
★ 연결 리스트
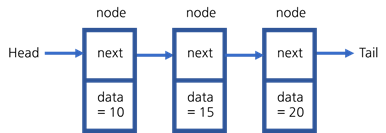
포인터를 사용하여 여러 개의 노드를 연결하는 자료 구조를 연결 리스트라고 합니다.
연결 리스트의 기본 구성 요소는 노드입니다. 노드에는 두 가지 정보가 들어있습니다. 첫 번째는 인접한 노드를 가리키는 next라는 이름의 포인터, 두 번째는 우리가 노드에 넣는 데이터를 가리키는 포인터입니다. (마지막 노드의 경우, 다음에 아무것도 없기 때문에 포인터가 null을 가리킵니다.)
이 리스트는 head라는 이름의 포인터에서 시작합니다. Head는 리스트의 첫 번째 노드를 가리킵니다. 힙에서는 이 연결 리스트의 head만 알고 있기 때문에, head.next 혹은 head.data 등으로 노드의 내용을 찾습니다. 하지만 연결 리스트의 길이가 매우 길 경우, 계속 head 뒤에 next를 붙일 수는 없습니다. 그래서 임시 포인터를 사용하여 탐색하는 방법을 사용합니다.
구현
public class LinkedList<E> {
// 노드 정의
class Node<E> {
E data;
Node<E> next;
public Node(E obj) {
data = obj;
next = null;
}
}
// 제일 앞의 노드
private Node<E> head;
// 제일 뒤의 노드
private Node<E> tail;
// 노드 개수를 세는 변수
private int currentSize;
// 기본 연결리스트
public LinkedList() {
head = null;
currentSize = 0;
}
// 맨 앞에 원소를 삽입
public void addFirst(E obj) {
Node<E> node = new Node<E>(obj);
// head가 가리키고 있는 맨 처음 노드의 주소값을 새로 만든 노드의 다음 노드 주소로 등록
// head가 새로 만든 노드를 가리키도록 한다. 이 두 줄의 순서가 중요!
node.next = head;
head = node;
currentSize++;
if (head.next == null) {
tail = head;
}
}
// 맨 뒤에 원소를 삽입
public void addLast(E obj) {
Node<E> node = new Node<E>(obj);
if (head == null) {
head = node;
tail = node; // head 포인터뿐만 아니라 tail 포인터도 바꿔줘야 합니다.
currentSize++;
return;
}
tail.next = node;
tail = node;
currentSize++;
}
// 맨 앞의 원소를 제거
public E removeFirst() {
// 경계 조건 1
if (head == null) {
return null;
}
E tmp = head.data;
// 경계 조건 2
if (head == tail) { // head.next == null, currentSize == 1도 가능
head = null;
tail = null;
} else {
head = head.next;
currentSize--;
}
return tmp;
}
// 마지막 원소를 제거
public E removeLast() {
// 자료 구조가 비어있는 경우
if (head == null)
return null;
// 자료 구조에 단 하나의 요소가 들어있을 때
if (head == tail)
return removeFirst();
// 그 외의 경우
// 임시 포인터 current, previous를 활용하여 마지막 노드를 제거합니다.
Node<E> current = head;
Node<E> previous = null;
while (current != tail) {
previous = current;
current = current.next;
}
previous.next = null;
tail = previous;
currentSize--;
return current.data;
}
// 위치에 상관없이 해당 요소 제거
public E remove(E obj) {
Node<E> current = head;
Node<E> previous = null;
// current가 null이면 끝까지 루프를 돈것
while (current != null) {
// 파라미터로 받은 obj와 중간의 요소의 주소 값은 무조건 다르므로 값이 같은지 비교하기 위해 comparable 사용
if (((Comparable<E>) obj).compareTo(current.data) == 0) {
if (current == head) // 노드가 1개 or 첫 번째 노드 제거
return removeFirst();
if (current == tail) // 마지막 노드 제거
return removeLast();
currentSize--;
previous.next = current.next; // 2. remove
return current.data;
}
// previous와 current 위치 계속 하나씩 옮기기
previous = current;
current = current.next;
}
// 루프를 다 돌아도 같은 것을 발견 못하면 제거 안했고 null 반환
return null;
}
// 특정 원소 포함 여부
public boolean contains(E obj) {
Node<E> current = head;
while (current != null) {
if (((Comparable<E>) obj).compareTo(current.data) == 0)
return true;
current = current.next;
}
return false;
}
// 마지막 원소 조회
public E peekLast() {
if (tail == null)
return null;
return tail.data;
}
// 향상된 for문 사용하기 위한 Iterator 인터페이스 구현
class IteratorHelper implements Iterator<E> {
Node<E> index;
public IteratorHelper() {
index = head;
}
public boolean hasNext() {
return (index != null);
}
public E next() {
if (!hasNext())
throw new NoSuchElementException();
E val = index.data;
index = index.next;
return val;
}
}
public Iterator<E> iterator() {
return new IteratorHelper();
}
}
위 코드는 연결 리스트의 내부 클래스에서 노드를 정의한 내용입니다. 그래서 외부에서 Node를 바로 직접적으로 접근할 수 없습니다. 노드는 next라는 포인터와 data를 가집니다.
data의 자료형은 E입니다. E는 정해지지 않은 자료형이고 이렇게 구현한 연결 리스트를 사용하면 그때 지정하겠다는 의미입니다. 그리고 next의 타입은 Node입니다. 다른 노드를 가리키는 포인터이기 때문입니다.
생성자까지 추가하여 코드를 적으면 노드 객체가 완성됩니다. 생성자에서는 객체를 data에 저장하고 next는 우선 null로 지정합니다.
노드의 개수를 세는 방법
노드의 개수를 직접 세는 방법보다 int 타입인 변수 currentSize를 만들어 노드의 개수를 세는 방법이 더 효율적입니다. 노드의 개수를 직접 셀 경우, 요소가 n개면 n번 세야 합니다. 따라서, 하나씩 세는 것의 시간 복잡도는 입니다. 하지만 currentSize라는 변수를 만들어놓고 리스트에 요소를 추가할 때마다 currentSize의 값을 늘려 놓으면, 리스트의 크기를 바로 알 수 있습니다. 이럴 경우, 시간 복잡도는 입니다.
배열과의 차이점
배열 또한 순서대로 여러 데이터를 저장할 때 사용한다는 공통점이 있습니다. 하지만 배열은 필요한 요소보다 너무 크게 만들거나 너무 작게 만들어 배열의 크기를 조정해야 한다는 문제점이 있습니다. 배열과 다르게, 연결 리스트는 항상 맞는 크기로 만들어지도록 설계되어 있습니다. 그래서 순차적인 데이터나 많은 양의 데이터가 있을 때 자주 사용됩니다.
★ 이중 연결 리스트
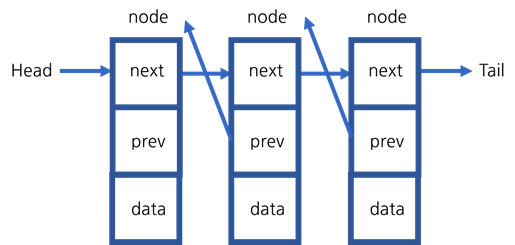
이중 연결 리스트는 단일 연결 리스트에 바로 전의 노드를 가리키는 previous 포인터를 추가한 연결 리스트입니다.
removeLast 메소드를 사용할 때, 단일 연결 리스트는 tail 포인터가 있더라도 의 시간 복잡도로 모든 노드를 한 번씩 거쳐야 한다는 단점이 있었습니다. 하지만 이중 연결 리스트는 tail 포인터가 가리키는 노드에서 previous 포인터가 가리키는 노드를 찾으면 되기 때문에 시간 복잡도가 이 됩니다.
이중 연결 리스트의 단점은 previous 포인터가 추가되기 때문에 노드를 추가하는 과정이 더 복잡해진다는 것입니다.
★ 원형 연결 리스트
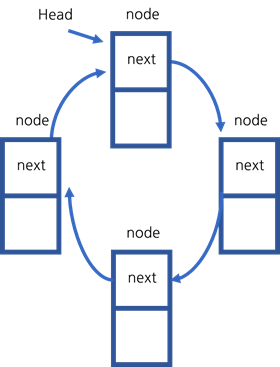
원형 연결 리스트는 마지막 next 포인터가 연결 리스트의 노드를 가리키는 연결 리스트입니다.
원형 연결 리스트의 tail의 next 포인터가 head를 가리키는지 확인하는 방법은 다음과 같습니다.
- tail 포인터를 사용하지 않을 경우, head에서 시작하여 이 될 때까지 반복한다면, 시간복잡도는 입니다.
- tail 포인터를 사용할 경우, 시간복잡도는 입니다.
tail의 next 포인터가 임의의 노드를 가리킨다면 확인하는 방법은 다음과 같습니다.
- tail에서 시작하여 tail 포인터가 다시 나타나는지 확인합니다. 시간복잡도는 입니다.
- 임시 포인터 2개를 사용하여 시작점을 잡고 currentSize만큼 떨어진 노드까지 확인한 후 시작점을 다음으로 옮겨 같은 노드가 나타날 때까지 반복합니다. 시간복잡도는 입니다.
