/usr/local/lib/python3.11/site-packages/ <-- site-packages (패키지 설치 위치)
└── pandas/ <-- 패키지
├── init.py <-- 패키지 초기화 파일
└── core/ <-- 서브패키지
├── init.py
└── series.py <-- 모듈 (.py 파일)
└── class Series: <-- 클래스
| 용어 | 예시 | 설명 |
|---|---|---|
| 프로젝트 루트 | /home/user/my_project/ | 파이썬 실행 기준점 (sys.path에 포함) |
| 패키지 | pandas/ | __init__.py 파일을 가진 폴더 |
| 서브패키지 | core/ | 패키지 내부의 또 다른 패키지 |
| 모듈 | series.py | 실제 .py 파일 |
| 클래스 | Series | 모듈 안에 정의된 클래스 |
| 함수 | def my_func(): | 모듈이나 클래스 안에 정의 가능 |
타입: <class 'pandas.core.series.Series'>
패키지 서브패키지 모듈 클래스 순
데이터 타입 확인 dtypes
print(df.dtypes)컬럼명 변경/ 전체/ 데이터프레임.columns=[바꿀 컬럼명]
컬럼명 변경
df.columns = ['이름', '나이', '도시', '연봉']
print("변경된 컬럼명:")
print(df.columns)
#변경된 컬럼명:
Index(['이름', '나이', '도시', '연봉'], dtype='object')
🧨DataFrame.columns = [...] 할 때, 컬럼 개수가 안 맞으면 에러가 발생!특정 컬럼만 변경
df.rename(columns={'연봉':'월급'},
df.rename(columns={'연봉': '월급'}, inplace=True)
print("일부 컬럼명 변경:")
print(df.columns.tolist())연봉 컬럼을 월급 컬럽으로 바꾸는 거임. ,inplace=True는 원본을 바꾸겠다는 의미. 디폴트가 False니까 원본 아니고 따로 저장하고 싶으면 할당하면 됨.
파일 불러오기
df=pd.read_csv("/content/drive/MyDrive/PYTHON/tips_data.csv")
판다스 패키치 안의 read_csv 라이브러리로 csv파일 열기
경로는 구글 드라이브 연동해서 복사read_csv의 옵션
df = pd.read_csv('data.csv',
encoding='utf-8',# 한글 인코딩
index_col=0,# 첫 번째 컬럼을 인덱스로
header=0,# 첫 번째 행을 컬럼명으로
sep=',',# 구분자 지정
na_values=['N/A', ''])# 결측치로 처리할 값들Excel 파일 읽기
df = pd.read_excel('파일경로/파일명.xlsx')라는데 xlsx 파일은 못 읽더라. openpyxl 다운로드 해야함 '!pip install openpyxl'
df2 = pd.read_excel("/content/drive/MyDrive/PYTHON/tips_data.xlsx", engine='openpyxl')sheet가 여러 개일 때는
df = pd.read_excel('파일명.xlsx', sheet_name='Sheet1')
실제 데이터로 학습하기(url도 읽을 수 있는 파이썬)
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)크기 보기 shape
titanic.shape(891, 12) 891은 row 12는 column
.
.
.
상단 기준으로 빼오기 .head()
칸 비워두면 기본 5칸만 가져오고 숫자 넣으면 그만큼 가져옴
titanic.head()하단 기준으로 빼오기 .tail() 동작방식 동일
titanic.tail()파일 형식 전부 뽑기 .info()
titanic.info()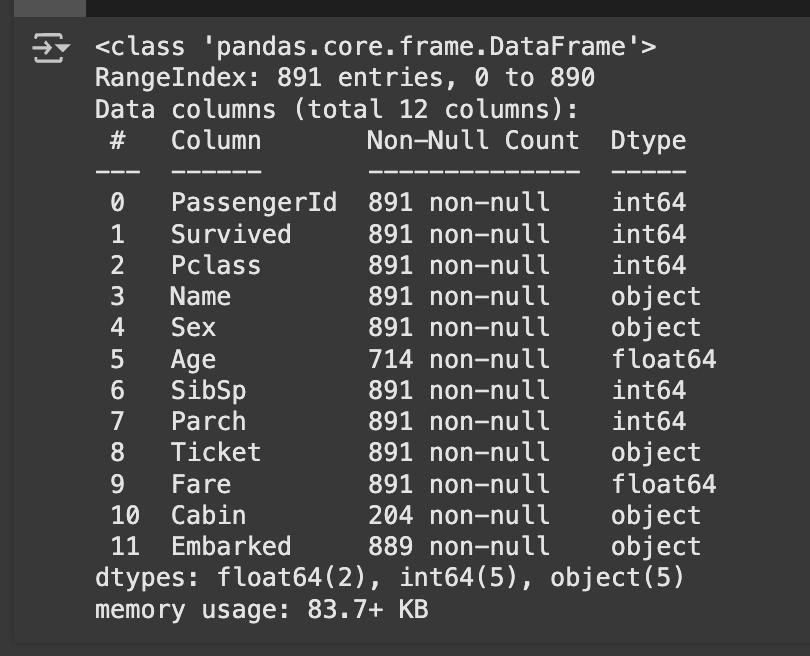
- 총 행 수와 컬럼 수 : 891행 12칼럼
- 각 컬럼의 데이터 타입: int64, object, float 64
- 결측치(null) 개수: Non null
- 메모리 사용량: 83.7kb
숫자형 데이터 기본 통계 보기
describe/뭐 어디 응용하는 함수는 아니고 그냥 대충 보는 거임. 소숫점 못 줄임
titanic.describe()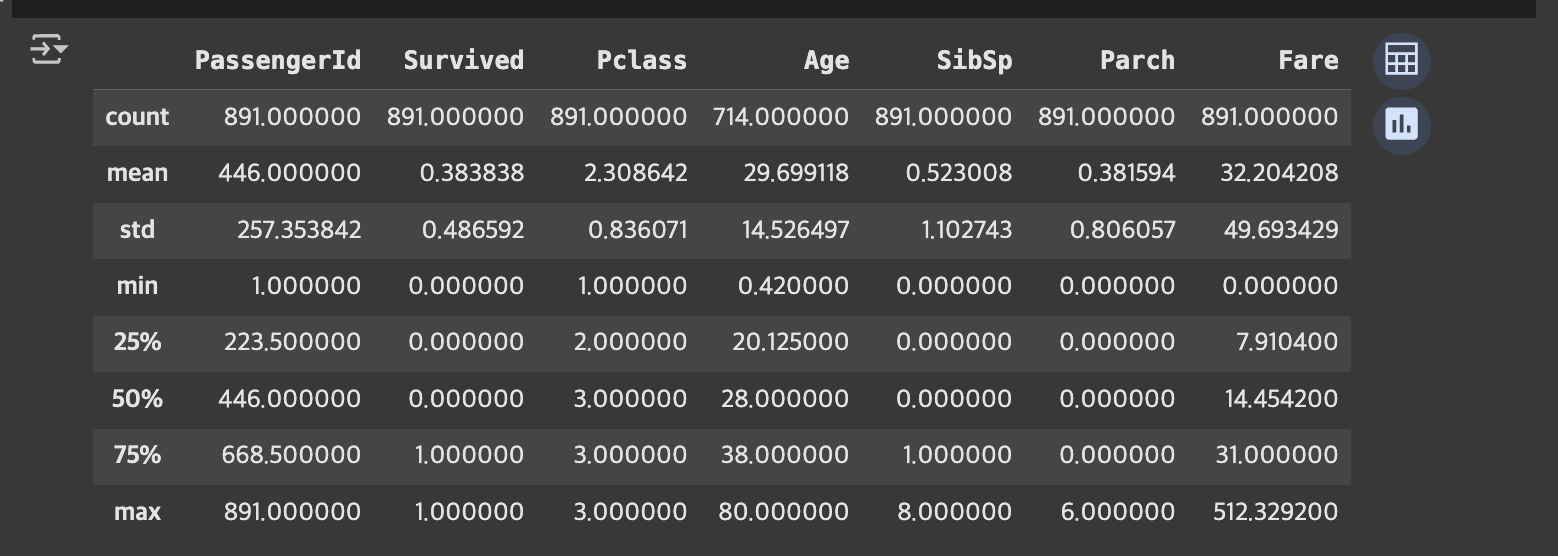
단순히 정보만 보는 거면 속성/동작하는 거면 메서드
메서드 모아보기
| 분류 | 메서드 | 설명 | 예시 |
|---|---|---|---|
| 조회 | head() | 상위 5개 행 반환 | df.head() |
| 조회 | tail() | 하위 5개 행 반환 | df.tail() |
| 조회 | info() | 컬럼별 타입 및 결측치 정보 | df.info() |
| 조회 | describe() | 수치형 요약 통계 | df.describe() |
| 조회 | shape | 행과 열 수 반환 | df.shape → (10, 5) |
| 선택 | loc[] | 인덱스 이름 기준 선택 | df.loc['index1'] |
| 선택 | iloc[] | 위치 기준 선택 | df.iloc[0, 1] |
| 선택 | query() | 조건문으로 행 필터 | df.query("age > 30") |
| 선택 | isin() | 특정 값 포함 여부 | df[df['col'].isin([1, 2])] |
| 선택 | between() | 범위 조건 | df[df['age'].between(20, 30)] |
| 조작 | rename() | 컬럼명 변경 | df.rename(columns={'old':'new'}) |
| 조작 | drop() | 행 또는 열 제거 | df.drop('컬럼명', axis=1) |
| 조작 | set_index() | 컬럼을 인덱스로 설정 | df.set_index('이름') |
| 조작 | reset_index() | 인덱스 초기화 | df.reset_index() |
| 조작 | apply() | 함수 적용 | df['리뷰'].apply(lambda x: x+1) |
| 정렬 | sort_values() | 컬럼 기준 정렬 | df.sort_values('age') |
| 정렬 | sort_index() | 인덱스 기준 정렬 | df.sort_index() |
| 결합 | concat() | 데이터프레임 연결 | pd.concat([df1, df2]) |
| 결합 | merge() | 조인 방식으로 병합 | pd.merge(df1, df2, on='key') |
| 결합 | join() | 인덱스를 기준으로 결합 | df1.join(df2) |
| 결측치 | isna() | 결측치 여부 확인 | df.isna() |
| 결측치 | fillna() | 결측치 채우기 | df.fillna(0) |
| 결측치 | dropna() | 결측치 제거 | df.dropna() |
| 결측치 | notna() | 결측치가 아닌 값 | df[df['col'].notna()] |
| 결측치 | ffill() | 결측치를 앞값으로 채움 | df.fillna(method='ffill') |
| 결측치 | bfill() | 결측치를 뒷값으로 채움 | df.fillna(method='bfill') |
| 통계 | mean() | 평균 | df['age'].mean() |
| 통계 | sum() | 합계 | df['매출'].sum() |
| 통계 | std() | 표준편차 | df['나이'].std() |
| 통계 | median() | 중앙값 | df['연봉'].median() |
| 통계 | corr() | 상관계수 | df.corr() |
| 통계 | count() | 값 개수 | df.count() |
| 통계 | value_counts() | 고유값 개수 세기 | df['성별'].value_counts() |
| 변형 | pivot() | 행/열 구조 변경 | df.pivot(index='이름', columns='과목', values='점수') |
| 변형 | pivot_table() | 그룹별 요약 + 피벗 | df.pivot_table(index='반', values='성적', aggfunc='mean') |
| 변형 | melt() | wide → long 형태로 변형 | pd.melt(df, id_vars='이름') |
| 변형 | stack() | 컬럼 → 인덱스 | df.stack() |
| 변형 | unstack() | 인덱스 → 컬럼 | df.unstack() |
| 시계열 | resample() | 시간 간격 재조정 | df.resample('M').mean() |
| 시계열 | asfreq() | 빈도 변경 | df.asfreq('D') |
| 시계열 | rolling() | 이동 평균 등 계산 | df['매출'].rolling(window=3).mean() |
| 시계열 | dt 접근자 | 날짜 정보 추출 | df['날짜'].dt.year |
데이터 선택하기 열(column) 선택
- 단일 컬럼 선택:(대소문자 구분 좀 잘하자)/컬럼 하나 선택했으니 시리즈임
names = titanic['Name']
names.head()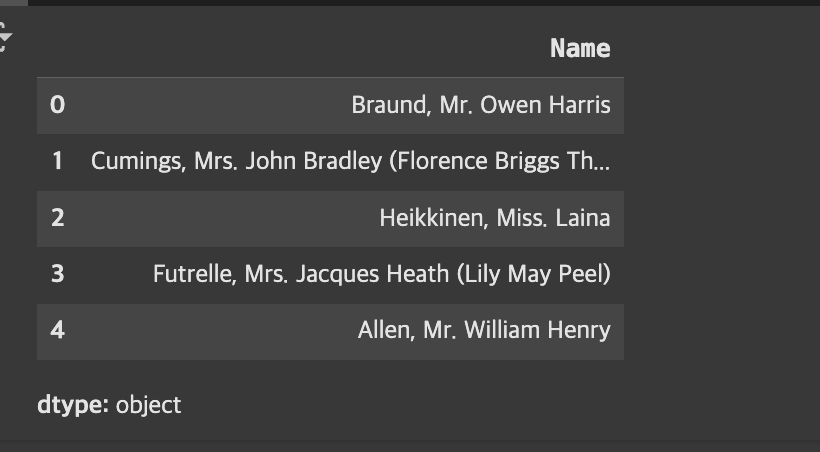
-여러 칼럼 선택:(Dataframe)이 됨. 괄호 두 번 쓰기!!!
bs_info=titanic[['Name','Age','Sex']]
bs_info.head()데이터 선택하기 행(row) 선택
loc: 라벨(인덱스 이름) 기반 한 행 선택
titanic.loc[0]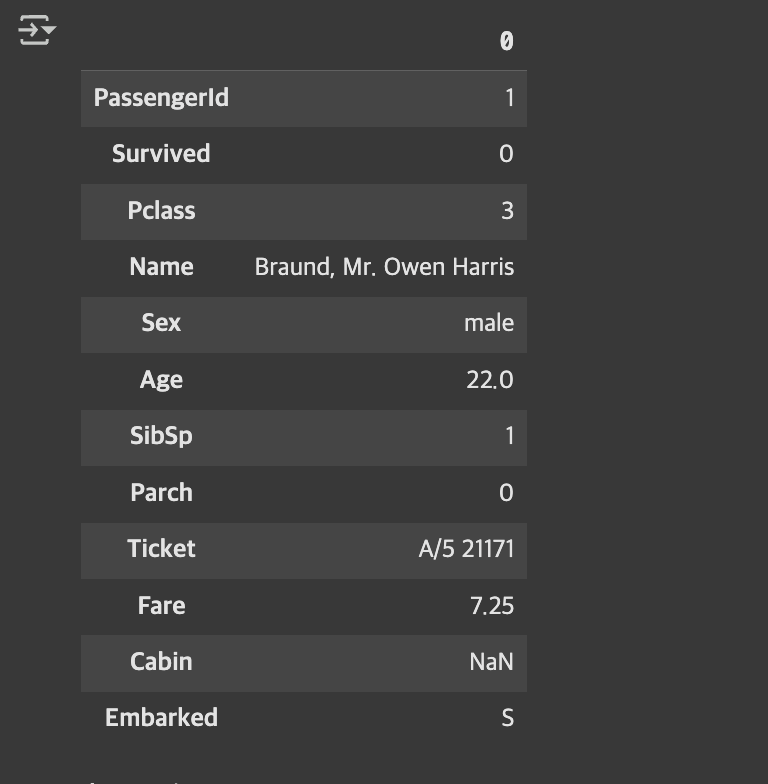
loc 기반 여러 행 선택
titanic.loc[0:4, ['Name', 'Age', 'Sex']]
0~4행, 출력할 컬럼 내용
iloc 기반 한 행 선택
titanic.iloc[0]iloc 기반 여러행 선택
titanic.iloc[0:5, [3, 4, 5]]
조건부 데이터 선택(where 같은 거임)
# 여성 승객의 수
females=titanic[titanic['Sex']=='female']
len(females)복합 조건부 데이터 선택
#30세 미만인 여성 출력
youngfemales=titanic[(titanic['Sex']=='female') & (titanic['Age']<30)]
youngfemales조건이 많아지면 변수 선언을 해보자/조건 결과만 저장 되니(bulean형태)실제 행 추출까지 이뤄줘야 함
female = titanic['Sex'] == 'female'
age_30 = titanic['Age'] < 30
young_females = titanic[female & age_30]여러값 중 하나와 일치
1등석 또는 2등석 승객
first_second=titanic[titanic['Pclass'].isin([1, 2])]
len(first_second)
결측치가 아닌 데이터 선택(notna/있는 값은 isna)
age_not_null=titanic[titanic['Age'].notna()]
len(age_not_null)
인덱스 번호 초기화 하기
(보통 조건 걸면 원본 인덱스 따라서 1,2,4,8 이딴식으로 나오는데 0부터 다시 정렬 하는 거임)
두 값의 인덱스 번호를 비교 해보셈
female = titanic['Sex'] == 'female'
age_30 = titanic['Age'] < 30
young_females = titanic[female & age_30]
young_femalesyoung_females_reset = young_females.reset_index()
young_females_reset칼럼 지정해서 인덱스로 변경해주기(특정 컬럼을 인덱스로)
df_indexed=titanic.set_index('Name')이러면 인덱스가 name값으로 변경 됨. 다만 name은 프라이머리키가 보통 아니기 때문에 지정하면 안됨. 예시임.
새로운 칼럼 생성
# 가족 크기 = 형제자매 + 부모/자녀 + 본인(1)
titanic['Family_Size'] = titanic['SibSp'] + titanic['Parch'] + 1
titanic[['Name', 'SibSp', 'Parch', 'Family_Size']].head()np.where()을 활용한 보다 쉬운 조건부 칼럼 생성
import numpy as np #numpy 설치
titanic['Is_Adult']=np.where(titanic['Age']>=18, 'Adult','Child')
titanic['Is_Adult'].value_counts()연습 문제[1등석 성인 승객을 구해보자]
titanic['Passenger_Category'] = np.where(
(titanic['Pclass'] == 1) & (titanic['Age'] >= 18),
'First_Class_Adult',
'Other'
)
titanic['Passenger_Category'].value_counts()데이터를 정렬해보자|sort_values.(column)
# 나이순으로 정렬
age_sorted = titanic.sort_values('Age')
print("나이순 정렬 (어린 순):")
print(age_sorted[['Name', 'Age']].head())
내림차순 정렬 ascending=False
# 나이 내림차순 정렬
age_desc = titanic.sort_values('Age', ascending=False)
print("나이순 정렬 (나이 많은 순):")
print(age_desc[['Name', 'Age']].head())여러 조건 기준 정렬 [column,column], ascending[bulean, bulean]
multi_sorted = titanic.sort_values(['Pclass', 'Age'], ascending=[True, False])
print("등급순, 나이 내림차순:")
print(multi_sorted[['Name', 'Pclass', 'Age']].head())