LLM이란
대규모 언어 모델(LLM)은 다양한 자연어 처리(NLP) 작업을 수행할 수 있는 딥러닝 모델이다.
Closed Source
- OpenAI의 GPT-3, GPT-3.5, GPT-4
- Google의 PALM, LaMDA, Bard
장점 : 뛰어난 성능, API 방식의 편리한 사용성
단점 : 보장할 수 없는 보안, API 호출 비용 → 기업에서 사용하기 어려움 (기업 기밀 유출, API 과금 이슈)
Open Source
- Llama 계열의 LLM - LLaMA, vicuna, Alpaca, LLaMA2, upstage-llama2
- 그외 Open-source LLM - MPT-7B, WizardLM
장점 : Closed source 못지 않은 성능, 높은 보안성, 낮은 비용
단점 : 개발 난이도 높음, 사용 위한 GPU 서버 필요
ChatGPT의 문제점
- 정보 접근 제한
-
ChatGPT(GPT-3.5)는 2021년까지의 데이터를 학습한 LLM이므로, 2022년 이후 정보는 답변을 하지 못하거나 거짓된 답변을 제공한다.
→ Vectorstore 기반 정보 탐색 or Agent 활용한 검색 결합
-
- 토큰 제한
-
GPT-3.5 : 4096, GPT-4 : 8192 입력 토큰 제한 존재
→ TextSplitter를 활용한 문서 분할
-
- 환각현상
-
Fact에 대한 질문을 했을 때, 엉뚱한 대답을 하거나 거짓말을 하는 경우가 많다.
→ 주어진 문서에 대해서만 답하도록 Prompt 입력
-
ChatGPT 개량
- Fine-tuning : 기존 딥러닝 모델의 weight를 조정하여 원하는 용도의 모델로 업데이트
- e.g. 블룸버그의 블룸 (금융전문)
- 기존 아키텍처를 사용 용도에 맞게 미세 조정 (한번 더 학습 필요 - 학습하는데 드는 그래픽카드, 시간 등을 고려해야함 → 고비용)
- GPT의 Encoder 구조를 가진 BERT를 미세조정하여 감성 분류 모델로 활용
- N-shot Learning : 0개~n개의 출력 예시를 제시하여, 딥러닝이 용도에 알맞은 출력을 하도록 조정
- In-context Learning : 문맥을 제시하고, 이 문맥 기반으로 모델이 출력하도록 조정
- 어떤 분야에 대해 깊이있게 대화 필요할 때 유용
- LangChain은 In-context Learning의 도구이다.
LangChain의 개념
오픈소스
LangChain : 언어 모델로 구동되는 어플리케이션을 개발하기 위한 프레임워크
- 데이터 인식 : 언어 모델을 다른 데이터 소스에 연결
- 에이전트 기능 : 언어 모델이 환경과 상호작용할 수 있도록 (동향 파악 요청 → 알아서 인터넷 검색해서 반환)
언어 모델을 잘 활용할 수 있게끔 도와줌
LangChain의 구조
- LLM : 초거대 언어모델로, 생성 모델의 엔진과 같은 역할을 하는 핵심 구성 요소
- e.g. GPT-3.5, PALM-2, LLAMA, StableVicuna, WizardLM, MPT
- Prompts : 초거대 언어모델에게 지시하는 명령문
- 요소 : Prompt Templates, Chat Prompt Template, Example Selectors, Output Parsers(원하는 형식의 대답으로 설정 가능 - 맑음, 맑습니다 등)
- Index : LLM이 문서를 쉽게 탐색할 수 있도록 구조화하는 모듈
- e.g. Document Loaders, Text Splitters, Vectorstores, Retrievers,
- Memory : 채팅 이력을 기억하도록 하여, 이를 기반으로 대화가 가능하도록 하는 모듈
- e.g. ConversationBufferMemory, Entitiy Memory, Conversation Knowledge Graph Memory
- Chain : LLM 사슬을 형성하여, 연속적인 LLM 호출이 가능하도록 하는 핵심 구성 요소
- e.g. LLM Chain, Question Answering, Summarization, Retrieval Questioin/Answering
- prompt를 여러 개 사슬처럼 구성
- e.g. LLM Chain, Question Answering, Summarization, Retrieval Questioin/Answering
- Agents : LLM이 기존 Prompt Template으로 수행할 수 없는 작업을 가능케하는 모듈
- e.g. Custom Agent, Custom MultiAction Agent, Conversation Agent
- Agent에 들어가는 툴이 다양 → 웹 검색, SQL쿼리작성 등
- 여러가지 툴을 LLM이 자체적으로 판단해서 구동
LangChain 작동 원리
- 문서 업로드
- Document Loader
- 컨플루언스, 노션 페이지 업로드도 가능
- 답변이 어떤 파일에 어떤 페이지에서 가져온건지 파악 가능
- 문서 분할
- Text Splitter
- PDF 문서를 여러 문서로 분할
- 문서 임베딩
- Embed to Vectorstore
- 임베딩 : LLM이 이해할 수 있도록 문서 수치화
- 임베딩 검색
- VectorStore Retriever
- 질문과 연관성이 높은 문서 추출
- 답변 생성
- QA Chain
- 질문과 연관성이 높은 문서 추출
- 질문에 대한 가장 유사한 텍스트를 가져와 프롬프트1 생성 → 챗지피티에게 줘서 프롬프트2 생성 → 챗지피티에게 줘서 답변 생성
Document Loaders
문서 불러오기, 다양한 형태의 문서(PDF, Word, YouTube etc.)를 RAG 전용 객체로 불러들이는 모듈이다.
다양한 형식의 문서를 불러오고 이를 LangChain에 결합하기 쉬운 테스트 형태로 변환하는 기능을 한다. 이를 통해 사용자는 txt 형식의 문서 뿐만 아니라 pdf, word, ppt, xlsx, csv 등 거의 모든 형식의 문서를 기반으로 LLM을 구동할 수 있다.
- Page_content : 문서의 내용
- Metadata : 문서의 위치, 제목, 페이지 넘버 등
DocumentLoader 종류
-
URL Loader : WebBaseLoader와 UnstructuredURLLoader
-
PDF Document Loader : PyPDFLoader
-
Word Document Loader : docx2txt
-
CSV Document Loader : CSVLoader
-
csv_args 설정 필요
- delimiter : 데이터 구분자
- quotechar : '"’ (묶어야 하는 string을 처리할 때 사용된다. 예를 들어 "Hello, python"과 같은 문자열은 delimiter가 콤마로 되어있는 경우, "Hello"와 "python"으로 나뉘어 지는데 이를 방지할 수 있다.)
- fieldnames : column
Text Splitters
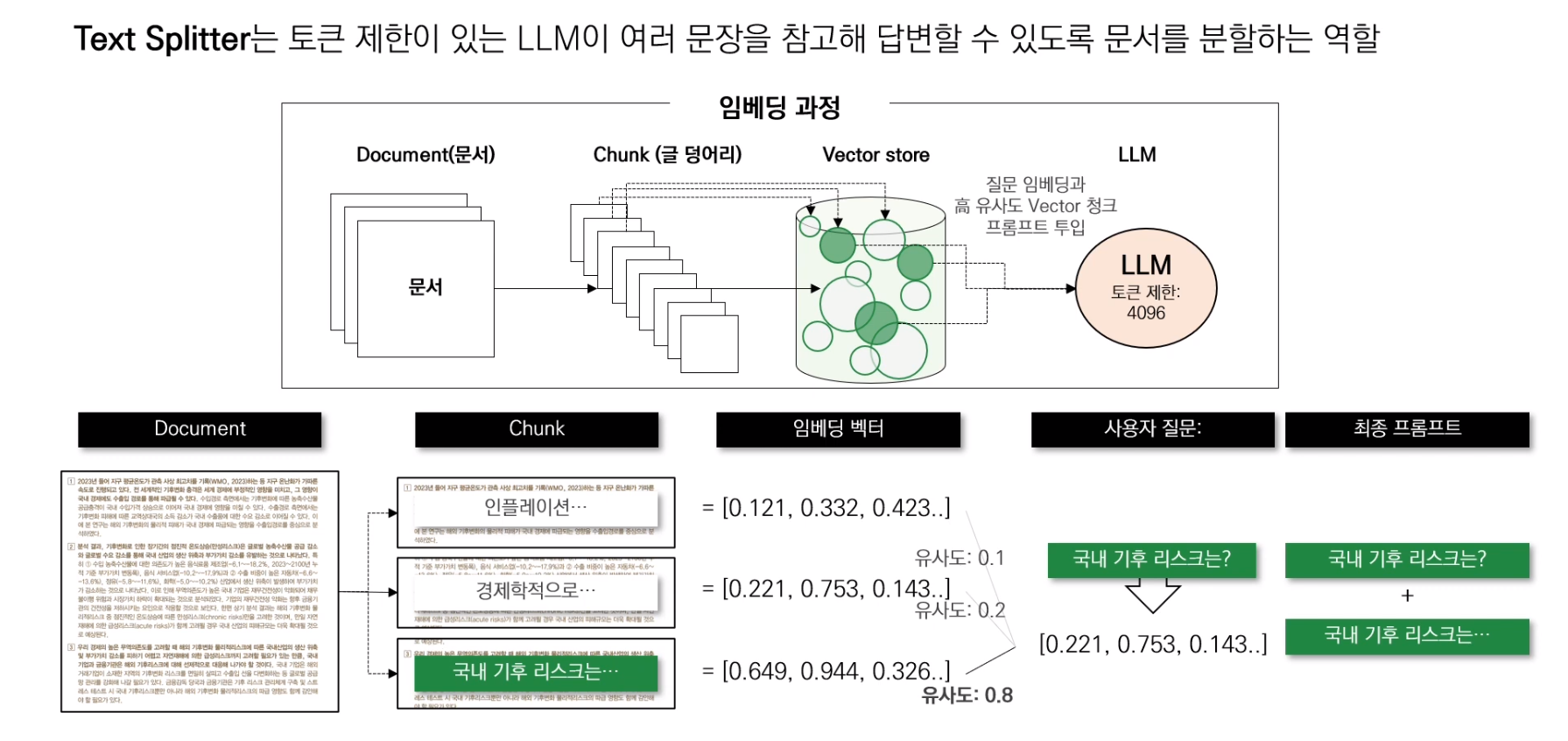
문서 텍스트 분할하기, 토큰 제한이 있는 LLM이 여러 문장을 참고해 답변할 수 있도록 문서를 분할하는 역할이다.
Document를 여러 개의 Chunk로 쪼개고, Chunk를 embedding vector로 만들고, vector store에 저장해준다. Chunk 하나당 하나의 Vector로 매칭된다.
특정 기준을 통해 텍스트를 청크로 나누는 모듈이다. 토큰 제한 이슈를 우회하여 Context를 학습시킬 수 있다.
Chunk 사이즈를 어떻게 할지, 어떻게 Chunking 할지가 중요하다.
- CharacterTextSplitter
- 구분자 1개 기준으로 분할하므로 max_token을 지키지 못하는 경우 발생
- 매개변수
- separator : 구분자
- chunk_size : 원하는 chunk의 사이즈
- chunk_overlap : 이전 chunk의 일부를 overlap
- 이전 chunk와 연결되는 내용이라면, context가 끊기지 않도록 하기 위해
- length_function : chunk_size의 기준
- e.g. len → 글자 수
- RecursiveCharacterTextSplitter
- 구분자 리스트를 기준으로 재귀적으로 분할하므로, max_token 지켜 분할
- 구분자 리스트 : 줄바꿈, 마침표, 쉼표
- 줄바꿈 기준 분할 → max_token 초과 → 마침표 기준 분할 → max_token 초과 X → 분할 완료
- 구분자 리스트를 기준으로 재귀적으로 분할하므로, max_token 지켜 분할
→ 대부분 RecursiveCharacterTextSplitter를 통해 분할
일반적인 글로 된 문서는 모두 TextSplitter로 분할할 수 있으며, 대부분 커버 가능하다.
그러나 코드, latex 등과 같이 컴퓨터 언어로 작성되는 문서의 경우 TextSplitter로 처리할 수 없으며, 해당 언어를 위해 특별하게 구분하는 Splitter가 필요하다.
예를 들어, Python 문서를 split하기 위해서는 def, class와 같이 하나의 단위로 묶이는 것을 기준으로 문서를 분할할 필요가 있다. 이러한 원리로 latex, HTML, 코드 등 다양한 문서도 분할할 수 있다.
- langchain.text_splitter의 Language 모듈을 import
- RecursiveCharacterTextSplitter에 Language를 매개변수로 분할 가능
RecursiveCharacterTextSplitter.from_language(language=Language.PYTHON)Vector Embeddings
Vector Embedding 형태로 저장하기 위해 Embedding 모델을 거쳐 수치화된 텍스트 데이터들을 Vector Store에 저장한다.
Text Embeddings는 텍스트를 숫자로 변환하여 문장 간의 유사성을 비교할 수 있도록 한다.
사용자 질문을 수치로 변환하는 것도 포함한다.
대부분의 경우 대용량의 말뭉치를 통해 사전학습된 모델을 통해 쉽게 임베딩한다.
비정형 데이터를 숫자로 변환해 좌표상에 위치할 수 있게 만들어주는게 임베딩 모델이다.
사전 학습 임베딩 모델에는 대표적으로 Open AI에서 제공하는 ada 모델과, HuggingFace의 모델들이 있다. 사용 목적과 요구사항에 따라 적절한 임베딩을 고르는 것은 RAG의 가장 중요한 부분이다.
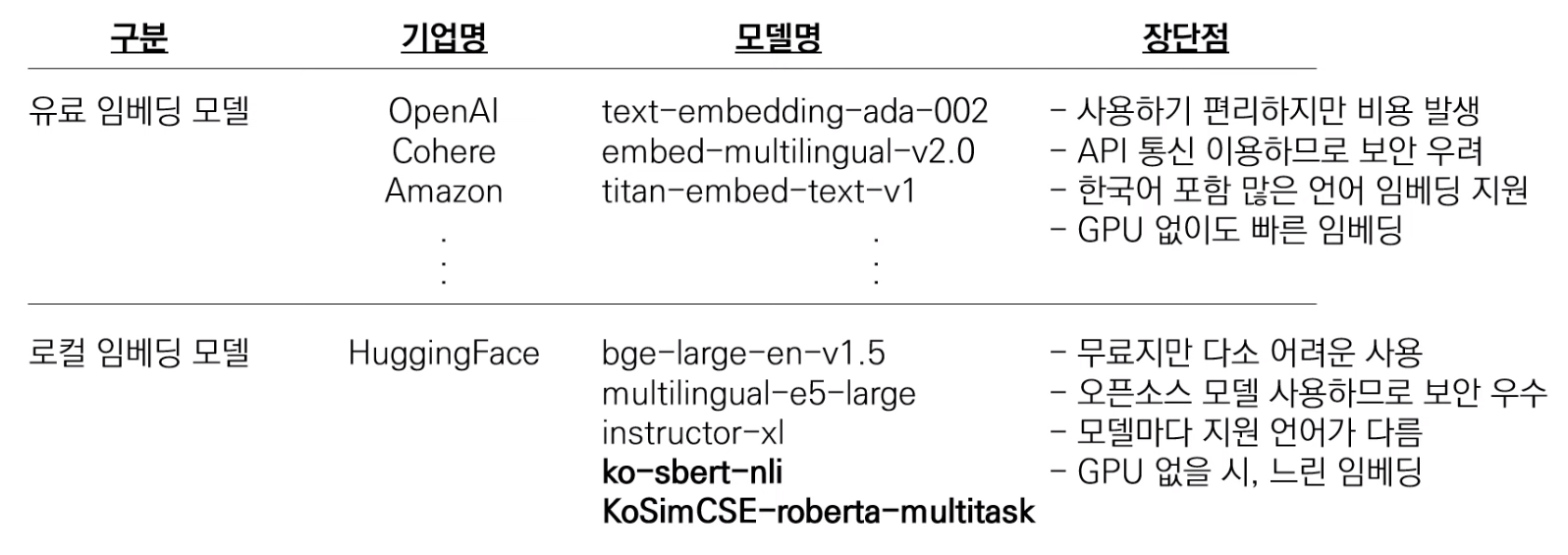
한국어 임베딩 성능 좋은 모델 : ko-sbert-nli, KoSimCSE-roberta-multitask
Vectorstore
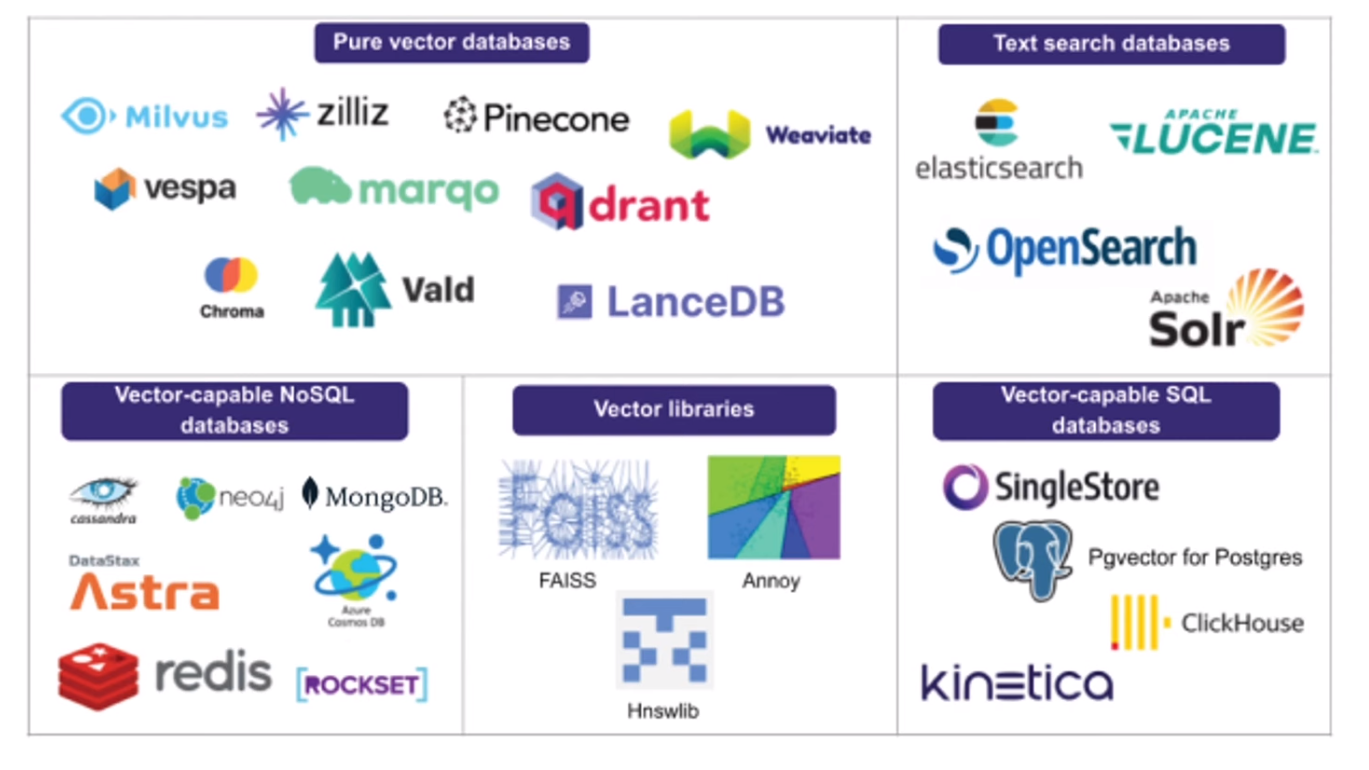
Retrieval 안에서 RAG에 임베딩된 값들을 저장하는 벡터 저장소이다. 벡터 저장소는 임베딩된 데이터를 인덱싱하여, input으로 받아들이는 query와의 유사도를 빠르게 출력한다. 대표적으로 FAISS, Chroma가 존재한다. CRUD와 같은 일반적인 DB의 기능을 포함한다.
Retrievers
사용자의 질문과 가장 유사한 문장을 검색하는 역할이다.
사용자의 질문을 임베딩 모델을 통해 임베딩시키고 임베딩된 벡터를 벡터 저장소 안에 있는 여러 text chunk vector와 비교해 가장 유사한 벡터를 뽑아 context로 넘기고, 사용자의 질문과 함께 프롬프트로 엮어 llm에게 넘겨주는 역할이다.
어떤 매개변수를 어떻게 설정해주는지, 어떤식으로 사용자 질문에 대처하는지 잘 수행하도록 만들어야 한다.
[참고자료]
LangChain 뿌시기
LLM 어플리케이션 개발을 위한 LangChain 소개
LangChain GitHub
