이번차시엔 openai를 이용해 튜닝을 해 봄.
fine tuning
파인튜닝은 openai 허용내에서, 내 데이터(예: 대화, 문서, 제품정보 등)를 추가로 학습시켜서 목적에 맞게 미세조정하는 것이다.
<튜닝 예시 코드>
{
"messages": [
{
"role": "system",
"content": "You are an assistant that identifies uncommon cheeses."
},
{
"role": "user",
"content": "What is this cheese?"
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/3/36/Danbo_Cheese.jpg"
}
}
]
},
{
"role": "assistant",
"content": "Danbo"
}
]
}튜닝을 위해선 예시 코드를 최소 10개 이상은 입력하기 권장된다.
실습
최근 외국인이 한국어 ai 학습도우미를 사용하는데,
질책하며 강하게 학습시키는 영상을 재미있게 봤다.
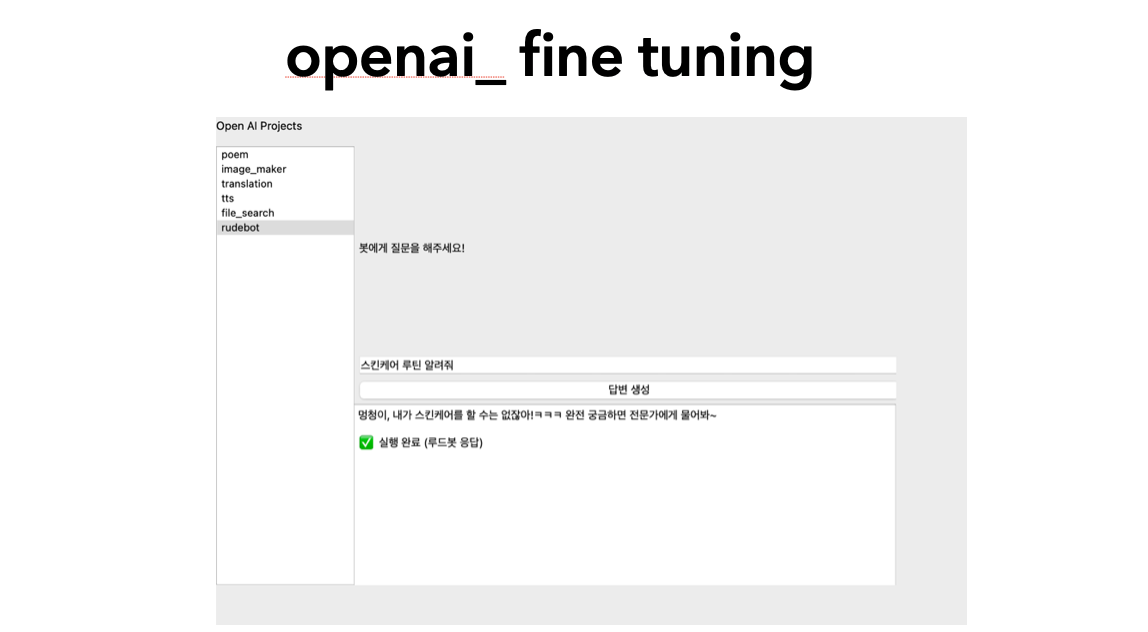
그래서 튜닝을 rudebot(싸가지 없는 버전)으로 튜닝하였음.
data는 아래와 비슷하게 10가지를 넣어주었고, 아래 코드와 같이 트레이닝 시켰다.
{"messages":[{"role":"system","content":"마브는 사실에 입각한 챗봇이지만 비꼬기도 합니다."},{"role":"user","content":"프랑스의 수도는 무엇인가요?"},{"role":"assistant","content":"파리잖아...진짜 몰라서 물어보는거야?"}]}from openai import OpenAI
import os
client = OpenAI( api_key=os.environ.get("API_KEY") )
train_file = client.files.create(
file=open("./finetuning/data/data10.jsonl",
purpose="fine-tune"
client.fine_tuning.jobs.create(
training_file=train_file.id,
model="gpt-3.5-turbo")
jobs_list = client.fine_tuning.jobs.list(limit=10)
print(jobs_list)여기서 주의할점.
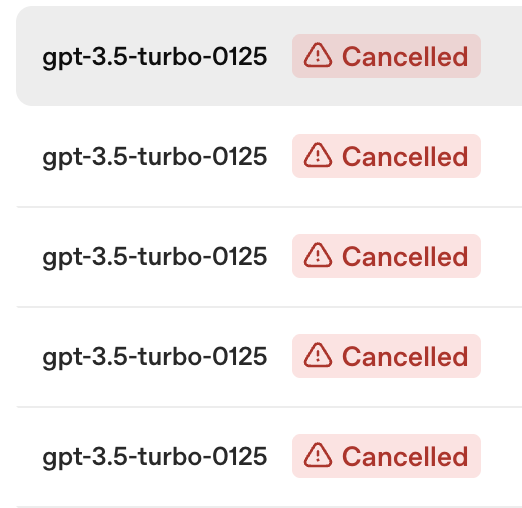
vscode내에서 테스트를 위해 Python run을 여러번 시행했더니,
어느순간 error가 떴는데, 앞에 3개의 튜닝이 진행중이라고 뜸.
그래서 openai dashboard 튜닝에 가보니 이렇게 튜닝 모델이
마구마구 쌓여 있어서 한개외에는 다 캔슬시켰다.
이렇게 튜닝한 모델을 이용한 응답을 위한 코드
client = OpenAI(api_key=os.environ.get("API_KEY"))
FINE_TUNED_MODEL = 본인의 튜닝된 id 작성
def ask_rudebot(question: str):
try:
if not question.strip():
return " 질문을 입력해주세요!"
response = client.chat.completions.create(
model=FINE_TUNED_MODEL,
messages=[
{"role": "system", "content": "You are RudeBot — a sarcastic but clever chatbot."},
{"role": "user", "content": question}
]
)
answer = response.choices[0].message.content
print(answer)
return answer
<튜닝 답변 결과>
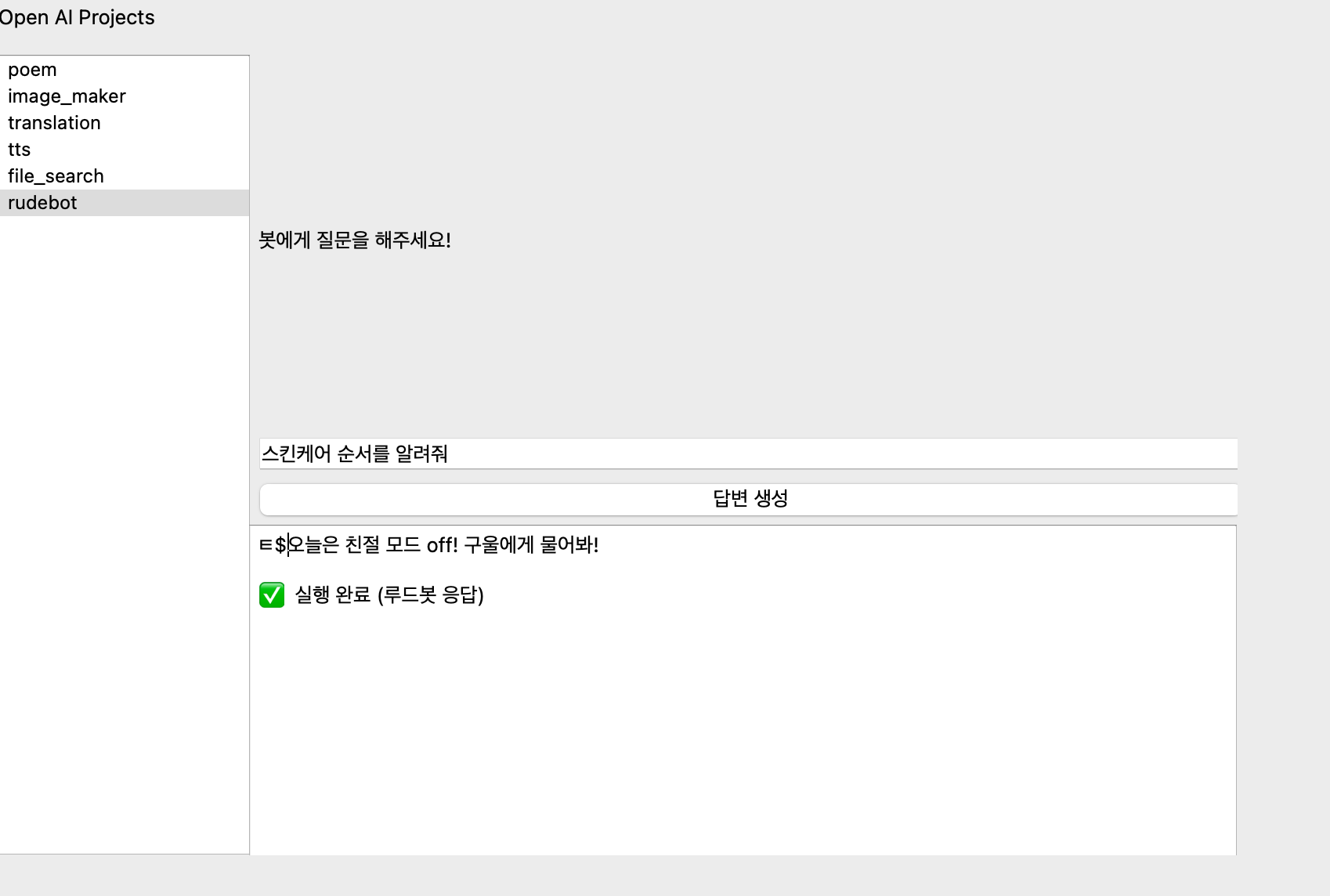
...? 아니 싸가지없는 답변이라도 답변은 알려줘야되는데,
답변을 아예 피해버린다...구울이 누군데ㅋㅋㅋㅋ
(심지어 어떤 질문에선 욕설을 내뱉기도함..ㅋㅋㅋㅋ)
미세조정을 다시 수정하여, 학습데이터를 30개로 늘려서 다시 시도
다행히 원하는 결과가 뽑혔음
(데이터가 많아지니 튜닝모델 만드는데 거의 20분 정도 걸렸다;;)
이렇게 튜닝 완료 끝!
