![]()
Full Stack Deep Learning 강의를 듣고 정리한 내용입니다.
📌Transfer Learning in Computer Vision
-
Resnet-50와 같은 deep neural network(NN)들은 성능이 좋긴함.
-
But they are so large that it overfits on our small data.
-
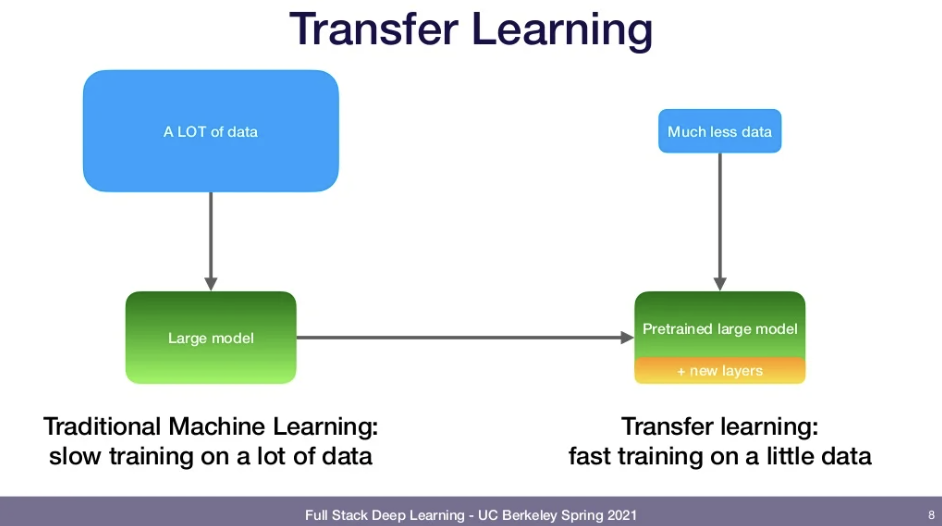
Solution: ImageNet을 사용해 NN을 train한 후 fine-tuning하기
-
Result: better performance!
-
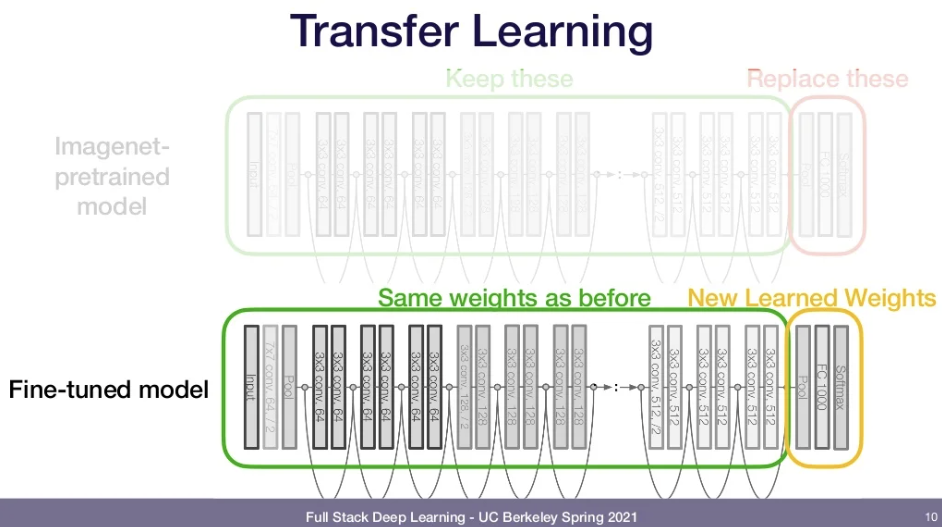
Fine-tuning model: ImageNet을 사용해 모델을 학습시킨 후 마지막 몇 개의 layer만 다른 것으로 replace.
-
Tensorflow와 Pytorch로 쉽게 구현 가능.
📌Embeddings and Language Models
- NLP에서의 input: sequence of words.
- Deep Learning에서의 input: vectors.
- How do we convert words to vectors?
- Idea: one-hot encoding
- look up whatever words you need to encode in the dictionary.
- All-zero vector except one at the position where that word is in the dictionary.
- Problem: scales poorly with vocab size.
- Logically violates what we know about word similarity
- SOL1)Map one-hot to dense vectors
- SOL2)Learn a Language Model
- "pre-train" for your NLP task by learning a really good word embedding
- How? -> train for a very general task on a large corpus of text(e.g., wikipedia).
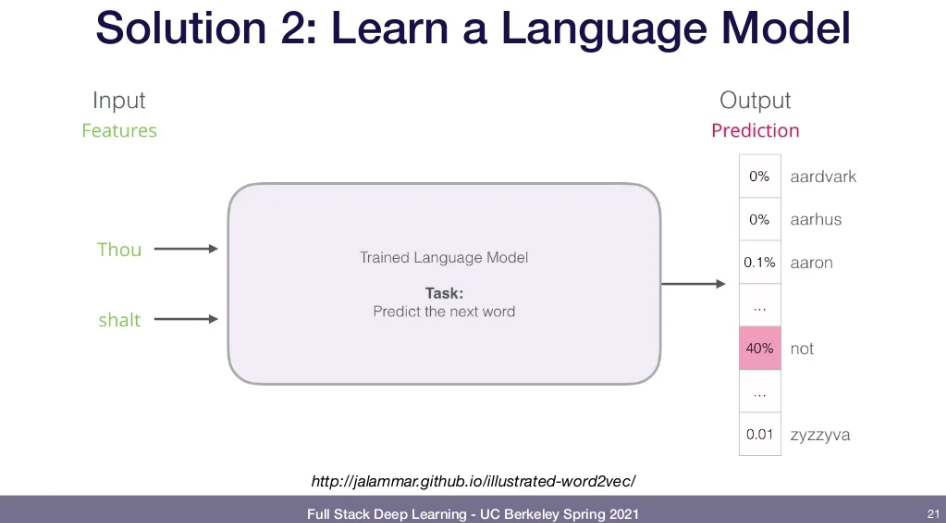
- N-Grams: Slide an N-sized window through the text, forming a dataset of predicting the last word.
- Skip-Grams: N-Gram의 성능을 향상시킬 수 있음. Look on both sides of the target word and form multiple samples from each N-gram.
- How to train faster: use binary instead of multi-class
📌NLP's ImageNet moment: ELMO and ULMFit on datasets
-
Word2Vec and GloVe embeddings became popular in 2013-14
-
많은 task에서 정확도를 큰 폭으로 높임.
-
But these representations are shallow:
- only first layer would have benefit of seeing all of Wikipedia
- rest of the layers would be trained on the task dataset( your data), which is way smaller
-
Why not pre-train more layers and disambiguate words, learn gramar, etc? -> ELMO 에서 처음 적용함
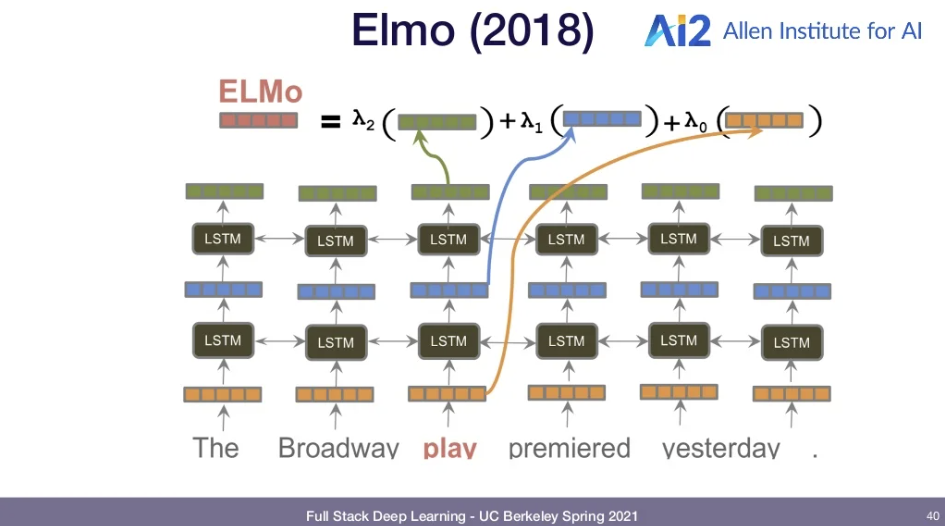
- SQuAD dataset

- SNLI dataset

- GLUE dataset

-
ULMFit
- similar to ELMO
- took hackers' approach to deep learning
📌Transformers
- 💡Attention in detail
- Input: sequence of tensors
- Output: sequence of tensors, each one a weighted sum of the input sequence
- Not a learned weight, but a function of x_i and x_j
- How do we learn weights?
- 1)Query: Compared to every other vector to comput attention weight for its own output y_i
- 2)Key: Compared to every other vector to comput attention weight w_ij for output y_j
- 3)Value: Summed with other vectors to form the result of the attention weighted sum
- Mulitiple Heads
- Layer Normalization
- Neural networks work best when inputs to a layer have uniform mean and standard deviation in each dimension.
- Layer 사이에서 normalization을 사용해 uniform mean + standard deviation 갖도록 하는 hack
- 💡BERT, GPT-2, DistillBERT, T5
- GPT, GPT-2
- Generative Pre-trained Transformer
- GPT learns to predict the next word in the sequence(generating text), just like ELMO or ULMFit
- 그치만 ELMO와 ULMFit은 embedding layer와 LSTM을 사용하고 GPT는 embedding layer와 transfer layer사용함.
- Uses masked self-attention
- BERT
- Bidirectional Encoder Representation from Transformers
- GPT(uni-directional)와 달리 bidirectional
- involves pre-training on A LOT of text w/ 15% of all words masked out
- also sometimes predicts whether one sentence follows another
- T5
- Text-to-Text Transfer Transformer
- Feb 2020
- Evaluated most recent transfer learning techniques
- Input and Output are both text strings
- Trained on C4(Colossal Clean Crawled Corpus) - 100x larger than Wikipedia
- 11B parameters
- SOTA on GLUE, SuperGLUE, SQuAD
- GPT-3
- DistillBERT
- a smaller model is trained to reproduce output of a larger model
- Transformers are growing in size
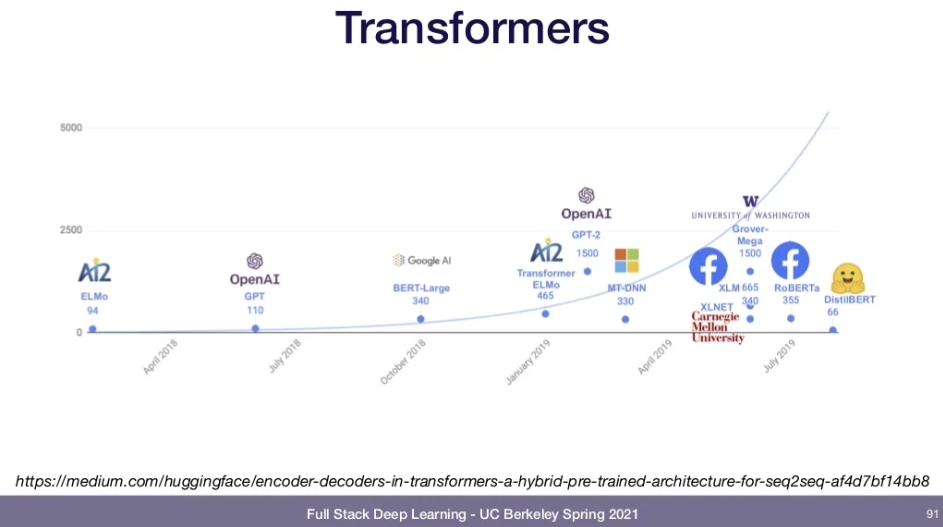
- GPT, GPT-2
📕READINGS
Attention is all you need(2017) http://peterbloem.nl/blog/transformers