Full Stack Deep Learning 강의를 듣고 정리한 내용입니다.
Neural Networks
📌Biological Neurons
- 외부의 자극이 dentrites를 통해 들어옴 ->역치를 넘어서면 firing함(axon을 통해 electrical potential전달)
📌Artificial Neuron
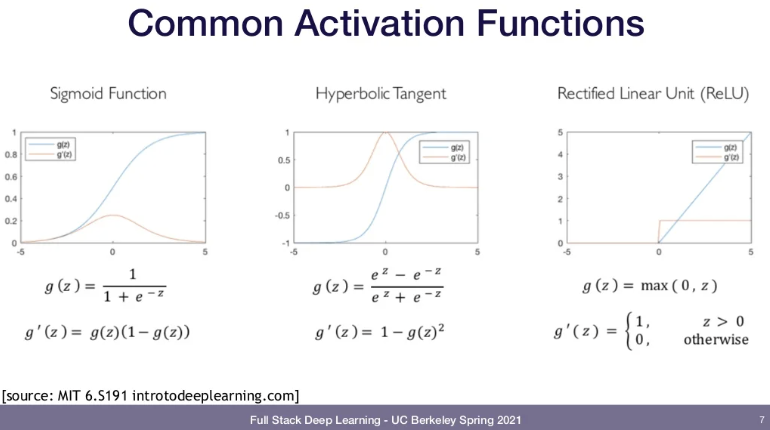
- input x: biological neuron에서 외부의 자극에 해당
- weight w: 자극에 대해 얼마나 영향을 받는지 조정
- b: bias
- activation function: (=threshold function) sum값이 역치를 넘어서면 on, 아니면 off
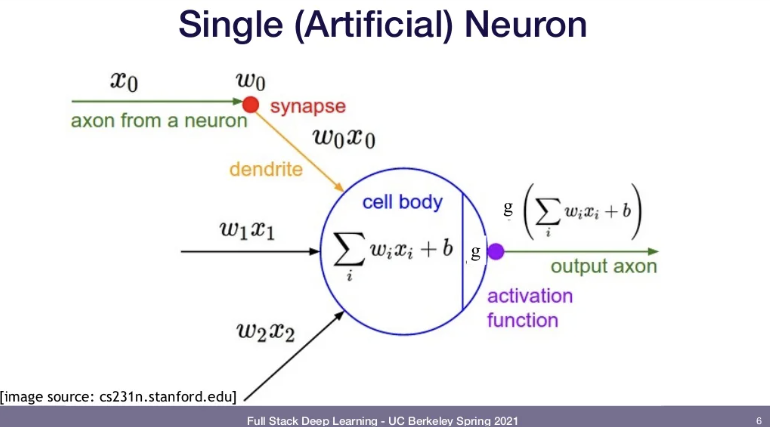
📌Common Activation Function
- Sigmoid Function
- Hyperbolic Tangent
- Rectified Linear Unit(ReLU)
Types of Learning Problems
![]()
📌 Unsupervised Learning
-
Unlabeled data X로 학습
-
GOAL: To learn the structure of data X
-
WHY? :
i) To generate more of the same kind of data(e.g. fake reviews, fake soundclips, etc)
ii) To obtain insights into what the data might hold -
e.g.1 Predicting next character in a string
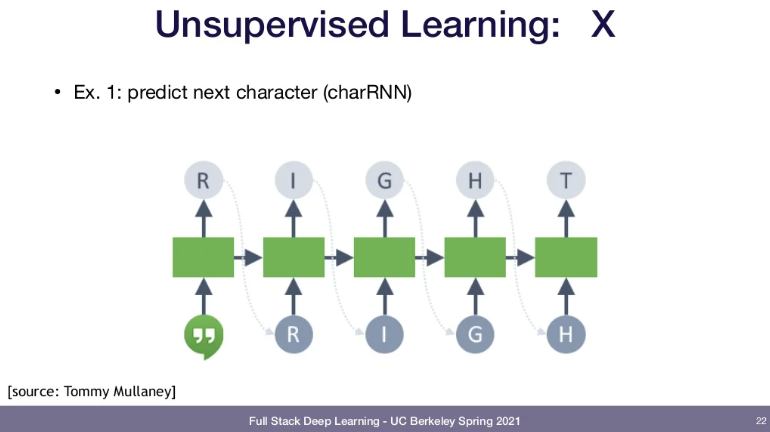
-> input type(글자들)과 model이 주어지면 RNN이 글을 쓴다. 아래는 character prediction의 예시이다.
Using RNN to feed in one character at a time and the RNN can output characters. What you end up learning is a language model. When you write a word, it will just keep writing by generating character by character. With an input type and model, it can generate paragraphs.
참고자료: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- e.g.2 Predicting word relationships
input: words in a vocabulary
-> 각 단어들을 벡터로 표현하고 학습된 시스템에 입력하면 man-woman, king-queen등의 관계를 파악한다.
Each words would be represented as a vector that's all zeros except for one in the place that corresponds to that word in some list of words. If you feed in a bunch of those vectors into a system that is properly set up and trained, you can determine that there are certain relationships between words like man-woman, king-queen.
- e.g.3 Predicting next pixel(pixelCNN)
-> 컴퓨터 비전 영역에서는 이미지의 픽셀 일부만 주어지면 나머지 부분을 자동완성하도록 응용할 수 있다.
_You can get something going with just a little bit of an image and then it auto-completes it.
📌 Supervised Learning
- Labeled data X(raw data), Y(label)로 학습
- Learn X -> Y
- GOAL: To learn a function in order to make predictions
- 상업적으로 사용하기에 가장 알맞음
📌 Reinforcement Learning
- Agent에게 특정 명령을 수행하도록 시켜 Environment와의 상호작용 확인
- GOAL: To learn how to take actions in an environment
- e.g. Train game-playing agents: move a robot in an environment and check if there's a reward associated or not
📌 (위의 세가지가 ML의 가장 대표적인 예시이고, 이 외에도 transfer learning, imitation learning, meta-learning, ...등 다양한 종류의 learning problem들이 존재한다.)
Empirical Risk Minimization
Empirical Risk Minimization = minimize loss L as measured (empirically) on the data
📌Linear Regression
2차원 그래프 : one-dimensional input과 one-dimensional output을 가짐.
GOAL: To minimize the loss function
find the setting of weights and biases like a and b in ax+b that minimize the loss function.
📌Neural Net Regression
- Find w,b parameters that optimize loss
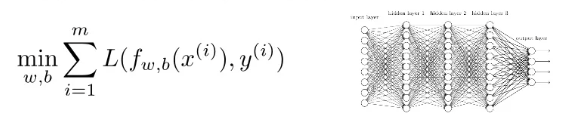
- Typical losses:
- Mean Squared Error(MSE)
- Huber loss(=more robust to outliers)
📌Neural Net Classification
-You try to predict from the input to some real valued output whereas in classification you predict from input to some categorical output. Outputs will be exactly 0, 1, 2, ... and these things will correspond to the label of the datapoint.
- Typical losses:
- cross entropy
Gradient Descent
📌Optimizing the Loss
-
GOAL: find w,b that optimize(=minimize the loss)
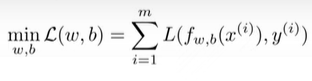
-
HOW: update each weight(wi)
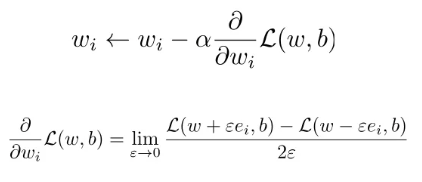
alpha: learning rate
gradient of the loss function with regard to the weight
📌Conditioning
-Well-conditioned data: zero-mean, equal variance
- First-order methods(You compute first order gradient and update the weight with that gradient)
- Initialization
- Normalization
- Second-order methods(compute second-order derivative of the loss function with regard to the weight. typically don't use this because computationally intensive.But there are some approximate second order methods that can be used to train neural networks more quickly)
- Exact:
- Newton's method
- Natural gradient
- Approximate second order methods:
- Adagrad, Adam, Momentum
- Exact:
📌Sampling Schemes for Gradient Descent
-We could compute the loss of every single data and update each weight, but in practice it is better to compute the gradient on just a subset of the data.
-> 모든 데이터의 loss를 계산해 각 weight를 업데이트 하기보다는 일부 데이터만 가지고 계산한다.
- Stochastic Gradient Descent
- Compute each gradient step on just a subset("batch")
of data -> 일부 데이터만 가지고 train 함 - PROS: less compute per step
- CONS: more noise per step
- Overall: faster progress per amount of compute
- Compute each gradient step on just a subset("batch")
Back Propagation
📌Gradients are just derivatives
-Neural Nets are made up of computations where each of the computations does have a gradient. So we can apply the chain rule to compute everything.
-NN 계산 시 chain rule을 사용함. 그리고 derivative를 직접 입력하지 않아도 됨->소프트웨어가 대신 해줌.
- Automatic differentiation software
- e.g. PyTorch, Tensorflow, Theano, Chainer, etc.
- 우리(사람)는 function f(x,w)만 프로그래밍 하면 됨
- software가 automatically computes all derivatives
- This is typically done by caching info during forward computation pass of f and then doing a bachward pass = "backpropagation"
Architectural Considerations
📌NN Architecture Considerations
-Data efficiency
- Sometimes we might need an infinitely large network or an extremely large amount of data to learn the weights
- In this case we can encode knowledge we have of the world into the architecture of the neural network.
e.g.
- Computer Vision: use convolutional networks = spatial translation invariance
- Sequence processing(e.g.NLP): use recurrent networks = temporal invariance(the rules of language are same no matter where in the sequence you are)
-Optimization landscape/conditioning
- Depth over Width(which one is better? depends!)/Skip connections, Batch/Weight/Layer Normalization
CUDA
📌Why did deep learning explosion kick off around 2013?
- Bigger datasets
- Good libraries for matrix computations on GPUs -> NVIDIA
📌Why are GPUs important?
- All NN computations are just matrix multiplications, which are well parallellized into the many cores of a GPU.
💡READING
http://neuralnetworksanddeeplearning.com/chap2.html