암마프 term-project

14장과 13장 하고 term-project 가능
14. Big Data Analytics - HadoopPlatform
Big Data Analytics On Hadoop Platform
- 데이터
- 컴퓨터에 의해 작업이 수행되는 수량, 문자 또는 기호
- 전기 신호의 형태로 저장 및 전송되고 자기, 광학 또는 기계적 기록 매체에 기록 될 수 있다
- 빅 데이터
- 방대한 양의 데이터. 시간이 지남에 따라 기하 급수적으로 증가하는 데이터 모음이다.
- 기존 데이터 관리 도구로는 불가능할 정도로 크기가 크고 복잡한 데이터
- 1) Structured/ 2) Unstructured/ 3) Semi-structured
- RDB-table/ Video & Audio/ text 형식(json, csv 등)
- 볼륨, 다양성, 속도 및 가변성
- 장점: 향상된 고객 서비스, 더 나은 운영 효율성, 더 나은 의사 결정
- Haddop Platform
- 인터넷을 통해 데이터를 받고 그 데이터를 병렬 처리 하는 플랫폼
- 서버들 사이에 네트워킹이 이루어져야함.
- 서버들이 linux 플랫폼으로 되어있으면 서로가 통신할 수 있도록 병렬처리할 수 있는 플랫폼을 공부하는 것이 목적
<Haddop Ecosystem & Components>
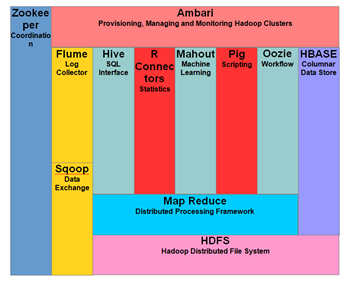
Hadoop에서 데이터는 Haddop Distributed File System이라고하는 분산 파일 시스템에 있습니다. 처리 모델은 계산 논리가 데이터를 포함하는 클러스터 노드 (서버)로 전송되는 'data locality'를 기반으로 한다.
- Map Reduce
- Hadoop에서 실행되는 애플리케이션을 작성하기위한 계산 모델 및 소프트웨어 프레임 워크. MapReduce 프로그램은 대규모 계산 노드 클러스터에서 대규모 데이터를 병렬로 처리할 수 있다.
- HDFS(Haddop Distributed File System)
- 데이터 분산처리 시스템 split
- 데이터 블록의 여러 복제본을 만들어 클러스터의 컴퓨팅 노드에 배포한다.
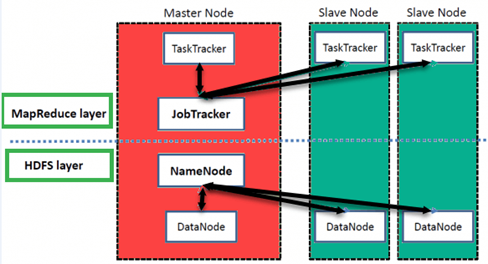
- NameNode: name space에서 사용되는 모든 파일과 디렉토리 (meta data 가지고 있음)
- DataNode: HDFS 노드의 상태를 관리하고 블록과 상호 작용할 수 있도록 도와줌.
- master node를 사용하면 Hadoop MapReduce를 사용하여 데이터의 병렬 처리를 수행 할 수 있다
- slave node는 복잡한 계산을 수행하기 위해 데이터를 저장할 수있는 Hadoop cluster의 추가 시스템이다. 또한 모든 slave node에는 작업 추적기와 데이터 노드가 함께 제공된다. 이를 통해 프로세스를 각각 NameNode 및 Job Tracker와 동기화할 수 있다.
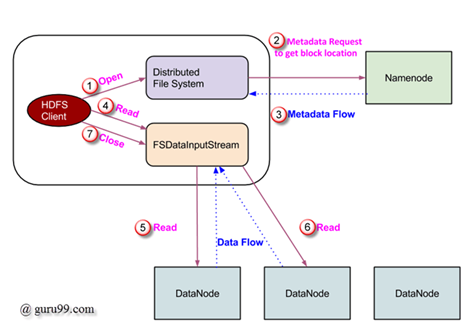
Read Operation in HDFS
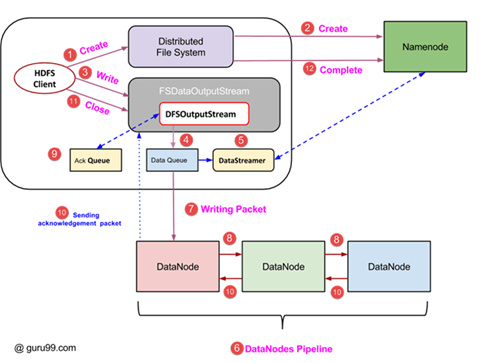
Write Operation in HDFS
MapReduce Architecture
-
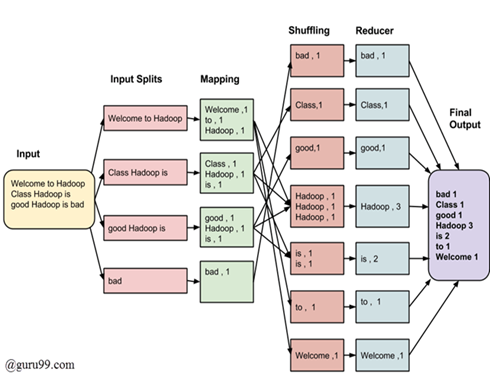
방대한 양의 데이터를 처리하는 데 사용되는 소프트웨어 프레임 워크 및 프로그래밍 모델.
각 단계에 대한 입력은 key-value 쌍!!(모두) -
모든 프로그래머는 두 가지 기능을 지정해야함 : map function, reduce function.
-
wordCount.java
-
input Splits
- 빅 데이터 작업의 MapReduce 작업에 대한 입력은 input Splits이라고하는 고정 크기 조각으로 나뉜다.
- 입력 분할은 single map에서 사용되는 입력의 chunk.
-
Mapping
- 각 분할의 데이터는 출력 값을 생성하기 위해 매핑 함수로 전달됨
- mapping level의 jop은 입력 분할에서 각 단어의 발생 횟수를 세고 <word, frequency>(=key, value) 형식의 list를 준비하는 것.
-
Shuffling (sorning)
- task: 매핑 단계 출력에서 관련 레코드를 통합하는 것.
-
Reducing
- shuffling 단계의 출력 값이 집계함
- Shuffling 단계의 값을 결합하고 단일 출력 값을 반환.
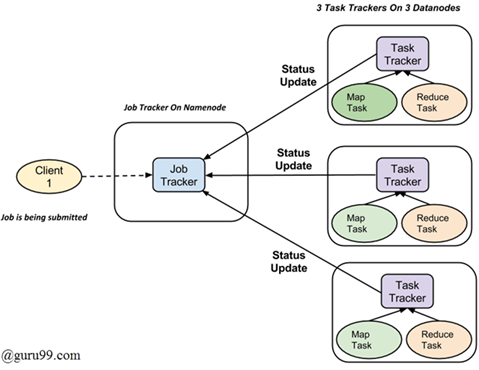
MapReduce Process Organization
-
Map tasks (Splits & Mapping)
-
Reduce tasks (Shuffling, Reducing)
-
Jobtracker : 마스터 역할 (제출 된 작업의 전체 실행을 담당)
-
Multiple Task Trackers: 각각의 작업을 수행하는 slave처럼 작동한다.
시스템에서 실행을 위해 제출된 모든 작업에는 Namenode에 상주하는 하나의 Jobtracker와 Datanode에 상주하는 여러 tasktracker가 있다.
job은 여러 작업으로 분할된 다음 클러스터의 여러 데이터 노드에서 실행된다. job tracker는 다른 데이터 노드에서 실행되도록 작업을 예약하여 활동을 조정한다. 개별 작업의 실행은 작업의 일부를 실행하는 모든 데이터 노드에 상주하는 job tracker에 의해 관리됩니다. job tracker는 작업 추적기에 진행 보고서를 보낸다. 또한 시스템의 현재 상태를 알리기 위해 주기적으로 'heartbit'신호를 Jobtracker에 보낸다. 따라서 job tracker는 각 작업의 전체 진행 상황을 추적한다. 작업 실패시 job tracker는 다른 작업 추적기에서 작업을 다시 예약 할 수 있다.
https://things-actruce.tistory.com/2
map, reduce, main(driver) 코드 짜면 됨.
직접 짜서 복붙해라??
Hadoop & Mapreduce Example: Create First Program in Java
driver(main program), reducer, mapper programming 해야함
Step 1
su - hduser_ //login
sudo mkdir MapReduceTutorial //디렉토리 생성
sudo chmod -R 777 MapReduceTutorial // 모든사람이 read, write exacution할 수 있도록 함
cd MapReduceTutorial // 디렉토리로 들어감
sudo chmod +r *.* // 모드 파일 read할수 있도록 함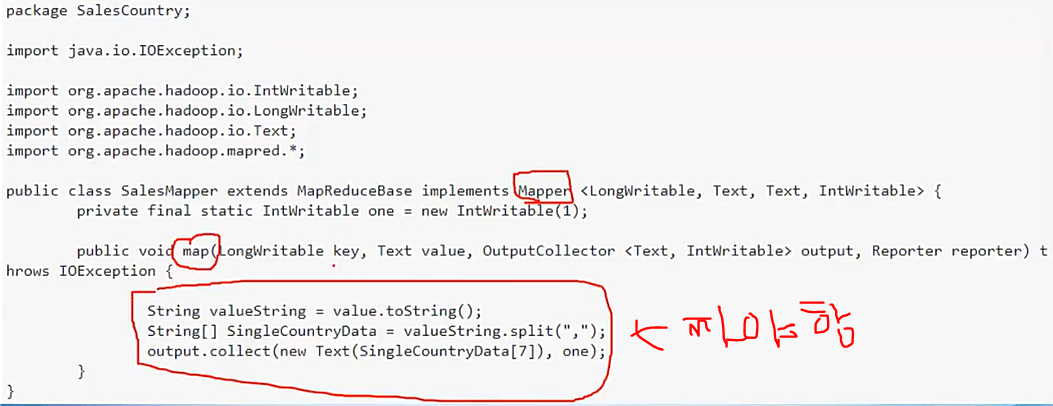
Step 2
export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.2.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.2.0.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.2.0.jar:~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"Step 3
javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java
1:38:12부터
Step 4
// Create a new file Manifest.txt
sudo gedit Manifest.txt
// add following lines to it,
Main-Class: SalesCountry.SalesCountryDrive Step 5
// Create a Jar file
jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class Step 6
// Start Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.shStep 7
// Copy the File SalesJan2009.csv into ~/inputMapReduce
// Now Use below command to copy ~/inputMapReduce to HDFS.
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /
$HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce hdfs 사용
Step 8
// Run MapReduce job
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales
// This will create an output directory named mapreduce_output_sales on HDFS. Contents of this directory
// will be a file containing product sales per country.여기까지가
1. Hadoop 프로그램 짜는지
2. Hadoop program을 compile하고 link해서 jar 파일 만드는 법
3. hdfs를 이용해서 local 데이터를 hdfs 파일에 분산 저장 방법
4. 분산된 input data에 대해서 hadoop run 시키는 법
Step 9
결과는 command 인터페이스를 통해 볼 수 있음
$HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000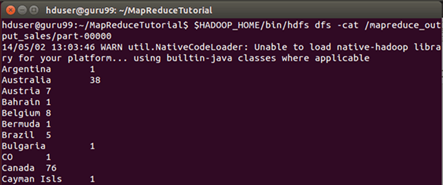
web에서도 볼 수 있음.
Step 10
Haddop Writable Data Types
....
서로 ping이 다 되는지
하둡 설치 word count를 run하기 -> term project다.
