사용했지만 문제가 발생한 테스트케이스에서는 후자의 방법을 사용한 것이라고 판단할 수 있겠습니다. 참고로 가설1과 가설2는 모두 아닌 것 같습니다. 가설1같은 경우 stack pointer의 alignment는 callq 하기 전에만 맞춥니다. 가설2의 경우에는 fault나 interrupt가 발생할 시 하드웨어에 의해 atomic하게 저장됨이 보장됩니다.
도움이 되었길 바라며, 추가로 궁금한 점이 있으면 편하게 질문 주세요. (편집됨)
28
이강욱 (정글5기)
12월 10일, 오후 7:11
조교님 안녕하세요..!
pintos 부팅 시의 메모리 할당에 관해 궁금한 점이 있습니다.
kernel code 영역과 bss 영역에 대한 메모리 할당은 언제 이루어지나요? (해당 영역을 위한 palloc_get_page() 호출을 찾지 못했습니다.)
palloc.c 의 populate_pools() 에서, 물리 메모리 전체를 반으로 나누어 각각을 user pool, kernel pool으로 지정해놓는 것으로 알고 있는데,
여기에서 '물리 메모리 전체' 라는 영역의 크기를 확인해 보니( base_mem 과 ext_mem 를 통해 확인하였습니다.),
test 수행 시의 설정인 20MB가 아닌, 20MB 에서 513KB 가 모자란 값으로 사용되고 있는 것 같습니다.
제가 추측으로는, 0x9fc00 ~ 0x100000 사이의 385KB 와, 0x13e0000 ~ 0x1400000 사이의 128KB 가 이 차이에 해당하고,
해당 차이에 kernel code 영역과 bss영역을 포함해 loader와 같은 부팅 시 필요한 영역들이 포함되어 있다고 생각했습니다.
이 차이에 해당하는 것이 맞는 것인가요? 추가적으로 base_mem 과 ext_mem 이 메모리 상에서 어떤 의미를 갖는 값들인지 궁금합니다...
감사합니다..!!!

박선호(TA)
2일 전
안녕하세요 조교 박선호입니다.
pintos의 code영역을 포함한 커널 정보는 0x20000~0x9ffff까지의 영역에 할당된다고 합니다. (첨부해주신 이미지에서 base_mem은 0x9fc00까지이므로 이 경우에서는 0x2000~0x9c00까지의 범위 내에 모두 저장될 듯 합니다.) 또한 base_mem 영역에는 loader나 kernel code를 포함하여 컴퓨터 운영에 필수적인 기본 정보가 담겨 있고, ext_mem은 커널이 자유롭게 메모리 할당을 해서 (palloc 같은 방식으로) 사용할 수 있는 영역인 것 같습니다.
더 자세한 내용은 https://web.stanford.edu/~ouster/cgi-bin/cs140-spring20/pintos/pintos_6.html 이곳에서 확인하실 수 있습니다. 여기에 들어가 보시면 부팅하는 과정을 굉장히 자세히 적어 놓았고, 메모리 레이아웃에 대한 설명도 잘 나와 있습니다.
도움이 되셨기를 바랍니다. 추가로 궁금한 점이 있으면 편히 질문 주세요.
web.stanford.eduweb.stanford.edu
Pintos Projects: Reference Guide
Pintos Projects: Reference Guide
29
이강욱 (정글5기)
어제, 오후 5:04
안녕하세요 조교님!
swap-fork test case 에 대해서 궁금한 점이 있습니다.
제가 이해한 바로는 test가 수행되면 현재 10 개의 자식 thread가 생성되고,
각 thread 별로 5MB 씩의 메모리를 읽으면서 swap이 제대로 되고 있는 지를 확인하고자 하는 test 인 것 같은데,
자식 thread의 소스코드에 CHUNK_SIZE 가 1MB 로 설정되어 있는 것 같습니다.
어느 값이 맞는 건가요..? 감사합니다.
해당 소스 코드
https://github.com/casys-kaist/pintos-kaist/blob/master/tests/vm/swap-fork.c#L10
https://github.com/casys-kaist/pintos-kaist/blob/master/tests/vm/child-swap.c#L15
(편집됨)
swap-fork.c
https://github.com/casys-kaist/pintos-kaist|casys-kaist/pintos-kaistcasys-kaist/pintos-kaist | 봇이 추가한 GitHub
child-swap.c
https://github.com/casys-kaist/pintos-kaist|casys-kaist/pintos-kaistcasys-kaist/pintos-kaist | 봇이 추가한 GitHub
4개의 댓글
박선호(TA)
9시간 전
안녕하세요 조교 박선호입니다.
코드를 읽어보면 1MB의 메모리만을 이용하여 테스트를 진행하는 것을 확인할 수 있습니다. 주석에 적힌 5MB라는 정보가 잘못된 것 같습니다.
도움이 되었기를 바랍니다. 추가 질문 있으면 편하게 해주세요.
이강욱 (정글5기)
9시간 전
사실 제가 질문 드린 이유는 make tests/vm/swap-fork.result 를 입력하면 발생하는 명령어가
pintos -v -k -T 600 -m 40 --fs-disk=10 -p tests/vm/swap-fork:swap-fork -p tests/vm/child-swap:child-swap --swap-disk=200 -- -q -f run swap-fork
인데, 옵션과 같이 메모리가 40MB 이고, 유저 pool에 해당하는 영역이 20MB 정도 된다고 했을 때,
10개의 thread가 1MB 씩 작업을 한다고 하면 swap이 발생하지 않게 되는 것 같습니다.
(실제로 swap 과정에 들어오는지 출력을 시도했지만, 해당 출력이 발생하지 않았습니다.)
박선호(TA)
9시간 전
swap-fork 라는 테스트케이스의 이름으로부터 추측하건대 이 테스트케이스는 단순히 swap 메커니즘의 동작 여부를 테스트하기 보다는 fork후에 swap영역에 읽거나 쓸 때 제대로 동작하는지를 테스트하기 위함이지 않을까 싶습니다. 특히 copy-on-write를 구현하면 fork할 경우 page를 바로 duplicate하지 않고 이를 write가 발생할때까지 미뤄야 하는데, fork한 다음 10개의 child process에서 write를 함으로써 이 과정이 잘 동작하는지 테스트하는 것 같습니다.
만약 이 테스트케이스로 swap과정이 잘 통과하는지 보고 싶으시다면 명령어를 수정하여서 메모리를 줄이는 방식을 사용하시면 될 것 같습니다. (편집됨)
