2019년 겨울 프로젝트 정리 1 - 소개
TweetDeck Clone Project
= 데이터 파이프라인 및 tweet 실시간 피드 개발
- 실제 Twitter 데이터를 받아, 분산 처리 및 저장
- 데이터 분석 및 처리를 통한 트렌드 정보 저장 및 제공
- 데이터 실시간 제공을 위한 전반적인 백엔드 서버 구축
- 실시간 피드 서비스를 위한 웹 어플리케이션 구현
지난 겨울에 진행했던 프로젝트를 더 잊어버리기 전에 기록하려고 한다.
총 4명이서 두달 간 진행한 프로젝트로, 나는 위 4가지 중 첫번째를 담당하였다.
TweetDeck 소개 및 발표 영상
TweetDeck이란?
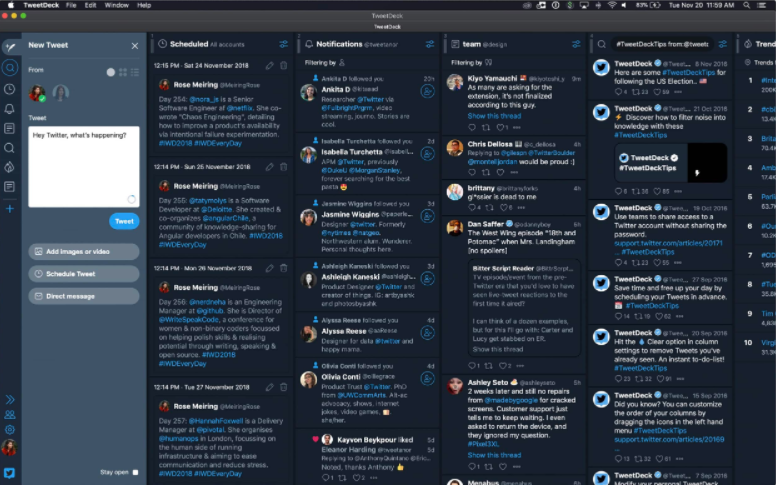
Twitter의 3rd party application으로 현재는 Twitter 서 인수하여 개발 및 운영 중이다.
Twitter의 경우 follow 하는 유저가 많아지면, 피드가 복잡해지고 tweet이 넘쳐나게 된다.
따라서 TweetDeck은 모든 사용자가 아닌, 특정 키워드 혹은 특정 사용자의 tweet을 따로 대시보드 형태로 column 구조로 보여준다.
참 멋져 보이는 이 녀석을 한번 만들어 보기로 했다.
물론 BTSDeck으로 컨셉을 잡아서 말이다.
만들고자 한 이유
- Twitter API를 통해서 실시간 tweet을 받을 수 있었다.
- 내가 실시간 데이터 처리 파이프라인을 만들고 싶었다.
(때문에 팀원들이 너무 고생했다)
(팀원들이 보고 싶다 같이 지하 1층에서 밥먹고 싶다)
최종 발표 영상 그리고 BTSDeck
최종 발표 영상
시연 관련된 부분은 2:52부터이다.
영상에서 볼 수 있듯이, (가시적으로) 구현한 기능은 아래와 같다.
- 회원가입 및 로그인 기능 구현
- 실시간 피드 기능
- 웹 페이지 접속 시 기본 BTS 키워드 관련 tweet 및 Hashtag 랭킹 피딩
- 키워드를 검색하거나 hashtag 클릭 시 column이 생성되며 관련 tweet 피딩
- 스크롤 내리면 과거 tweet 피딩
그리고,
(비가시적으로 내가) 구현한 기능은 아래와 같다.
- 실시간 tweet을 kafka로 메시징
- 메시지들을 Spark Streaming으로 공통화 및 필터링
- 처리된 데이터를 Cassandra에 적재
- 안정적인 처리를 위해 분산 시스템 구축
돌아보면 일주일도 안 걸릴 일들을 밑바닥부터 배워가며, 이런 저런 오류를 맞이하며 두달동안 했었다.
물론, 이 분야를 진로로 삼았고 첫 발돋움이었기에, 생각하면서 매순간 열정적이었다.
전체적인 아키텍처
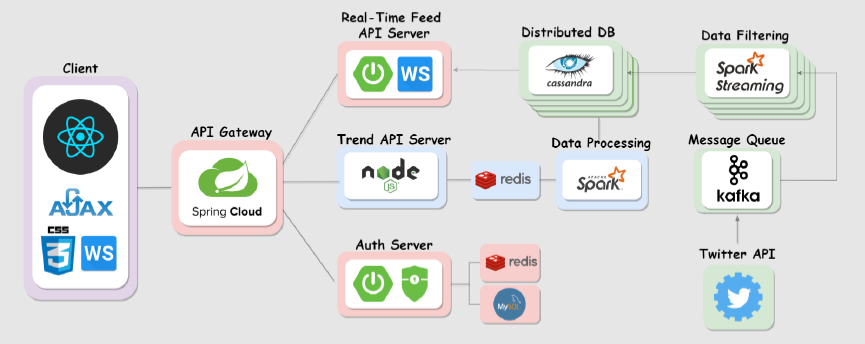
모두가 관련 개발을 해본 적이 없어서 정말 naive한 아키텍처이다.
더 나은 구조가 있다면 댓글 부탁드립니다🙇♂️
간단하게 설명을 하자면,
데이터 파이프라인 부분,
- Twitter Stream API를 통해 실시간으로 유입되는 데이터를 받아 tweet과 retweet으로 구분하고,
- Kafka message queue에 데이터를 보내고,
- Consumer인 Spark Streaming Application에 의해 필요한 데이터 형태로 필터링 및 변형되어 DB에 저장
- 클러스터 환경 설계(Spark & Cassandra DB)
- 데이터 유입 및 구조 분석을 바탕으로 데이터 처리 및 저장 프로세스 정의
- 데이터 처리를 위해 DB 부하를 막기 위해 분산 데이터베이스인 Cassandra DB 설계
아래부터는 팀원들이 작업했기 때문에 부정확할 가능성이 크다.
트렌드 데이터 처리 부분,
- Cassandra에 적재된 데이터를 바탕으로,
- 스파크를 활용하여 데이터 분산 처리 후,
- 결과를 redis에 저장한다.
- 인기 tweet 랭킹 (Top 10) - 가장 많이 retweet 되고 있는 tweet 목록
- 해시태그 랭킹 - Twitter에서 가장 많이 언급되는 hashtag 분석 결과
빨간색 부분,
- 인증 서버
- 회원가입 및 이메일 인증 기능이 구현되어 있고,
- 웹 토큰의 경우 redis에, 회원 정보는 MySQL에 저장한다.
- API Gateway
- 사용자 요청을 기능에 따라 분산하여 서버로 보내고,
- 로그인 관련 JWT 처리를 담당하고,
- 테스트 해보진 않았지만 트래픽 안정적인 서버 운영이 가능하게 한다.
- Real-Time Feed API Server
- 실시간 데이터는 WS , 스크롤 다운 시 과거 데이터는 HTTP 요청
- 소켓 연결 시 기존 JWT 와 함께 인증하기 위해 secondary token 사용
- 검색어 별로 쿼리 결과를 주기적으로 publish 해서 클라이언트에서 subscribe
클라이언트 부분,
- 서버와의 통신을 통해 Tweet 데이터들을 실시간 으로 받아 Rendering
- BTS, Search, Hashtag, Ranking 과 같은 기능 별 Column component 구현
- 각 Column 기능에 맞도록 두 가지 방법으로 데이터 수신 하여 Rendering
- 시간 간격에 따른 지속적인 데이터 수신
- Pub/Sub 구조의 Socket 통신 방식을 이용한 데이터
- 검색에 따른 혹은 키워드 클릭에 따른 Column 추가 기능
이제 소개를 마치고, 내가 했던 것들을 위주로 정리해보려 한다.🙋♂️
기대되네요 !!!