Full Stack Deep Learning 강의를 듣고 정리한 내용입니다.
📌AlexNet
-
Deep layer with 8 layers
-
First convnet winner
-
Innovated with ReLU and Dropout
- Dropout: some set of weights are set to zero randomly in training
-
Heavy data augmentation(flip, scale, etc)
- Fun fact: usually drawn as two parts, because the biggest GPU only had 3GB memory at the time
- 그래서 model distributed training을 했어야 했다. (model이 두개의 다른 GPU에 위치한 상태)
📌ZFNet
- 거의 AlexNet과 동일 + just tweaking some parameters
- famous for deconvolutional visualizations
- each layers detect a certain type of image patch.
- early layers: learn edge detection & texture detection(color detection)
- later layers: detect parts of objects, e.g., ears, eyes, wheels, etc.
📌VGGNet
- More layers!
- Only use 3x3 convolutions & 2x2 max pools
- increased channel dimension with each layer
- early layers: 64 channels- later layers: 512 channels
- has 138 million parameters
- most parameters are used in the later layers with the fully connected layers
-사용되는 parameter를 제한하기 때문에 적은 수의 parameter로 계산할 수 있다-> 빠름!
📌GoogleNet
- =inception net
- VGG만큼 저렴하지만 3%정도의 parameter만 사용한다
- No fully-connected layers
- Is just a stack of inception modules( network module more creative than the standard)
- injected classifier outputs not only at the end but also in the middle
- it let the network get gradient from the loss function at more spot than just at the end of the network
📌ResNet
- Very deep layer: 152 layers
- Down to 3.57% top-5 error(5%인 human performance보다 낮음!)
- most commonly used network now
- Problem: network가 깊어질수록 얕은 네트워크만큼의 성능을 내야하는데 그러지 않는 경우 발생
- due to vanishing gradient
-Solution: make an option to skip around layers- gradient가 vanish되는 경우 skip
- ResNet Variants
- DenseNet: using more skip connections (skip connection을 건너뛰고 싶은 해당 layer만이 아니라 다른 모든 부분에 다 연결함)
- ResNeXt: inception net + ResNet
📌SqueezeNet
- Focused on trying to reduce the number of parameters as much as possible
- Use constant 1x1 bottlenecking techniques
- number of channels never expands
📌Overall Comparison
![]()
![]()
📌Localization, Detection, and Segmentation
![]()
-
Classification: given an image, output the class of the object
-
Localization: Do classification, but also highlight where the object is in the image
-
Detection: given an image, output every object's class and location
-
Segmentation: label every pixel in the image as belonging to an object or the background
- Instance Segmentation: additionally differentiates between different objects of the same class
-
Using networks for Localization
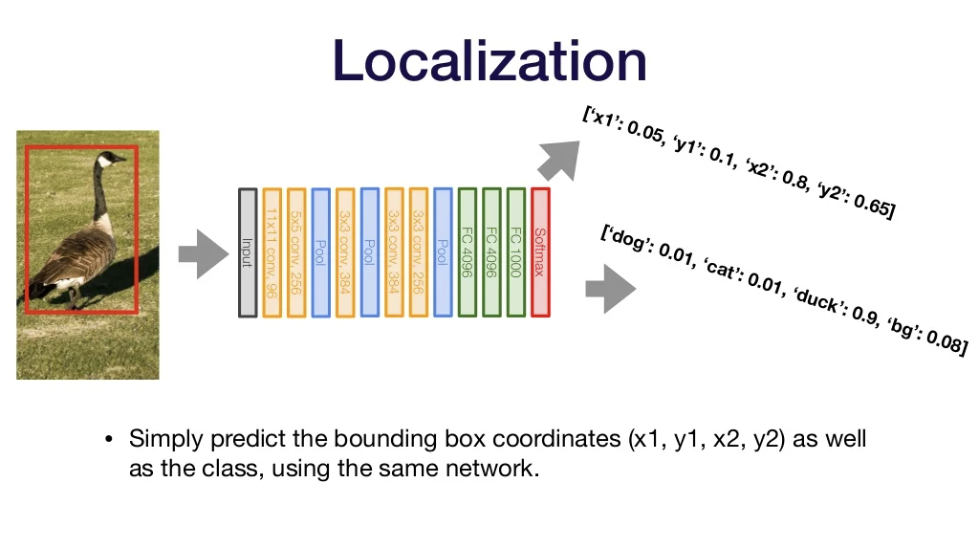
- output bounding box coordinates(x1,y1,x2,y2) as well as the class of an object
- class 결과를 제공할 때 사용하는 network와 동일한 네트워크를 사용해 마지막 단계에서 coordinate 예측값도 산출하게 한다. -
Using networks for Detection
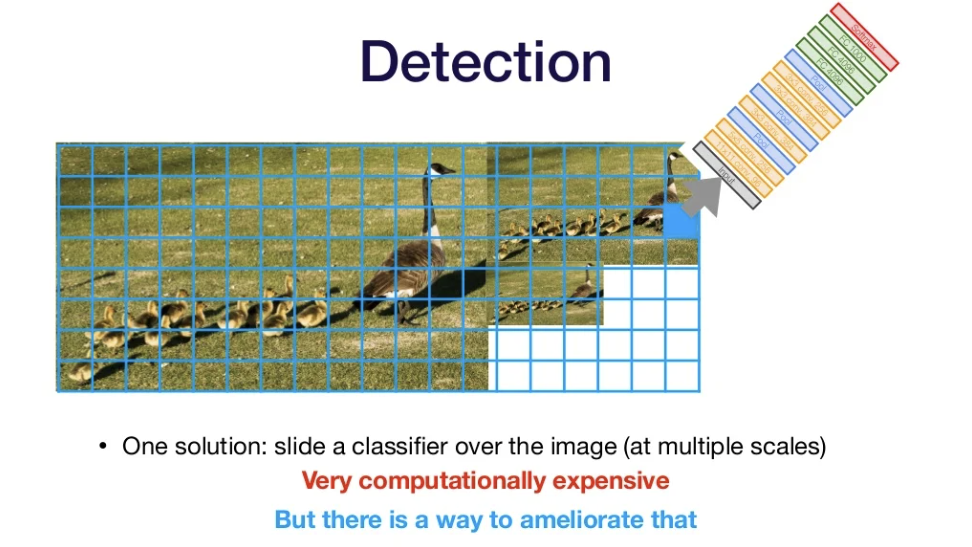
- 몇 개의 object가 있는지 모르는 상태라서 Localization에 사용한 방법을 사용할 수 없음
- Solution: slide a classifier over the image(at multiple scales)
- VERY computationally expensive, but 해결방법 있음!
📌Non-maximum Supression(NMS) and IOU
- Non-maximum Supression(NMS): When multiple bounding boxes overlap, you should keep the one with the highest score and remove all the others.
- Intersection over Union(IOU): most common metric for localization quality
📌YOLO/SSD
-
YOLO(You Only Look Once)
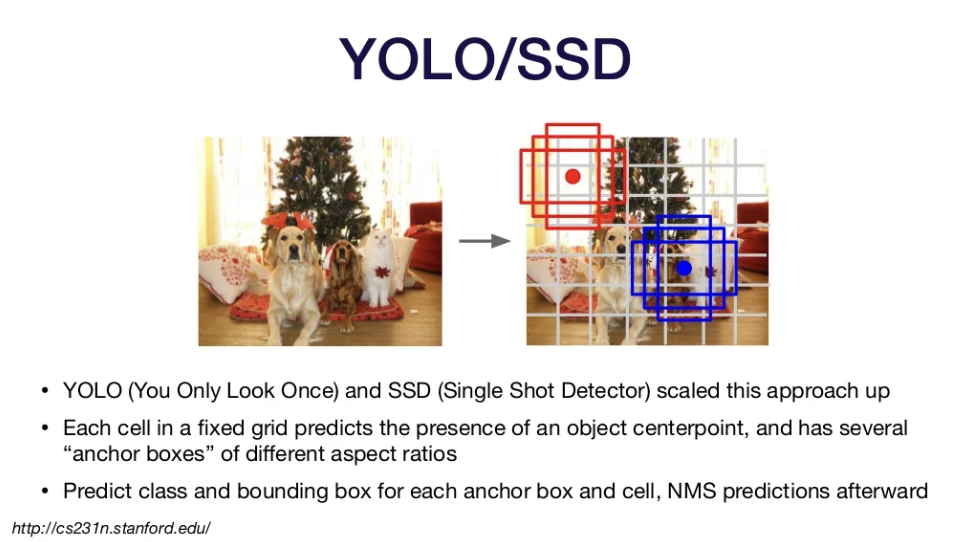
1. Put a fixed grid over an image, and within the grid find objects
2. Output class and box coordinates
3. Run non-maximum supression
- nice & fast, and is in active development! -
Microsoft COCO: Common Objects in Context

- 이 dataset을 가지고 YOLO의 성능을 평가함.
- 330,000 images & 1.5 million object instances & 80 categories & some captions
📌Region Proposal Methods
-
이제까지는 이미지의 모든 부분을 관찰함.
- 그러지 말고 중요해 보이는 부분만 관찰하면 어떨까? (look only at regions that seem interesting)
-
R-CNN(Region-CNN)
- Using external(non-deeplearning) methods to find regions
- Use AlexNet on regions
- Predict both class and bounding box(coordinates)
-
Faster R-CNN
-Used convnet for the Regional Proposal Network- Region Proposal Network(RPN): a fully convolutional method for scoring a bunch of candidate windown for "objectness"
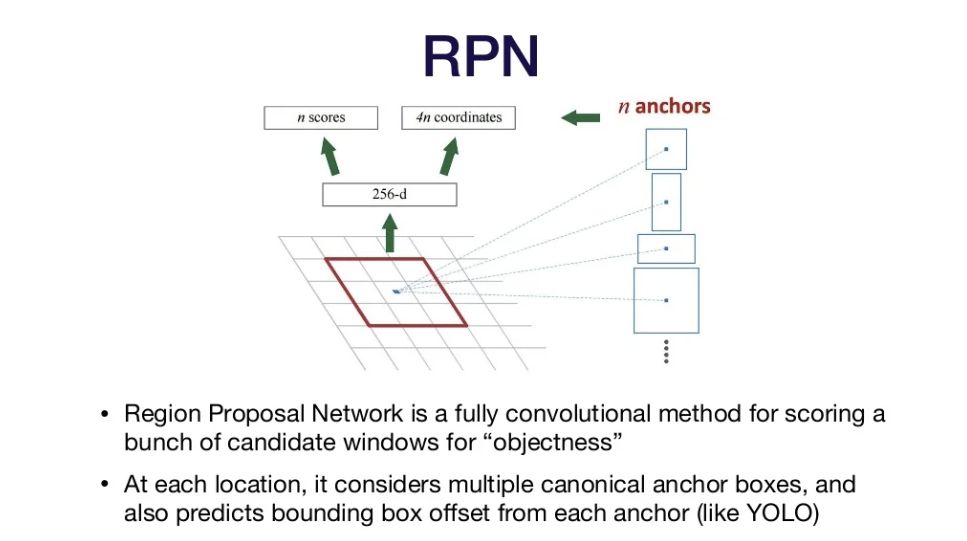
- Faster (because everything is done in the convnet!)
- Four losses total: classifier and bbox regression for both RPN and object classifier
- Region Proposal Network(RPN): a fully convolutional method for scoring a bunch of candidate windown for "objectness"
-
Mask R-CNN
-Each region goes in not only the classification but also the segmentation step- Regions go through a couple of non-downsampling convolutions
📌Adversarial Attacks
- Convnets can be brittle in unexpected ways
- Convnet 공격 방법
- Add noise to an image

- Add real things in real world such that when you take an image of it, it messes up the network

- 자율주행자동차 운행에 문제
- Add noise to an image
- Who would win?
- Detect 방법: try to find inputs that push the gradient of the network towards some class very strongly -Defend 방법:
- adversarial example을 같이 traing하기(doesn't work well)
- Smooth the class decision boundaries(= Defensive distillation)