
오늘도 산뜻하게 임포트하고 시작하자
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt타이타닉도 쓸 것이다.
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)⛔️고급 결측치 처리 기법
Forward Fill(ffill)
.ffill() |이전 값으로 결측치를 채움
만약 데이터가 아래와 같다고 하자data = {'score': [85, None, None, 70, None]}
df = pd.DataFrame(data)이걸 `df.ffill()` 메써드를 쓰면 아래와 같이 나온다.| index | score |
|---|---|
| 0 | 85 |
| 1 | 85 |
| 2 | 85 |
| 3 | 70 |
| 4 | 70 |
앞에 나온 값으로 None값이 채워진다.Backward Fill(bfill)
.bfill() |다음 값으로 결측치를 채움
동일한 데이터에 bfill 메써드를 적용 해보자.df.bfill()| index | score |
|---|---|
| 0 | 85 |
| 1 | 70 |
| 2 | 70 |
| 3 | 70 |
| 4 | NaN |
뒤에 나온 값으로 결측값이 채워진다.타이타닉에도 적용하자.
titanic_ffilll=titanic.copy()원본 데이터는 계속 써야 하니까 카피를 하자.
before_ffill=titanic_ffill['Age'].isnull().sum()비교를 위해 채우기 전 값도 시리즈로 빼놓자.
titanic_ffill['Age_ffill'] =
titanic_ffill['Age'].ffill()age_ffill이라는 컬럼을 새로 만들고 그 내용은 age 컬럼의 결측치를 ffill() 메써드로 채운다.
after_ffill=titanic_ffill['Age_ffil'].isnull().sum()fill한 뒤 결측값이 있는지 확인 해보자.
print(f'포와드 필 전의 결측값은 {beforeffill}개')
print(f'포와드 필 후의 결측값은 {after_ffill}개')
Forward Fill 사용 시기:
- 시계열 데이터에서 값이 서서히 변하는 경우
- 설문조사에서 "이전 답변과 동일" 의미인 경우
선형 보간법(Interpolation).inpterpolate()
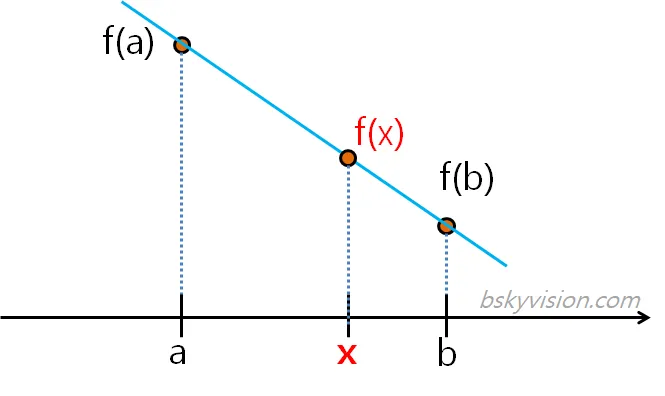
보=보강하다 간=사이를
선형의 그래프의 사이를 보강하는 것기본 값은 평균을 내서 보강해준다. 앞뒤 값의 평균으로 채우므로 급격한 변화를 피할 수 있습니다. 연속적인 변화가 예상되는 데이터에 적합하다. 타이타닉에는 보간에 알맞은 연속적인 데이터가 없음.
df = pd.DataFrame({'value': [1, np.nan, np.nan, 4]})
print(df['value'].interpolate())0 1.0
1 2.0 ← (1 + 4) 사이 중간값
2 3.0
3 4.0아래와 같은 옵션을 가지고 있는데 한 번 읽어보면 좋다.
| 옵션 | 설명 |
|---|---|
method='linear' | (기본값) 숫자 기준으로 직선 보간 |
method='time' | DatetimeIndex가 있을 때 시간 기준 보간 |
method='index' | 인덱스 값 기준으로 보간 |
method='polynomial', order=2 | 다항식으로 보간 (2차, 3차 등) |
limit= | 최대 몇 개의 NaN만 채울지 제한 |
limit_direction='forward' | 앞에서부터만 채우기 (또는 'backward', 'both') |
아쉬우니까 시간 보간 예시 하나만 들어주자.
df = pd.DataFrame({'value': [1, np.nan, 3]},
index=pd.to_datetime(['2020-01-01', '2020-01-02', '2020-01-04']))
df['value'].interpolate(method='time')데이터 타입 변환 및 날짜 처리
📌 자주 발생하는 타입 문제들
- CSV 파일에서 숫자가 문자열로 읽힌 경우
- 범주형 데이터가 문자열로 저장된 경우
- Yes/No, True/False가 문자열로 저장된 경우
- 순서가 있는 범주형 데이터 처리📍 실무에서 자주 마주치는 더러운 데이터 시뮬레이션
messy_data = {
'customer_id': ['C001', 'C002', 'C003', 'C004', 'C005'],
'age': ['25', '34', 'N/A', '42', '28'], # 문자열로 저장된 숫자 + 결측치
'income': ['50,000', '75,500', '42,300', '91,200', '38,750'], # 콤마가 있는 숫자
'is_premium': ['Yes', 'No', 'Yes', 'Yes', 'No'], # 문자열로 저장된 불리언
'membership_level': ['Gold', 'Silver', 'Gold', 'Platinum', 'Bronze'], # 범주형
'score': ['85.5', '92.0', '78.5', '89.2', '76.8'] # 문자열로 저장된 실수
}
df= pd.dataframe(messy_data)df=pd.dataframe(data) 기억
📊데이터타입 확인 .info()/.dtypes
df.dtypes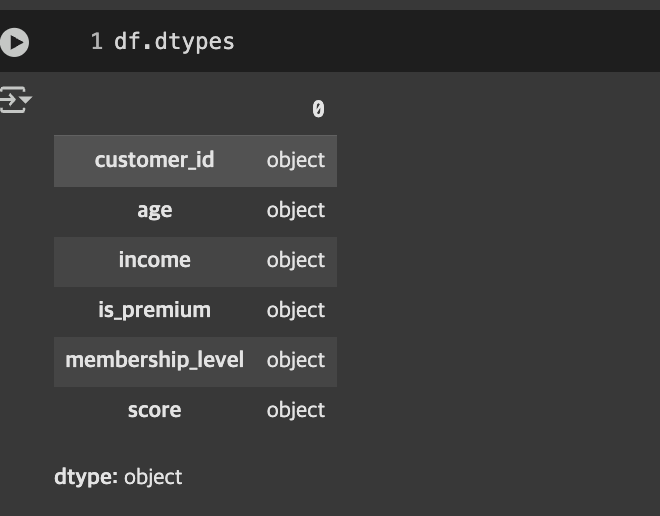
df.info()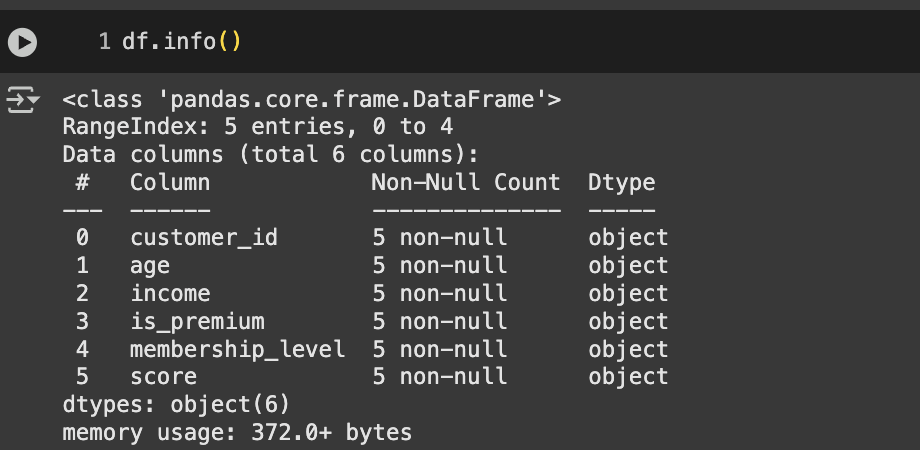
모든 값이 특정한 값이 없는 object인 것 확인 가능.
데이터 본격변환 .astype()
연습용 데이터 생성# Series()는 앞글자 대문자 유념.
clean_numbers = pd.Series(['10','20','30','40','50'])
clean_numbers.info()
#전부 object인 것 확인 가능astype(int)
#astype()으로 문자열 정수로 변환
clean_numbers_int=clean_numbers.astype(int)
clean_numbers_int.dtype결과값이 int64인 것 확인 가능
흐지만!!!!!! 결측치 같은게 있는 경우!!!
astype()은 오류를 내면서 폭사한다!!!
결측치가 있는 데이터 변환 pd.to_numeric()
age컬럼에는 NaN이 섞여있다.
df['age'].dtype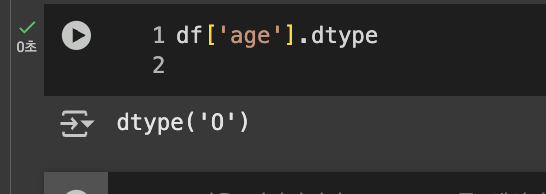
'o'=object라는 뜻어차피 안 될 거지만, astype(int)를 시도해보자
df['age_trans_type']=df['age'].astype(int)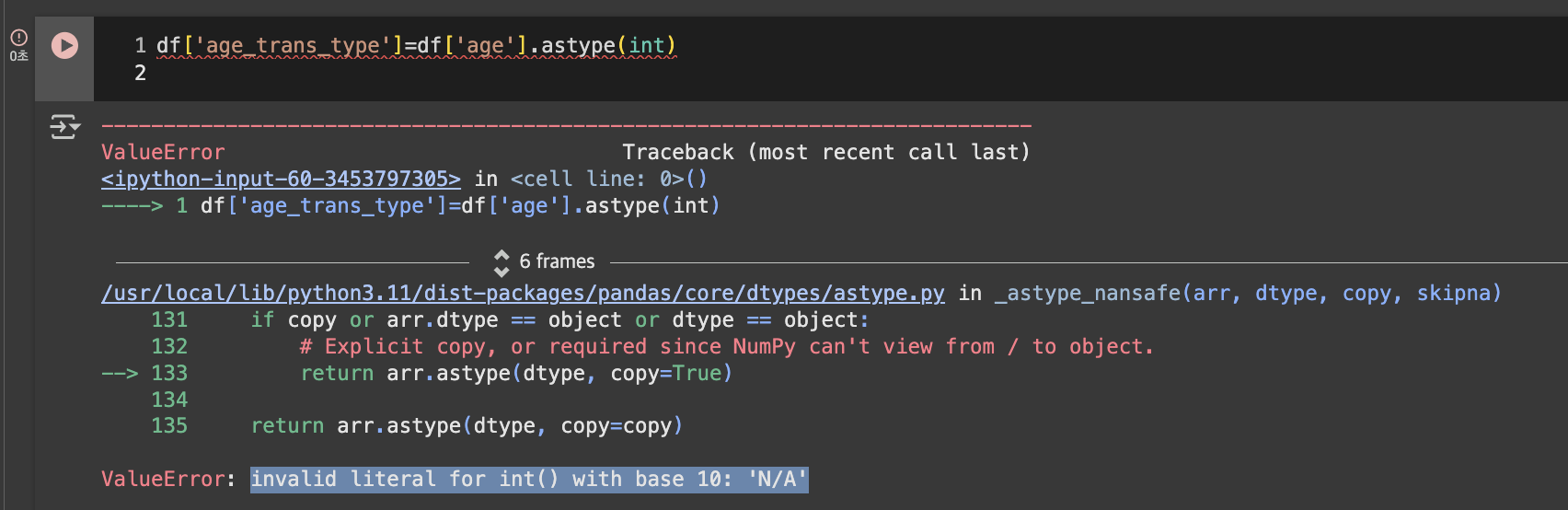
invalid literal for int() with base 10: 'N/A'
대충 파이썬은 유도리가 없어서 결측값을 int로 바꿀 수 없다는 뜻이다.pd.to_numeric() | 숫자형(int 또는 float)으로 변환해주는 함수
일반적인 기능은 대동소이하나 error 발생 시 기본 값을 설정 할 수 있다!!
얘는 메서드가 아니고 함수다. 사용법 주의
pd.to_numeric(바꿀 컬럼, errors= 대응 할 값)
옵션값 의미 'raise'(기본값)에러 발생 시 멈춤 'coerce'변환 안 되는 값은 NaN으로 바꿈'ignore'변환 안 하고 원본 그대로 둠
ex)
df['age_trans_type']=pd.to_numeric(df['age'],errors='coerce')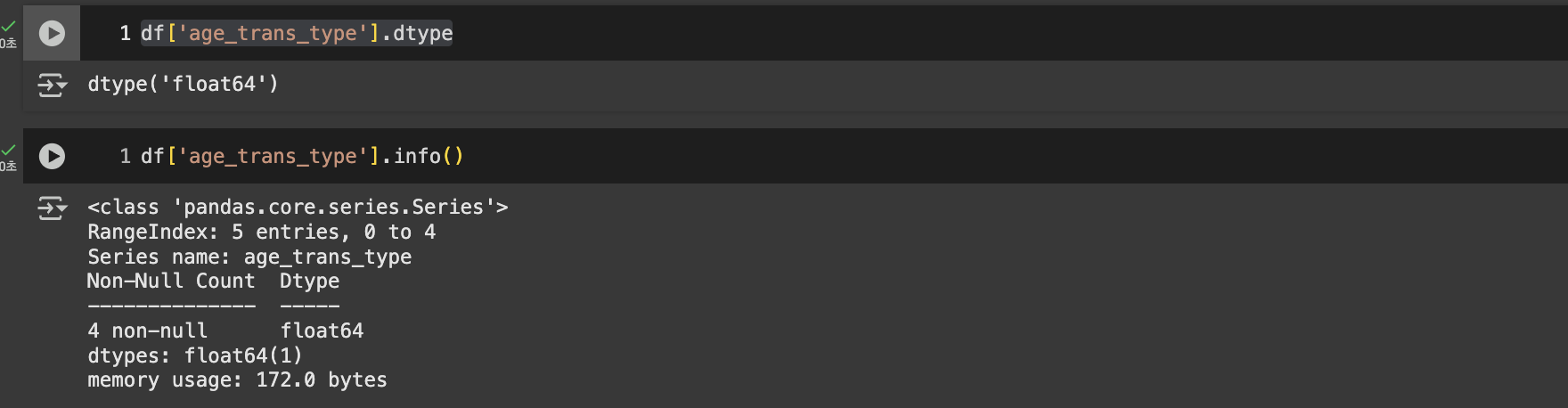
정상 적용 된 것을 확인 할 수 있다.
❜콤마 단위 처리 방법 .str.replace()
인컴 컬럼 다시 확인 하자.
df['income_clean'] = df['income'].str.replace(',','').astype(float)
#object type인 Income을 str로 변환한 뒤
#replace메서드로',를 ''으로 변경. 그 뒤에 astype(float)로 전체를 float로 바꾼다.series의 Replace는 값이 정확이 ,이었을 때만 바꿈
df.str.replace(‘,’,’’)는 값이 안에 포함 되어있으면 바꿈print("\n수입 변환 결과:")
print(df[['income', 'income_clean']])
[]=1차원 series [[]]2차원 dataframe소수점 변환
score 데이터 다시 확인
df['score_clean']=df['score'].astype(float)
print(df[['score','score_clean']])불리언 타입 변환
yes/no >> True/False로
df['is_premium_bool']=df['is_premium'].map({'Yes':True, 'No':False})
print(df[['is_premium','is_premium_bool']])불리언을... 멋대로 적은 경우에는 이걸로 밀어 버리자...
어휴 쓰기 귀찮아. 하지만 손으로 써야지 실력이 늘겠죠 민규 어린이???
boolean_variations {'Y':True, 'N':False, 'yes':True, 'no':False, 'TRUE': True, 'FALSE':False, '1':True, '0':False}
mixed_boolean = pd.Series(['Y', 'N', 'yes', 'no', 'TRUE', 'FALSE', '1', '0'])
cleaned_boolean=mixed_boolean.map(boolean_variations)
result_df=pd.DataFrame({'원본':mixed_boolean,'변환후':cleaned_boolean})
싫다면?
왜 11시 30분인데 안 나가시는 거죠.
