그래서 컴파일러가 뭔데?
컴파일러란?
높은 단계의 언어(Hign-level language)를 컴퓨터가 알아들을 수 있는 언어(Object code, Machine code)로 바꾸는 것을 의미한다.
우리가 C++, Java, Python을 이용해서 쓴 언어는 컴퓨터가 알아듣지 못한다. 컴퓨터는 0과 1로 이루어진 언어만 이해할 수 있기 때문이다. 이를 가능하게 해주는 것이 컴파일러다.
이와 비슷한 프로그램들에는 인터프리터(Interpreter), 어셈블러(Assembler)등등이 있다.
각각의 의미는 무엇일까?
인터프리터는 높은 단계의 언어를 낮은 단계의 언어로 바꾸지 않고, 바로 시행하게 해줄 수 있게 해주는 프로그램을 의미한다. 단계가 좀 줄어들기는 하지만, 그 대신 시행하는 시간이 10배 이상 느려진다.
어셈블러는 어셈블리로 쓰여진 코드를 기계어, 낮은 단계의 언어로 바꿔주는 프로그림이다. 어셈블리어는 기계어와 1대1 대응이기 때문에, 각 구문을 명령어에 맞게 치환만 해주면 되므로 컴파일러와 다른 취급을 한다고 한다.
그럼 컴파일러가 일을 처리하는 과정을 알아보자.
먼저 소스코드를 스캐너에 넣는다. 스캐너에 대한 자세한 설명은 뒷 장에서 하도록 하겠다.
스캐너에 소스코드를 넣으면, 모든 명령어들과 변수 등등이 토큰화가 된다. 토큰이라는 것은 프로그램을 구성하는 가장 작은 요소들을 의미한다.
이 만들어진 토큰은 파서로 들어가게 된다. 파서에 대한 설명도 뒷 장에서 마저 하도록 하겠다.
파서는 이 토큰들을 이용해, 추상 구문 트리(Syntax Tree)를 만든다.
이 추상 구문 트리는 의미 분석기(Sementic Analyzer)에 들어가고, 의미 분석기는 Annotated Tree를 만든다.
이 Anootated Tree는 Source Code Optimizer에 들어가고, Source Code Optimizer는 중간 언어(Intermediate Code)를 만든다.
중간 언어는 Code Generator에 들어가고, Code Generator는 Target Code를 만든다.
Target Code는 Target Code Optimizer에 들어가고, 조금 더 깔끔한 Target Code로 나오게 된다.
과정이 있어서 적기는 했지만, 교수님이 진도를 Sementic Analyzer까지만 나간다고 하셨기 때문에, 아마 정리는 거기까지만 할 것 같다.
그럼, 스캐너(Scanner)에 대해 먼저 알아보자.
스캐너란?
위에서도 적었듯이, 소스 코드를 토큰(프로그램을 구성하는 가장 작은 요소)로 구분하는 프로그램이다. 한 줄의 코드를 예로 들어보겠다:
a[index] = 4 + 2이러한 코드가 있다고 가정해보자. 우리는 이런 코드를 토큰화하면 이렇게 나타낼 수 있을 것이다:
identifier leftbracket identifier rightbracket assignment number plussign number
a [ index ] = 4 + 2이러한 과정을 거치기 위해, Symbol Table과 Literal Table이 필요하다.
파서(Parser)에 대해서도 알아보자.
파서란?
위에서 구한 토큰을 이용, Syntax Tree나 Parse Tree를 구해주는 프로그램이다.
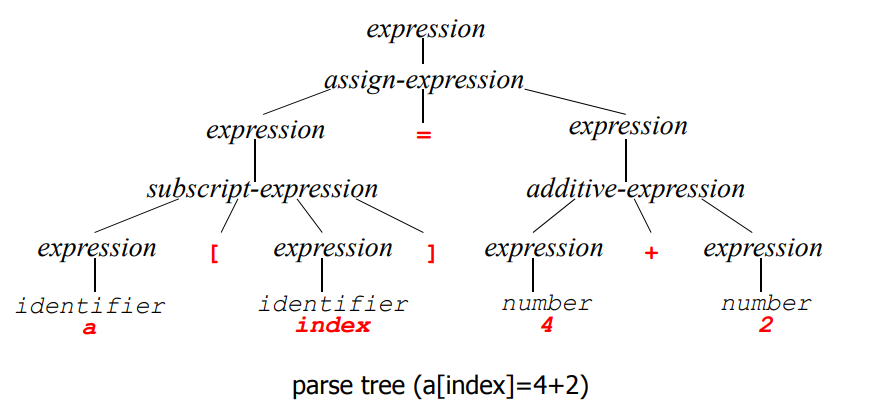
우리가 위에서 구한 a[index] = 4 + 2에 대한 Parse Tree의 결과이다.
위의 트리에서 한 단계 더 나아갈 수 있는데, 이것을 Abstract Syntax Tree라고 한다.
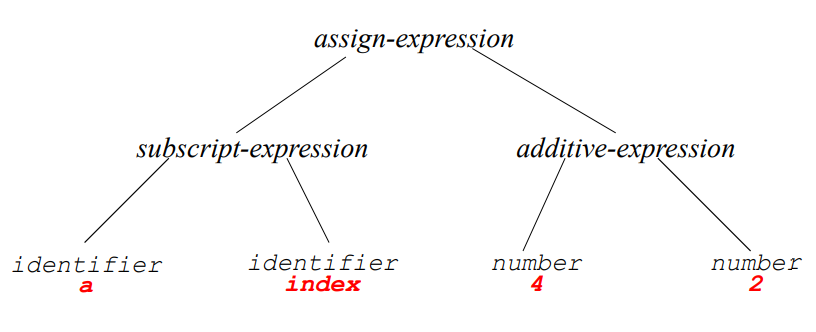
이렇게 그릴 수 있겠다.
마지막으로, 의미 분석기(Sementic Analyzer)에 대해 알아보자.
의미 분석기란?
위에서 구한 Abstract Syntax Tree를 조금 더 자세한 트리로 바꾸는 프로그램이다. 이 트리에는 위의 토큰들이 각각 어떤 데이터 타입인지 등등의 새로운 정보가 추가된다. 그래서 이 트리는 Decorated Syntax Tree라고도 한다.
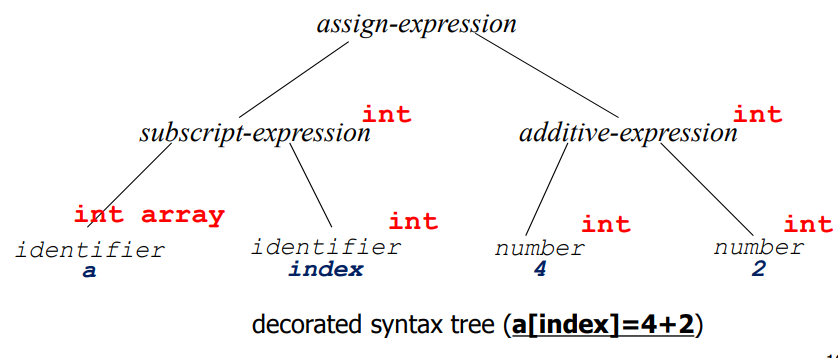
그 다음 장에서는 부트스트래핑(Bootstrapping)과 Porting에 대해 알아보도록 하겠다.
