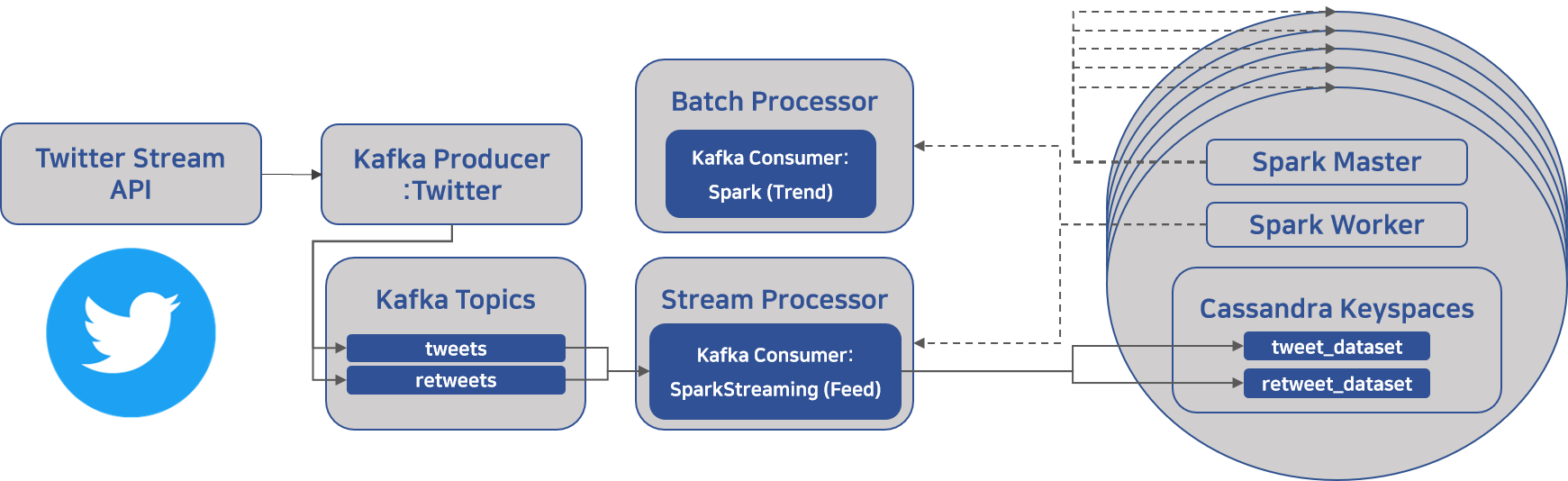
(아키텍처 내 왼쪽에 해당하는)
2019년 겨울 프로젝트 정리 3 - from Kafka to Spark
TweetDeck Clone Project
= 데이터 파이프라인 및 tweet 실시간 피드 개발
Kafka로부터 tweet message들을 읽어, Spark로 실시간으로 분산 처리 후 Cassandra DB에 저장하는 부분에 대해 설명해보려 한다.
- API - Filter realtime Tweets
- Code - KafkaTweetConsumer.py
- Specs
- CentOS Linux release 7.7.1908
- Java 8
- Cassandra 3.11.5
- cqlsh 5.0.1
- Spark 2.4.4 built for Hadoop 2.7
- Hadoop 2.7.7
- kafka_2.11-2.1.1
과거에 Notion에 정리했던 것을 간단하게 옮긴 것이라 중간 과정 공백이 많을 가능성이 높다
환경 설정 및 분산 처리 관련된 것을 구글링을 통해 배우는 것이 현명하다
전체적인 프로세스
코드의 전반적인 프로세스와 코드를 작성하면서 참고할만한 점들을 정리한다.
과정
SparkConf를 사용하여conf생성- 카산드라 관련된 config 입력해준다.
- Create
SparkContextfor Connection to a Spark Clusterconf를 parameter로 하여 생성한다.
- Create
StreamingContextfor using streaming application KafkaUtils를 사용해KafkaStream생성.- Spark Streaming application과 topic 그리고 기타 params를 정의한다.
- Output →
DStream
KafkaStream에서 각 RDD map 함수 처리- json 객체로 변환
- parsing 및 필요한 데이터 추출 작업
- 변환된 DStream을 foreachRDD 함수를 통해 cassandra에 저장
참고할 점
map()vsforeachRDD()map()→ Return a new DStream by applying a function to each element of DStream.foreachRDD()→ Apply a function to each RDD in this DStream.
⭐고민했던 점⭐
- Kafka에서 받는 데이터를 JSON으로 변형하기 위해
json.loads함수를 두번 적용해야 하는 점 - Spark Streaming(DStreams), Structured Streaming(Spark SQL engine), RDD, DataFrame이 서로 다른 성격과 버전을 가지고 있어서, 그 차이점들을 명확하게 알아야 사용할 수 있다는 점.
- DataFrame을 사용하여 필요한 스키마 형태에 맞춰 JSON Data를 필터링을 해보려 했지만, 결국 직접적으로 python dict 자료구조를 사용하여 손수 필터링
- 하지만, DataFrame 사용에 있어서 어느 정도 연습을 했다는 점
- Kafka 데이터는 partition, key, value, header로 이루어져 있고, 현재 key가 None으로 설정되어 있기 때문에, 그저 리스트 형태에서 두번째 인자를 가져와 value로써 사용하게 된다.
- 스키마에 따른 데이터 필터링 시 데이터 자체의 누락과 처리 과정에서 데이터 분류를 해야하는 점
- 데이터 저장에 있어서 스키마를 명확하게 해야하는 점. 따라서 저장하기에 앞서 데이터 형태 변형을 모두 해야하는 점
- 데이터 저장에 있어서 PRIMARY KEY 관련하여 클러스터링 개념이 부족하여 왜 20개의 데이터가 처리되는데 1개만 저장되는지에 대한 문제. 결국 모든 PRIMARY 키의 조합이 Unique하게 이루어져야 그 데이터의 순서 및 모든 것이 정렬되어 저장될 수 있기에 그렇게 한다.
알아야 했던 점
- Spark SQL의 변화
- Spark v2.0.0 이전에는 SparkContext를 모든 Spark 함수에 접근하는 채널로써 사용하고, SQLContext(sc)를 사용하여 Spark SQL application이 동작하도록 하였다.
- 하지만, v2.0.0 부터는 SparkSession 한 가지로 Spark SQL apllication이 동작도록 간소화되었다.
- 우리는,
- Spark Streaming과 Spark SQL을 모두 사용하고, Spark SQL에서 구조적 API에 해당하는 Dataframe을 사용하게 될 것 같은데,
- 우리가 RDD를 잘 다룬다면, 뭐 Spark SQL을 사용하지 않을 수도 있다.
- KafkaUtils 관련
- 우리는 createDiectStream을 사용하는데, createStream과 다른 점은 카프카로 메세지를 받아서 (특정 배치 시간 간격 동안) 저장없이 처리한다. 그래서 parameter로 storage level이 없다.
Raw Data 처리 프로세스
Raw 데이터를 분석하고, 이를 바탕으로
어떤 스키마를 바탕으로 데이터를 처리하고 분류할 지 프로세스를 정의하였다.
처리 과정
-
Retweet
**"retweeted"으로 Retweet 확인** (프로필 렌더링에 있어서 중요)- 만약
true라면,"retweeted_status"속 데이터로 아래 방식으로 Tweet 렌더링
-
Tweet
-
**"in_reply_to_status_id"로 Reply 확인**- Reply 라면,
"entities"속"user_mentions"member 수, 리스트 데이터로 만들어서 전달
- Reply 라면,
-
Text
**"truncated"로 Text 초과 데이터 확인**true시"extended_tweet"로 Text 렌더링 (entities 및 extended_entities가 이 안으로 속해 있음)false시 기본"text"로 렌더링을 해야 하는데, Quoted 시"display_text_range"데이터가 없기 때문에,"entities"를 제외한 부분을 Text로 렌더링 해야 한다.주의hashtag나 urls 같은 경우, 초과 범위 안은 entities에 초과된 것들은 extended_tweet 안에 따로 존재.
-
Media
**"truncated"확인**true시"extended_tweet"로 media 정보가 모두 넘어가기 때문에, Text 및 media 관련 데이터를 모두"extended_tweet"에서 색인하여 렌더링false시 기본"entities"&"extended_entities"모두에 media 데이터가 있으므로 선택하여 렌더링
-
Quoted
**"is_quote_status"로 Quoted 확인**- 만약
true라면,"quoted_status"속 데이터로 Tweet 렌더링 - Quotmed는 Reply와 Text까지만 Rendering
-
-
Filtering
- Language → Only English
- Reply 제외
처리를 마친 JSON
Raw 데이터 예시는 이전 포스팅 확인
{
"created_at":"Tue Jan 28 02:21:06 +0000 2020",
"id":1221981496820453376,
"id_str":"1221981496820453376",
"text":"smilegateserverdev #smilegateserverdev\nsmilegateserverdev #smilegateserverdev\nsmilegateserverdev\u2026 https:\/\/t.co\/tolbTYmZU5",
// **길이 제한 생략** (항상 존재)
"truncated":true,
// **User Data** (항상 존재)
"user":{...},
// **Retweet Data** (Retweet이 아니라면 생략)
"retweeted_status":{...},
// **Quoted Data** (아래 5개) (Quoted가 없다면 상위 4개 생략)
"quoted_status_id":1222013115358990336,
"quoted_status_id_str":"1222013115358990336",
"quoted_status":{...},
"quoted_status_permalink":{...},
"is_quote_status":false,
// **초과된 데이터** (Text 관련) (없다면 생략)
"extended_tweet":{...},
// **Entity** (해시태그, URL, User_mentions, Symbols 등) (항상 존재)
"entities":{...},
// **초과된 데이터** (영상 및 사진 관련) (없다면 생략)
"extended_entities":{...},
// **Retweet** (항상 존재)
"retweeted":false,
"lang":"it",
"timestamp_ms":"1580178066817"
}
Twitter API Data Exception
Twitter API로 받는 데이터에서 예외 처리할 사항들
Quoted Tweet 비공개로 인한 데이터 누락
-
해당 데이터
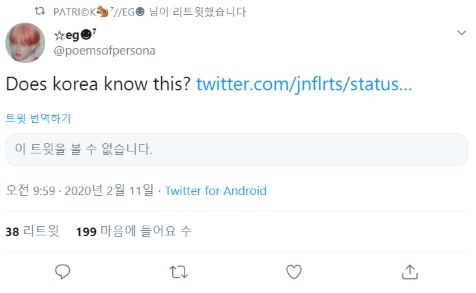
-
'is_quote_status'는 True가 되지만,'quoted_status'데이터는 없게 된다.
timestamp_ms 데이터 누락
{'created_at': 'Mon Feb 10 00:18:27 +0000 2020', 'id': 1226661672573689862, 'id_str': '1226661672573689862', 'text': '‘what made you decide to have the film in korean’ she asks the korean director who lives in korea and speaks korean… https://t.co/gNSSJyZTBE', 'source': '<a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a>', 'truncated': True, 'in_reply_to_status_id': None, 'in_reply_to_status_id_str': None, 'in_reply_to_user_id': None, 'in_reply_to_user_id_str': None, 'in_reply_to_screen_name': None, 'user': {'id': 1100818939007901696, 'id_str': '1100818939007901696', 'name': 'princess naya ⁷ 💕💘💖💗💓💞', 'screen_name': 'hoyarkive', 'location': '♡ ot7 + jk + chungha', 'url': 'http://www.curiouscat.me/princessnaya', 'description': '#YOONGI: no YOU live in a society, i live in hopeworld ☻', 'translator_type': 'none', 'protected': False, 'verified': False, 'followers_count': 1286, 'friends_count': 258, 'listed_count': 5, 'favourites_count': 4396, 'statuses_count': 3185, 'created_at': 'Wed Feb 27 18:04:22 +0000 2019', 'utc_offset': None, 'time_zone': None, 'geo_enabled': False, 'lang': None, 'contributors_enabled': False, 'is_translator': False, 'profile_background_color': '000000', 'profile_background_image_url': 'http://abs.twimg.com/images/themes/theme1/bg.png', 'profile_background_image_url_https': 'https://abs.twimg.com/images/themes/theme1/bg.png', 'profile_background_tile': False, 'profile_link_color': 'A00B26', 'profile_sidebar_border_color': '000000', 'profile_sidebar_fill_color': '000000', 'profile_text_color': '000000', 'profile_use_background_image': False, 'profile_image_url': 'http://pbs.twimg.com/profile_images/1226524646108995590/zNMyCTH4_normal.jpg', 'profile_image_url_https': 'https://pbs.twimg.com/profile_images/1226524646108995590/zNMyCTH4_normal.jpg', 'profile_banner_url': 'https://pbs.twimg.com/profile_banners/1100818939007901696/1581261239', 'default_profile': False, 'default_profile_image': False, 'following': None, 'follow_request_sent': None, 'notifications': None}, 'geo': None, 'coordinates': None, 'place': None, 'contributors': None, 'is_quote_status': False, 'extended_tweet': {'full_text': '‘what made you decide to have the film in korean’ she asks the korean director who lives in korea and speaks korean and hired a korean cast to play korean characters to make social criticism about class in korea\n\nhttps://t.co/UwOWd1ej2G', 'display_text_range': [0, 236], 'entities': {'hashtags': [], 'urls': [], 'user_mentions': [], 'symbols': [], 'media': [{'id': 1226655108286406656, 'indices': [213, 236], 'media_url': 'http://pbs.twimg.com/ext_tw_video_thumb/1226655108286406656/pu/img/u1UqOQ4joWS5jZwy.jpg', 'type': 'video', 'video_info': {'aspect_ratio': [16, 9], 'duration_millis': 34567, 'variants': [{'content_type': 'application/x-mpegURL', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/pl/_y_7pzqoXgjbnHgT.m3u8?tag=10'}, {'bitrate': 832000, 'content_type': 'video/mp4', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/vid/640x360/ROE626tsdcwiaHtb.mp4?tag=10'}, {'bitrate': 2176000, 'content_type': 'video/mp4', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/vid/1280x720/pECEW8SuXumK5uox.mp4?tag=10'}, {'bitrate': 256000, 'content_type': 'video/mp4', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/vid/480x270/2lGE_B2aop7mRUux.mp4?tag=10'}]}}]}, 'extended_entities': {'media': [{'id': 1226655108286406656, 'indices': [213, 236], 'media_url': 'http://pbs.twimg.com/ext_tw_video_thumb/1226655108286406656/pu/img/u1UqOQ4joWS5jZwy.jpg', 'type': 'video', 'video_info': {'aspect_ratio': [16, 9], 'duration_millis': 34567, 'variants': [{'content_type': 'application/x-mpegURL', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/pl/_y_7pzqoXgjbnHgT.m3u8?tag=10'}, {'bitrate': 832000, 'content_type': 'video/mp4', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/vid/640x360/ROE626tsdcwiaHtb.mp4?tag=10'}, {'bitrate': 2176000, 'content_type': 'video/mp4', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/vid/1280x720/pECEW8SuXumK5uox.mp4?tag=10'}, {'bitrate': 256000, 'content_type': 'video/mp4', 'url': 'https://video.twimg.com/ext_tw_video/1226655108286406656/pu/vid/480x270/2lGE_B2aop7mRUux.mp4?tag=10'}]}}]}}, 'quote_count': 8905, 'reply_count': 1587, 'retweet_count': 133452, 'favorite_count': 484247, 'entities': {'hashtags': [], 'urls': [{'url': 'https://t.co/gNSSJyZTBE', 'expanded_url': 'https://twitter.com/i/web/status/1226661672573689862', 'display_url': 'twitter.com/i/web/status/1…', 'indices': [117, 140]}], 'user_mentions': [], 'symbols': []}, 'favorited': False, 'retweeted': False, 'possibly_sensitive': False, 'filter_level': 'low', 'lang': 'en'}
- 애초에
'timestamp_ms'값이 누락된 데이터 존재. 수없이 많이 존재. - 조건문을 통해
print한 결과인데, 또 중요한 것이 중복 데이터가 존재.- 데이터를 확인해보면 특별한 것이 없는데, 더 무서운 것은 리트윗 수가 13만이다.
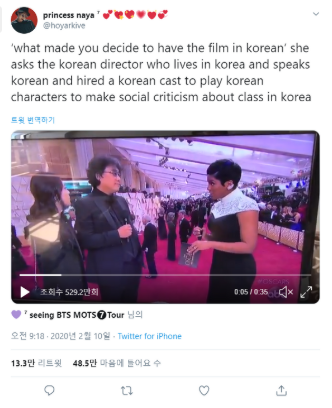
profile_banner_url 데이터 누락
-
TweetDeck에서 프로필 클릭 시 모습
-
원래 배경 설정이 되어 있지 않더라도 기본 트위터 배경 URL이
**'profile_banner_url'** 에 있었는데, 누락되는 경우가 있어서 제외
retweeted 이 아닌, text 시작이 RT인지로 리트윗 판단**
- 모든 데이터가
retweeted가 false인 것을 확인하고, 다르게 처리하였다.
데이터 누락 BLOCK 처리
분산 클러스터 환경 설정
아래 링크들을 참고하는 것이 현명하다
참고 링크
-
전체적인 파이프라인 - mavoll/SparkPipeline
- README 보면 그냥 분산 클러스터 환경 설정의 모든 과정을 전부 설명하고 있다.
- 이 github을 바탕으로 만들었다해도 과언이 아니다.
-
카산드라 관련 - How To Run a Multi-Node Cluster Database with Cassandra on Ubuntu 14.04 | DigitalOcean
추가로 고민했던 사항
과연 내가 하고 있는 것은 데이터 파이프라인이 맞는가?
"Inside Twitter's Realtime Delivery of Tweets for Enterprise Customers" by Lisa White
실제 Twitter API가 작동하는 원리에 대한 youtube 영상인데, 사실 데이터 파이프라인이 아닌,
Filtered API를 만들고 있는 것이 아닌가라는 고민을 했다.반년이 지난 지금 생각해보니 파이프라인이 아니었다...
끝🙋♂️
아무도 안보는 블로그지만 그 소수의 고생하고 있는 이들이 도움을 받길