

Abstract
- Transformer 모델들은 맥락 기반의 전역적인(global) 상호 작용을 잘 캡쳐한다.
- CNN 모델들은 지역적인 특징을 효과적으로 활용한다.
- Conformer는 parameter-efficient 방식으로 오디오 시퀀스의 지역적 & 전역적 의존성을 모델링하기 위해서 어떻게 CNN과 transformer를 결합할 수 있는가에 대해 연구함으로써 transformer와 cnn의 장점을 모두 얻을 수 있다.
- 음성 인식에 대한 convolution 변형 트랜스포머를 제안 (
Conformer) - Conformer는 이전에 트랜스포머와 CNN 기반 모델들의 성능을 앞선다. (SOTA 정확도를 달성하며)
- 널리 사용되는 LibriSpeech benchmark에 대해, Conformer는 언어 모델 없이 2.1%/4.3%의 WER를 달성했고, 외부 언어 모델과 함께 1.9%/3.9%의 WER를 달성했다. (test/testother dataset)
- Conformer는 오직 10M(천만) 개의 파라미터만을 가진 small model에서도 2.7%/6.3%의 경쟁력있는 성능을 보여줬다.
Introduction
- Recurrent neural networks(RNNs)는 ASR에서 사실상 표준으로 사용이 되어왔음.
- 오디오 시퀀스의 시간적 종속성(temporal dependencies)을 모델링 할 수 있기 때문
- 최근에는 Self-attention 기반의 Transformer 구조가 장거리의 상호관계를 캡쳐하는 능력과 높은 훈련 효율성 때문에 시퀀스를 모델링하는데 폭넓게 사용되고 있다.
- convolutions는 레이어별로 local receptive field(로컬 수용 필드)를 통해 점진적으로 지역적인 맥락(local context)을 캡쳐하면서, ASR에 에 대해서도 성공적으로 작동했다.
- 그러나 self-attention과 convolutions는 각각 각자의 한계를 갖고 있다.
- Transformers가 긴 범위의 전역적(global) 맥락을 잘 파악하지만, → 세밀한 지역적 feature 패턴을 뽑아내는 능력이 부족.
- CNNs는 지역적 정보를 잘 뽑아내고 비전 분야에서 사실상 computational block으로 사용된다.
cnn은 translation equivariance(등분산)를 유지하는 지역 window를 통해 공유된 위치 기반의 커널들을 학습한다. 그리고 엣지나 모양같은 feature들을 잘 캡쳐한다. → 지역적 연결성을 사용하는 것의 한계는 전역적인 정보를 캡쳐해내기 위해 더 많은 층 또는 파라미터가 필요하다는 것.
- Transformers가 긴 범위의 전역적(global) 맥락을 잘 파악하지만, → 세밀한 지역적 feature 패턴을 뽑아내는 능력이 부족.
-
최근 연구들은 convolution과 self-attention을 합치는 것이 이것들을 각각 사용하는 것 보다 더 성능이 좋다는 것을 보여주고 있다.
-
해당 연구에서는, ASR 모델들에서 self-attention과 convolution을 어떻게 유기적으로 합칠수 있는가에 대해 연구했다.
⇒ 결론적으로, 한쌍의 feed forward 모듈 사이에 샌드위치처럼 끼인 self-attention과 convolution의 새로운 조합을 소개한다.
-
Conformer는 LibriSpeech에서 SOTA를 달성했고, testother dataset에 대해 외부 언어 모델을 사용한 경우, 이전에 가장 좋은 성능을 낸 Transformer Transducer보다 15% 상대적인 개선을 이루었다.
Conformer Encoder
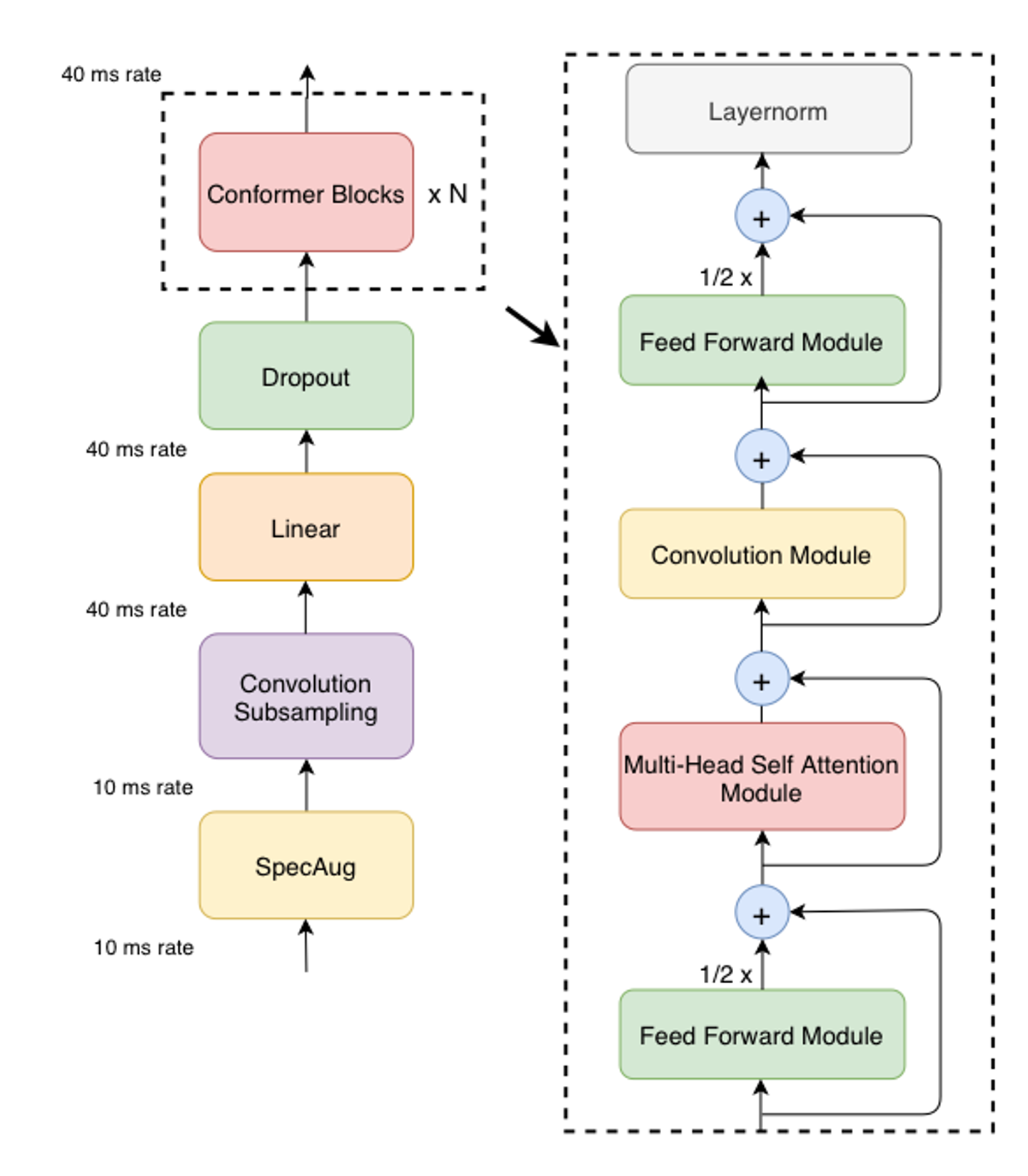
conformer의 오디오 인코더는 첫째로 input을 convolution subsampling layer로 처리한 후, 여러 conformer block으로 처리한다.
Conformer의 특별한 점은 Transformer block들 대신 Conformer block을 사용한다는 것이다.
conformer block은 함께 쌓여있는 4개의 모듈로 이루어져 있다.
- 첫번째 feed-forward module
- a self-attention module
- a convolution module
- 두번째 feed-forward module
Multi-Head Self-Attention Module
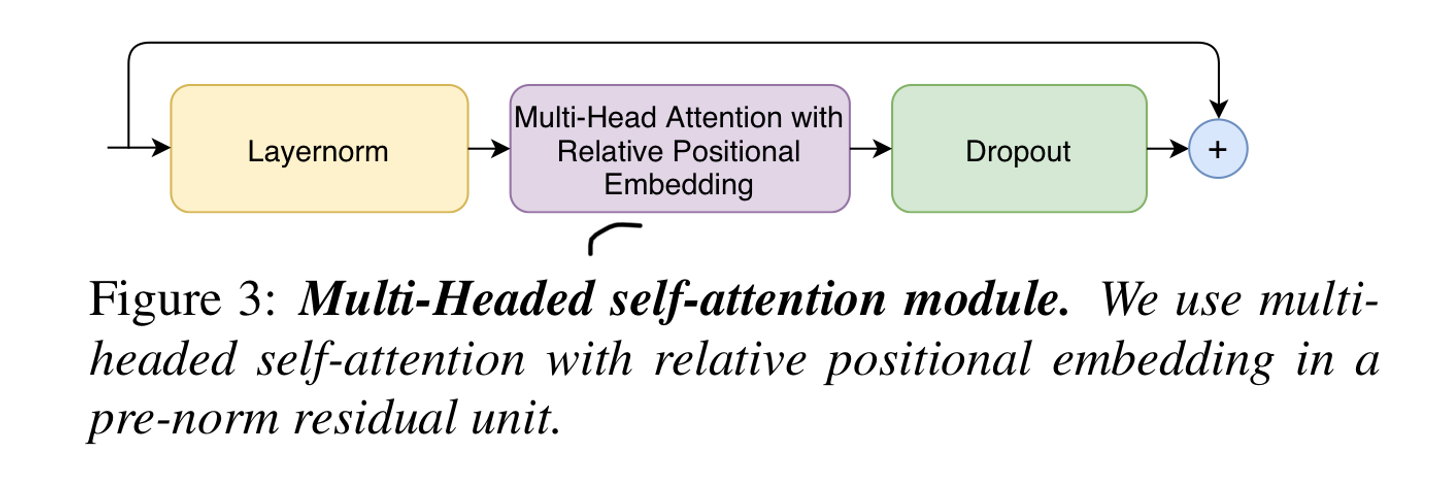
Conformer의 Multi-headed self-attention(MHSA)은 Transformer-XL로부터 Relative positional encoding을 적용
-
Relative sinusoidal positional encoding: 절대적인 위치가 아닌, 상대적인 위치를 통해 정보를 인코딩하는 방식
-
self-attention module이 서로 다른 input length에 대해 일반화를 더 잘하도록 한다.
-
또한 relative positional encoding을 사용하는 encoder는 발화 길이의 변화에 더 강하다(robust)
-
relative positional encoding
-
positional encoding은 왜 필요한가?- 같은 단어이면 다른 위치에 있더라도 같은 representative를 갖게 되기 때문. e.g. “
철수/ 가 / 영희 / 를 / 좋아해”라는 시퀀스와 “영희 / 가 /철수/ 를 / 좋아해”라는 시퀀스에서철수에 해당하는 attention layer의 아웃풋은 두 문장에서 완벽하게 동일하다. 이러한 문제를 해결하기 위해 2017년에 발표된 Transformer 논문에서는 인풋에 위치 인코딩 (position encoding)을 더해주는 방법을 사용
- 여기에 positional encoding이 더해져야지만, 위치(관계) 정보가 representative에 더해진다
- 같은 단어이면 다른 위치에 있더라도 같은 representative를 갖게 되기 때문. e.g. “
-
`relative positional encodig`은 왜 필요한가?
- absolute positional encodig을 사용하면, token의 semantic vector와 간단히 합쳐줌으로써 위치 정보를 더할 수 있다.
- 그러나 absolute positional encoding을 사용하게 되면, 필연적으로 모델이 처리할 수 있는 토큰의 개수에 제한이 생기게 된다. e.g. 언어 모델이 최대 1024개의 위치만 인코딩할 수 있다고 가정해보면, 필연적으로 1024토큰보다 긴 시퀀스는 모델에서 처리할 수가 없다.
-
그럼, relative positional encoding은 어떤 식으로 사용이 되는가?
Absolute PE의 경우
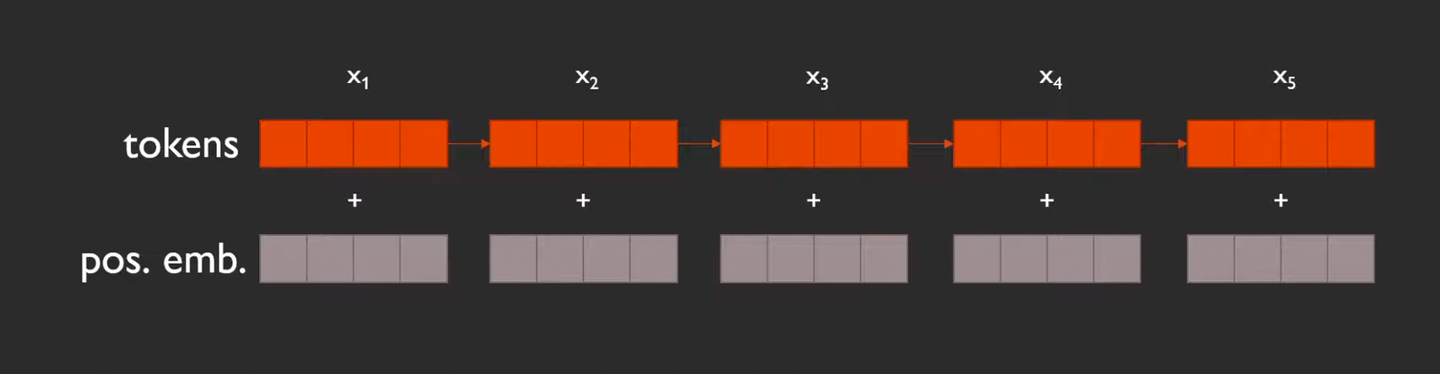
- 각 토큰은 하나의 PE만을 갖는다.
- 내가 전체 토큰 중 몇 번째에 위치 하는지 절대 위치 정보만 알면 되기 때문에 PE가 하나만 필요하다.
Relative PE의 경우
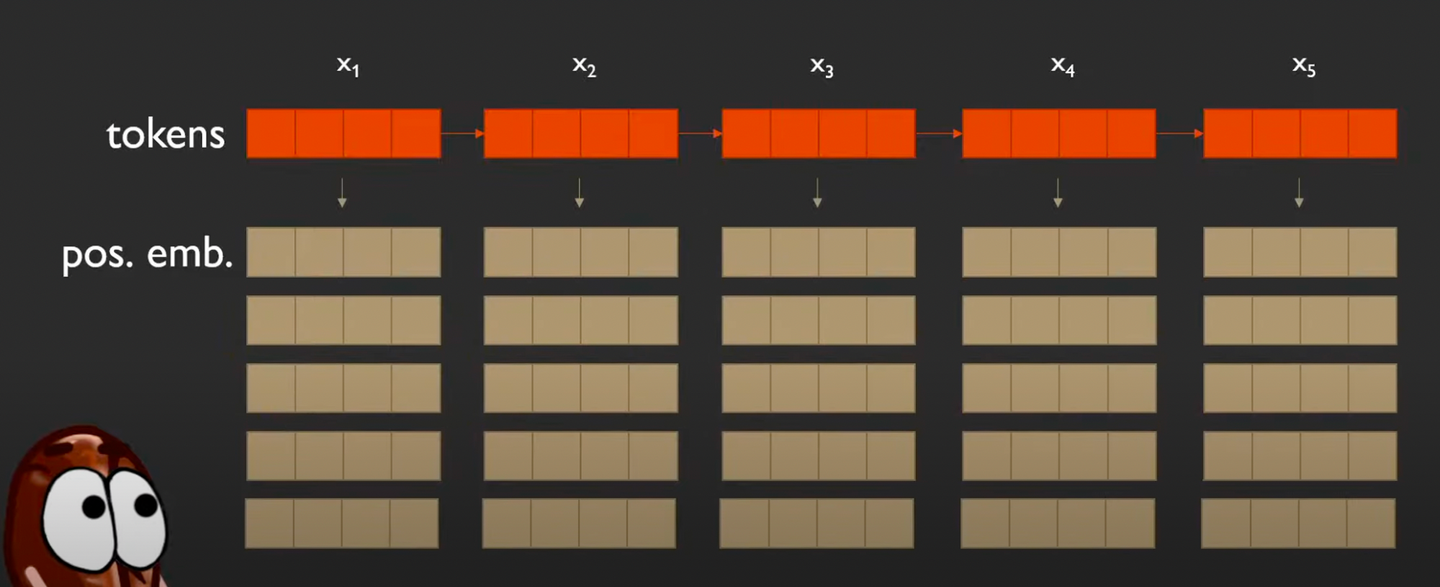
-
각 토큰은 여러개의 PE를 갖는다.
-
나 자신과 다른 토큰들 간의 관계(거리)를 나타내기 위해서
-
절대 순서(absolute position)를 인코딩하지 않고, 각 토큰이 다른 토큰에 대한 위치 관계를 인코딩한다.
-
어떻게 각 토큰은 전체 토큰 수만큼의 relative positional encoding을 갖는가?
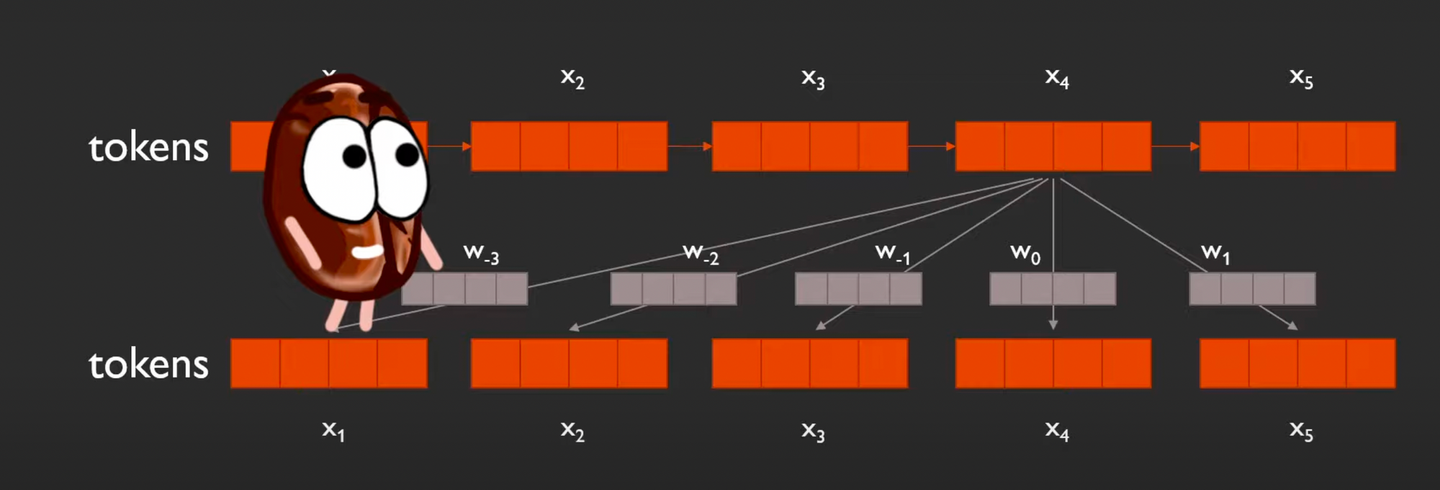
-
를 예시로 들면,
- 하나는 자기 자신과의 위치(=0)에 대한 relative pe,
- 그외에는 나를 제외한 다른 토큰들과의 거리에 대한 relative embedding
-
이걸 ~토큰에 대해 반복
-
Relative posional embedding ⇒ 내가 이든, 이든 동일하다. (얼마나 떨어 졌는지만 신경쓰기 때문 (단위: 홉 이라고 하나봅니다..!)
- 자기 자신에 대한 positional embedding :
- 내 앞에 있으면 내 뒤에 있으면
-
여기에서 학습 해야할 positional embedding은 총 9개! (나올 수 있는 위치 임베딩의 범위가 ~ 이기 때문)
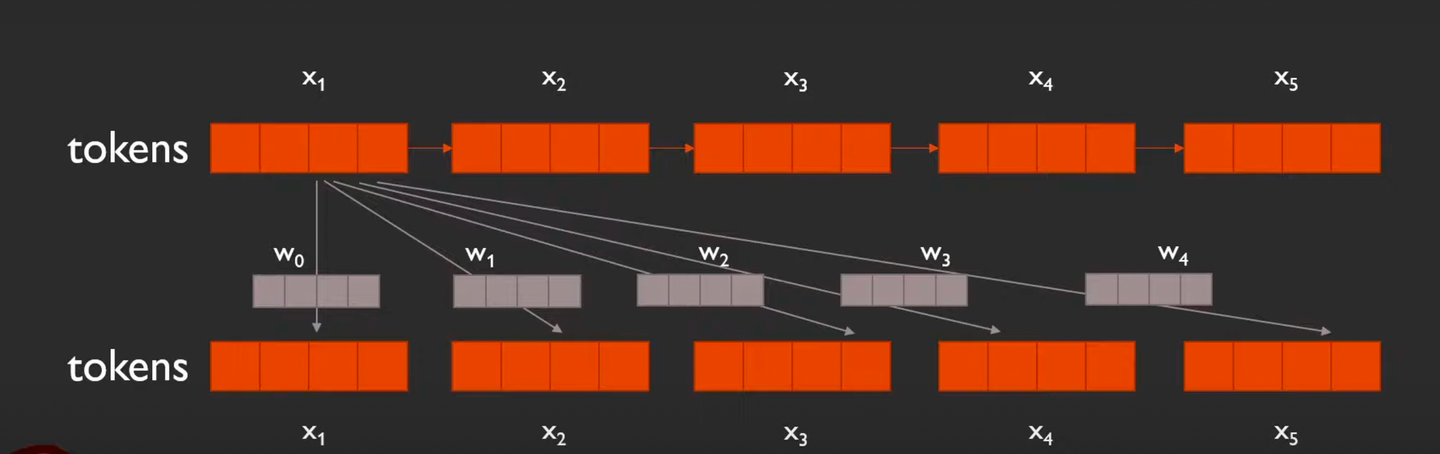
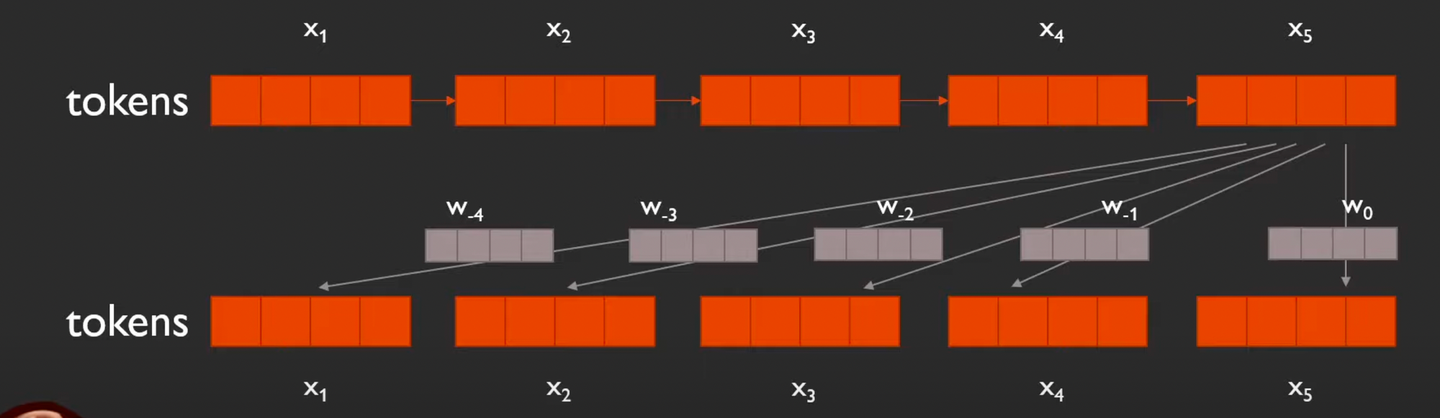
⇒ 위 그림에서 각 토큰 별로 표시된 위치 임베딩을 각각 한줄로 세워보면 아래처럼 된다!
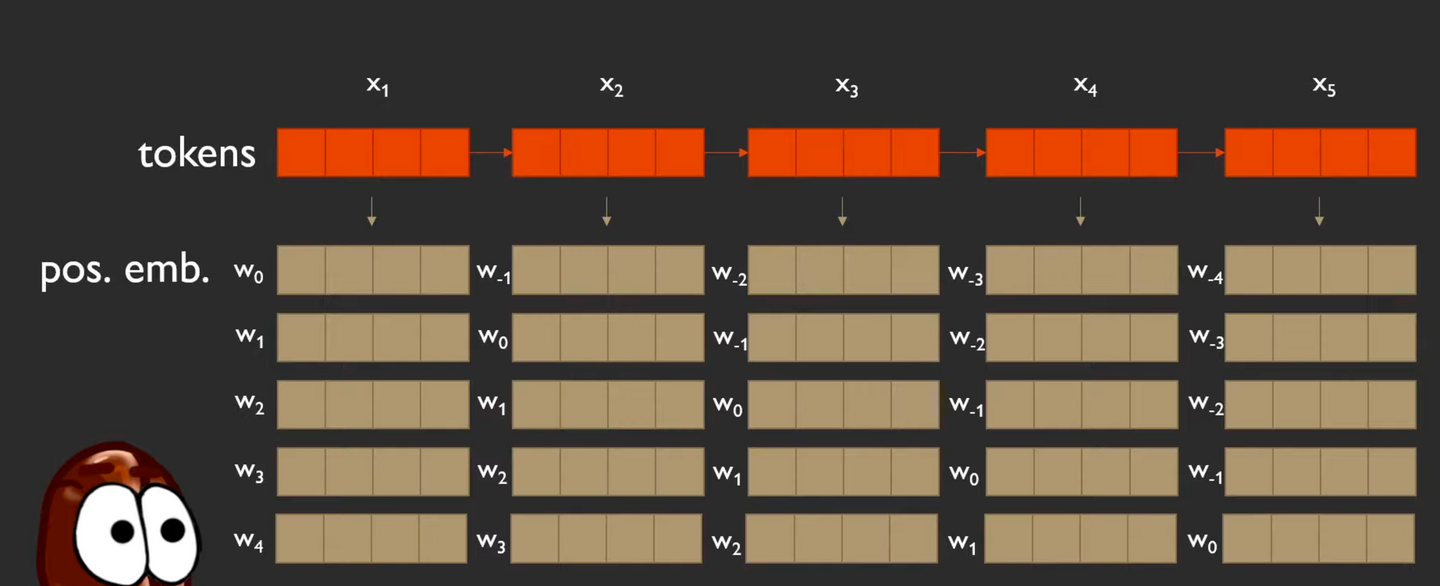
-
그리고 각 벡터는 하나의 토큰과 다른 토큰 사이의 관계(위치 거리)에서 비롯되기 때문에 아래처럼 쌍 별 표기법을 사용할 수 있다(pair-wise notation)
-
또한 에서 가 2인 경우, 같은 해당 positional embedding은 같은 값을 갖는다.
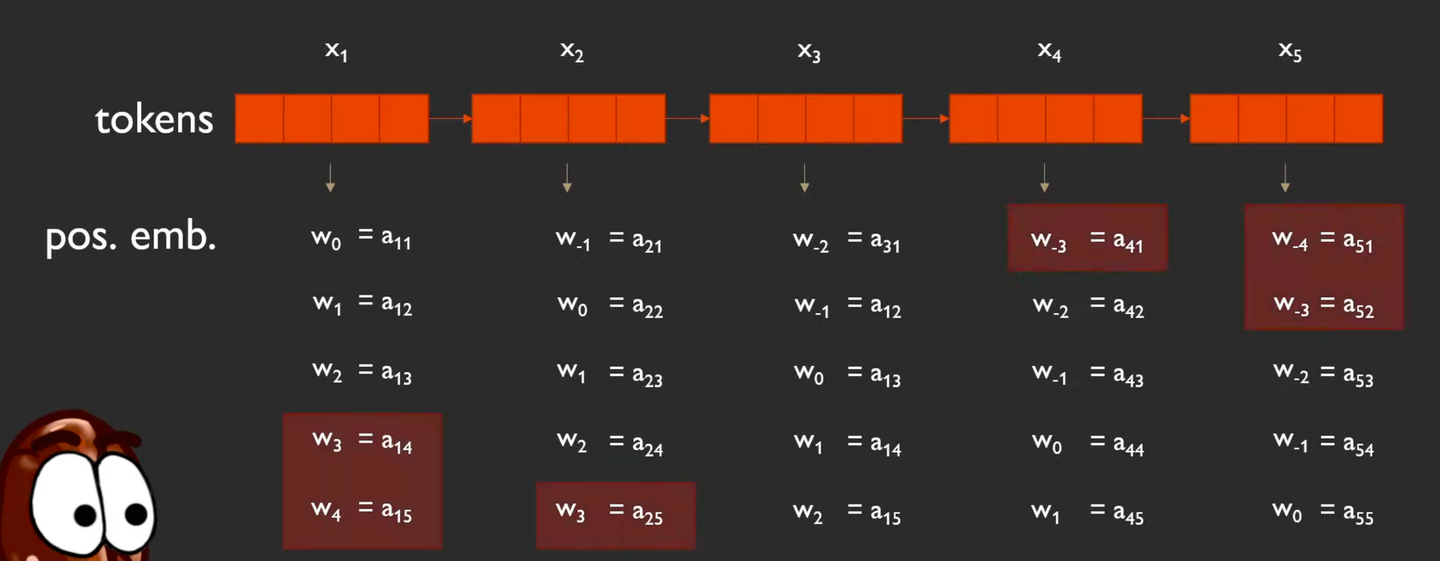
그러나 만큼 있는 positional embedding을 어떻게 처리해야할까?
⇒ 각 토큰마다 가지고 있는 총 토큰 개수만큼의 pe를 다 더해서 토큰과 곱하는 것은….. 토큰이 가진 semantic meaning에 혼동을 가져올 것.
⇒ 그렇다면, self-attention으로 연산하기!
- self-attention이 relative positional encoding에 대한 정보도 갖도록 공식을 수정해서 사용!
-
-
-
-
modified Self-attention with Relative Positional Encoding
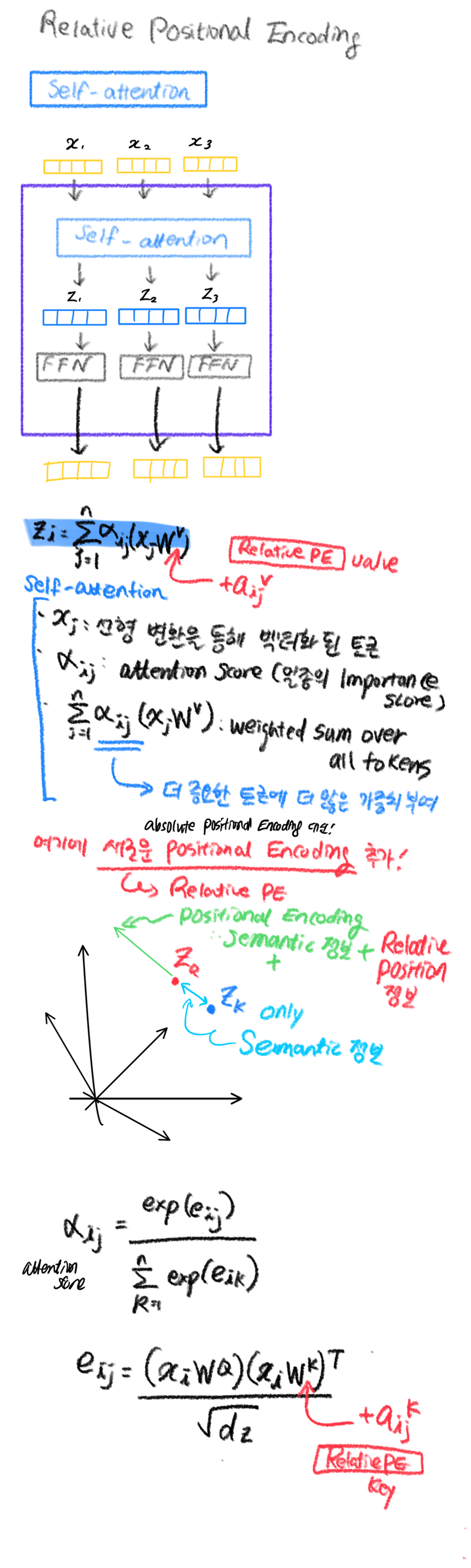
- 각 토큰은 하나의 PE만을 갖는다.
-
그럼, Relative PE의 장점과 특징
Self-Attention with Relative Position Representative논문에서는 텍스트로만 실험을 했지만, 텍스트가 아닌 요소 간에 pair relative 관계가 있는 모든 그래프 표현에 이 방법을 적용할 수 있다.- 이러한 상대적인 표현은 우리가 시퀀스에 있는지 아니면 더 복잡한 그래프에 있는지 상관 없이 한쌍의 토큰이 서로 얼마나 떨어져 있는지에만 의존하기 때문에 relative pe 사용 가능!
- 학습된 positional encoding은 모든 시퀀스 길이로 일반화된다는 것.
- 이렇게 되면 무언가 가까이 있거나 멀리 있다는 것만 저장할 수 있지만, 얼마나 먼지 구체적으로는 알 수 없다.
-
학습을 원활하게 하기 위해 앞단에 Layernorm을 적용하고, dropout을 통해 정규화를 해주었다.
Convolution Module

-
convolution module은 gating 매커니즘으로 시작한다.
- pointwise conv와 gated linear unit(GLU)
- 이것 다음엔 단일 1d depthwise conv layer가 온다.
- batchnorm은 딥러닝 학습을 돕기 위해 이 conv 이후에 적용이 된다
-
point-wise conv
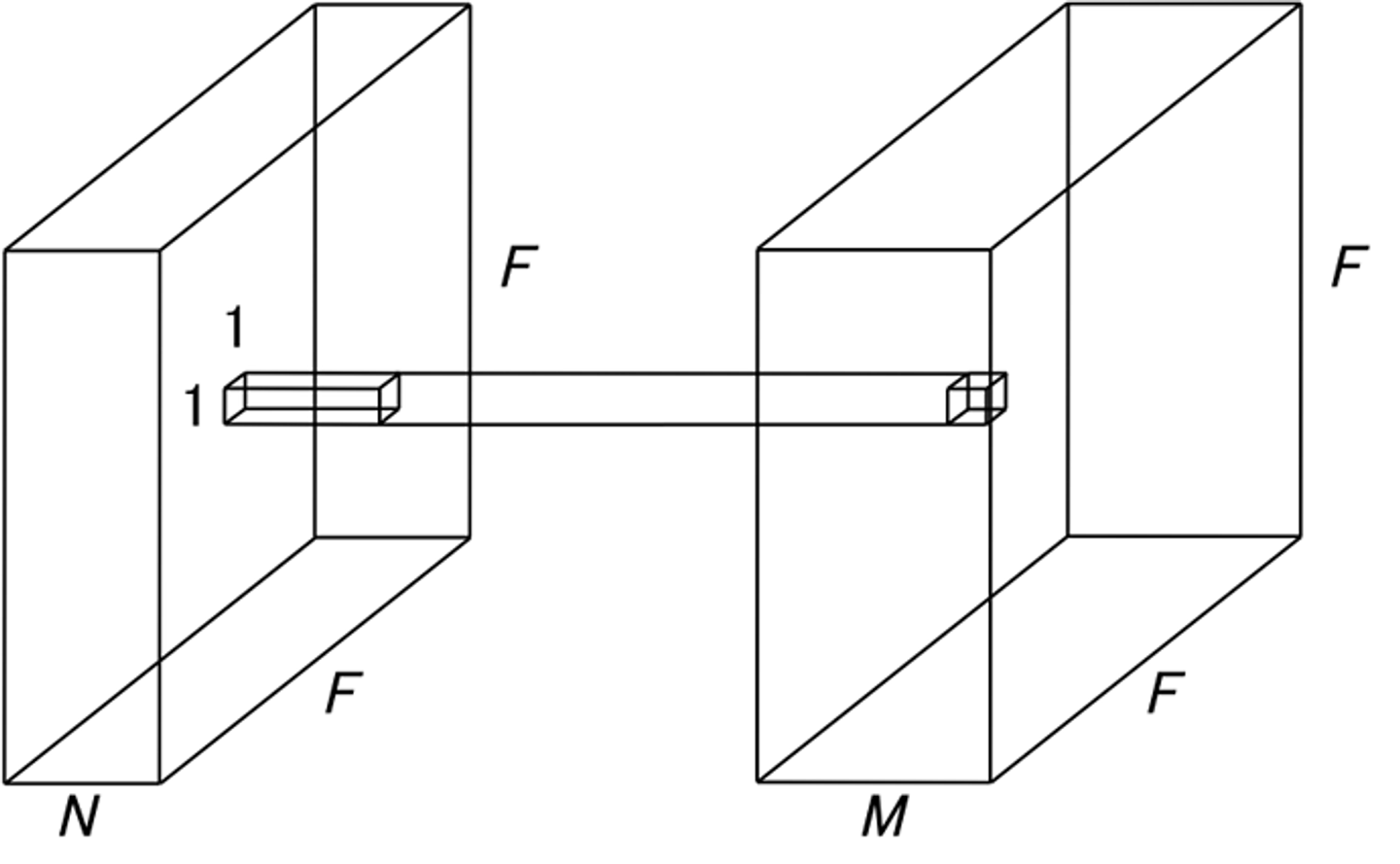
Point-wise Convolution의 filter의 크기는 1x1으로 고정되어 있기때문에 1 x 1 Convolution이라고도 불립니다.
channel들에 대한 연산만 수행하므로, output의 크기는 변하지 않고 channel의 수를 조절 할 수 있는 역할을 하게 됩니다.
보통 dimensional reduction을 위해 많이 쓰입니다. 이 것은 channel의 수를 줄이는 것을 의미하는데, 추후의 연산량을 많이 줄여줄 수 있어 중요한 역할을 하게 됩니다.
-
Glu Activation
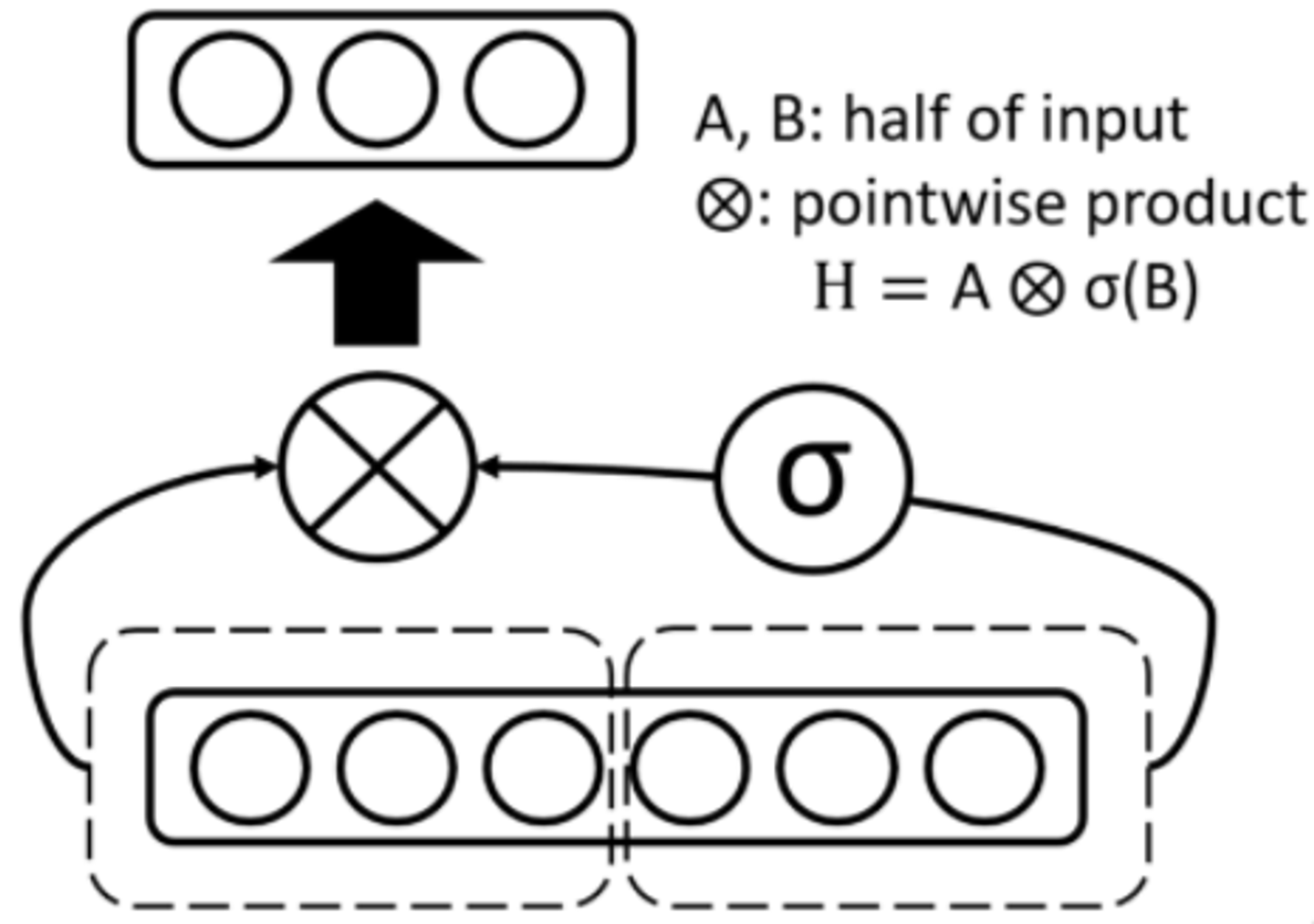
- 입력의 절반에 시그모이드 함수를 취한 것과, 나머지 입력의 절반을 가지고 point-wise 곱을 계산한다
- 따라서 출력 값의 차원은 입력 값의 차원의 절반이 된다.
class GLU(nn.Module): """ The gating mechanism is called Gated Linear Units (GLU), which was first introduced for natural language processing in the paper “Language Modeling with Gated Convolutional Networks” """ def __init__(self, dim: int) -> None: super(GLU, self).__init__() self.dim = dim def forward(self, inputs: Tensor) -> Tensor: outputs, gate = **inputs.chunk(2, dim=self.dim)** return **outputs * gate.sigmoid()**
-
Depth-wise Convolution
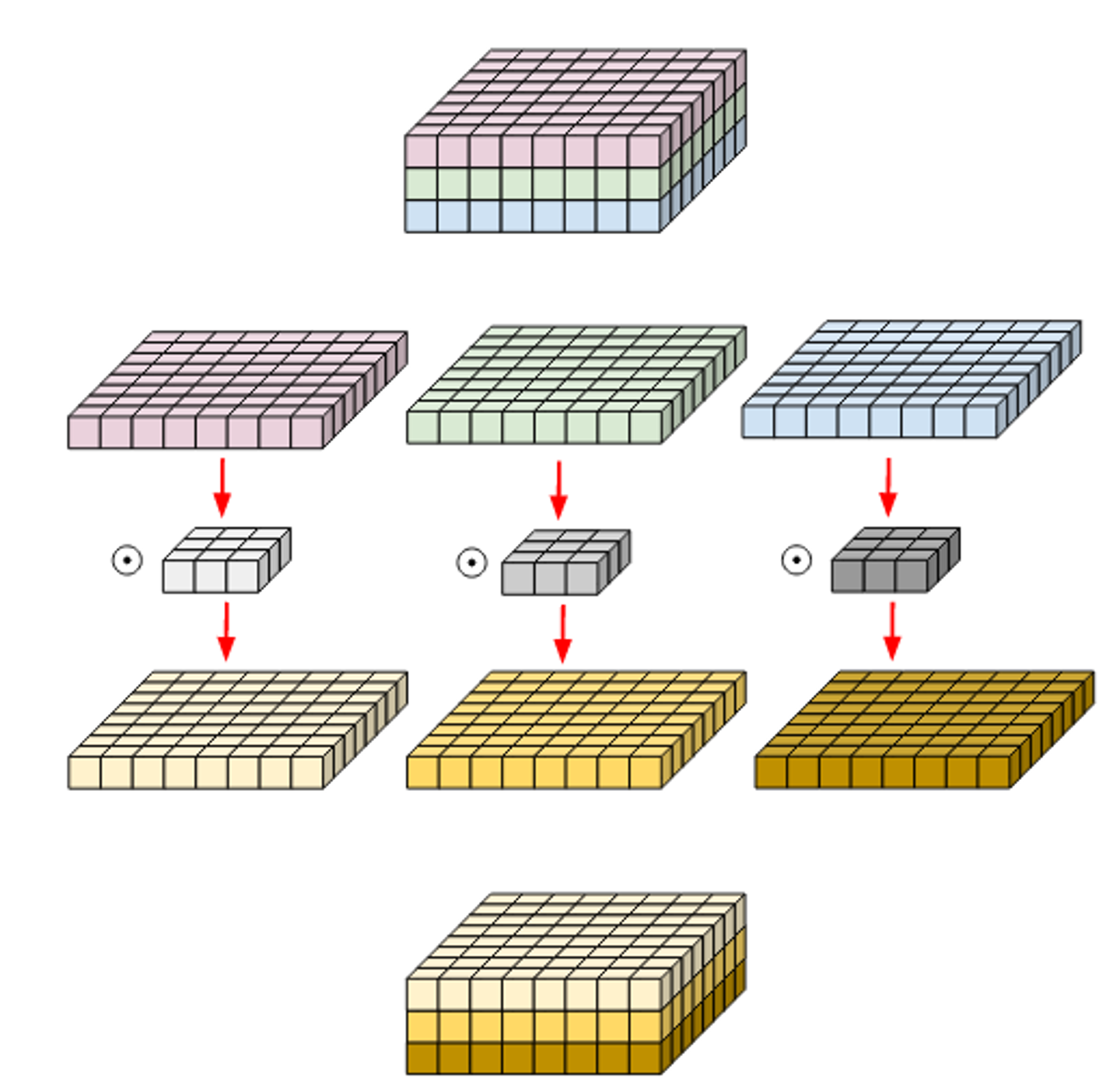
Depth-wise convolution은 Standard convolution이 각 채널만의 spatial feature(공간적 특징)를 추출하는것이 불가능하기 때문에 고안해낸 방법이라고 할 수 있습니다.
그렇다면 당연히 Depth-wise conv에서 하려고 하는것은 각 channel마다의 spatial feature를 추출하는 것입니다.
따라서 여기서는 각 channel마다 filter가 존재하게 되고, 이러한 특징때문에 input과 output의 channel이 같게됩니다.
-
Swish activation
- 어떤 연구에서는
Swish, 또 다른 연구에서는SiLU로 불린다-
sigmoid에 입력값 를 한 번 더 곱해주는 모습
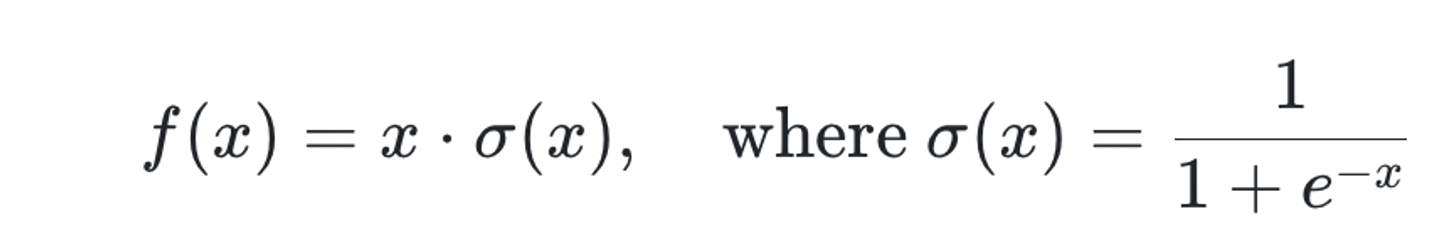
-
ReLU와 비교했을 때 음수 부분에서 좀 더 완만한 모습을 보인다.
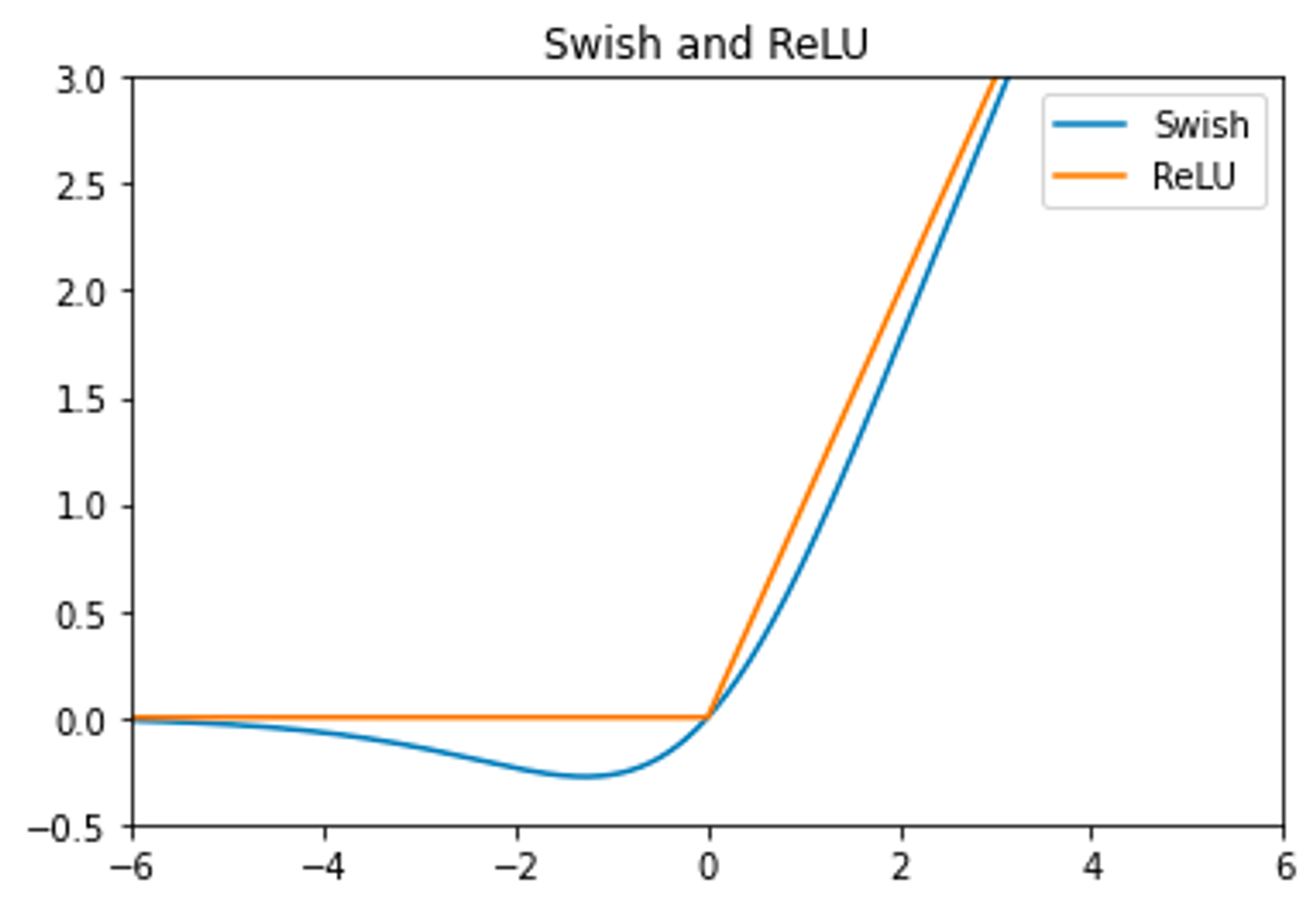
-
- 어떤 연구에서는
class Swish(nn.Module):
"""
Swish is a smooth, non-monotonic function that consistently matches or outperforms ReLU on deep networks applied
to a variety of challenging domains such as Image classification and Machine translation.
"""
def __init__(self):
super(Swish, self).__init__()
def forward(self, inputs: Tensor) -> Tensor:
return **inputs * inputs.sigmoid()**Feed Forward Module

- 그리고 두 선형 변환으로 구성되어 있다.
- 그리고 비선형 활성화 함수가 그 사이에 적용된다. (Swish Activation)
- residual connection은 Feed Forward layer 위에 추가되고, 그 이후에 layer normalization가 뒤따른다.
- 이런 구조는 Transformer ASR models로부터 도입되었다.
- Conformer는 pre-norm residual units을 따르고, residual unit 내에서, 그리고 첫번째 선형 계층 이전 입력에 layer norm을 적용했다.
- 또한 Swish activation, dropout을 적용했고,
- 그것들은 network 정규화를 돕는다.
Conformer Block
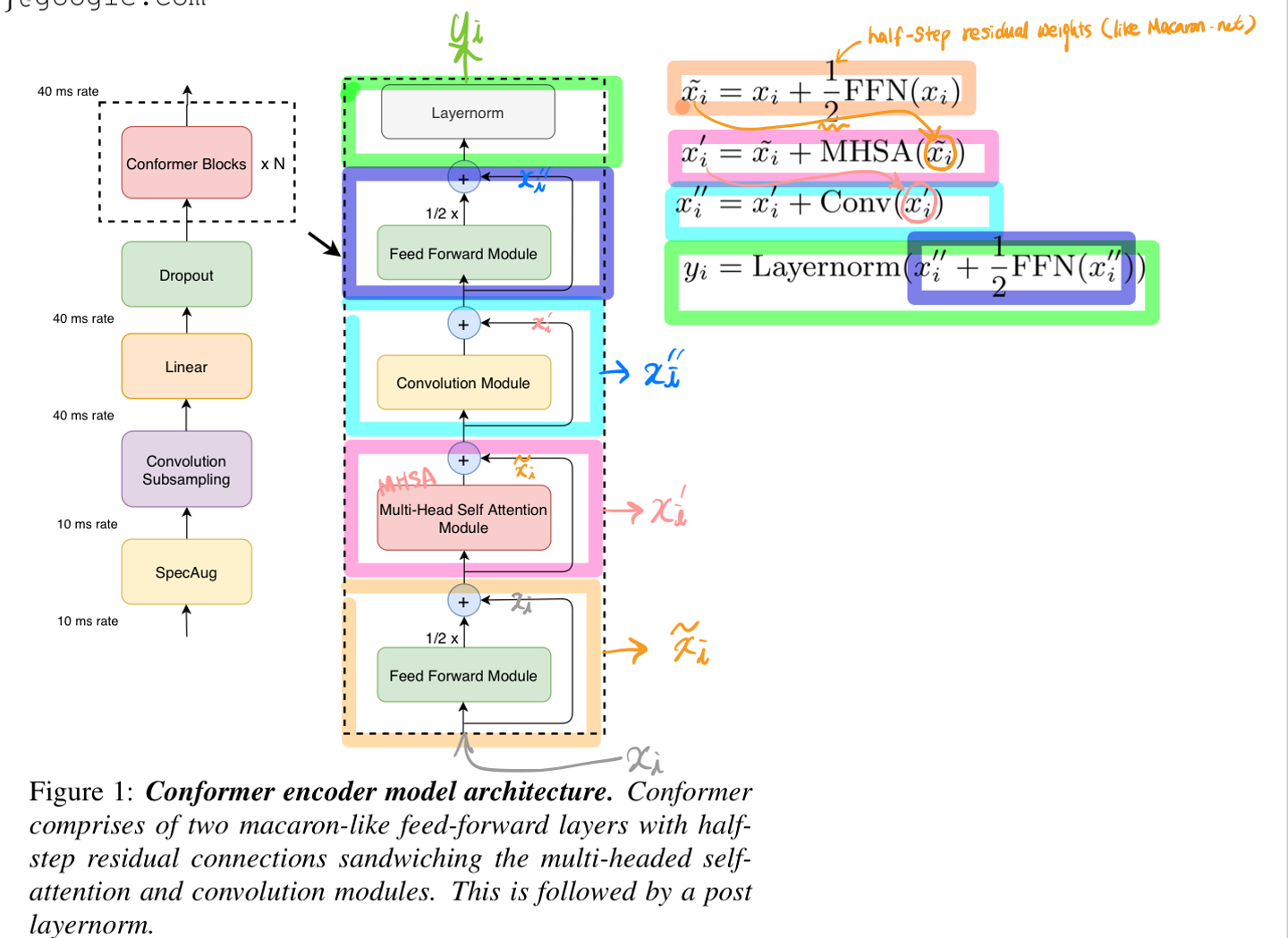
Conformer 구조
-
샌드위치 구조 (Macaron-Net)에서 영감
-
Transformer 블럭에 있는 original Feed Forward Layer를
two-half-stepFeed-forward layers로 대체- 하나는 attention layer 전에,
- 하나는 attention layer 다음에 온다.
-
Macaron-net처럼
half-step residual weights in FFN사용. -
두번째 feed forward module 뒤에 마지막 layernorm 레이어가 뒤따른다.
-
수식으로 확인해보면,

- : Feed Forward Module
- : Multi Head Self Attention
- : Convolutions module
-
sandwich structure
- 어텐션 레이어와 conv를 사이에 끼운 half-step residual connections
- single feed forward module 쓰는 거 보다 훨씬 효율이 좋았다.
- 어텐션 레이어와 conv를 사이에 끼운 half-step residual connections
-
음성 인식에서는 self-attention module 후에 convolution module을 쌓는 것이 더 좋다는 것을 발견.
Experiments
Data
- LibriSpeech
- 970 시간의 라벨링된 데이터
- 추가적으로 800M(8억) 개의 단어 토큰 corpus ( for building language model)
- 80 채널의 filterbank feature를 25ms 만큼의 윈도우로부터, 10ms 만큼의 stride 로부터 계산
- SpecAugment의 mask parameter (F=27), ten time masks with maximum time-mask ratio(ps=0.05), where the maximum-size of the time mask is set to ps times the length of the utterance(=발화의 길이)
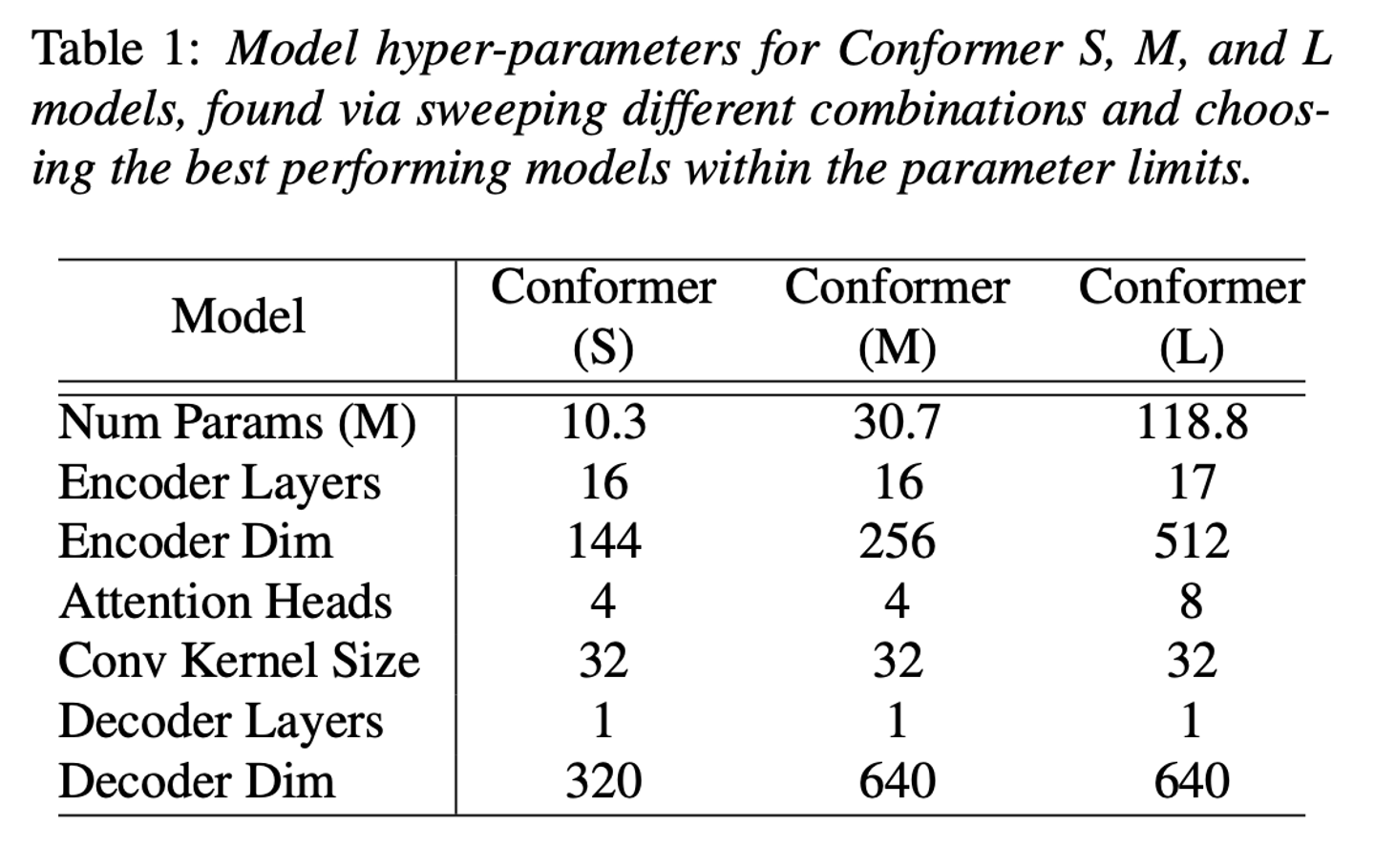
Conformer Transducer
- small (10M), medium (30M), large(118M) (params)
- 네트워크 깊이, 모델 차원, 어텐션 헤드의 개수 조합을 다르게 해서 모델의 파라미터 사이즈 제약 조건 내에서 제일 성능이 잘 나온 것을 사용.
- single-LSTM-layer decoder를 사용
- regularization을 위해서, 각 conformer의 residual unit에 dropout을 적용했다.
- module input으로 집어넣어지기 전에 각각의 module의 output에 적용.
- = 0.1
- Variational nosie 는 regularization으로서 모델에 적용되었다.
- 1e-6 weight의 L2 정규화도 또한 네트워크 내 모든 trainable weights에 적용
- Adam optimizer를 사용하는데 = 0.9, =0.98 ,
- transformer learning rate schedule은 10k warm-up step, peak learning rate 0.05/ d
- 여기서 d는 conformer encoder 내 모델의 차원이다.
- 3-layer LSTM language model을 사용해 STT 결과를 보정했다.
Ablation Studies
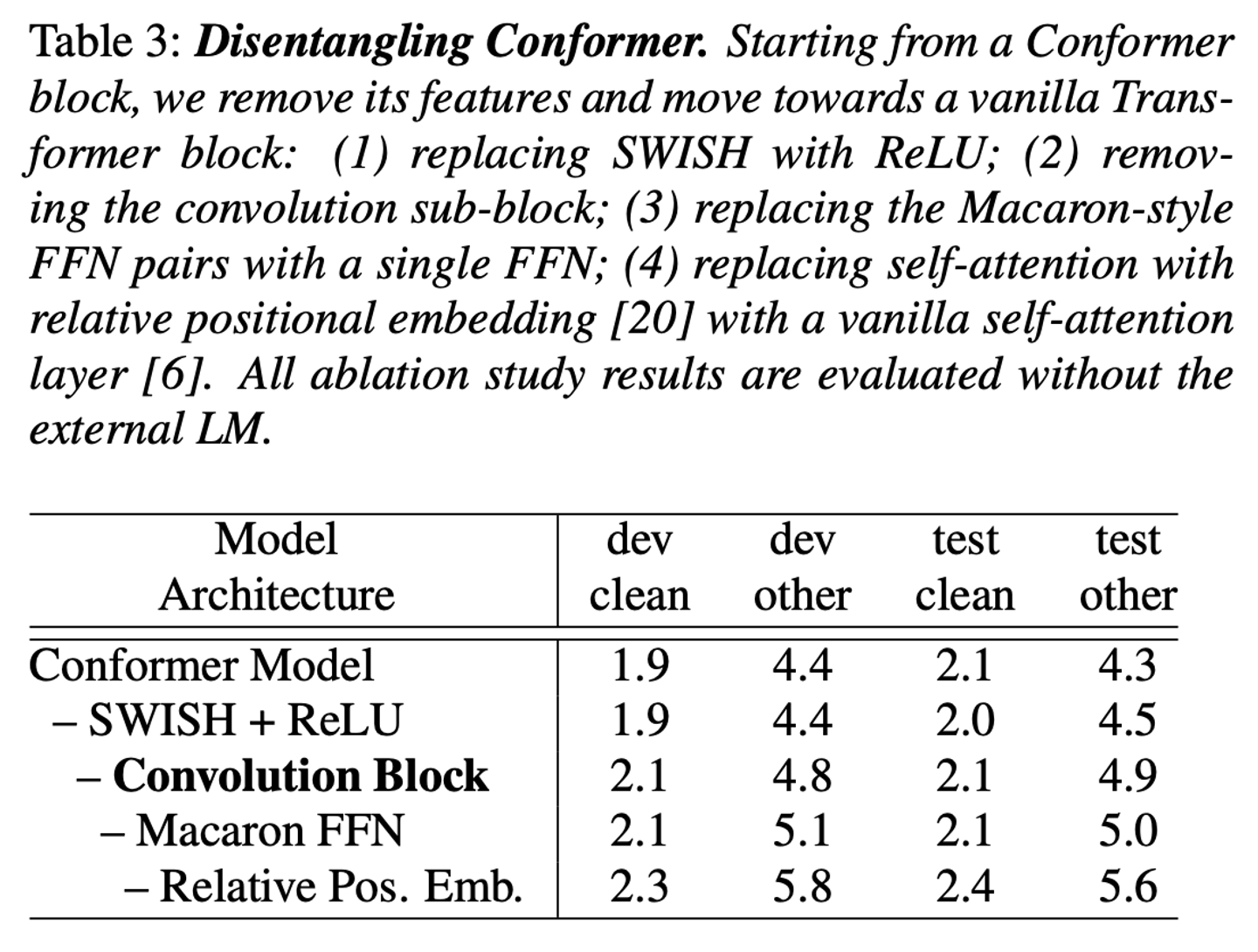
Conformer에서 도입한 요소들 중 어떤 것이 가장 성능에 영향을 많이 미쳤는지 확인하기 위해 하나씩 빼가면서 Ablation study 실시
- 그 결과, Conformer Model에서 Convolution Block이 영향을 많이 끼쳤음 을 알 수 있다.
Conclusion
- Conformer구조에서 self-attention구조에 convolution 모듈을 포함한 것이 성능에 중요한 영향을 미쳤고, 더 적은 파라미터 수로 더 좋은 성능을 얻었다.
Reference
- https://github.com/upskyy/Paper-Review/blob/main/Review/Conformer.md
- https://rimiyeyo.tistory.com/entry/SR-paper-Conformer-Convolution-augmented-Transformer-for-Speech-Recognition-파헤치기?category=910441?category=910441
- pointwise&depthwise conv: https://hichoe95.tistory.com/48
- swish activation: https://velog.io/@iissaacc/Swish-function
- https://github.com/sooftware/conformer
- Relative positional encoding
