https://www.youtube.com/watch?v=7S_tz1z_5bA&t=1080s&ab_channel=ProgrammingwithMosh
위의 유트브 튜토리얼 영상을 보면서 네이티브 쿼리 연습을 진행중이다.
현재 작업하고 있는 외주 프로젝트에서 RDBMS mysql을 쓰려 하는데 처음으로 사용하다 보니 db 테이블을 그려가면서 미리 계획 디자인을 할때 네이티브 쿼리 자체를 모르니 설계 할때 애로사항이 있었다. (one to one, one to many, many to many 컨셉도 구글링으로 계속 읽어 갔지만 역시 직접적으로 연습을 해야 좀더 테이블 스키마를 구체화 하기 쉬워 질거 같다.)
study에 나오는 sql_store db구조는 이런식이다.

Query clauses
- USE - db 선택
- SELECT - column 선택
- FROM - table 선택
- WHERE + 조건(column) - 쿼리값을 구할때 WHERE을 사용해 조건을 붙여 필터링 할수 있다.
- ORDER BY + 조건(column) - 쿼리값을 구할때 조건에 따라 sorting 해서 준다.
USE sql_store;
SELECT *
FROM customers
-- WHERE customer_id = 1 // -- means comment 혹은 주석
ORDER BY first_nameSELECT in details
SELECT last_name, first_name, points, points + 10
FROM customers
위에 + 는 연산을 해서 원래 points 콜룬의 값에 10을 더한 값들을 가진 콜룬을 보여준다.
-
SQL 에는 연산자들이 아래 처럼 있다. 마치 프로그래밍 언어처럼
+, -, *, % -
as를 사용해 반환되는 새 콜룬에 익명을 줄수 있다.
SELECT
last_name,
first_name,
points,
(points + 10) * 100 as 'discount factor'
FROM customers
DISTINCT
예)
SELECT DISTINCT state
FROM customers
- 위에 SELECT절 뒤에 distinct을 붙이므로 customer 테이블에서 중복된 state 값을 걸러낸다.
WHERE
쿼리 반환값을 필터링 해준다
SELECT *
FROM customers
WHERE points > 3000
- 위 쿼리에선 customers 테이블에서 3000 point를 초과하는 포인트를 가진 customers row 를 반환 한다
sql comparison operator list:
=
<
<=
= equality
!= not equality
<> not equality
SELECT *
FROM customers
WHERE state = 'VA'
- 위 쿼리 state = 'VA' 에서 '' 가 붙는 이유는 텍스트 데이터 타입들을 쿼리 할땐 스트링에 맞춰 쿼리 한다.
SELECT *
FROM customers
WHERE birth_date > '1990-01-01';
- 위 쿼리는 customers 테이블에서 customer 생년월일이 1990 이후인 사람들 row를 반환한다.
**DATE YYYY-MM-DD 과 텍스트 데이터 타입은 SQL에선 ''로 감싸서 쿼리한다.
SELECT *
FROM orders
WHERE order_date >= '2018-01-01';
- 위 쿼리는 order중 오더 날짜가 2018 1월 1일 과 2019년도 사이에 만들어진 order를 반환한다.
AND, OR, and NOT = Logical operators
SELECT *
FROM Customers
Where birth_date > '1990-01-01' AND points > 1000;
-
위 쿼리는 커스터머중 1990-01-01 이후에 태어난 사람중 포인트를 1000점 초과하는 사람을 반환한다.
SELECT *
FROM Customers
Where birth_date > '1990-01-01' OR points > 1000; -
반면에 위 쿼리는 1990-01-01 이후에 태어나거나 포인트 점수가 1000점 초과한 커스터머만 반환한다.
AND 나 OR 을 사용해 컨디션을 더 붙인다.
SELECT *
FROM Customers
Where birth_date > '1990-01-01' OR
(points > 1000 AND state = 'VA') -
위 쿼리처럼 여러 logical operators를 쓸때 사용 순서가 중요하다는걸 보여준다.
() 가 없어도 MYSQL에서는 AND가 OR보다 순서적으로는 먼저다.
그럼으로 위 쿼리에서 OR 뒤에 조항에 해당하는 커스터머 row가 먼저 반환 되고 그다음 birth_date > '1990-01-01' 컨디션에 해당하는 row들이 반환된다.SELECT *
FROM Customers
WHERE NOT (birth_date > '1990-01-01' OR points > 1000);
-
위 쿼리와 아래 쿼리는 같다. NOT은 모든 조건들을 inverse 반대화 한다.
SELECT *
FROM Customers
WHERE birth_date < '1990-01-01' AND points <= 1000;Excercise:
order_items 테이블에서 오더 번호가 6이면서 자제값 과 물류량을 계산해 총 가격이 30이 넘는 오더를 반환 해라.
SELECT ,
quantity unit_price AS total
FROM Order_items
WHERE order_id = 6
AND quantity * unit_price > 30;IN operator
expr IN (value,...) - Returns 1 (true) if expr is equal to any of the values in the IN() list, else returns 0 (false). This is equivalent to the expression (min <= expr AND expr <= max)
SELECT *
FROM Customers
WHERE state = 'VA' OR state = 'GA'OR state = 'FL' -
위 쿼리와 아래 쿼리는 똑같은 customer rows 를 반환한다.
조건문에 OR 을 체이닝 하는거보다 훨씬 깔끔한 방법이다.
SELECT *
FROM Customers
WHERE state IN('VA', 'FL', 'GA')
반대로 아래 쿼리는 위의 쿼리와 반대적인 반환값이 나온다.
SELECT *
FROM Customers
WHERE state NOT IN('VA', 'FL', 'GA');
BETWEEN operator
expr BETWEEN min AND max - If expr is greater than or equal to min and expr is less than or equal to max, BETWEEN returns 1, otherwise it returns 0.
- Let's say if we want to see customers who has points more than equal to 1000 and less than equal to 3000. one way to write this in query would be:
SELECT *
FROM Customers
WHERE points >= 1000 AND points <= 3000;
위 쿼리는 아래와 같다.
SELECT *
FROM Customers
WHERE points BETWEEN 1000 AND 3000;
- For best results when using BETWEEN with date or time values, use CAST() to explicitly convert the values to the desired data type. Examples: If you compare a DATETIME to two DATE values, convert the DATE values to DATETIME values. If you use a string constant such as '2001-1-1' in a comparison to a DATE, cast the string to a DATE.
- Between에 들어갈 expr에 숫자 타입 말고도 date 타입도 사용할수있다.
Like operator
- expr LIKE pat [ESCAPE 'escape_char'] - Pattern matching using an SQL pattern. Returns 1 (TRUE) or 0 (FALSE). If either expr or pat is NULL, the result is NULL.
With LIKE you can use the following two wildcard characters in the pattern:
% matches any number of characters, even zero characters.
_ matches exactly single character.
helps matching value that matches specific string pattern.
SELECT *
FROM Customers
Where last_name Like 'b%';
위 쿼리는 커스터머중 성이 b로 시작하는 커스터머를 반환한다.
%는 b뒤에 있는 문자패턴을 가르키며 대소문자 가리지 않는다.
SELECT *
FROM Customers
Where last_name Like 'brush%';
위 쿼리는 커스터머중 성이 specific하게 brush시작 커스터머를 반환.
SELECT *
FROM Customers
Where last_name Like '%b%';
위 쿼리는 커스터머중 성에 앞뒤 위치 상관없이 b가 value에 들어가 있는 커스터머.
SELECT *
FROM Customers
Where last_name Like '%y';
위 쿼리는 커스터머중 성의 마지막 문자가 y인 사람.
SELECT *
FROM Customers
Where last_name Like '_y' ;
위 쿼리는 커스터머중 성에서 여섯번째 문자가 y인 커스터머를 반환
SELECT *
FROM Customers
Where last_name Like 'b____y';
위 쿼리는 커스터머중 성이 첫번째 문자는 b, 그리고 여섯번째는 y로 끝나는 커스터머 반환
SELECT *
FROM Customers
Where
address LIKE '%trail%' OR
address LIKE '%avenue%'
AND phone LIKE '%9';
위 쿼리는 커스터머중 주소값에 'trail' 과 'avenue' 스트링 패턴을 포함하는 커스터머중
전화번호가(varchar) '9'로 끝나는 커스터머를 반환 한다.
REGEXP operator
- REGEXP가 Like보다 스트링 패턴에선 더욱 유용하다.
SELECT *
FROM Customers - WHERE lastname REGEXP '^field'
_last_name이 'field'로 시작하는 커스터머 반환 - WHERE lastname REGEXP 'field$'
_last_name이 'field'로 끝나는 커스터머 반환 - WHERE lastname REGEXP 'field|mac|rose'
_last_name이 field or mac or rose 포함하고 있는 커스터머 반환 - WHERE lastname REGEXP '^field|mac|rose'
_last_name이 'field'로 시작하거나 'mac' OR 'rose' 를 포함하는 커스터머 - WHERE lastname REGEXP 'field$|mac|rose'
_last_name이 'field'로 끝나거나 OR mac OR rose를 포함하는 커스터머 - WHERE lastname REGEXP '[gim]e'
_last_name이 'ge' OR 'ie' OR 'me' 를 포함하는 커스터머 - WHERE lastname REGEXP 'e[fmq]'
_last_name이 'ef' OR 'em' OR 'eg'를 포함하는 커스터머 - WHERE lastname REGEXP '[a-h]e'
_last_name이 'a' 부터 'h'까지 + 'e' 패턴을 포함하는 커스터머
^ beginning
$ end
| logical OR
[ abcd ][ a-f ] range
더 많은 정보는 공식문서에서....
https://dev.mysql.com/doc/refman/8.0/en/regexp.html
예제:
-- Get the customers whose first names are elka or ambur
-- SELECT *
-- FROM Customers
-- WHERE first_name REGEXP 'ELKA|AMBUR';
-- last names end with ey or on
-- SELECT *
-- FROM Customers
-- WHERE last_name REGEXP 'EY'
-- last names start with 'my' or contain 'se'
-- SELECT *
-- FROM Customers
-- WHERE last_name REGEXP '^my|se'
-- last name contain 'b' followed by 'r' or 'u'
SELECT *
FROM Customers
WHERE last_name REGEXP 'b[ru]'
IS NULL operator
Let's say if want to look for customer who dont have a phone number in our db.
Perhaps we want to send them an email that they are missing phone num.
SELECT *
FROM customers
WHERE phone IS NULL
아래 쿼리는 위에꺼와 반대 값을 반환.
SELECT *
FROM customers
WHERE phone IS NOT NULL
예제: db에서 커스터머 오더(테이블)중에 배송 완료가 안된 오더를 찾아라.
SELECT *
FROM orders
WHERE shipped_date IS NULL
ORDER BY clause
SELECT *
FROM customers
ORDER BY state DESC;
- state 아래로 내려오는 sorting
SELECT *
FROM customers
ORDER BY state, first_name;
- 커스터머중 state 부터 sorting 하고 그다음에 first_name 콜룬을 sorting 한다.
SELECT *
FROM customers
ORDER BY state DESC, first_name;
-
반환하는 커스터머 값을 state 을 아래로 내려오는 sorting하고 그다음에 first_name을 asending manner로 sorting한다.
-
You can sort data by any columns whether that column is in the select clause or not.
예)
SELECT first_name, last_name
FROM customers
ORDER BY birth_date
SELECT first_name, last_name
FROM customers
ORDER BY 1, 2 < -- NOT RECOMMENDED syntax
- 위 쿼리의 1,2 뜻은 sorting을 first_name먼저 sorting 한후 last_name을 sorting한다.
예제:
SELECT , quantity unit_price AS total_price
FROM order_items
WHERE order_id = 2
ORDER BY total_price DESC
Limit clause
Limit절은 pagination 할때 유용하다.
예시: 3번째 페이지에서는 7-9 row 데이터만 필요하다면...
SELECT *
FROM customers
LIMIT 6(offset), 3 <------ 처음 6개 row 커스터머를 스킵하고 그다음 3 커스터머를 반환
-- page 1: 1-3
-- page 2: 4-6
-- page 3: 7-9
challenge:
-- Get the top three loyal customers
답:
SELECT *
FROM customers
ORDER BY points DESC
LIMIT 3
Order of caluse in mysql grammer
- mysql 문법 순서이다.
SELECT
FROM
WHERE
ORDER BY
LIMIT
INNER JOINS
- 여태까지 나는 하나의 테이블에서 쿼리를 해왔다. 그치만 실무에선 multiple 테이블 관계성을 이용해 쿼리 한다.
예시) 커스터머 중 오더를 만든 커스터머를 쿼리해서 데이터를 보고 싶다. 이러한 상황엔 어떤 쿼리가 올바를까?
orders 테이블엔 customer_id 콜룬이 있어서 참조 할수 있다.
SELECT order_id, o.customer_id, first_name, last_name
FROM orders as o
INNER JOIN customers as c
ON o.customer_id = c.customer_id;
- 위 쿼리는 FROM orders, INNER JOIN customers 테이블에 익명을 각각 'o', 'c'를 부여한다.
- INNER는 스킵할수 있다.
- INNER JOIN절 뒤에 조인할 테이블
- ON절 뒤에 조인 컨디션 혹은 join specification
- SELECT statement후 customer_id콜룬은 orders, customers 테이블 둘안에 존재 하기 때문에 어디 테이블 소속인지 상세화 해야한다. 예) orders.customer_id
joined_table: {
table_reference {[INNER | CROSS] JOIN | STRAIGHT_JOIN} table_factor [join_specification]
| table_reference {LEFT|RIGHT} [OUTER] JOIN table_reference join_specification
| table_reference NATURAL [INNER | {LEFT|RIGHT} [OUTER]] JOIN table_factor
}
join_specification: {
ON search_condition
| USING (join_column_list)
}
mysql 공식 문서를 보니 위에 하이라이트 한 부분을 사용하는것이 기본적인 문법인거 같다.
- In MySQL, JOIN, CROSS JOIN, and INNER JOIN are syntactic equivalents (they can replace each other). In standard SQL, they are not equivalent. INNER JOIN is used with an ON clause, CROSS JOIN is used otherwise.
문제:
For each order form orders table, return both the product id as well as its name(products table), followed by the quantity(o.quantity), and unit price(o.unit_price) from order_item table.
SELECT order_id, o.product_id, quantity, o.unit_price, name
FROM order_items as o
INNER JOIN products as p
ON o.product_id = p.product_id;
- 위 쿼리에서 조인 하는 테이블 두개에서 같은 콜룬이 있다면 상황에 맞게 alias를 SELECT절 안에 사용해야 한다.
- 위 쿼리는 생성된 오더들중 제품 이름과 주문량, 주문당시 가격, 제품 id를 반환한다.
- order_items 테이블과 products 테이블을 조인.
Joining across multiple DBs
실무에선 여러 db를 한 프로젝트에 사용해 일을 할수 있습니다.
이럴때 다른 db에서 테이블들 스키마 형태가 비슷하면 좋은 db 디자인 이라고 말하기 어렵습니다.
일단 여러 db 테이블들을 조인할떄 문법은 이렇습니다.
USE sql_store; < == sql_store db을 사용한다
SELECT *
FROM order_items as oi
JOIN sql_inventory.products as p < === sql_inventory db안에 product 테이블을 조인한다
ON oi.product_id = p.product_id; < === oi 테이블 과 p 테이블에서 product_id가 매칭이 되는 row를 반환한다.
Self Joins
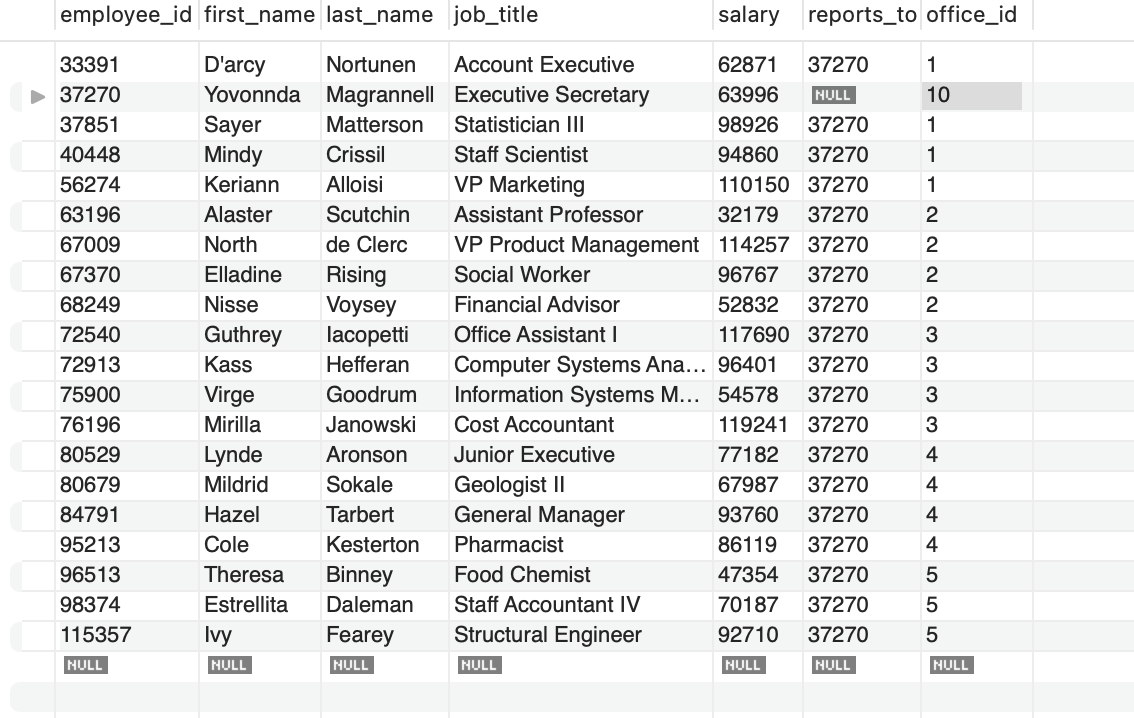
이러한 테이블이 있다 하자.
employee_id는 각 직원의 고유 아이디이고 reports_to값은 매니저를 참조한다.
여기서 reports_to는 employee_id 값이 37270을 가진 Magrannell을 가리키며 이러한 테이블은 self join을 할수 있게 한다. 이 방법 외에도 여러가지 다른 방법이 있겠지만 (manager 테이블을 따로 만든다던가 role, manager 테이블 두개를 따로 생성 해서 미래 유지보수를 대비하던가) 이 방법이 심플해 보이긴 했다.
답)
USE sql_hr;
SELECT *
FROM employees e
JOIN employees m
ON e.reports_to = m.employee_id;
위의 예시에서 좀더 나아가 더 심플한 반환값을 위해 쿼리를 작성해서 직원 이름이랑 매니저 이름만 추출해보자.
SELECT e.employee_id,
e.first_name AS emp_first_name,
e.last_name AS emp_last_name,
m.first_name AS manager_first_name,
m.last_name AS manager_last_name
FROM employees e
JOIN employees m
ON e.reports_to = m.employee_id;
보다시피 같은 테이블에 다른 익명을 사용해 조인 시킴으로서 self 조인이 할수 있다.
Joining multiple tables
- 실무에선 2개 혹은 10개 이상의 테이블들을 조인해서 쿼리를 작성할때도 있습니다.
아래는 총 세개의 테이블을 조인 해서 만든 쿼리 예시입니다.
USE sql_store;
SELECT o.order_id, o.order_date, c.first_name, c.last_name, os.name AS status
FROM orders AS o
JOIN customers as c
ON o.customer_id = c.customer_id
JOIN order_statuses as os
ON o.status = os.order_status_id
ORDER BY o.order_id;
예시문제:
-- use payments table as base and join it with other tables so that you can
-- produce a report that shows the payment with more details, name of the clients and payment methods.
SELECT
p.payment_id,
p.amount,
pm.name AS payment_method_name,
p.date AS payment_date,
i.due_date AS payment_due_date,
i.number AS invoice_number,
c.name AS client_name
FROM payments AS p
JOIN clients AS c
ON p.client_id = c.client_id
JOIN payment_methods AS pm
ON p.payment_method = pm.payment_method_id
JOIN invoices AS i
ON p.invoice_id = i.invoice_id
ORDER BY payment_date
Compound Join condintion
여태까지 우린 하나의 콜룸을 이용해 테이블안에 row들을 식별해 왔습니다.
customers 테이블이 있다할때 보통 customer_id 라던가 하는 콜룬이 있어 식별할수 있었지만 때에 따라 같은 방법을 사용해 특정 데이터를 식별 할수 없을때가 있습니다. 그 예로 들어 id 값에 복수 중복값들이 있다면 하나의 데이터 을 쿼리 할려고 할떄 애로사항이 있읈 있지요.
-
그러할때 우리는 하나 대신 여러 콜룬을 조인 컨디션으로 사용해 쿼리를 작성합니다.
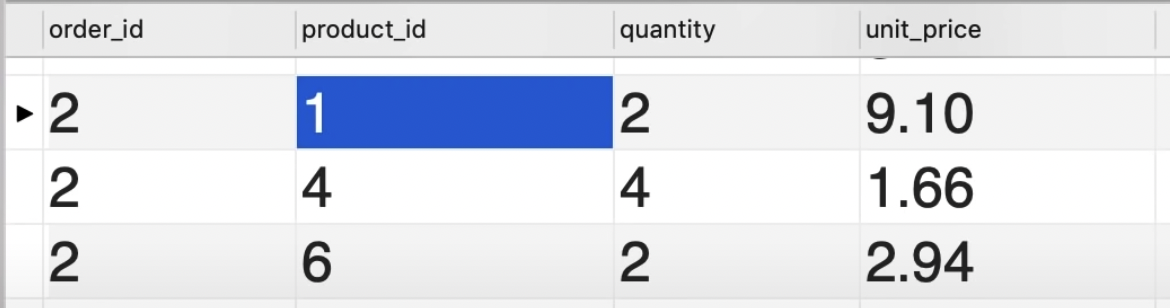
-
composite primary keys - primary key가 두개가 한 테이블에 존재 할때
USE sql_store;
SELECT *
FROM order_items oi
JOIN order_item_notes oin
ON oi.order_id = oin_order_id
AND oi.product_id = oin.product_id; <=== 조인 컨디션을 더한다.
Implicit Join Syntax
우리는 여태까지 조인을 이러한 식을 작성했습니다.
SELECT *
FROM orders o
JOIN customers c
ON o.customer_id = c.customer_id;
더 쉽게 쓸수 있는 방법이 있는데....
SELECT *
FROM orders o, customers c,
WHERE o.custoemr_id = c.customer_id <=== join 컨디션이 WHERE 에 들어간다.
WHERE + 조인 컨디션을 안쓰면 cross join이 나온다
EXplicit 문법으로 쓰는게 보통 더 좋은거 같긴 하다...
OUTER JOIN
여태까진 INNER JOIN/JOIN은 INNER JOIN 입니다.
Outer Join에는 두가지가 있는데 LEFT JOIN, RIGHT JOIN이 있습니다.
예시:
SELECT
c.customer_id,
c.first_name,
o.order_id
FROM orders o
JOIN customers c
ON o.order_id = c.customer_id;
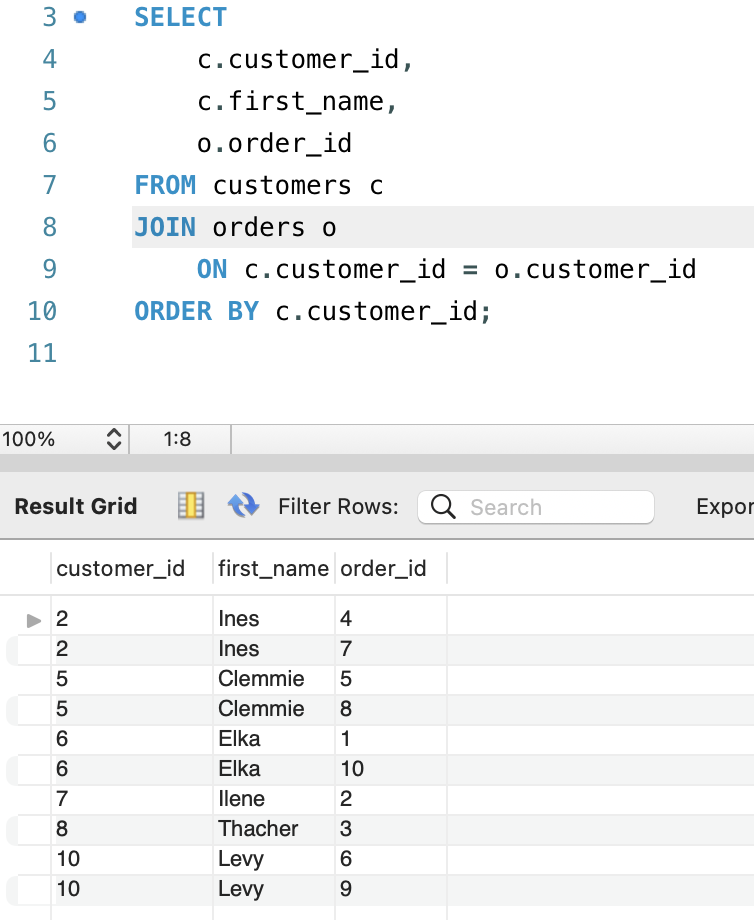
위 쿼리는 오더를 생성한 커스터머만 정보만 리턴 합니다. 그런데 만약 우리가 오더를 생성하지 않은 커스터머 정보까지 조인쿼리로 반환하려면 어떻게 해야 할까요? 여기선 LEFT JOIN을 써보겠습니다.
SELECT
c.customer_id,
c.first_name,
o.order_id
FROM customers c
LEFT JOIN orders o <=== 여기서 LEFT 는 customers 테이블을 가르킵니다. 반대로 RIGHT은 orders 가 되겠죠
ON c.customer_id = o.customer_id
ORDER BY c.customer_id;
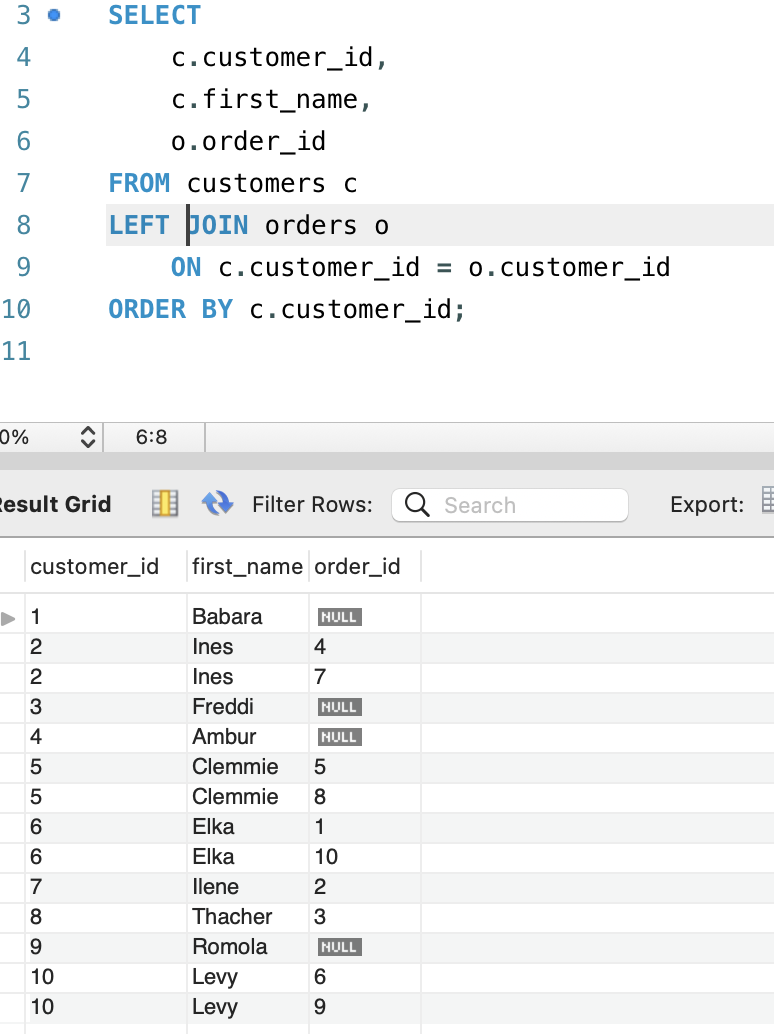
실무에선 다른 개발자들이 LEFT/RIGHT OUTER JOIN을 쓸때가 있는데 OUTER는 옵션입니다.
- challenge: Produce a report that returns all of products that have been made in orders and those that have not.
SELECT
p.product_id,
p.name,
oi.quantity
FROM products p
LEFT JOIN order_items oi
ON p.product_id = oi.product_id
ORDER BY p.product_id
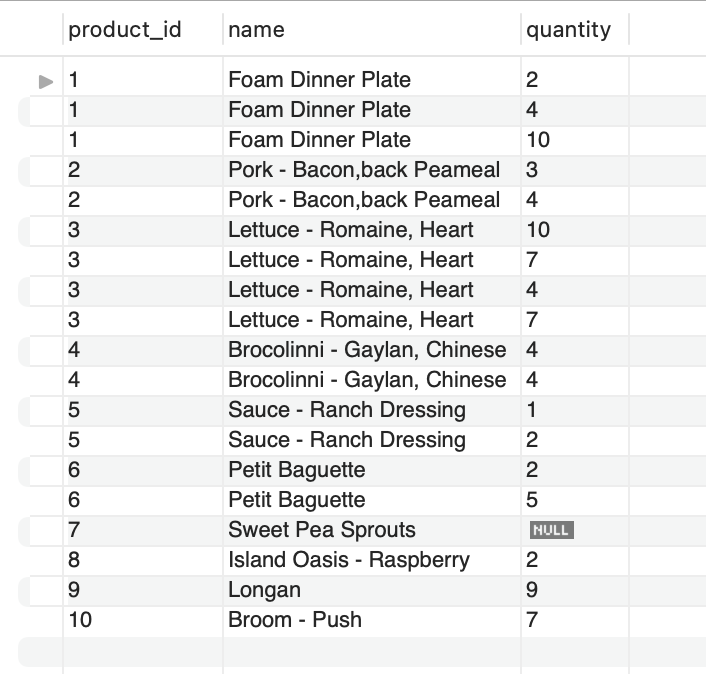
- 위의 product id 7 제품은 오더가 들어오지 않았으므로 order_items의 quantity에 null로 반환된다.
OUTER JOIN between multiple tables
아래 쿼리는 모든 커스터머 정보 및 오더를 만든 커스터머 까지 반환 합니다.
오더를 생성하지 않은 커스터머는 order_id키 값이 null이 되죠.
SELECT
c.customer_id,
c.first_name,
o.order_id
FROM customers c
LEFT JOIN orders o
ON c.customer_id = o.customer_id
ORDER BY c.customer_id

이런식으로 반환이 되네요.
한편, 여기서 shippers 라는 orders 테이블과 연관된 테이블 데이터들도 조인 하려 합니다.
INNER JOIN으로 조인을 체이닝 하면...
SELECT
c.customer_id,
c.first_name,
o.order_id,
o.shipper_id,
sh.name AS shipper
FROM customers c
LEFT JOIN orders o
ON c.customer_id = o.customer_id
JOIN shippers sh
ON o.shipper_id = sh.shipper_id
ORDER BY c.customer_id

뭔가가 잘못된걸 느낍니다.
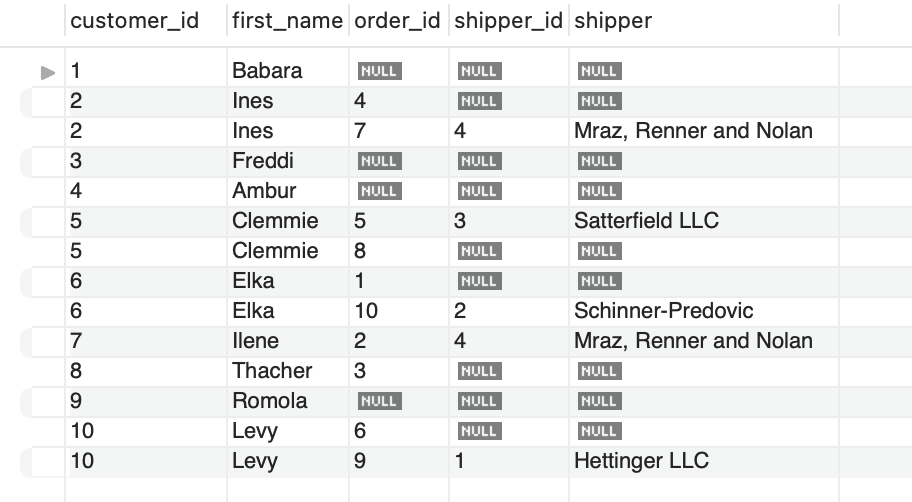
여기서 문제점은 orders 데이터들중에 오더가 생성이 안되 orders 테이블에 shipper_id가 null되어 있는 로우들이 있습니다. 여기서 LEFT JOIN을 써서 모든 커스터머, 모든 오더의 shipper_id 정보까지 반환하려 쿼리를 수정하면....
SELECT
c.customer_id,
c.first_name,
o.order_id,
o.shipper_id,
sh.name AS shipper
FROM customers c
LEFT JOIN orders o
ON c.customer_id = o.customer_id
LEFT JOIN shippers sh
ON o.shipper_id = sh.shipper_id
ORDER BY c.customer_id
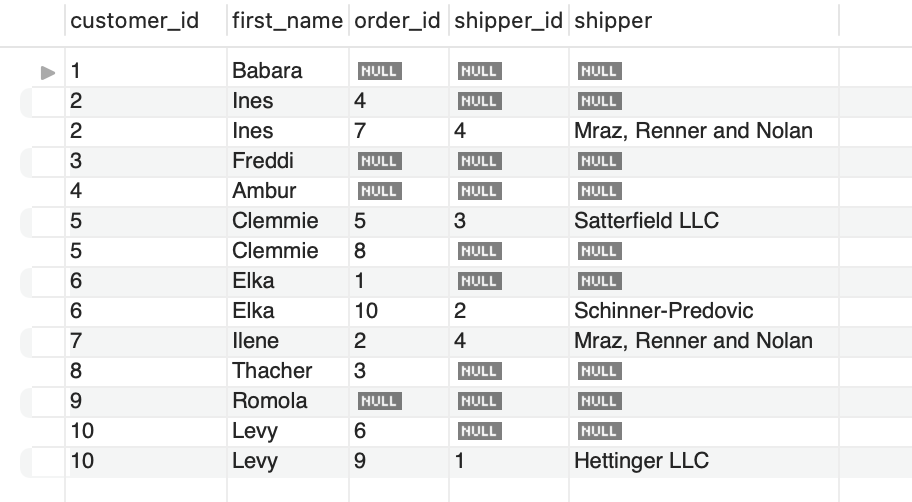
이렇게 제대로 나오네요.
- It is best practice to chaing LEFT JOIN(s) instead of mixing LEFT and RIGHT joins. <- less obvious and confusing
lef와 right 조인을 섞으면 개발자나 db 관리자가 쿼리를 분석하기 힘듭니다. 추천 안함.
- challenge: 오더 관련 정보를 반환해야 하는데 오더를 생성한 커스터머 이름(1) 그리고 배송자(2)이름 배송 상태(3) 배송날짜 (4) 그리고 오더 고유 넘버(5) 를 보여줘야한다. orders, customers, shippers, order_status 테이블들을 조인해서 쿼리를 작성해라.
SELECT
o.order_date,
o.order_id,
c.first_name,
sh.name AS shipper,
os.name AS status
FROM orders o
JOIN customers c <== INNER JOIN를 하는 이유는 각 오더에는 customer_id가 not null.
ON o.customer_id = c.customer_id
LEFT JOIN shippers sh <== LETF 는 orders를 가리킨다
ON o.shipper_id = sh.shipper_id
JOIN order_statuses os <== orders.status는 항상 값이 있다. not null
ON o.status = os.order_status_id
SELF OUTER JOINS
저번에 SELF JOIN을 연습해본 쿼리를 다시 보자면
USE sql_hr;
SELECT
e.employee_id,
e.first_name,
m.first_name AS manager
FROM employees e
JOIN employees m
ON e.reports_to = m.employee_id; <== only returns people who has manager
그치만, 위 쿼리는 매니저가 있는 직원들 데이터만 반환한다. 만약
우린 매니저들의 상사값도 반환 받고 싶다면 아우터 쿼리 형식으로 아래처럼
USE sql_hr;
SELECT
e.employee_id,
e.first_name,
m.first_name AS manager
FROM employees e
LEFT JOIN employees m
ON e.reports_to = m.employee_id;
LEFT 베이스가 employees 테이블 이므로 상사가 없는 매니저 직원의 상사 값(null)이 나온다.
USING caluse
USE sql_store;
SELECT
o.order_id,
c.first_name,
sh.name as shipper
FROM orders o
JOIN customers c
-- ON o.customer_id = c.customer_id 아래 USING은 같다
USING(customer_id)
LEFT JOIN shippers sh
USING(shipper_id)
SELECT *
FROM order_items oi
JOIN order_item_notes oin
-- ON oi.order_id = oin.order_id AND
-- oi.product_id = oin.product_id
USING (order_id, product_id)
- 예제)
USE sql_invoicing;
SELECT
p.date,
c.name AS client,
p.amount,
pm.name as payment_method
FROM payments p
JOIN clients c
USING(client_id)
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id;
Natural Joins
In mysql, we have easier way to write joins but not so recommend in real practice.
This guide illustrates just few examples for the sake of familarity.
USE sql_store;
SELECT
o.order_id,
c.first_name
FROM orders o
NATURAL JOIN customers c; < === natural join lets the mysql db to infer this query based on the common column from both table.
- 위 Natural Join은 쓰기에는 매우 편하나 db한테 전적으로 쿼리 해독을 맡기기에 조금 위험할수 있다.
* Cross Joins
We use cross joins to combine or join EVERY records from first table and EVERY records from second table.
Meaning it returns every instances of table A and table B.
SELECT
c.first_name AS client,
p.name AS product
FROM customers c
CROSS JOIN products p
ORDER BY c.first_name
위 예제는 좋은 예제는 아니지만, 여러개 테이블(small, medium sizes in number of columns and datas)를 cross join을 해서 한꺼번에 쿼리하기엔 괜찮다.
아래 쿼리는 위의 쿼리와 같지만 더 간결한 문법이다. FROM 에 여러개 테이블들을 쓸수 있다.
SELECT
c.first_name AS client,
p.name AS product
FROM customers c, orders o
ORDER BY c.first_name
- challeng: Do a cross join between shippers and products, by using the implicit syntax, and then using the explicit syntax
SELECT
p.product_id,
p.name as product_name,
sh.name as shipper
FROM products p, shippers sh
ORDER BY p.product_id;
or
SELECT
p.product_id,
p.name as product_name,
sh.name as shipper
FROM products p
CROSS JOIN shippers sh
ORDER BY p.product_id
Union
We been using JOINs to combine colmns from multiple tables for the return value.
In SQL, we can combine rows(instance, data) from multiple tables.
VERY POWERFUL
SELECT
order_id,
order_date,
'Active' as status
FROM orders
WHERE order_date >= '2019-01-01'
위쿼리의 반대는...
SELECT
order_id,
order_date,
'Archived' as status
FROM orders
WHERE order_date < '2019-01-01'
SELECT <=== (1)
order_id,
order_date,
'Active' as status
FROM orders
WHERE order_date >= '2019-01-01'
UNION
SELECT <=== (2)
order_id,
order_date,
'Archived' as status
FROM orders
WHERE order_date < '2019-01-01'
Combine caluse는 여러 쿼리를 결합하여 값을 반환한다.
한가지 주의할건 각 쿼리의 SELECT뒤에 콜론 수는 모두 같아야 한다.
-
2번째 예시:
SELECT first_name <== 첫번째 쿼리의 콜룬이 리턴값의 키이름으로 지정된다.
FROM customers c
UNION
SELECT name <== name 키값은 안나옴
FROM shippers sh
-
challenge:
SELECT
customer_id,
first_name,
points,
'Bronze' AS types
FROM customers
WHERE points < 2000
UNION
SELECT
customer_id,
first_name,
points,
'Silver' AS types
FROM customers
WHERE points Between 2000 AND 3000
UNION
SELECT
customer_id,
first_name,
points,
'Gold' AS types
FROM customers
WHERE points > 3000
ORDER BY first_name
Column attributes
How to insert, update, delete datas in db or tables.
Insert a single row
INSERT INTO customers (
first_name,
last_name,
birth_date,
address,
city,
state
)
Values(
'John',
'Smith',
'1990-06-01',
'address',
'city',
'WA',
)
Insert multiple rows
USE sql_store;
INSERT INTO shippers(name)
VALUES('shippers1'),
('shippers2'),
('shippers3')
Inserting Hierarchical Rows
So far I been inserting new row in single table.
Here's some examples of how to insert datas in multiple tables.
INSERT INTO orders(customer_id, order_date, status)
VALUSE(1, '2019-01-02', 1);
SELECT LAST_INSERT_ID() <== returns id of last row in a table.
INSERT INTO orders(customer_id, order_date, status)
VALUSE(1, '2019-01-02', 1);
INSERT INTO order_items
VALUES
(LAST_INSERT_ID(), 1, 1, 2.95),
(LAST_INSERT_ID(), 2, 1, 3.95)
Create copy of a table with Sub query
1)
CREATE TABLE orders_archived AS
SELECT FROM orders; <=== this is sub query in this context
2)
truncate orders_archived table
3)
INSERT INTO orders_archived
SELECT <== sub query
FROM orders
WHERE order_date < '2019-01-01';
Updating a single row
UPDATE invoices
SET payment_total = 10, payment_date = '2019-03-01'
WHERE invoice_id = 1;
UPDATE invoices
SET
payment_total = invoice_total * 0.5,
payment_date = due_date
WHERE invoice_id = 3;
Updating multiple rows
UPDATE invoices
SET
payment_total = invoice_total * 0.5,
payment_date = due_date
WHERE invoice_id IN (3,4);
Using subqueries in UPDATEs
UPDATE invoices
SET
payment_total = invoice_total * 0.5,
payment_date = due_date
WHERE client_id = <=== for single record
(SELECT client_id
FROM clients
WHERE name = 'Myworks')
UPDATE invoices
SET
payment_total = invoice_total * 0.5,
payment_date = due_date
WHERE client_id IN
(SELECT client_id
FROM clients
WHERE name = 'Myworks')
Delete row/s
1)
DELETE FROM invoices
WHERE invoice_id = 1
SELECT *
FROM clients
WHERE name = 'Myworks'
2)
DELETE FROM invoices
WHERE client_id = (
SELECT *
FROM clients
WHERE name = 'Myworks'
)
Restore db
save sql file in reserve?
CAST(expr AS type [ARRAY])
CAST(timestamp_value AT TIME ZONE timezone_specifier AS DATETIME[(precision)])
The following are the syntax of CAST() function in MySQL:
CAST(expression AS datatype);
TIP
- order of each clause matters for return value from each query.
- line breaks, white spaces, and tabs are ignored for sql commands.
- Specificity in sql commands is crucial, as it helps traffic for db server and network.
Challenge
- SELECT
name,
unit_price,
(unit_price * 1.1) AS new_price
FROM products;
- 이미지 필요
- SELECT *
WHERE order_date = '2019'
FROM order;
