Tag
An HTML document is a collection of tags that defines a web page's contents. Tags are used to describe specific types of content such as images, paragraphs, headings, footers, and many more.
Attribue in tag
HTML Attributes modify or define a particular characteristic of a tag.
An attribute either modifies the default functionality of an element type or provides functionality to certain element types which are unable to function correctly without them.
--예시--
<img src="http://iiimgur.com/dQED8fc.png" alt="Memes aren't funny pictures">
주의: 각 다른 태그마다 다른 attribute를 가지고 있으니 MDN에서 확인할것.
HTML 기본 구조
<!DOCTYPE html> <-- html 버전을 알려준다. 보통 html ver 5
<html> <-- top chain most parent.
<head>
<title>My first document</title>
<meta charset="UTF-8" />
</head>
<body>
<p>Hey!</p>
...
</body>
</html>
-
DOCTYPE html This tag indicates that the markup language for your document content is HTML5.
-
html tag The spine of HTML document is html tag. Every HTML document has to have this tag, and there has to be ONLY ONE html tag per document.
-
The head tag contains general information about the document. In this tag, later on, you will place the link to your stylesheets (which will enable you to style your document). Usually, it contains a title and metadata tags.
(favicon도 여기에 들어가며 head은 웹 SEO을 설정하기 위해 작업을 해야하는 경우가 있다.) A quick and easy guide to meta tags in SEO -
title tag - defines the title of the document. There’s only one title element in the head element of an HTML. This title only contains text, and it’s shown in the browser’s title bar or on the page’s tab.
-
meta tag - used to define metadata. It is meant to help browsers to render the page. In our example, this tag contains information of allowed charsets to be used in the document (charset defines which special characters are allowed, such as á or ñ).
-
body tag The body tag contains all the visible elements which will be presented to the users. There can be only one body element in an HTML document.
DOM
The Document Object Model (DOM) is a cross-platform and language-independent application programming interface that treats an HTML, XHTML, or XML document as a tree structure wherein each node is an object representing a part of the document. The objects can be manipulated programmatically, and any visible changes are occurring as a result may then be reflected in the display of the document.
In short, the DOM (Document Object Model) represents how the browser reads the HTML document. After the browser reads the HTML document, it creates a representational tree called the Document Object Model and defines how that tree can be accessed.
웹브라우저가 html 문서를 읽고 이러한 tree 형식의 html 부분/elements(node)들을 가진dom 오브젝트를 형성하는데 이 오브젝트를 사용해 UI 변화나 기능을 웹사이트에서 구현할수 있다.
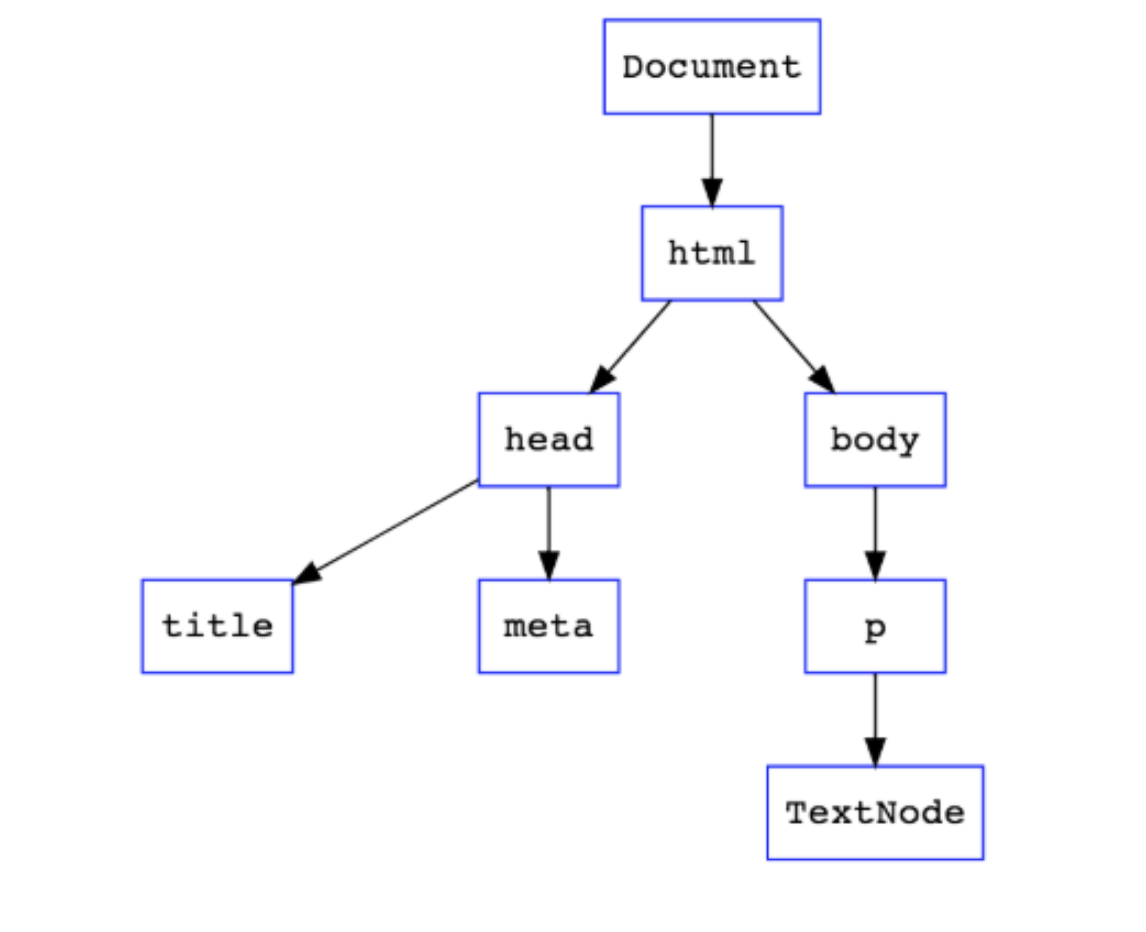
In the DOM, everything is a node. The document, the body, all other elements, the elements’ attributes, the content within the elements, are all nodes.
The DOM tree
위의 그림을 보면 알수 있듯이 document -> html -> head, body 형식으로 tree가 시작이 되는데 여기서 document노드가 제일 상위권 html/노드/엘레멘츠 가 다음 상위권 노드 그다음 head body는 자매 관계를 가진 head node의 자식 노드이다.
the DOM (Document Object Model) contains all of the elements of an HTML document
the DOM elements respect family tree structure
DOM collections
-
!!!DOM collections are read-only. DOM collections, and even more – all navigation properties listed in this chapter are read-only.
We can’t replace a child by something else by assigning childNodes[ i ] = ....
Changing DOM needs other methods. We will see them in the next chapter. -
DOM collections are live. Almost all DOM collections with minor exceptions are live. In other words, they reflect the current state of DOM.
If we keep a reference to elem.childNodes, and add/remove nodes into DOM, then they appear in the collection automatically. -
Don’t use for..in to loop over collections. Collections are iterable using for..of. Sometimes people try to use for..in for that. Please, don’t. The for..in loop iterates over all enumerable properties. And collections have some “extra” rarely used properties that we usually do not want to get:
<body>
<script>
// shows 0, 1, length, item, values and more.
for (let prop in document.body.childNodes) alert(prop);
</script>
</body>USE for ... of loop that iterates iterable with Symbol.iterator
Block level element
Block vs. Inline elements
A block level element begins a new line on the webpage and, if no width is set, extends the full width of the available horizontal space of its parent element.
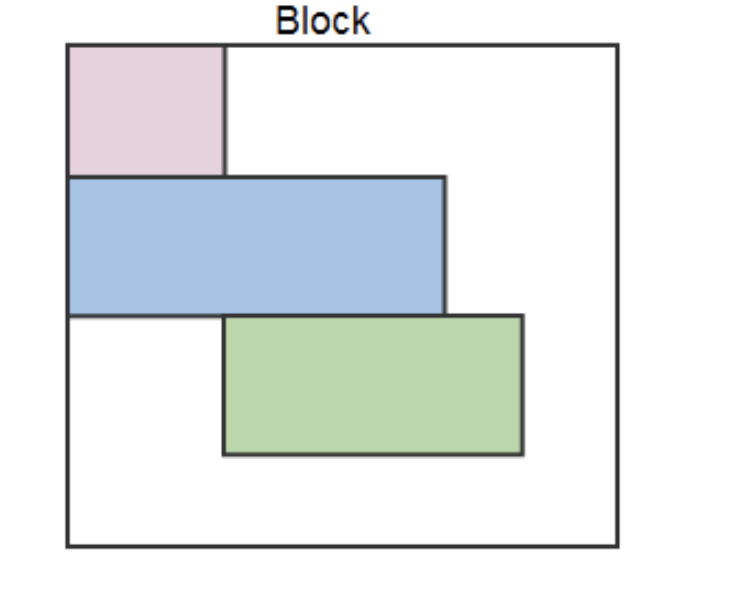
Inline elements flow like text. They don’t start a new line and only take up as much width as necessary.

The most used block level elements are:
- header block: < header >
- division block: < div >
- section block: < section >
- article block: < article >
- aside block: < aside >
- footer block: < footer >
- navigation block: < nav >
- headings: < h1 > ... < h6 >
- paragraph: < p >
- lists: < ul > , < ol >
- table: < table >
Semantic tags
nav, main, section, article, header, figure and figcaption, aside, footer, etc.
The < header > tag
According to the official MDN docs, < header > element represents an introductory content, typically a group of introductory or navigational aids. It may contain some heading elements but also a logo, a search form, an author name, and other elements.
< div >
< div >: The Content Division element is one of the most generic and most used elements when you start planning and building your page. Think of them as boxes that will group parts of your webpage that are supposed to go together.
If div has no content inside, its height will be zero by default.
< section >
According to the definition of < section > tag on W3.org, the section element represents a generic section of a document or application. A section, in this context, is a thematic grouping of content.
According to best practices,< div> element should be used as an element of last resort, for when no other element is suitable.
Use of more appropriate elements instead of the < div> element leads to better accessibility for readers and easier maintainability for authors.
< article >
The < article> tag can be seen as a stand-alone part of the website, being able to be distributed independently throughout the website or reused on some other websites.
The < article> element is a good choice to contain entire blog posts, news articles, and similar content.
example:
<section class="forecast">
<h1>Weather forecast for Seattle</h1>
<article class="day-forecast">
<h2>03 March 2018</h2>
<p>Rain.</p>
</article>
<article class="day-forecast">
<h2>04 March 2018</h2>
<p>Periods of rain.</p>
</article>
<article class="day-forecast">
<h2>05 March 2018</h2>
<p>Heavy rain.</p>
</article>
</section>< aside>
The < aside> tag represents part of a webpage but its content is not directly related to the main content displayed on the page - ex. sidebars.
Heading tags - < h1>...< h6>
Heading tags are used to describe headings of varying levels of importance.
<h1>h1 - The most important title on the page!</h1>
<h2>h2 - The second most important title on the page.</h2>
<h3>h3 - The third most important title on the page.</h3>
<h4>h4 - The fourth most important title on the page.</h4>
<h5>h5 - The fifth most important title on the page.</h5>
<h6>h6 - The sixth most important title on the page.</h6>The < p> (paragraph) tag
The paragraph tag, as seen above, is a block element that represents a paragraph or block of text.
Typically, these paragraph tags are proceeded by some heading to declare what the paragraph is about, or possibly other paragraph tags.
<h1>The Meaning of Life</h1>
<h2>Good Relationships</h2>
<p>Text supporting good relationships. Lorem ipsum dolor sit amet, consectetur adipisicing elit. Repudiandae suscipit, excepturi totam commodi sed autem possimus quod omnis neque quo exercitationem earum quam explicabo eveniet fuga nulla atque. Deleniti, voluptate.</p>
List < ul>, < ol >
< ol> - We use it when we need to express certain data that needs to follow the specific order (such as recipes or list of instructions), and in this case, we are talking about ordered lists
< ul> - when the order does not matter,
< li> - Each item in the list will be on a new line, separated with bullet points or number depends on the type of list elements that the list elements are nested within. li elements should only be used inside of lists.
The < table>
The < table> tag is used to organize tabular data in different rows and columns.
Read MDN for more details
<table>
<thead>
<tr>
<th colspan="2">The table header</th>
</tr>
</thead>
<tbody>
<tr>
<td>The table body</td>
<td>with two columns</td>
</tr>
</tbody>
</table>
which is resulted as below:
| The table header | |
|---|---|
| The table body | with two columns |
1 Difference between td and th
The main difference between td and th is that th is used just for titles and headers of the table, while td is used for the content.
2 DO NOT USE IT AS FOR LAYOUT OF WEBPAGE (even for part of website)
The < footer> tag
< footer> tag is a structural element used to identify the footer of a page, document, article, or section. This tag typically contains copyright and authorship information or additional navigational elements.
Semantics?
Semantic HTML is HTML with a meaning.
When google seo crawler engine looks at your website, and your website is not sementically made, it can't infers the website's meaning based on poorly managedtags and attributes.
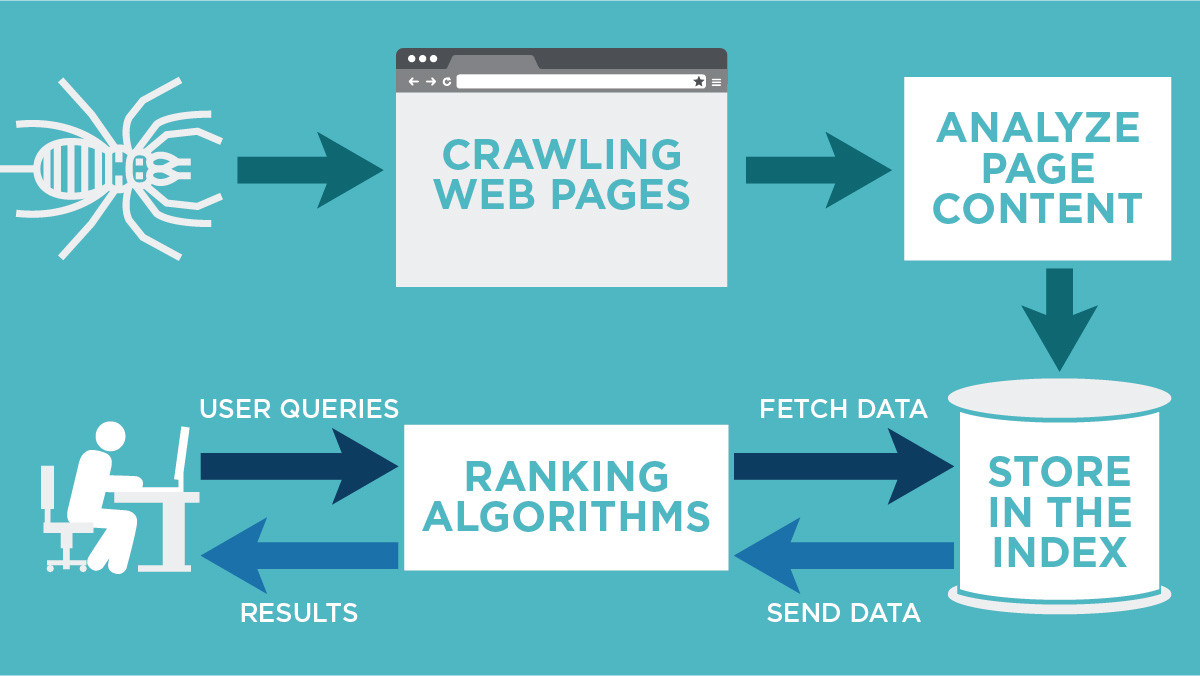
구글이 SEO Crawler 엔진이 어떻게 웹페이지를 인덱싱 하고 유저들에게 보여주는 과정.
Basic website sementaic layout:
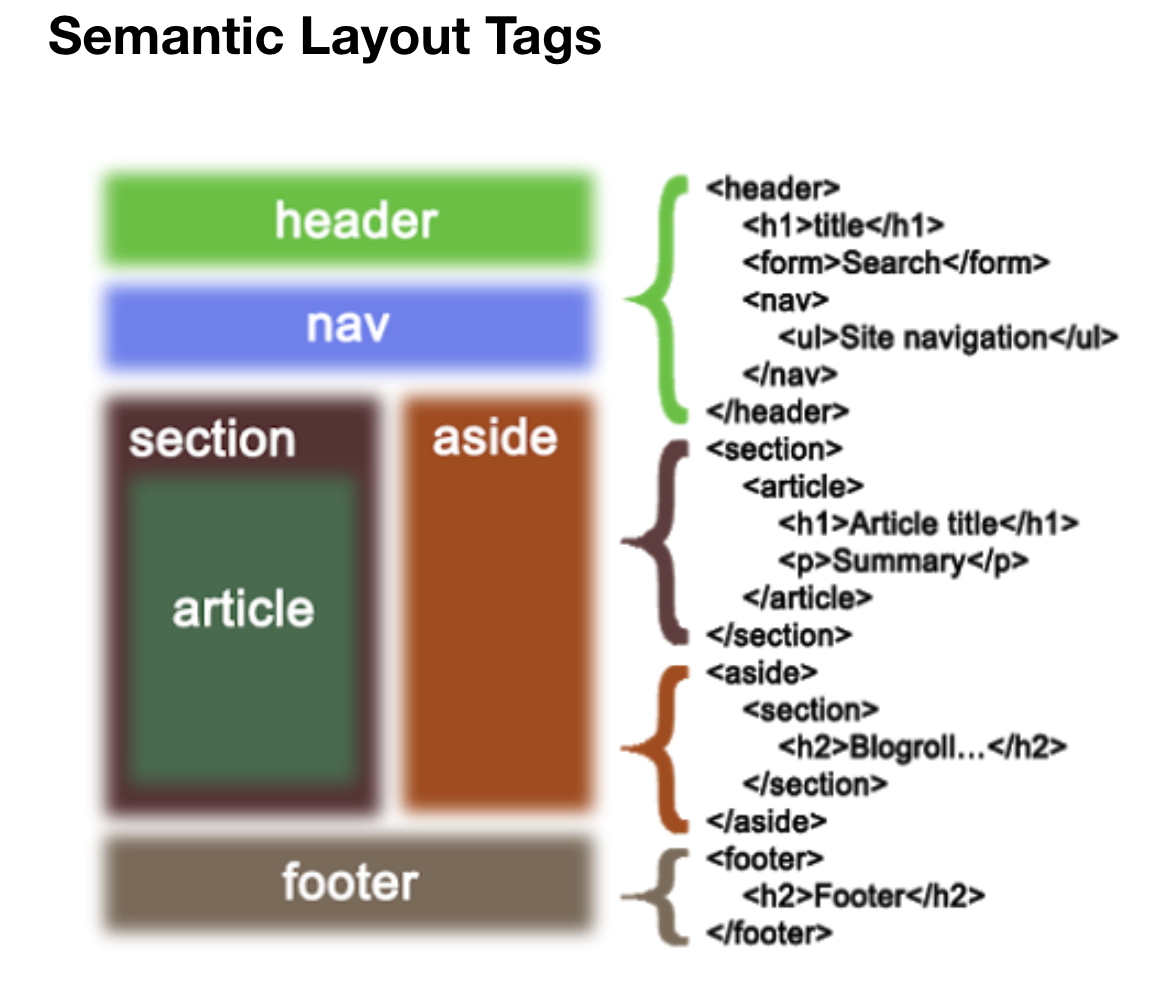
semantic tags:
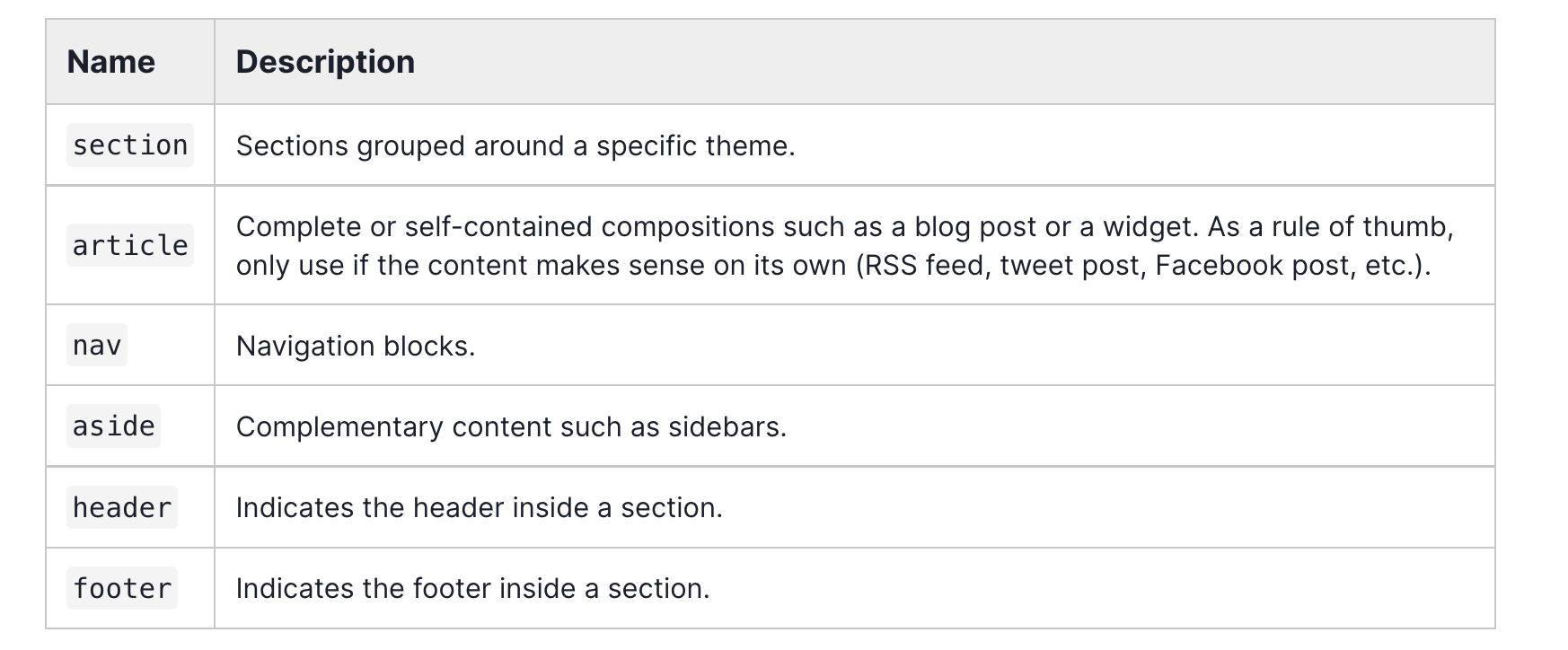
Every sectioning element (body, article, section, nav and aside) can have its own header and footer.
Review
- HTML is a language for creating web pages and applications,
- HTML elements are the building blocks of web pages,
most of the tags have opening and closing part, but some tags are self-closing - the DOM (Document Object Model) contains all of the elements of an HTML document
- the DOM elements respect family tree structure
