두 번째 글
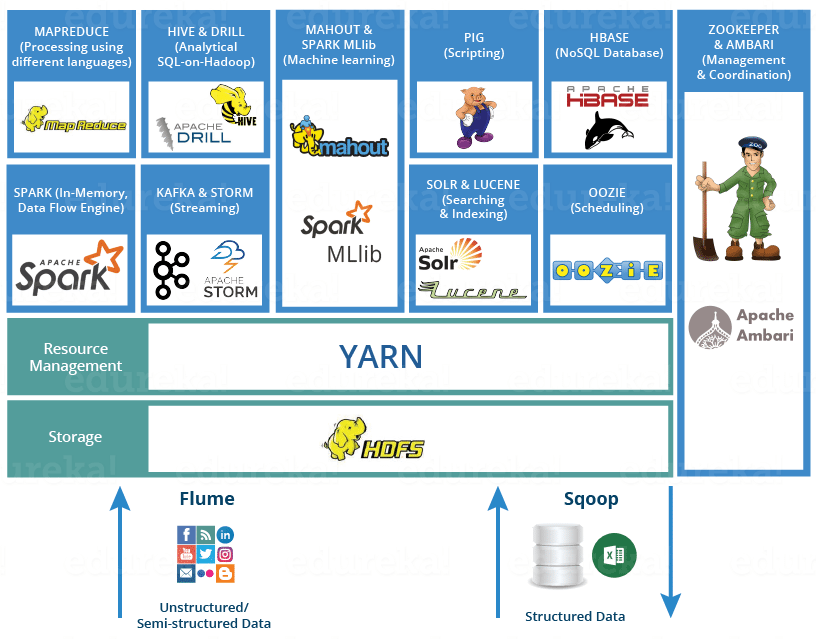
Hadoop Ecosystem
@Hadoop Tools for Crunching Big Data
왜?
방학동안 스마일게이트 서버개발캠프를 참여하면서, 팀 프로젝트로 데이터 파이프라인 개발 을 하게 되었다. 무지한 상태로 Kafka, Spark, Cassandra 를 다뤄보면서 한계를 참 많이 마주하였다. 특히 프레임워크에 대한 이해도가 충분하지 않은 채 사용하는 것을 정말로 스스로가 답답할 정도였다. 심지어 나는 관련 생태계에 대한 지식도 없었기에 이리저리 공부만 하다 이끌리기 십상이었다.
아무튼 프로젝트 마지막에 분산 클러스터 환경으로 스파크 잡을 실행해보려 하였다.
하지만, Pyspark는 클러스터 매니저로 Standalone을 지원하지 않았고, 해결을 위해선 Hadoop Yarn을 사용한다는 사실을 알게 되었다. 이것저것 해보다가 결국 프로젝트는 끝나버렸다.
무언가 해결 및 느낀
사실 프로젝트(TweetDeck Clone)에서 개발한 데이터 파이프라인 내 Ingestion 및 Processing이 간단했기 때문에 이래저래 기능은 구현했던 것 같다.
- 하지만, 결국 끝날 즈음에야 사실 내가 개발하고 싶었던 부분은 데이터 파이프라인의 느낌이 아니라 Realtime Tweet Filtered API 에 가까웠다.
- 일맥상통하는 부분이 있겠지만, 데이터 분석용이 아니라 결국 소비자에게 데이터를 실시간으로 렌더링한다는 것이 핵심이었다. 때문에 사용자가 제공하는 metric을 필터에 반영해서 데이터가 흘러야 한다는 것도 중요하게 구현해야 할 점이었다. 이를 DB Query 조건으로 구현한 것이 너무나 아쉽다.
- 쉽지 않다...
결론은,
- 딱 Kafka, Spark, Cassandra(분산형 DB)만 배우면 잘 만들 줄 알았다.
- 아니다. 생태계 프로세스를 이해하고, 적당히 필수적인 건 다 배워야 로그라도 읽는다...
배운 지식
정의 및 목적 - Hadoop Ecosystem is neither a programming language nor a service, it is a platform or framework which solves big data problems.
Below are the Hadoop components, that together form a Hadoop ecosystem
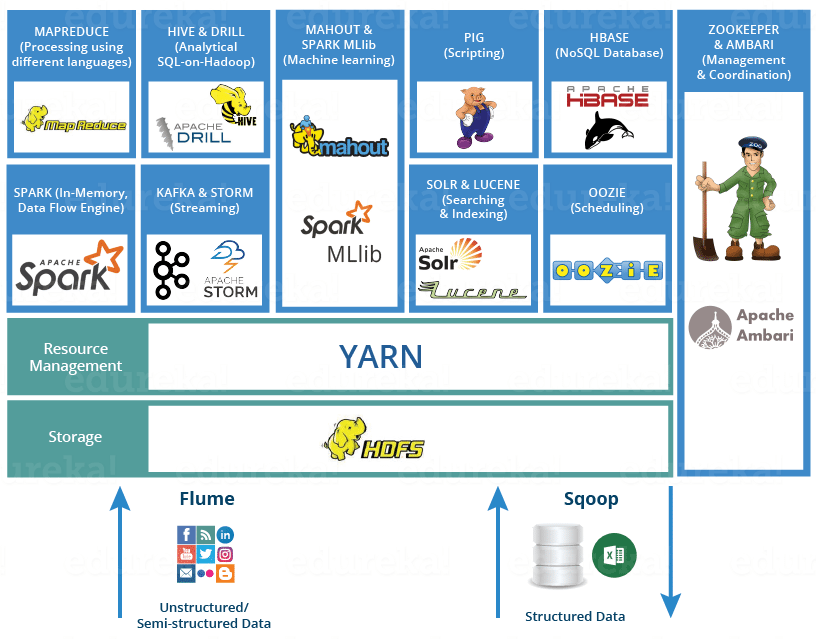
HDFS -> Hadoop Distributed File System
- 여러 구조의 빅데이터를 저장할 수 있다.
- 분산 노드 형태로 NameNode 와 DataNode 로 나뉘어, NameNode 에는 실제 데이터가 아닌 각종 메타데이터나 데이터 테이블이 저장되며 DataNode 에 실제 데이터가 저장된다.
- 메타데이터 및 분산 데이터 저장 등 여러가지를 통해 데이터를 알아서 잘 관리한다.
데이터 파이프라인을 만들 때 사용하지 않았다. 그저 DB로써 생각하였고, 디스크 읽고 쓰기 때문에 인메모리 프로세스보다 속도가 느리다고 들었다. 그래서 그저 cassandra를 썼었다. 하지만, 이 Hadoop Ecosystem을 활용하여 데이터 파이프라인을 개발하는 과정에서 고려해야만 했었다. 마지막에 결국 Hadoop 환경을 설정해야하는 한계를 마주했다. 전체 파이프라인에서 필요한 기능에 따라 알맞은 프레임워크를 택해야 하고, 전체적인 구조를 잘 구현하는 과정에서 HDFS가 backbone이라고 표현한 이유를 알 것 같았다.
YARN -> Yet Another Resource Negotiator
Hadoop Ecosystem의 두뇌 역할
It performs all your processing activities by allocating resources and scheduling tasks.
- 두 가지 메인 컴포넌트 ResourceManager & NodeManager
- 그리고, Schedulers & ApplicationsManager
사실 스파크 잡이든 쿼리든 어플리케이션의 모든 잡들을 YARN에게 제출하고, YARN이 이를 받아서 어디서 실행시키고 로그를 저장하고 이런 것들을 관리하기 때문에 사실 이것도 필수이다. 나는 생태계 내 프레임워크들을 너무 독립적으로 생각하였다.
정리하기 점점 벅차네
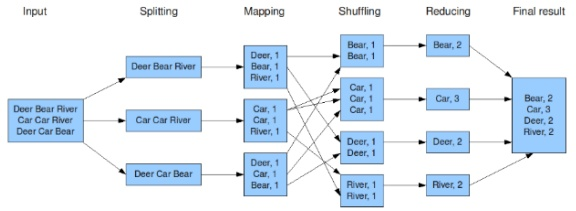
MapReduce -> Data processing using programming
감탄사가 나온다. 구글짱. 아래 그림으로 간단하게 이해하였다.
Spark -> In-memory Data Processing
노션에 공부하고 정리한 글이 수두룩 하다. 하지만 이제야 이해 후 헬로우 월드 정도 하는 기분이다. 힘들지만 재미있다.
PIG, HIVE -> Data Processing Services using Query (SQL-like)
SQL Query를 처리하는데 가장 MapReduce가 유용하게 쓰이는 것 같다.
- PIG는 블로그 글을 읽어보면, 아래와 같은 특징이 있는데 뭔가 HIVE를 쓰고 싶다. 나중에 언젠가 다시 마주치길 바란다.
- PIG has two parts: Pig Latin, the language and the pig runtime, for the execution environment. You can better understand it as Java and JVM.
- 10 line of pig latin = approx. 200 lines of Map-Reduce Java code
- 위를 정리해보면, Pig Latin이라는 언어로 간단하게 맵리듀스를 구현하며 이를 최적화된 컴파일러가 변환하여 효율적인 맵리듀스 잡을 구현하는 것 같다.
Zookeeper -> Managing Cluster
Kafka를 사용하면서 이 친구에 대해서 궁금했었다. 간단하게 알아보자.
- Apache Zookeeper coordinates with various services in a distributed environment.
- Hadoop Ecosystem 내 다양한 프레임워크가 서로 상호 작용하는 과정에서 싱크를 맞추기 위해 소모되는 시간이 많았는데 이를 해결했다. 정확히 무슨 싱크를 맞추는지는 나중에 직접적으로 사용하면서 겪어봐야겠다.
HBase -> NoSQL Database
Mahout, Spark MLlib -> Machine Learning
Apache Drill -> SQL on Hadoop
Oozie -> Job Scheduling
Flume, Sqoop -> Data Ingesting Services
Solr & Lucene -> Searching & Indexing
Ambari -> Provision, Monitor and Maintain cluster4
느낀 점
사실 이 모든 것을 정확하고 깊게 파악하기란 너무 고되고 긴 시간이 필요할 것이다. 하지만, 어느 정도 각각의 역할과 돌아가는 방식에 대해 알아야만 후에 빠르게 고민하고 적용하고 배우면서 사용하지 않을까. 어렵다 증말.
끝
+Hadoop Tutorial 란 글을 먼저 읽고 왔어야 했던 것 같다. 다음 글 확정.
안녕하세요 카산드라 사용하는분을 찾기가 힘든데 사용하고 계시다니 반갑습니다.
국내에 카산드라 커뮤니티가 없어서 얼마전에 개설했는데 홍보하고자 합니다.
주소는 https://www.facebook.com/groups/cassandrausergroup/ 이고..부담스럽지 않으시다면 같이 노하우 공유나 정보 공유 해주셨으면 합니다! 감사합니다.