![]()
Full Stack Deep Learning 강의를 듣고 정리한 내용입니다.
📌3 Buckets of ML Infrastructure & Tooling Landscape
![]()
- Data
- Sources
- Data Lake/Warehouse
- Processing
- Exploration
- Versioning
- Labeling- Training/Evaluation
- Compute
- Resource Management
- Software Engineering
- Frameworks & Distributed Training
- Experiment Management
- Hyperparameter Tuning- Deployment
- CI/Testing
- Edge(mobile/robotic hardware)
- Web
- Monitoring📌Software Engineering
- Programming Language
- Python, because of the libraries
- Clear winner in scientific and data computing
- Editors
- use text editors
- Vim, Emacs, Jupyter, VS Code, PyCharm
- VS Code makes for a very nice Python experience
- built-in git staging and diffing
- peek documentation
- Open whole projects remotely
- Lint code as you write
- Use the terminal integrated in the editor
- notebook port forwarding (opens notebooks(e.g.Jupyter) in the browser seamlessly)
- Linters and Type Hints
- Static analysis can catch some bugs(like using a variable never defined)
- Static type checking both documents code and catches bugs
- Jupyter Notebooks
- Notebooks have become fundamental to data science
- Great as the "first draft" of a project
- Jeremy Howard from fast ai. 추천!!(course.fast.ai videos)
- Problems with notebooks: hard to version, notebook IDE is primitive, very hard to test, out-of-order execution artifacts, hard to run long or distributive tasks
- Counterpoints to these problems: some companies has made good workflow in the notebook
- Streamlit
- New, but great at fulfilling a common ML need: interactive applets- Decorated normal Python code
- smart data caching, quick re-rendering
- Setting up environment
-
📌Compute Hardware
![]()
- GPU
- NVIDIA is the only game in town
- Google TPUs are the fastest
- Cloud
- Amazon Web Services, Google Cloud Platform, Microsoft Azure are the heavyweights.
- Heavyweights are largely similar in function and price.
- AWS most expensive
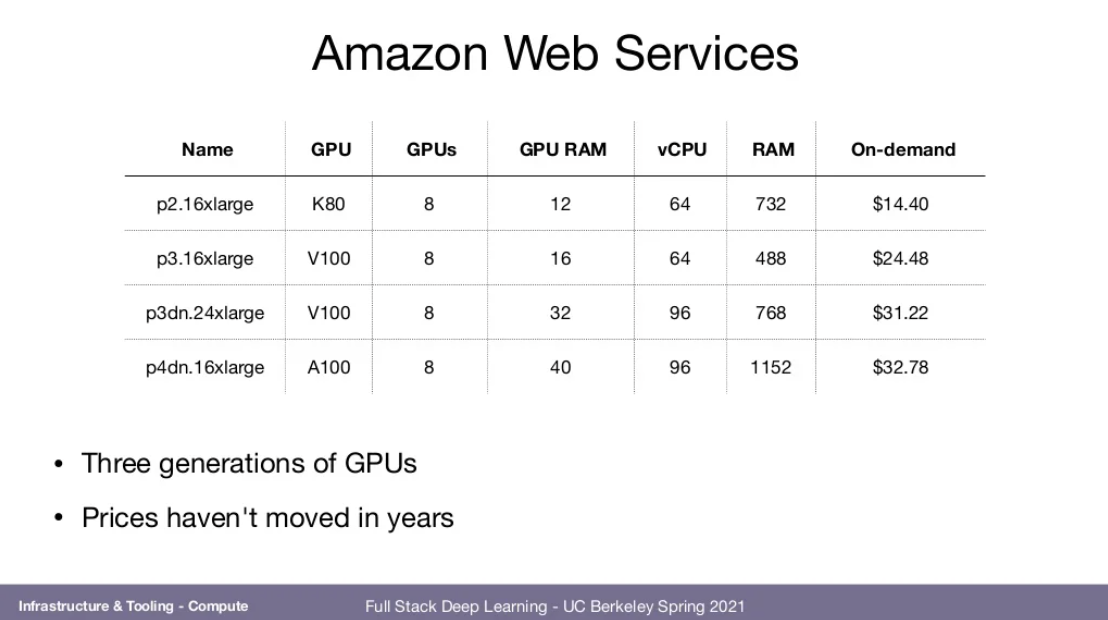
- GCP just about as expensive, and has TPUs
- Azure reportedly has bad user experience
- AWS most expensive
- Startups are Coreweave, Lamda Labs, and more
- On-prem
- Build your own
- Up to 4 Turing or 2 Ampere GPUs is easy
- All you need to know: http://timdettmers.com/2018/12/16/deep-learning-hardware-guide/
- Buy pre-built
- Lambda Labs, NVIDIA, and builders like Supermicro, Cirrascale, etc.
- Build your own
- In Practice
- Even though cloud is expensive, it's hard to make on-prem scale past a certain point
- Dev-ops(declarative infra, repeatable processes) definitely eadier in the cloud
- Maintenance is also a big factor
- Recommendation for hobbyist
- Development
- Build a 4x Turing or 2x Ampere PC
- Training/Evalutaion
- Use the same PC, just always keep it running
- To scale out, use Lambda or Coreweave cloud instances.
- Development
📌Resource Management
![]()
📌Deep Learning Frameworks
- Unless you have a good reason not to, use Tensorflow/Keras or PyTorch
- Both have converged to the same point:
- Tensorflow uses eager execution -> Pytorch랑 비슷한 code 작성 가능, and Pytorch got faster using TorchScript
- Most new projects use PyTorch (because it's more dev-friendly)
- fast.ai library builds on PyTorch with best practices
- PyTorch-Ligthning adds a powerful training loop
- Hugging face
- Tons of NLP-focused model architectures (and pre-trained weights) for both PyTorch and Tensorflow
- Distributed Training
- Using multiple GPUs and/or machines to train a single model.
- More complex than simplt running different experiments on different GPUs
- A must-do on big datasets and large models
- Data Parallelism
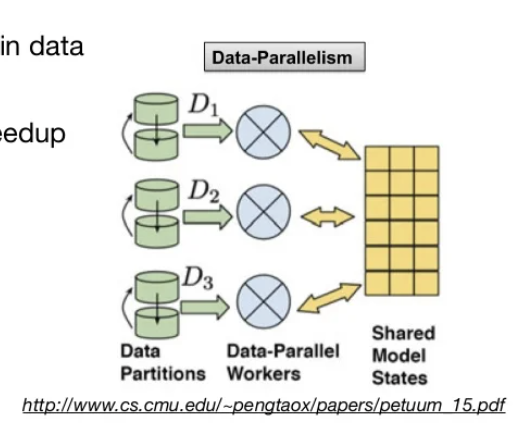
- If iteration time is too long, try training in data parallel regime
- For convolution, expect 1.9x/3.5x speedup for 2/4 GPUs.


- Model Parallelism
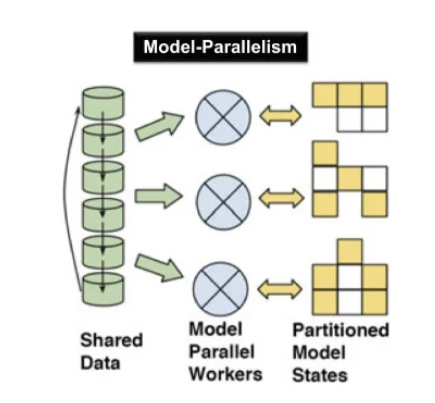
- Model parallelism is necessary when model does not fit on a single GPU
- Introduces a lot of complexity and is usually not worth it.(But this is changing.)
- Better to buy the largest GPU you can, and/or use gradient checkpointing
📌Experiment Management
- Problem:
- Even when running one experiment at a time, you can lose track of which code, parameters, and dataset generated which trained model.
- When running multiple experiments, problem is much worse.
- Solutions:
- Tensorboard
- A fine solution for single experiments
- Gets unwieldy to manage many experiments, and to properly store past work
- MLFlow Tracking
- self-hosted solution from DataBricks
- Comet.ml
- Weights & Biases
- publish reports with embedded charts, figures, etc.
- Tensorboard
📌Hyperparameter Tuning
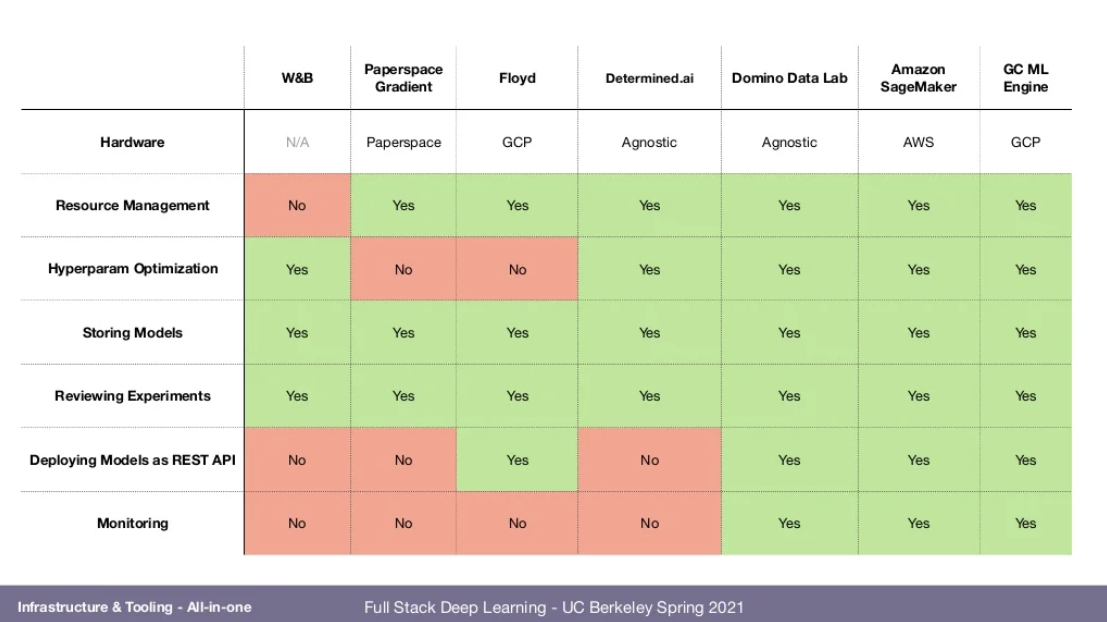
📌All-in-one Solutions
- Single system for everything
- development(hosted notebook)
- scaling experiments to many machines(sometimes even provisioning)
- tracking experiments and versioning models
- deploying models
- monitoring performance
- FBLearner Flow
- Google Cloud AI Platform
- Amazon SageMaker
- Neptune Machine Learning Lab
- FLOYD
- gradient by Paperspace
- Determined AI
- Domino Data Lab
:)
💡READING: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43146.pdf