

Wavenet
2016년 구글 딥마인드에서 발표된 end-to-end 딥러닝 기반 음성 생성모델
모델의 전체 구조
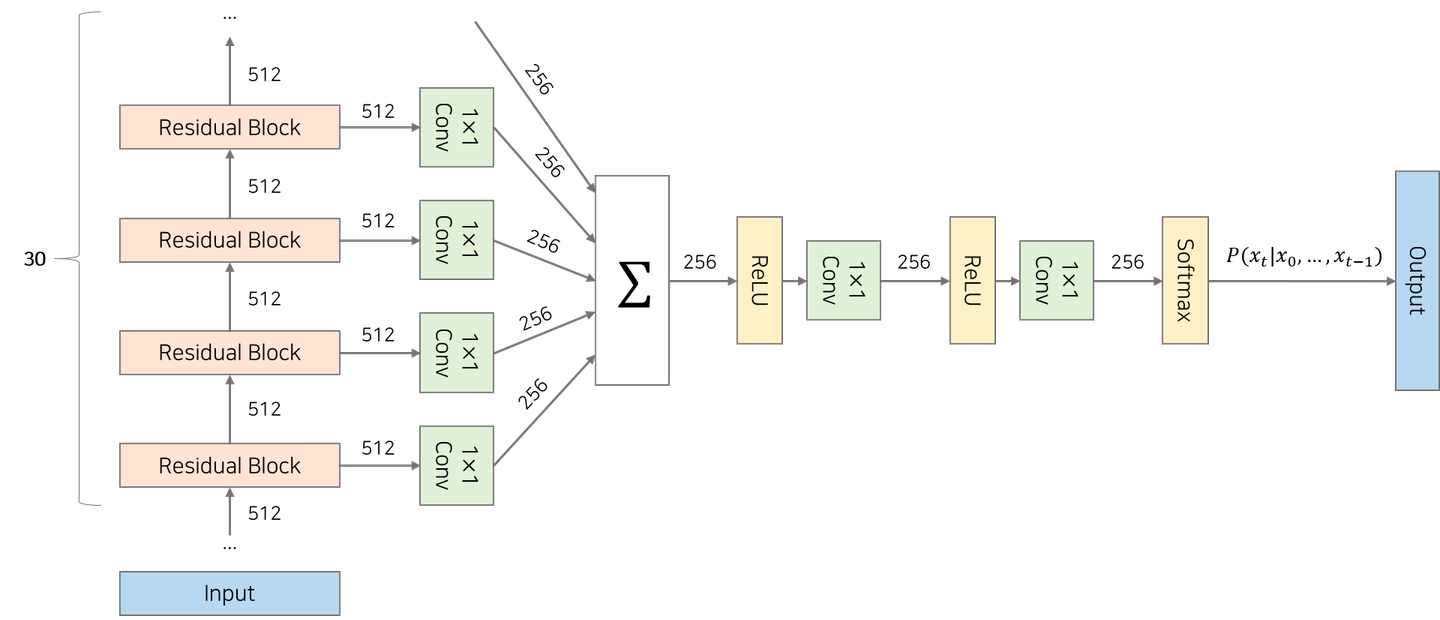
- 음성, 음악 등을 생성해내는 오디오 생성 모델
- 긴 음성 파형을 학습하고 생성할 수 있는 구조를 가지고 있다.
- condition 모델링을 통해 텍스트 뿐만 아니라, 화자의 identity 등의 특징이 주어졌을 때의 오디오도 생성해낼 수 있다.
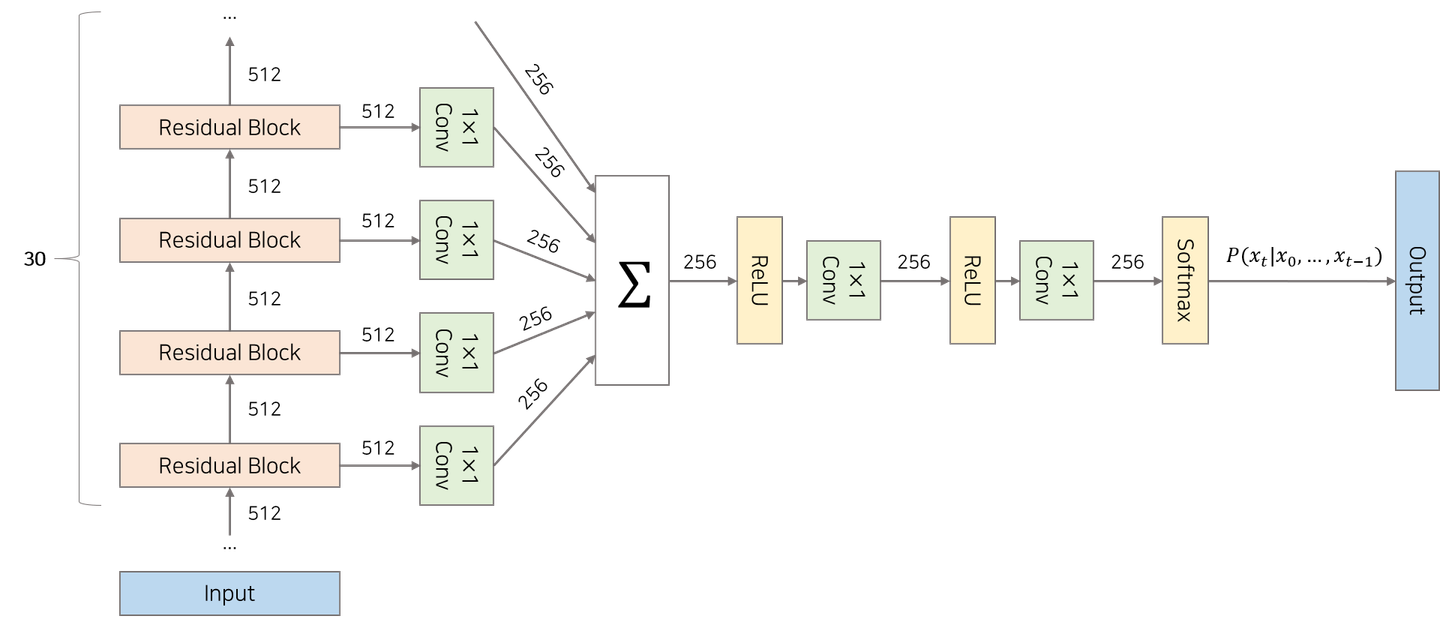
- 30개의 residual block을 쌓은 모델 구조
Input audio sequence
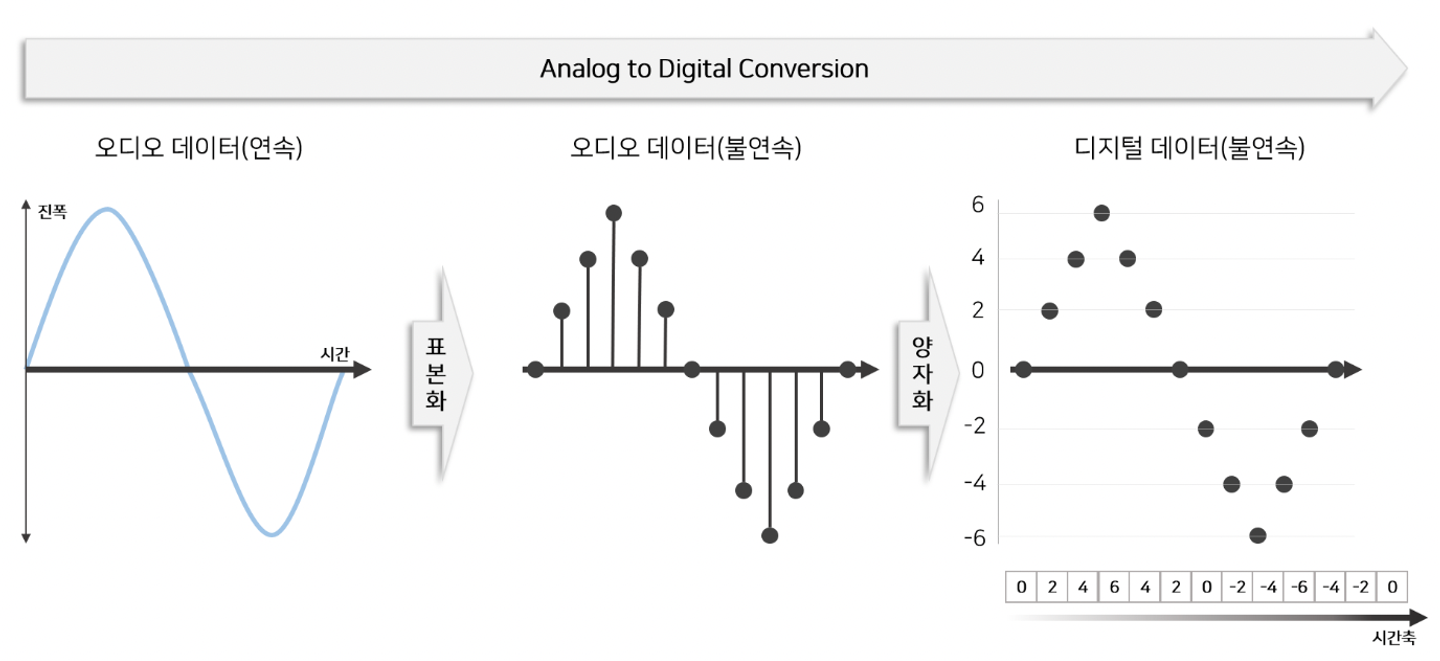
- 모델에 input으로 들어가야하는 아날로그 오디오 데이터는 연속형(Continuous) 데이터 → 실제 세계의 연속적인 오디오를 디지털화(e.g. wav, mp3, ..)해서 사용하기 위해서는 2가지 단계가 필요하다. →
표본화(sampling),양자화(Quantizing)
- 따라서, computing을 위해선 먼저 연속형 데이터(오디오 데이터)를 샘플링된 형태로 표현해줘야 한다.
- 보통, 음성 파일마다 초당 몇개의 샘플을 가지고 샘플링을 할지 결정하게 되는데 일반적으로 16000을 사용한다. (sampling_rate=16000)
- 시간 별로 1초당 16000개의 샘플을 샘플링 했다면, 이제 continuous한 진폭도 양자화를 시켜줘야 한다.
- 진폭에 대한 양자화의 경우, 일반적으로 진폭의 크기는 16bit(~ )로 저장이 된다.
→ 이 과정을 거친 이산형(Discrete) 오디오 데이터는 정수 배열(int array)로 표현된다. 이 정수 배열이 wavenet의 input으로 활용된다.
확률론적 모델, Wavenet
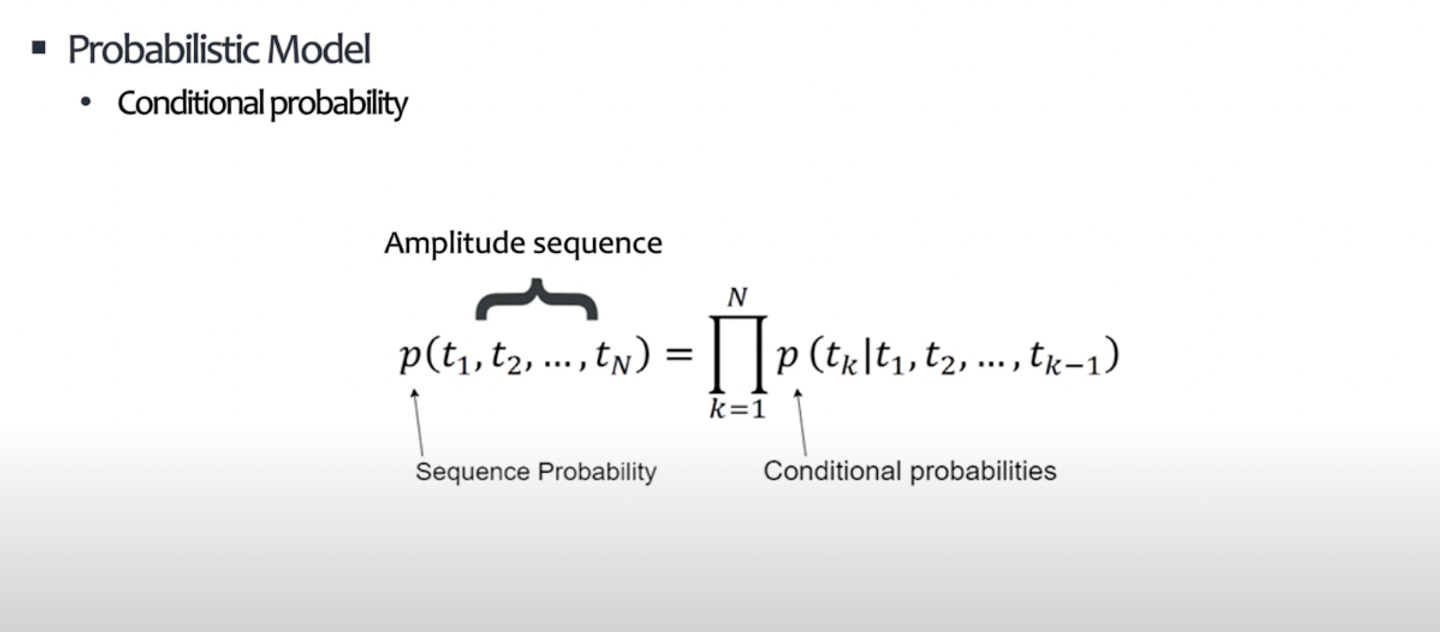
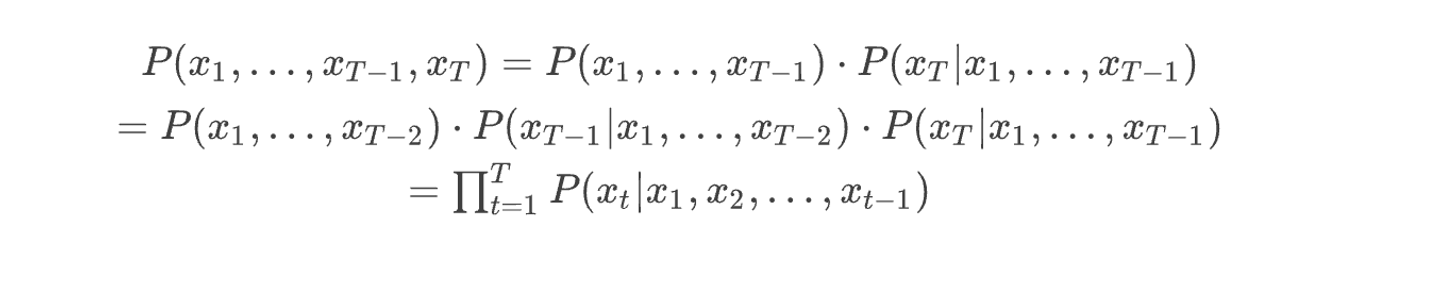
T개의 배열로 구성된 음성 데이터 가 주어졌을 때, 음성으로써 성립할 확률 를 학습하여 이후 생성에 활용한다. 즉, 예를 들어 이 주어졌을 때(조건부), 가 나올 확률(확률)을 학습하고, 이를 기반으로 나중에 생성 테스크를 진행한다.
- 음성의 등장 확률을 학습한 확률론적 모델
- 위에서 샘플링+양자화 를 통해 디지털화 된 오디오 데이터를 input으로 받으면, wavenet은
- 과거()부터 현재시점()까지의 음성 데이터를 보고 → 직후 시점()에서 특정 음성이 등장할 확률들을 예측한다.
- e.g. 현재 idx=3이라면, 를 보고 에 들어갈 음성을 예측한다.
- 이렇게 예측(생성)된 시점의 음성은 다음 시점의 음성을 예측(생성)하기 위해 다시 input으로 들어가게 된다. (Auto-Regressive)
- 과거()부터 현재시점()까지의 음성 데이터를 보고 → 직후 시점()에서 특정 음성이 등장할 확률들을 예측한다.
- 위에서 샘플링+양자화 를 통해 디지털화 된 오디오 데이터를 input으로 받으면, wavenet은
구조
전체적인 구조
- 30개의 Residual Block
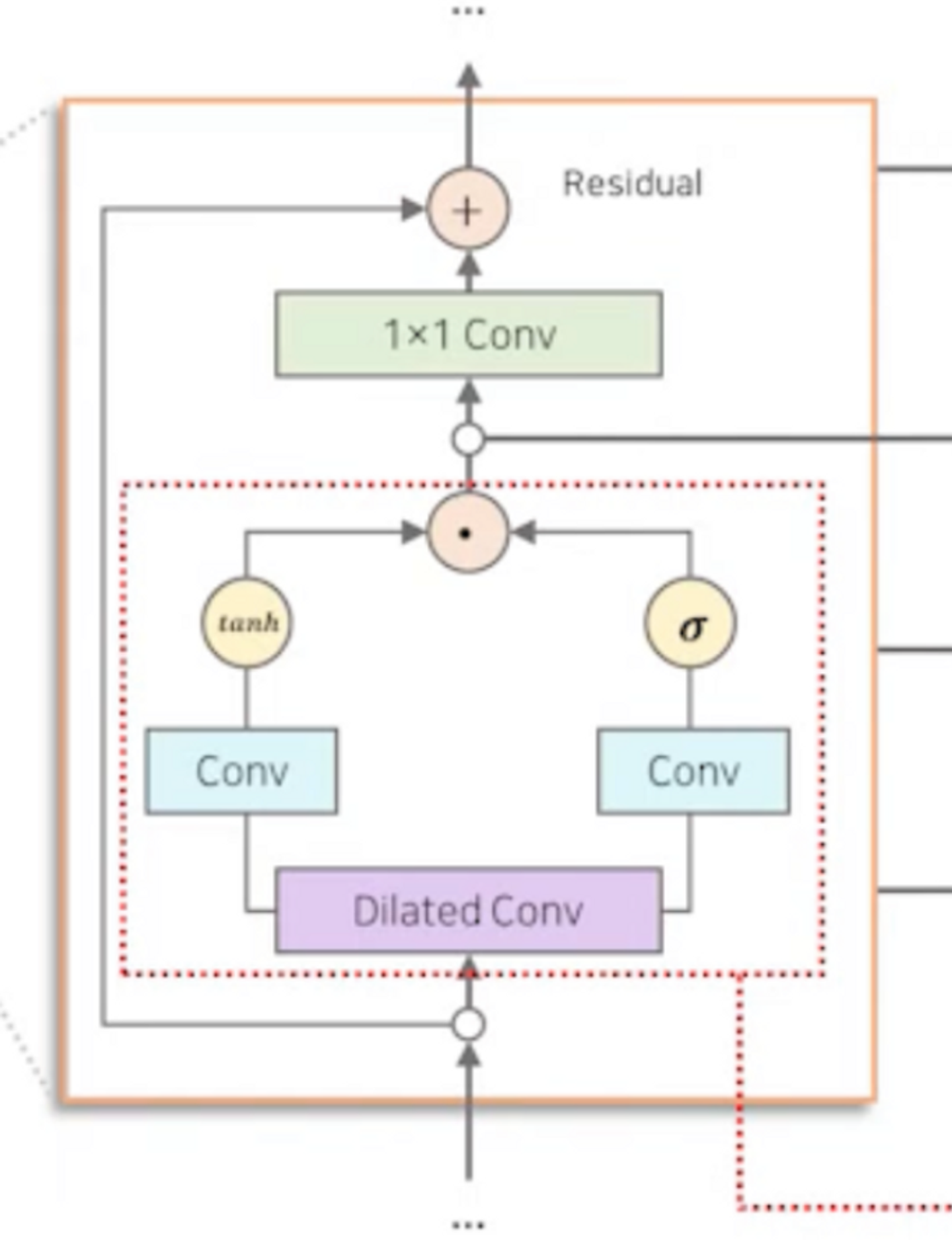
- Residual block
- block 내부에서 입력과 출력 사이에 잔차(Residual)을 추가하는 것
- 입력 데이터의 변화를 잔차로 나타내고, 이를 출력에 더하는 방식으로 진행
- 입력 데이터를 보다 깊은 네트워크로 전달 → 레이어간 정보 흐름을 강화 & 깊은 구조의 신경망에서도 기울기 소실 문제를 완화한다.
- 정수 배열을 input으로 받은 첫번째 residual block의 output은 두번째 residual block의 output으로, … 이렇게 순서대로 30번째 residual block까지 전달되게 된다.
- 30개의 Residual Block에서 나온 매 시점의 결과물은, skip connection을 통해 합쳐진다. → 이를 활용해 최종 output인 t시점의 특정 음성 등장 확률을 계산한다.
Input | Companding Transformation
- 각 audio sample들에 대한 조건부확률인 을 모델링하기 위해 사용되는 방식인 Softmax Distribution
→ 시점의 의 amplitude(진폭) 값은 ~ (범주형)중에 어떤 값일 확률이 가장 높을까?를 알아내는데 사용.
- 오디오 시퀀스는 각 time step 하나 당 16-bit의 정수형 값을 가지고 있는데, → 이 때, 각 time step마다 의 discrete variable(categorical variable)에 대한 조건부 확률을 예측해야 한다. → 그러나 너무 많은 범주에 대해서 softmax 확률값을 구하면, 정확히 어떤 정수값이 t시점에 오는 것이 좋을지에 대해 확신할 수 없기에 tractable(효율적으로 다룰 수 있는)이 어려우므로,
$\mu-law$ 압축 변환을 사용한다.
- companding Transformation(압축 변환)
-
압축 변환은 16bit(~, 65536개)의 값을 8bit(~, 256개)의 범위로 Quantize 하는 방법 중 하나.
- 이 때, 비선형적 quantization을 하게 되는데, 이렇게 비선형적 양자화를 거친 샘플이 오리지널 샘플과 좀 더 비슷한 소리를 낸다고 이야기한다.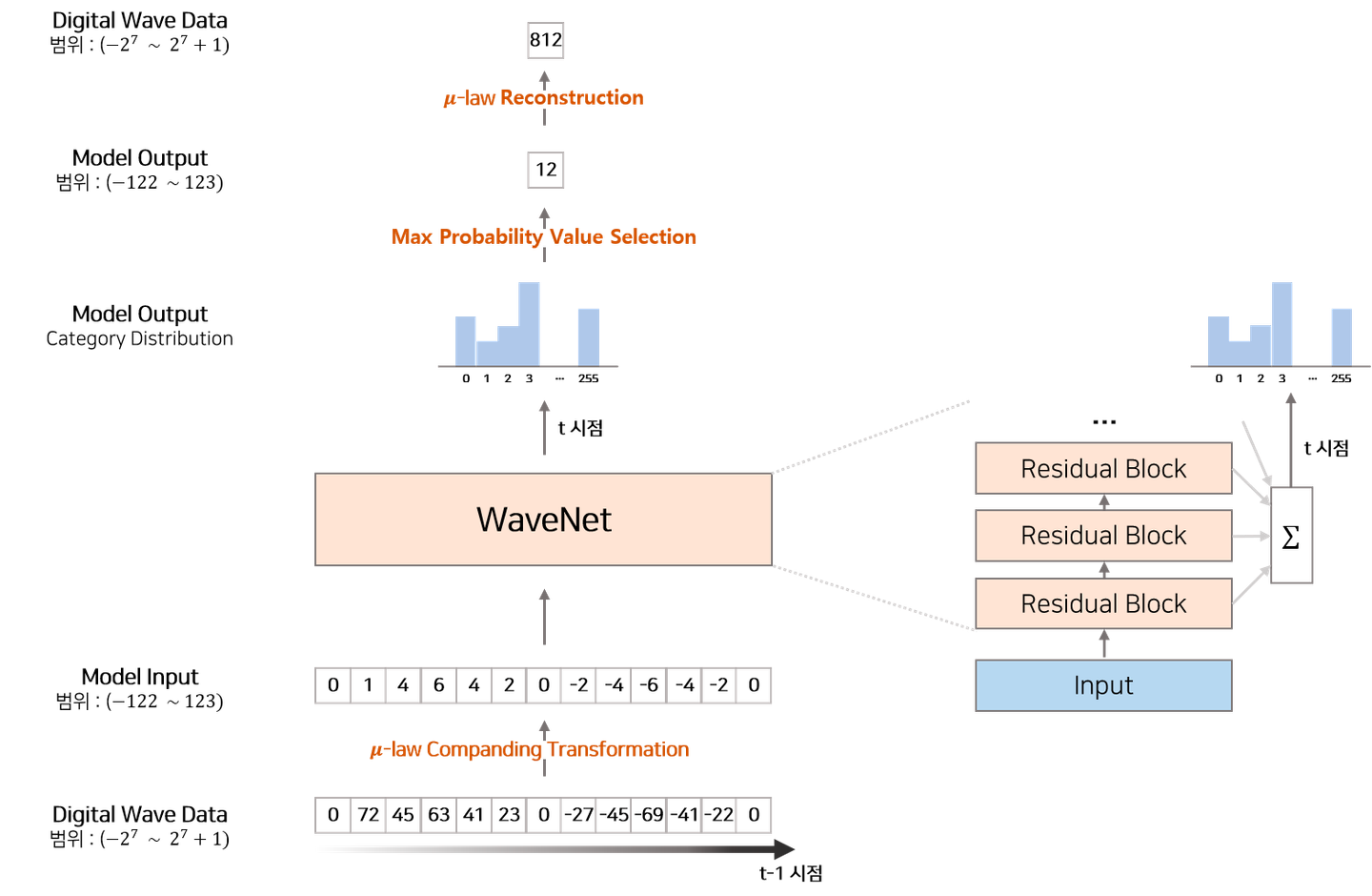
-
모델 구조 | Residual Block의 구성
1. Dilated Causal Convolution
2. Gated Activation Units
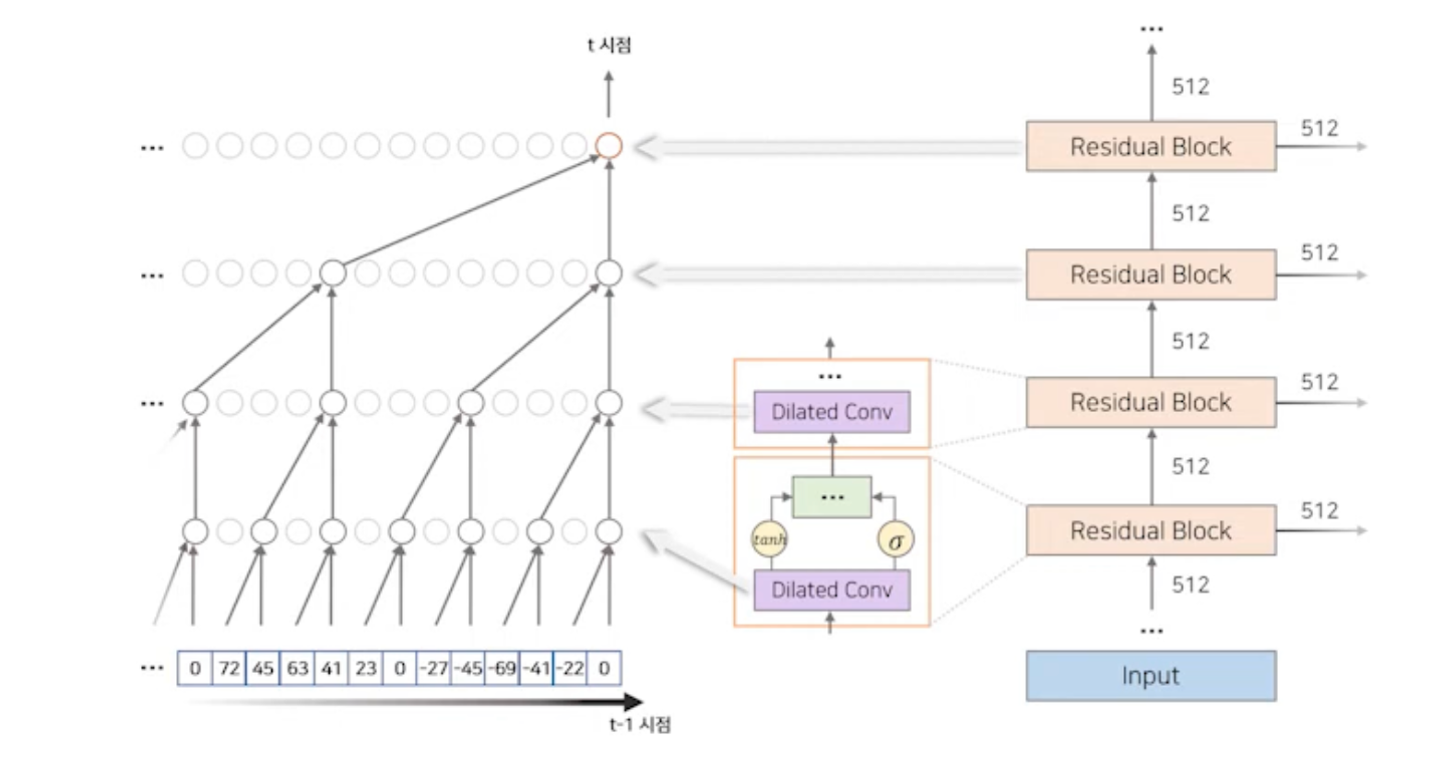
- Dilated Causal Convolution
- 과거 음성 정보(~)를 이용해 현재 시점()의 정보를 생성하는 역할 1) 시간 순서를 고려하여 과거 정보만을 접근해 정보를 추출한다. (
Causal Convolution) → Recurrent connections가 없기 때문에, RNN보다 학습이 빠르다. (특히 매우 긴 시퀀스에 데이터를 학습할 때) → 그러나, causal conv만 사용하면 수용 범위 넓히기 위해 많은 양의 layer를 쌓아야한다. 2) 추출 간격을 조절하여 Layer를 적게 쌓아도 더 넓은 수용범위를 갖는다. (Dilated Convolution) →더 넓은 과거 시점(but 더 적은 layer 사용)을 참조해서 현재 시점의 정보 생성 가능 → 오른쪽 그림: 4개의 레이어만 쌓았으나, 왼쪽과 비교했을 때, 개의 훨씬 넓은 수용 범위를 갖고 있음- 음성 데이터는 일반적으로 매우 긴 시퀀스를 갖고 있기 때문에, 넓은 수용범위를 갖는 구조가 필요함. 따라서 Dilated Causal Convolution은 음성 데이터에 적합한 구조.
- 과거 음성 정보(~)를 이용해 현재 시점()의 정보를 생성하는 역할 1) 시간 순서를 고려하여 과거 정보만을 접근해 정보를 추출한다. (
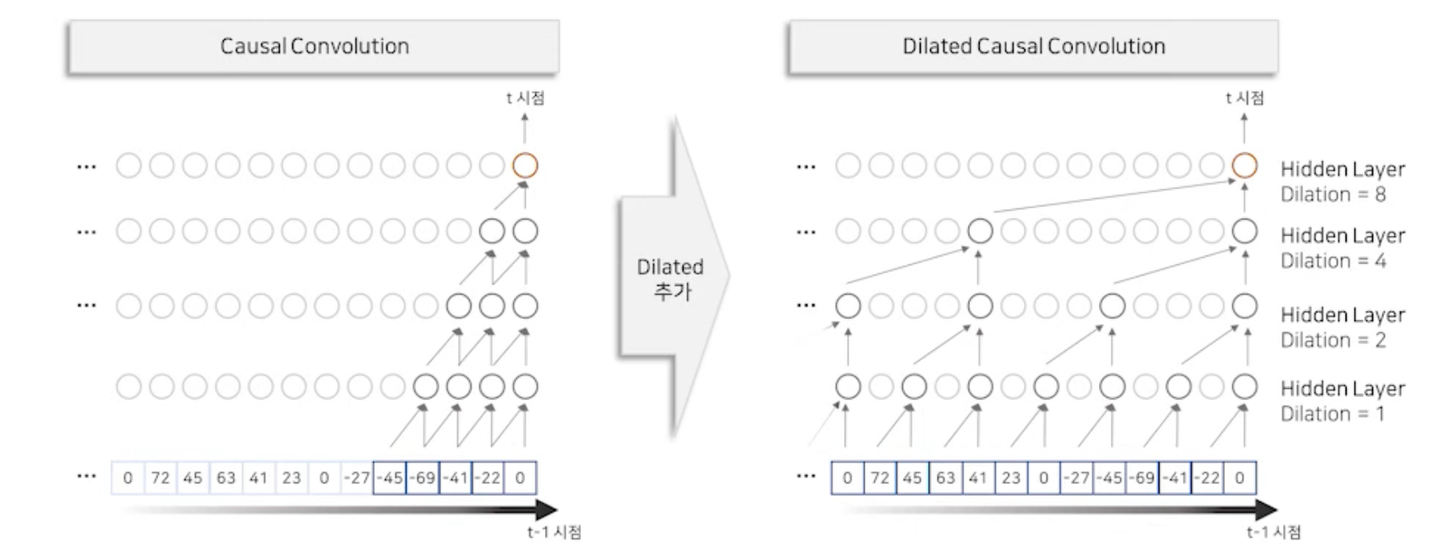
- 과거의 정보를 받아 특정 시점의 샘플이 예측되면, 그 예측된 샘플은 다시 네트워크에 input으로 들어가 그 다음 샘플을 예측하는데 사용된다. → 즉, Wavenet은 시점 순으로 순차적으로 샘플을 예측한다.
- Wavenet은 총 30개의 레이어에서 1부터 512까지 각 레이어에서 2배씩 dilation이 증가하는 것을 반복한다.
- (1, 2, 4, … , 512), (1, 2, 4, …, 512), (1, 2, 4, …, 512) 총 30개 레이어
-
Gate Activation units
- Dilated Convolution에서 생성된 정보를 다음 Layer에 얼마나 전달할 지 결정함.
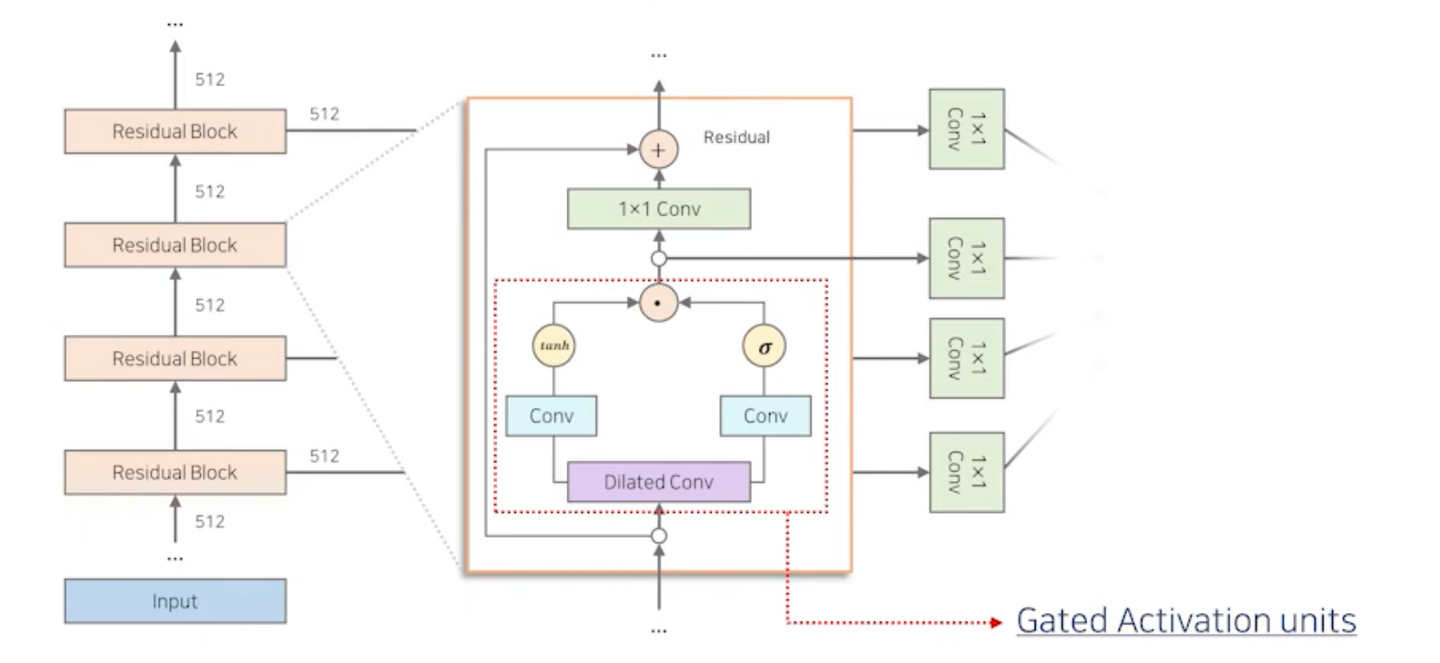
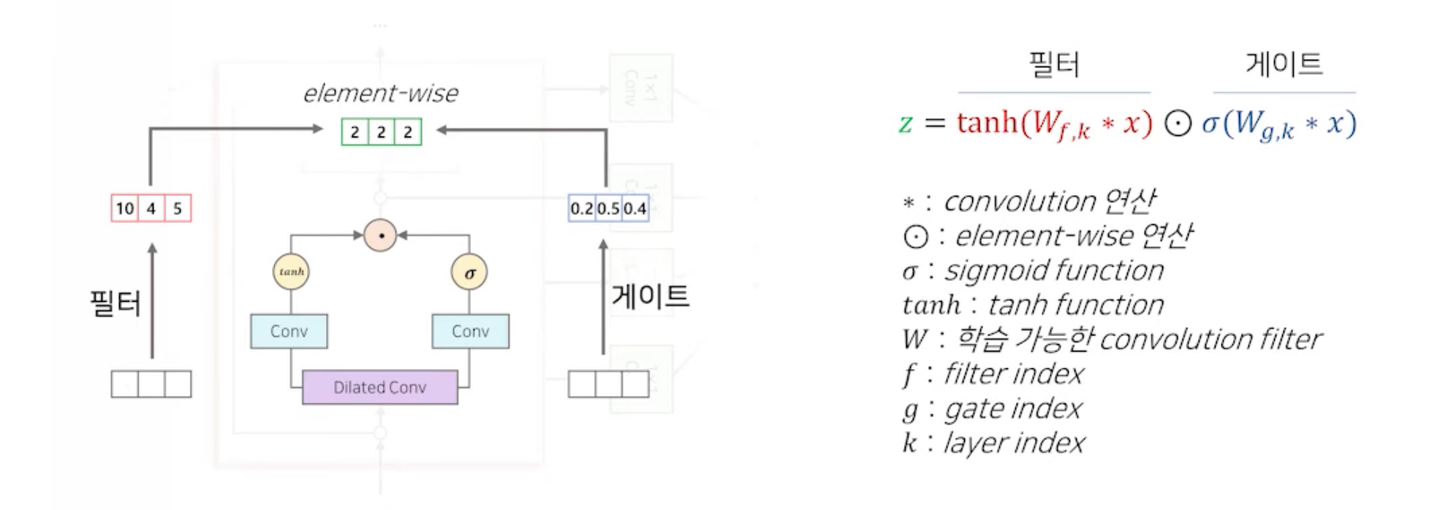
1) 필터(Filter)
- Dilated Conv에서 생성된 정보를 가공하는 역할
2) 게이트(Gate)
- 필터 경로에서 가공된 정보를 다음 Layer에 얼마나 전달해 줄지 결정(0~1 사이의 확률)
- convolution과 Gated Activateion Units를 통과하여 생성된 벡터는 Residual Connection으로 입력과 연결되어서 최종 결과를 생성한다. → Residual Connection을 사용하면서 Gradient Vanishing을 방지하여 Layer를 많이 쌓을 수 있다고..
- 1X1 Conv
- 1X1 Conv - 해당하는 채널 수를 줄이는 목적 or linear projection 목적
- residual connection으로 이어지는 1x1 conv → high level feature를 만들기 위한 과정. 즉, 다음 encoder layer에게 넘겨주기 위해 사용되는 feature
- 왼쪽으로 빠져있는 1x1 conv들 → Decoding feature를 만들기 위해 따로 빼놓은 feature
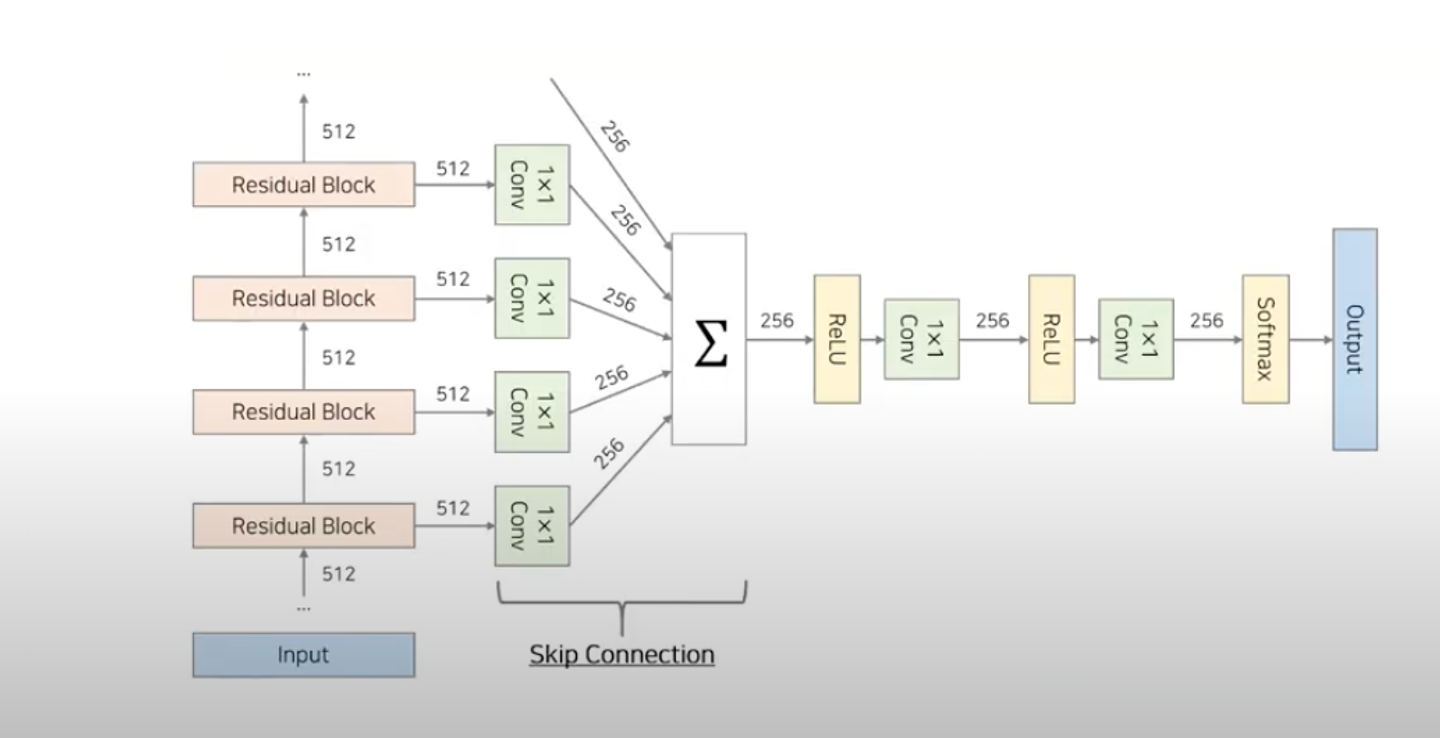
- 왼쪽으로 빠져있는 1x1 conv들이 내뱉은 각 layer마다의 feature(local feature)들이 모두 더해져서 최종적인 global feature를 하나 만든다.
- 그렇게 나온 데에 decoding prediction을 위한 추가적인 처리를 거친 embedding을 만든다.
softmax- digital signal의 범위가 8bit으로 정해져있는데, 그 8bit 값 중에서 어떠한 값을 가지는지 categorical prediction을 한다.
우리가 하고 싶은 것은, Text to Speech!
- text가 조건으로 주어졌을 때, 음성을 만들어내는 모델을 만들고 싶다
- 그러나 위에 설명한 모델 구조에서는 text가 들어가질 않는데..? (input audio → output audio 구조)
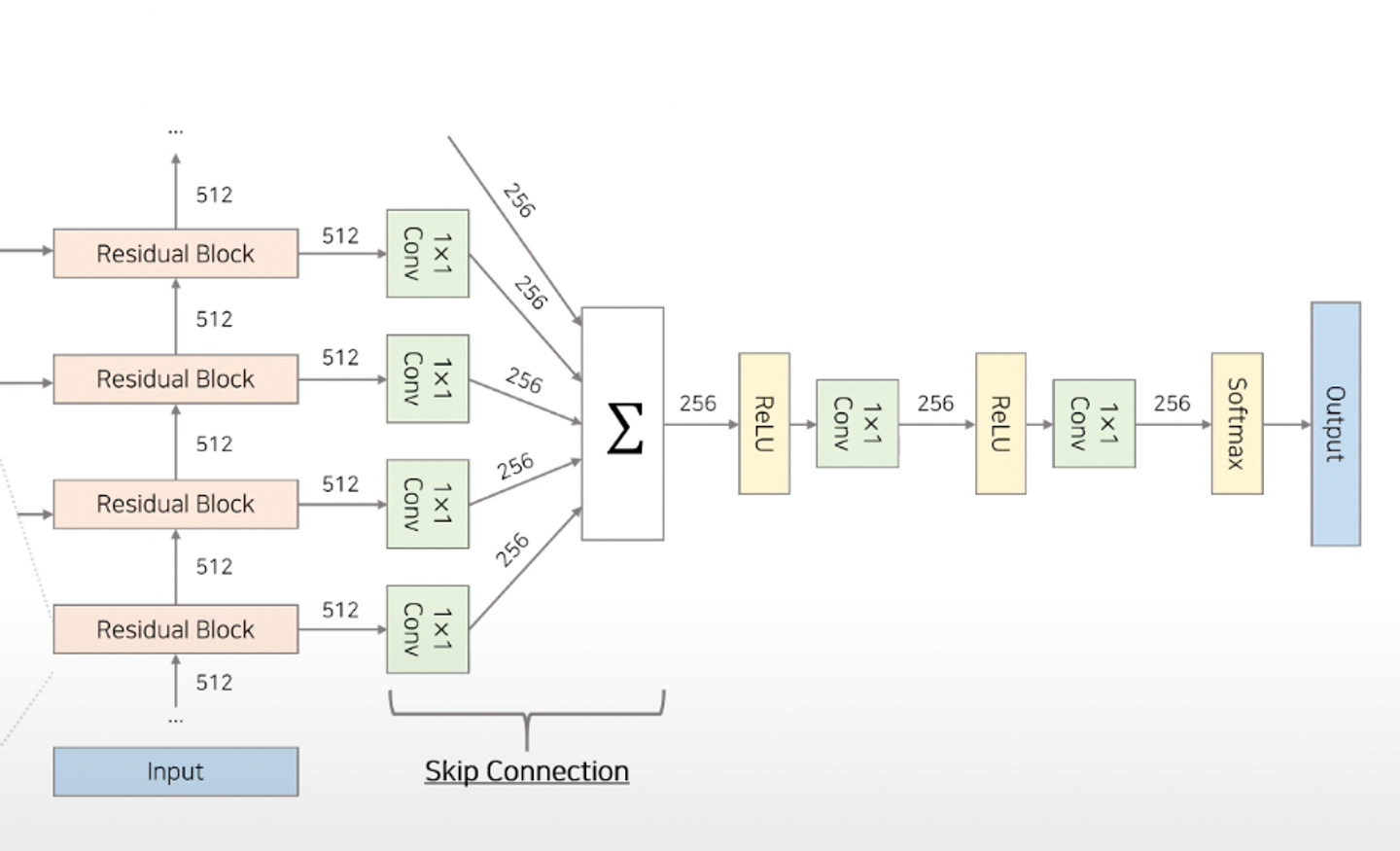
- 전체 모델 구조
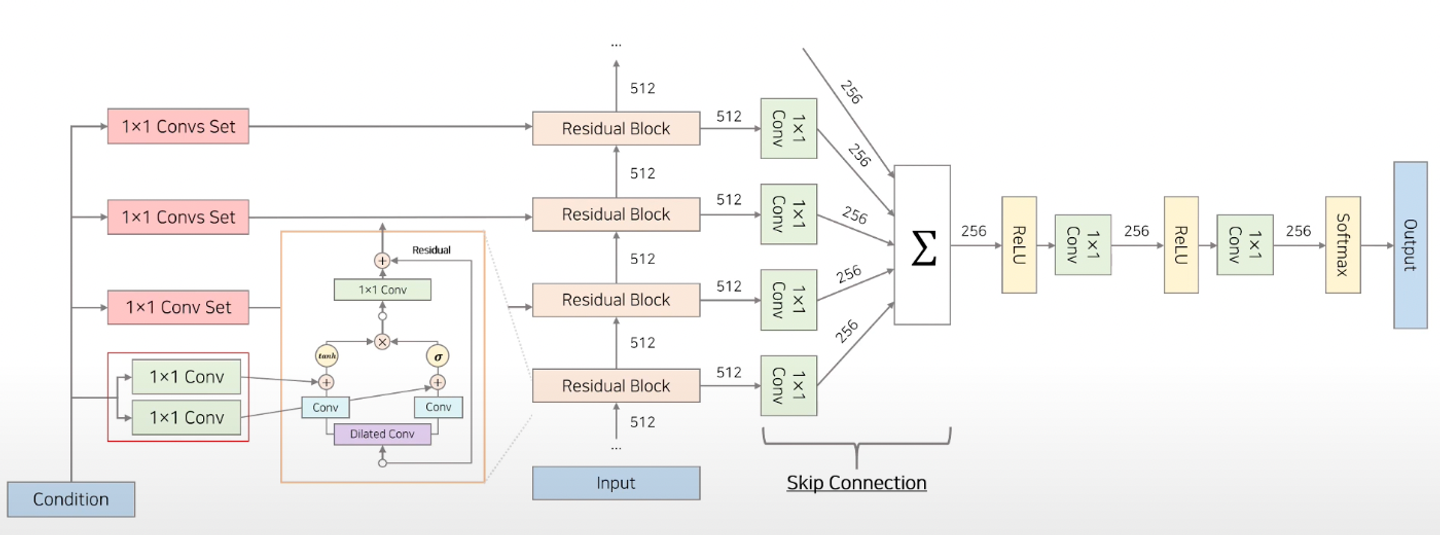
-
그 중, 왼쪽 구조를 살펴보면, text 정보가 언제 어디서 들어가는지 알 수 있다!
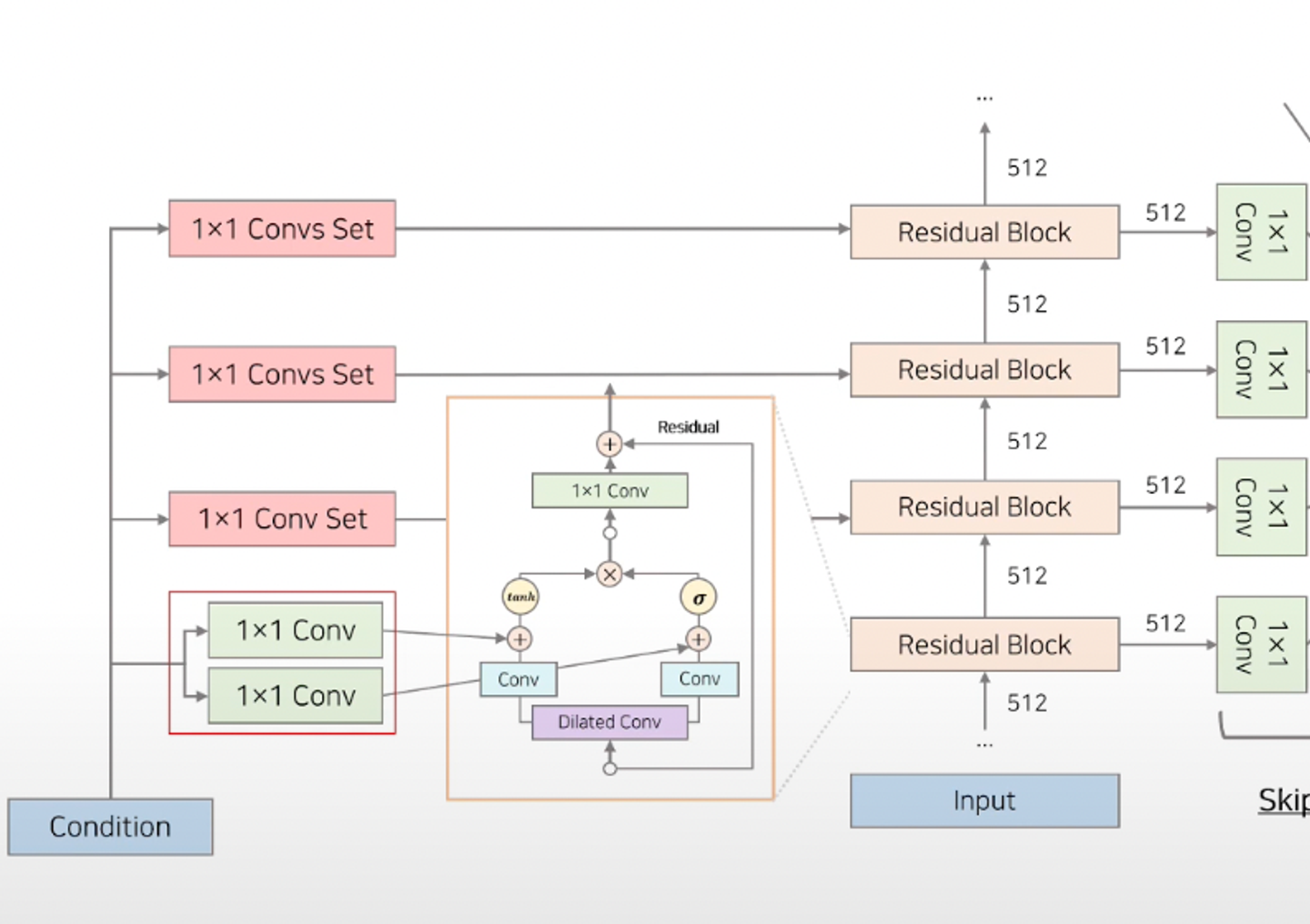
- 위에서 설명했던
Residual Block- 여기에 1X1 Conv는
어떤 목적을 달성하기 위해추가되는 Conditional한 latent vector를 만들어 Residual Block 내 Gated Activation Units에 추가한다. - 이 때, Condition에는
Global과Local두가지 정보가 존재한다. - 기존 wavenet 구조
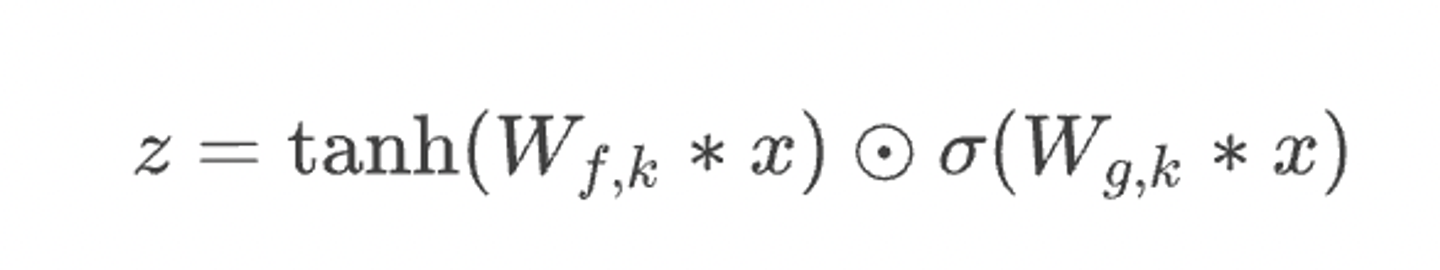
- 여기에 1X1 Conv는
- 위에서 설명했던

1) Global Conditioning
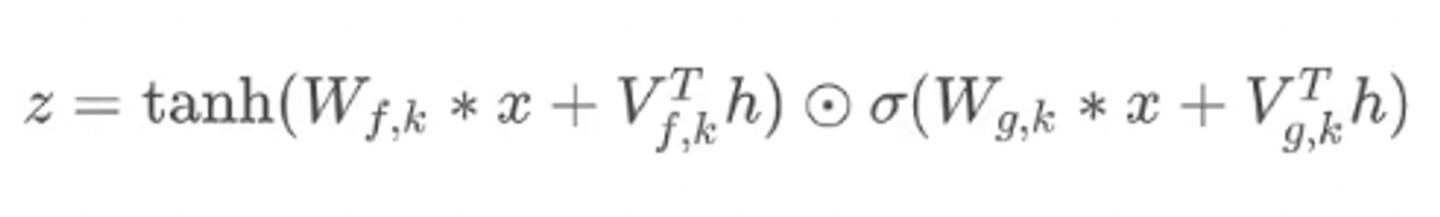
-
모든 시점에서 동일하게 적용되는 조건 정보
-
e.g. 화자 정보에 대한 임베딩 → 화자의 ID를 One-hot vector로 변환한다.
- 기존 wavenet 구조 수식에 가 더해진다.2)
LocalConditioning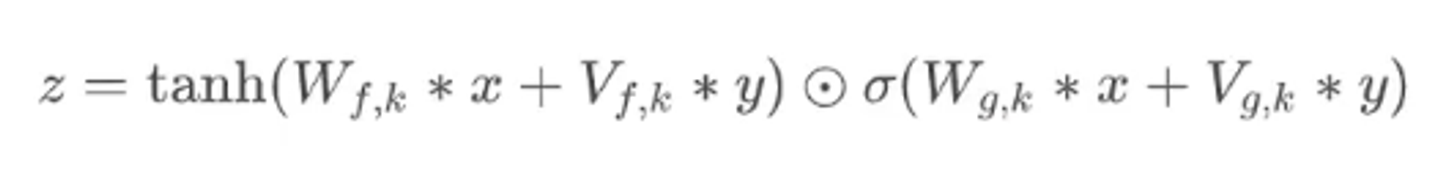
-
모든 시점마다 다르게 주는 조건 정보
-
는 같은 시퀀스를 갖는다.
-
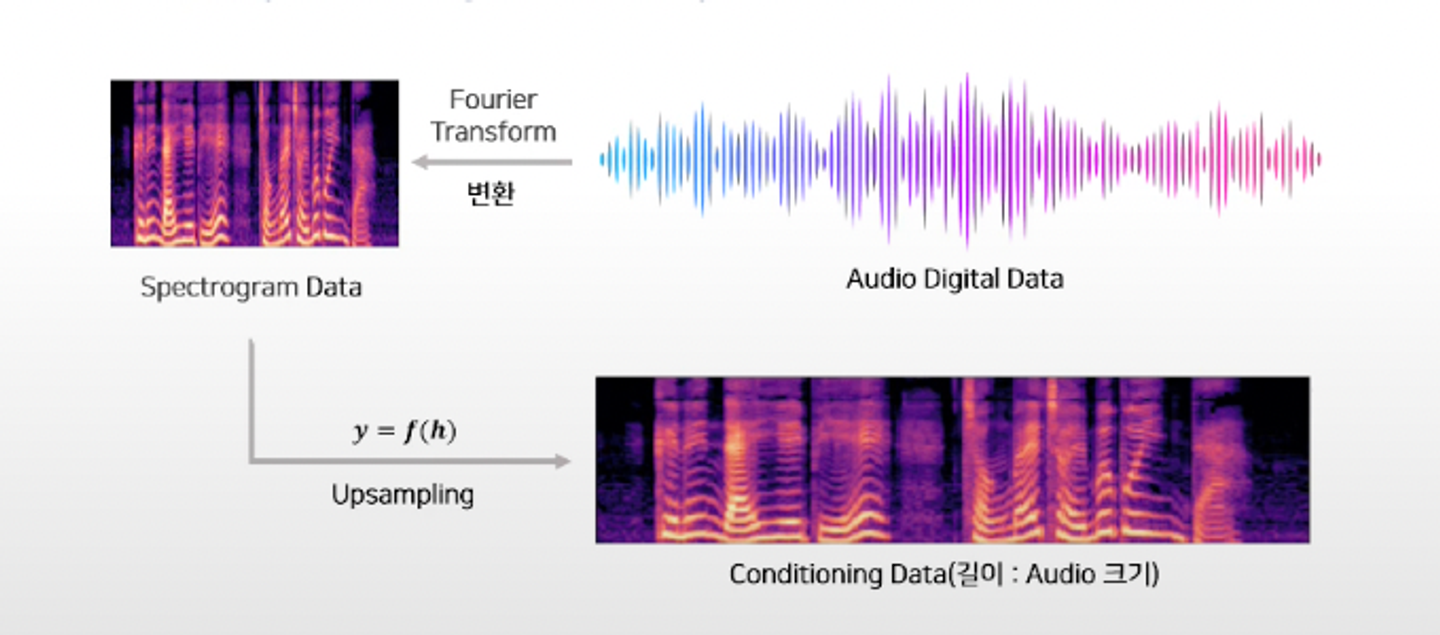
일반적으로 는 오디오, 는 text embedding 혹은 mfcc같은 오디오 feature
→ 따라서 조건과 오디오가 서로 다른 길이를 가질 때 이 길이를 맞춰주기 위해 사용되는 것이 Transposed Convolution
-
Transposed Convolution란? (feat. chatgpt)
- Transposed convolution은 신호나 데이터의 크기를 조정하기 위해 사용되는 컨볼루션 연산의 한 종류입니다. 일반적인 컨볼루션 연산이 입력 신호의 크기를 줄이는 것과 달리, 트랜스포즈드 컨볼루션은 입력 신호의 크기를 늘리는 데 사용됩니다. 따라서, 입력 신호와 출력 신호의 크기를 조정함으로써 조건과 오디오의 길이를 맞춰줄 수 있습니다.
- 트랜스포즈드 컨볼루션은 일반적인 컨볼루션과 유사한 방식으로 작동하지만, 필터를 입력 데이터에 적용하는 과정에서 패딩(padding)과 스트라이드(stride)를 사용하여 출력의 크기를 조절합니다. 패딩은 입력 데이터 주변을 가상의 값으로 채우는 것으로, 출력의 크기를 증가시킬 수 있습니다. 스트라이드는 필터를 이동시키는 간격을 조정하여 출력 크기를 제어하는 데 사용됩니다.
- 트랜스포즈드 컨볼루션은 주로 이미지 처리에서 사용되며, 이미지 복원, 슈퍼 해상도, 분할, 객체 감지 등 다양한 응용 분야에서 활용됩니다. 길이가 다른 조건과 오디오 데이터의 크기를 맞추기 위해 트랜스포즈드 컨볼루션을 사용할 수 있습니다. 이를 통해 입력 데이터의 크기를 조정하고, 필요한 경우 패딩과 스트라이드를 조절하여 출력 데이터의 크기를 조절할 수 있습니다.
- 음성과 조건 정보 (e.g. Spectrogram)
- Transposed Convolution 사용 (learnable parameters)
- → upsampling func
- Transposed convolution은 신호나 데이터의 크기를 조정하기 위해 사용되는 컨볼루션 연산의 한 종류입니다. 일반적인 컨볼루션 연산이 입력 신호의 크기를 줄이는 것과 달리, 트랜스포즈드 컨볼루션은 입력 신호의 크기를 늘리는 데 사용됩니다. 따라서, 입력 신호와 출력 신호의 크기를 조정함으로써 조건과 오디오의 길이를 맞춰줄 수 있습니다.
-
평가 방법
- Mean Opinion Score(MOS) test
- 피실험자에게 실험 모델로부터 생성된 음성을 들려주고 1~5점의 품질 점수를 선택하도록 하는 실험
- WaveNet(L+F)
L: 텍스트 임베딩에 대한 컨디셔널한 vector가 주어짐 (Linguastic feature)F: 추가적인 조건 제공 (e.g. log F0, duration of phoneme, ..)
- 16-bit : 오리지널 음성파일에 저장되는 방식
- 8-bit companding 방식 → 압축했지만, 크게 성능에 차이 없으므로, 계산적으로 이점인 압축 방식을 사용하는 것이 좋다.
Reference
