세 번째 글
What is Hadoop?
@Introduction to Big Data & Hadoop
왜?
이전에 읽은 Hadoop Ecosystem 이 사실 Hadoop 소개 시리즈 3탄이었고, 지금 읽고 있는 글이 1탄이다. 더 충격적인 것은 Big Data and Hadoop 으로 166개의 글이 묶여서 존재한다. 물론 다 읽지 않을 예정이다.
그래서. 3탄을 제일 먼저 읽었으니 1탄 2탄도 친절하게 읽으려 한다.
이것저것 정리
서문
As to understand what is Hadoop, we have to first understand the issues related to Big Data and traditional processing system.당연한 말이다. Hadoop이라는 것이 결국 어떤 것을 보완 및 해결하기 위해 나온 것이니, 빅데이터 및 기존 데이터 프로세싱 시스템에 대해서 알아볼 필요가 있다.
빅데이터 분석으로 참 할 수 있는 것이 많다.
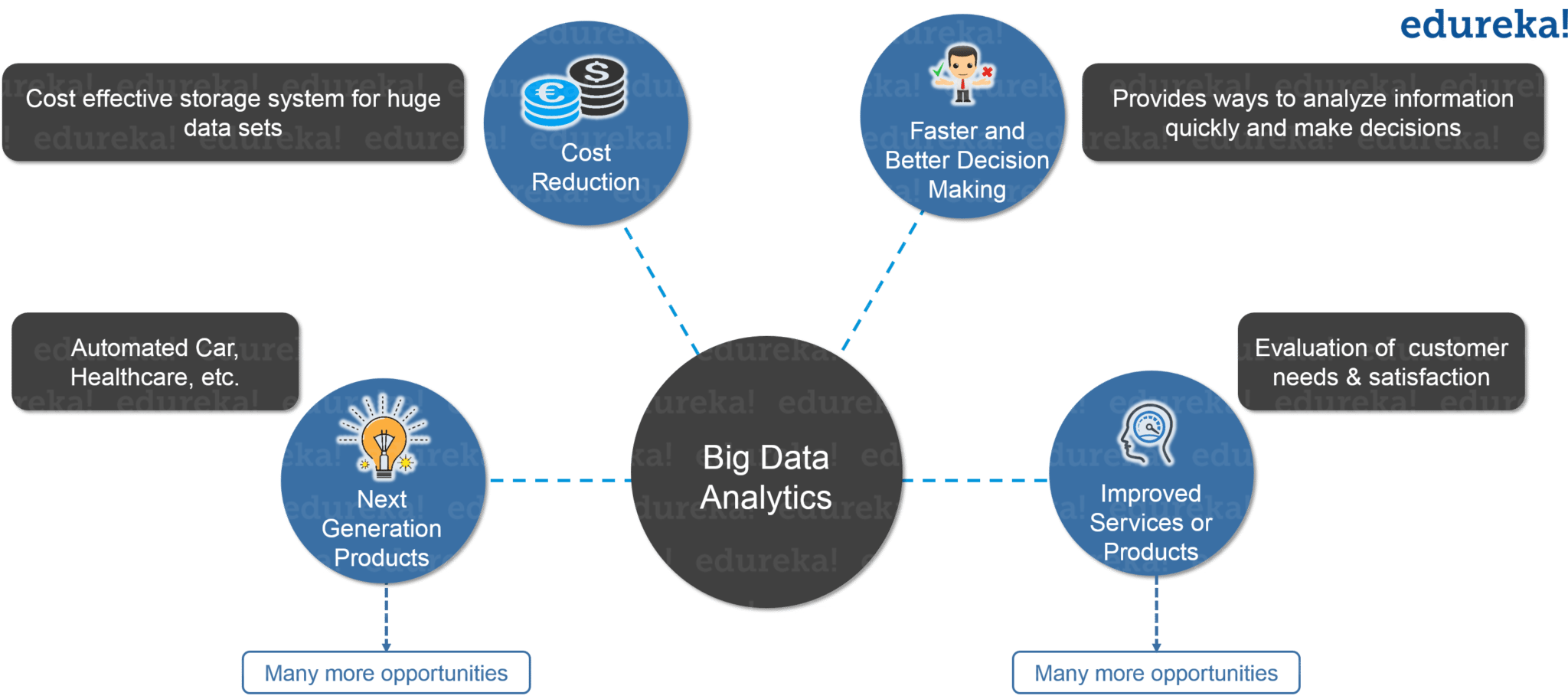
Problems with Traditional Approach
과거 메인 이슈는 다양한 데이터(구조화, 비구조화, 반구조화)의 이질성을 이해하고 각각에 맞게 데이터을 다뤄야 하는 것이었다.
하지만, 이제는 빅데이터 관련 문제
- 어마무시한 양의 데이터를 저장해야 해
- 여러 다른 종류의 데이터를 저장해야 해
- 데이터 접근 및 처리 속도가 정말 빨라져야 해
Evolution of Hadoop
그래서 나온 것이 Hadoop
- 2003년, 구글의 GFS(Google File System) 등장
- 2004년, 구글의 MapReduce 논문 등장
- 2005년, GFS 및 MapReduce 방식의 연산을 하는 Nutche 등장
- 2006년, 야후가 이들 기반 Hadoop 개발
- 2008년, Hadoop 오픈소스 릴리즈
What is Hadoop?

HDFS
다양한 포맷의 데이터를 여러 클러스터에 분산 저장하는 파일 시스템
YARN
분산 처리를 통해 리소스 및 데이터 관리를 돕는 매니저
- 분산 저장을 통해 스케일링 문제를 해결 한다. 수평적 스케일링 가능.
- Since in HDFS, there is no pre-dumping schema validation. And it also follows write once and read many model.
- 분산 저장 및 분산 처리를 통해 속도 극대화.
(사실 이게 핵심 아닌가)
When to use Hadoop ?
- Search – Yahoo, Amazon, Zvents
- Log processing – Facebook, Yahoo
- Data Warehouse – Facebook, AOL
- Video and Image Analysis – New York Times, Eyealike
When not to use Hadoop ?
- Low Latency data access : Quick access to small parts of data
- Multiple data modification : Hadoop is a better fit only if we are primarily concerned about reading data and not modifying data.
- Lots of small files : Hadoop is suitable for scenarios, where we have few but large files.
느낀 점
Hadoop. 넌 참 멋져.
끝
개발자로 일하는 김찬영입니다.