대용량 트래픽 처리를 위한 DB 고려 요소
- 성능: 대용량 데이터베이스를 다룰 때 가장 중요한 측면 중 하나는 성능입니다. 데이터베이스 시스템이 대용량 데이터를 효율적으로 처리하고 검색하는 능력은 매우 중요합니다.
- 확장성: 대용량 데이터베이스는 시간이 지남에 따라 계속해서 데이터가 증가할 수 있습니다. 따라서 확장 가능성이 중요합니다. 즉, 데이터베이스 시스템이 수평적으로(더 많은 서버 추가) 또는 수직적으로(더 강력한 서버로 업그레이드) 확장할 수 있는 능력이 필요합니다.
- 안정성과 신뢰성: 대용량 데이터베이스는 중요한 비즈니스 데이터를 포함하고 있으므로 데이터의 안정성과 신뢰성은 매우 중요합니다. 데이터의 손실이나 손상 없이 안정적으로 운영되어야 합니다.
- 기능과 기술: 각각의 데이터베이스 시스템은 고유한 기능과 기술을 제공합니다. 어떤 시스템이 더 적합한지는 데이터베이스 운영에 필요한 기능과 요구사항에 따라 다를 수 있습니다.
7조 티켓팅 프로젝트 분석:
- 쓰기, 읽기, 삭제 기능만 존재함
- 이벤트 기간 혹은 인기 강연 등록시 순간적으로 쓰기 트래픽 과다 발생(때문에 빠른 Insert 필요)
- 이벤트 기간 혹은 인기 강연 마감시 오토마우스 등 불필요한 트래픽 차단 필요
- 티켓팅 마감 되었을 경우 이미 지불한 사람에게 요금 자동 환불 && 빠른 lock
- 대기 순번 연동
티켓팅 DB 요구 사항(가정) :
-
실제 현업에서도 많이 쓰여야 함
-
레퍼런스가 많아야 함
-
대용량 트래픽 처리에 최적화 되어야 함 → DB 인덱스 특화, 쓰기 작업 다수
-
금액이 비싸지 않아야 함 (예산 최대 30만원)
-
고성능 트랜잭션 기능이 있어야 함(300명 정원 마감 게시글에서 마지막 300번 자리를 놓고 1천명이 경쟁할 때)
-
DB 분산화가 가능해야함 (샤딩)
-
비교표 :
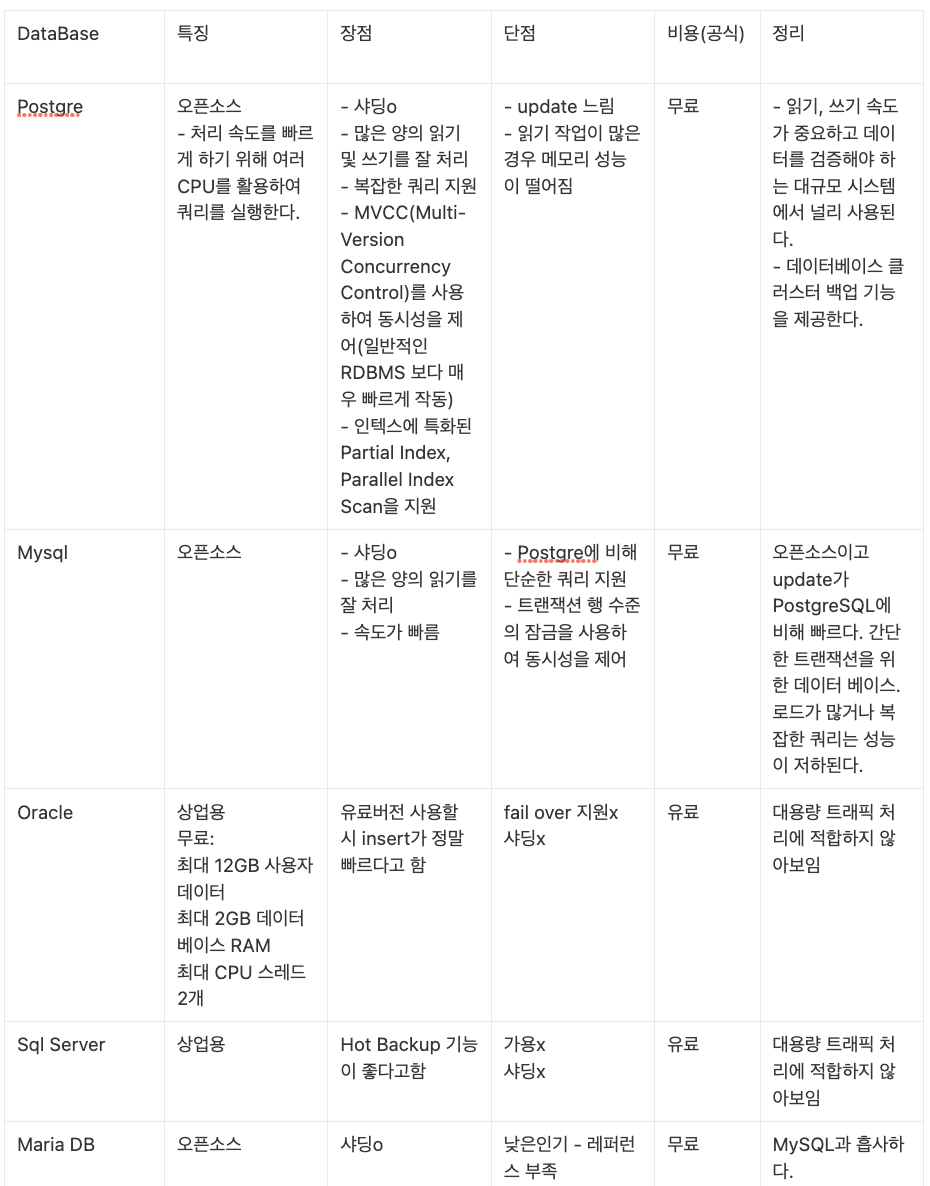
현재 여기까지 비교해봣을때 유력한 후보는 PostgreSQL 과 MySQL이다.
- PostgreSQL: PostgreSQL은 오픈 소스 객체-관계형 데이터베이스 시스템으로, 확장성과 성능이 뛰어나며, 다양한 데이터 타입을 지원합니다. 또한, PostgreSQL은 복제와 샤딩을 통해 고용량 트래픽을 처리할 수 있습니다. 트랜잭션 처리 능력이 뛰어나고, 많은 참조 자료가 있어 실제 환경에서 많이 사용됩니다. 또한, 오픈 소스이기 때문에 비용 부담이 적습니다.
- MySQL: MySQL은 가장 널리 사용되는 오픈 소스 관계형 데이터베이스 중 하나로, 높은 성능, 확장성, 유연성을 제공합니다. MySQL은 복제와 파티셔닝 기능을 통해 고용량 트래픽을 처리할 수 있습니다. 또한, InnoDB 스토리지 엔진을 사용하면 높은 성능의 트랜잭션 처리가 가능합니다. 많은 참조 자료가 있어 실제 환경에서 많이 사용되며, 오픈 소스이기 때문에 비용 부담이 적습니다.
- 트랜잭션 처리: PostgreSQL은
MVCC(Multi-Version Concurrency Control)를 사용하여 동시성을 제어합니다. 이는 여러 트랜잭션이 동시에 실행될 때 데이터 일관성을 유지하면서 성능을 향상시키는 데 도움이 됩니다. 반면에, MySQL은행 수준의 잠금을 사용하여 동시성을 제어합니다. 이는 동시에 많은 트랜잭션이 발생할 때 성능에 영향을 줄 수 있습니다. - 기능: PostgreSQL은 JSON, XML 등의 비관계형 데이터를 지원하며,
사용자 정의 함수, 트리거, 저장 프로시저등의 고급 기능을 제공합니다. 반면에 MySQL은 이러한 기능을 제한적으로만 지원합니다. - 확장성: PostgreSQL은 수직 및 수평 확장이 가능하며, 복제 및 파티셔닝 기능을 통해 대규모 트래픽을 처리하는 데 더 유리합니다. 반면에 MySQL은 주로 수직 확장에 초점을 맞추고 있습니다.
- 성능: PostgreSQL은
복잡한 쿼리와 대규모 데이터베이스에 대해 더 높은 성능을 제공합니다. 반면에 MySQL은간단한 쿼리에 대해 빠른 응답 시간을 제공하지만, 복잡한 쿼리에 대해서는 PostgreSQL보다 성능이 떨어질 수 있습니다
MVCC가 뭐지?
→ 한 사용자의 변경이 다른 사용자에게 즉시 보이지 않게 합니다. 이로 인해 사용자는 동시에 발생하는 다른 트랜잭션의 영향을 받지 않고 일관된 데이터베이스 상태를 볼 수 있습니다. 만약 내가 영화 예매를 하려는데 누가 먼저 예약을 선점해도 내 화면엔 예약이 안된걸로 보임
행 수준 잠금시 대량 트래픽 처리에 어떤 불이익이 있는데?
→ MySQL에서 행 수준 잠금이라는 것은, 데이터베이스에서 데이터를 처리하는 방식을 의미합니다. 이것을 일상적인 상황으로 비유하자면, 도서관에서 한 권의 책을 빌리는 상황으로 생각해 볼 수 있습니다.
도서관에는 많은 책들이 있습니다. 그 중에서 한 권의 책을 빌리려고 할 때, 그 책은 잠시 동안 다른 사람이 빌릴 수 없는 상태가 됩니다. 즉, 책을 빌리는 사람이 그 책을 '잠가' 버리는 것입니다. 이것이 바로 MySQL에서의 행 수준 잠금입니다.
이제, 많은 사람들이 동시에 같은 책을 빌리려고 한다면 어떻게 될까요? 한 사람이 책을 빌리는 동안, 다른 사람들은 기다려야 합니다. 이로 인해 도서관에서 책을 빌리는 전체 과정이 느려질 수 있습니다. 이것이 바로 MySQL에서 많은 트랜잭션이 동시에 발생할 때 성능 저하가 발생하는 이유입니다.
즉, 행 수준 잠금은 데이터의 일관성을 유지하기 위해 필요하지만, 동시에 많은 요청이 발생하는 상황에서는 성능 저하를 일으킬 수 있습니다. 따라서 이러한 특성을 고려하여 데이터베이스를 설계하고 운영해야 합니다.
사용자 정의 함수, 트리거, 저장 프로시저란?
- 사용자 정의 함수(User-Defined Functions) : 이는 데이터베이스 사용자가 필요에 따라 직접 만든 함수를 말합니다. 예를 들어, 우리가 쇼핑몰에서 할인율을 계산하는 함수를 만들 수 있습니다. 이 함수는 원래 가격과 할인 가격을 입력으로 받아, 할인율을 계산하여 반환합니다. 이렇게 사용자 정의 함수를 사용하면 복잡한 계산이나 로직을 데이터베이스 내에서 직접 처리할 수 있습니다.
- 트리거(Triggers): 트리거는 특정 이벤트(데이터 삽입, 수정, 삭제 등)가 발생했을 때 자동으로 실행되는 코드를 말합니다. 예를 들어, 우리가 은행에서 계좌 이체를 할 때, 한 계좌에서 돈을 빼는 동시에 다른 계좌에 돈을 넣는 작업이 필요합니다. 이런 경우 트리거를 사용하면 한 작업이 성공했을 때만 다른 작업이 실행되도록 할 수 있습니다. → 얘 특히 필요해보임. 티켓팅 취소 될 때 다음 순번이 자동으로 채워지게끔
- 저장 프로시저(Stored Procedures): 저장 프로시저는 데이터베이스에 저장되어 필요할 때 호출하여 사용하는 코드 블록입니다. 예를 들어, 우리가 쇼핑몰에서 주문 정보를 조회하는 작업을 자주 수행한다면, 이 작업을 수행하는 코드를 저장 프로시저로 만들어 데이터베이스에 저장해두고 필요할 때마다 호출하여 사용할 수 있습니다.
수직 확장, 수평 확장, 복제 및 파티셔닝 이란?
- 수직 확장(Vertical Scaling): 수직 확장은 기존의 서버에 더 강력한 CPU, 더 많은 RAM, 더 큰 디스크 등을 추가하는 방식
- 수평 확장(Horizontal Scaling): 수평 확장은 새로운 서버를 추가하여 시스템의 용량을 늘리는 방식
- 복제(Replication)와 파티셔닝(Partitioning): 복제는 데이터를 여러 서버에 동일하게 저장하는 것을 말하며, 파티셔닝은 데이터를 여러 부분으로 나누어 서로 다른 서버에 저장하는 것
“PostgreSQL은 수직 및 수평 확장이 가능하며, 복제 및 파티셔닝 기능을 통해 대규모 트래픽을 처리하는 데 더 유리합니다. 반면에 MySQL은 주로 수직 확장에 초점을 맞추고 있습니다.”
이게 무슨 뜻?
→ MySQL은 원래 웹 애플리케이션과 같은 상대적으로 간단한 사용 사례를 위해 설계되었습니다. 이러한 애플리케이션에서는 대개 하나의 데이터베이스 서버만 필요로 하며, 이 서버는 웹 서버와 밀접하게 통신하여 사용자의 요청을 처리합니다. 즉, DB 서버의 수평 분산에는 적합하지 않는다는 뜻
간단한 쿼리 예시 :
SELECT * FROM users WHERE age > 18;복잡한 쿼리 예시 :
SELECT users.name, orders.order_date
FROM users
INNER JOIN orders ON users.id = orders.user_id
WHERE users.age > 18 AND orders.status = 'completed'
ORDER BY orders.order_date DESC;대규모 데이터베이스의 기준이 뭐지?
정확한 기준은 없지만 일반적으로, 수백만 개 이상의 레코드를 가진 데이터베이스나 수십 GB 이상의 디스크 공간을 차지하는 데이터베이스 또는 많은 수의 테이블과 복잡한 관계를 가진 데이터베이스를 일반적으로 "대규모 데이터베이스” 라고 말함.
결론 : 현재까진 PostgreSQL 이 가장 적합한듯 함
그렇게 생각한 이유 :
-
대용량 트래픽 처리를 하기 위해서 DB는 오픈소스여야함. 오픈소스가 아닌 경우 요금이 발생하는데 액수가 어마어마함…
-
우리 프로젝트는 수많은 사용자가 짧은 시간안에 몰림. 심지어 환불 취소까지 발생함. 이럴 경우 빠르고 정확한 트랜잭션이 중요.
-
“읽기” 못지 않게 “쓰기” 작업이 많은 서비스
-
MySQL의 행 수준 잠금은 순간적으로 많이 몰리는 우리 서비스에 적합하지 않아보임.
-
DB 수직 확장은 한계가 명확하다. CPU, 메모리를 무한 대로 늘릴 수는 없다. 또한, 자동복구(failover)나 다중화가 되지 않아 장애 대응이 어렵다.
-
참고자료:
