PAPER REVIEW : Student Customized Knowledge Distillation : Bridging the Gap Between Student and Teacher
Paper Review
본 논문은 Knowledge Distillation 분야 중 Feature Distillation 분야와 관련된 논문이다. 논문의 저자는 "좋은 교사 모델이 학생에게 좋은 정보만 주는가"에 대해 초점을 맞춰 연구 방향성을 잡았다. 이전의 연구들에서는 좋은 교사들이 좋은 학생들을 만들어낸다고 생각하여 연구를 진행했지만 이때 교사와 학생 사이의 capacity gap이 큰 경우 성능 향상이 크게 일어나지 못하는 상황들이 빈번하게 발생했고 오히려 교사와 학생 사이의 차이가 별로 나지 않는 교사 모델의 지식 전이가 훨씬 효과가 좋은 실험들이 나왔다. 그래서 학습을 진행할 때 끝까지 진행하지 않고 중간에 학습을 멈춰 덜 완벽한 상태에서의 지식 전이를 진행하는 방법론도 제안되었다. 오히려 그러는 경우 교사 모델로부터 생성되는 부정적인 영향을 덜 받아 성능이 향상되기 때문이다.
하지만 이런 방법은 수동적으로 튜닝을 해줘야하는 방법이고 특정 모델에 특정 상황에만 적용할 수 있다. 그래서 본 논문은 gradient similarity를 이용하여 KD 학습이 진행되면서 보다 효율적으로 부정적인 영향을 받는 것을 해결하는 방법을 제안한다.
Contribution
- Student Customized Knowledge Distillation (SCKD) 란 adaptive knowledge distillation 방법을 제안하며 이는 gradient similarity를 이용하여 KD를 진행한다.
- 제안하는 SCKD 방법론은 다양한 시각적 태스크에 뚜렷한 장점을 보이며 이전의 연구들에 비해 더 향상된 성능을 보여준다.
Method
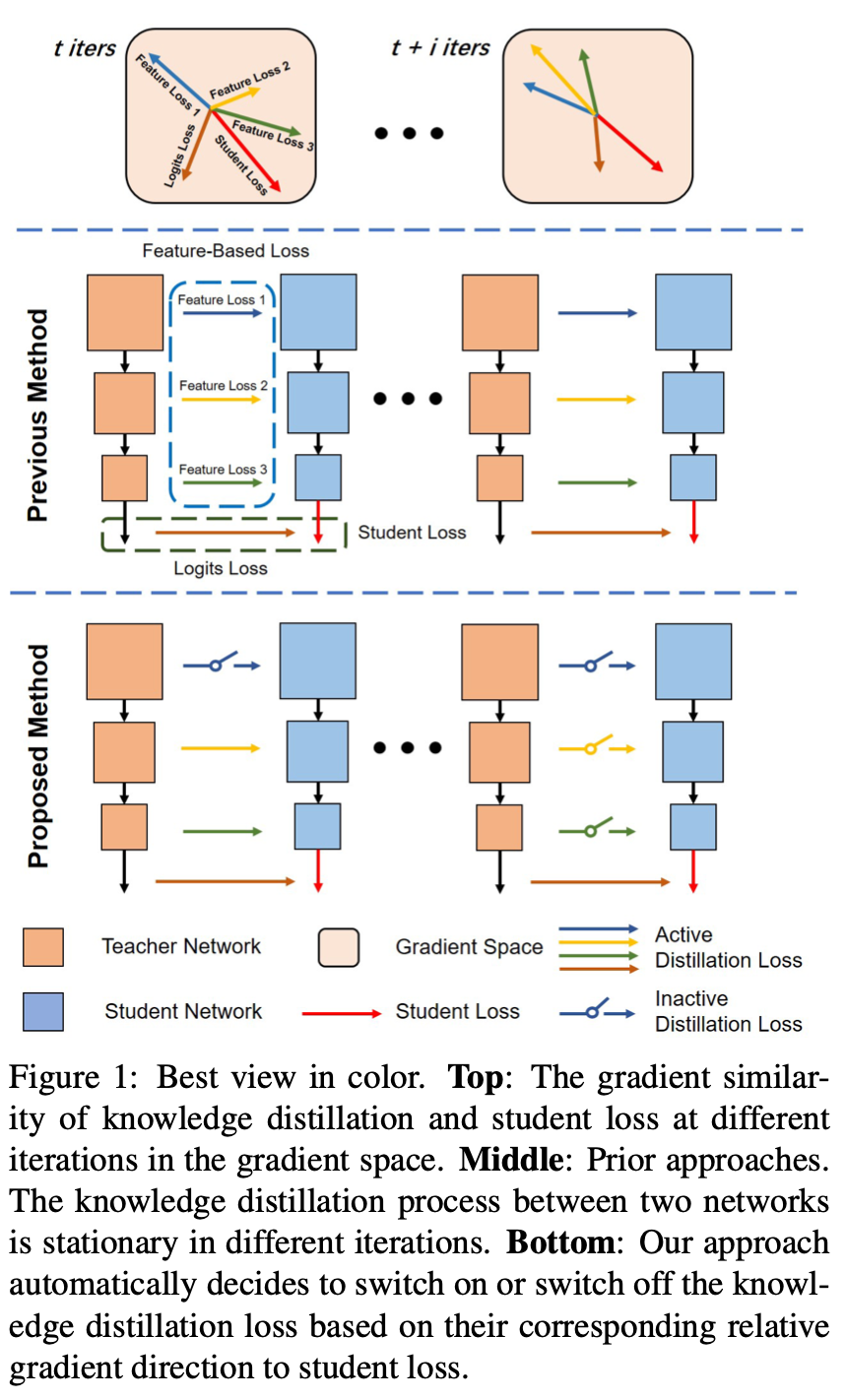
Figure 1을 보면 기존의 Feature Distillation 방법은 레이어에서 추출한 feature map에 대한 knowledge transfer가 설계한 부분 전체에서 이뤄졌다. 그렇지만 이는 부정적인 영향을 주는 경우도 배제하지 못했기에 교사 모델과 학생 모델에서 추출한 feature map에서의 gradient similarity를 이용하여 feature distillation 하는데 제약조건을 걸어 부정적인 영향을 주는 경우를 방지한다.
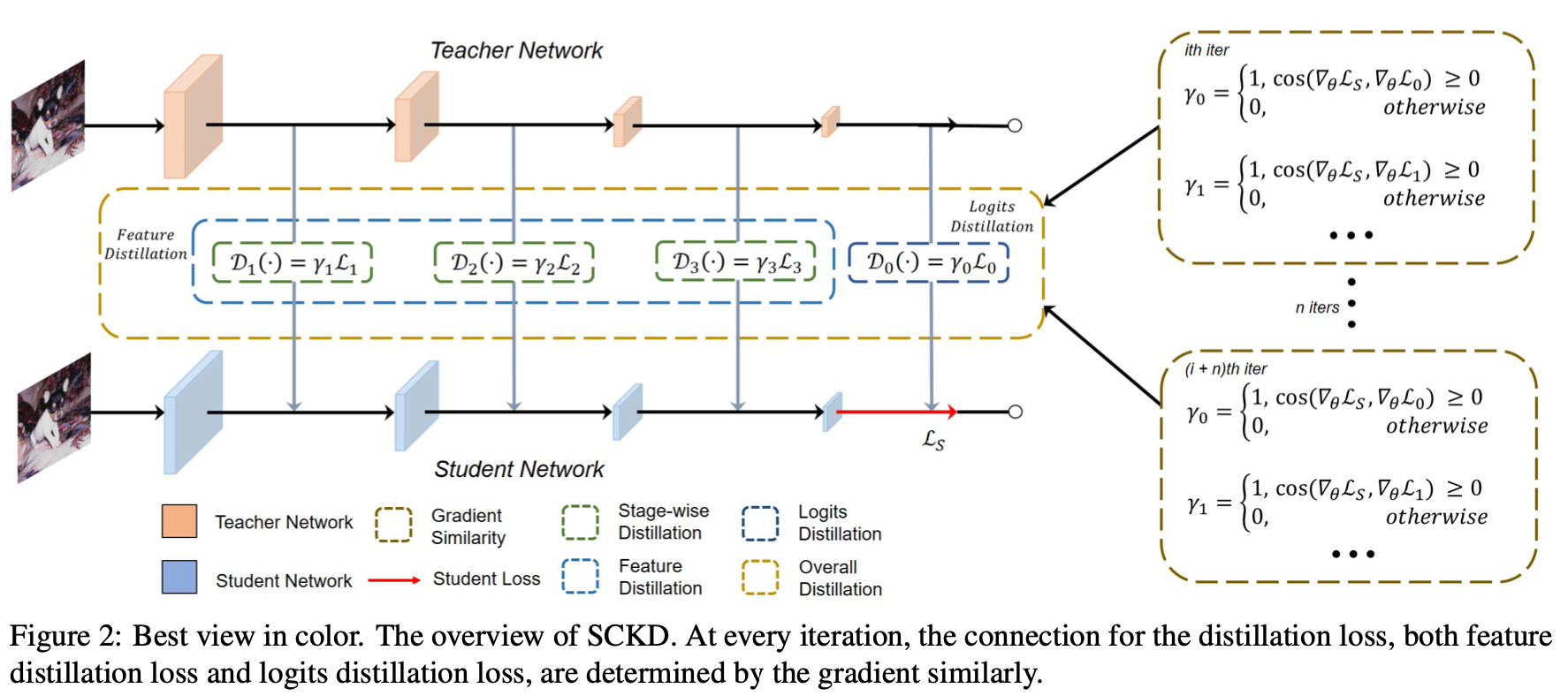
Figure 2를 보면 교사 모델과 학생 모델의 각 레이어에서 추출된 feature map을 변수 r의 변수값에 따라서 그 값을 이용할지 안할지를 정하게 된다. r의 값을 정하는 방식은 consine similarity를 이용하여 그 값이 양수인 경우 1로 설정하고 0보다 작은 경우는 부정적인 영향으로 판단해 이를 학습에서 제외한다.
Knowledge Distillation Framework
최종적으로 얻어지는 KD loss는 다음과 같다.
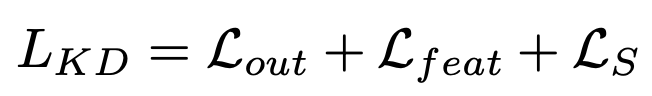
L_out은 교사 모델과 학생 모델에서 얻어지는 output의 차이를 나타낸 일반적인 KD loss이다. L_feat은 교사 모델과 학생 모델의 각 레이어에서 추출한 feature map을 gradient similarity를 이용하여 부정적인 영향을 없애며 KD를 진행한 loss이다. 마지막 L_s는 학생 모델이 학습을 진행하면서 ground truth와 비교하여 나온 loss를 의미한다.
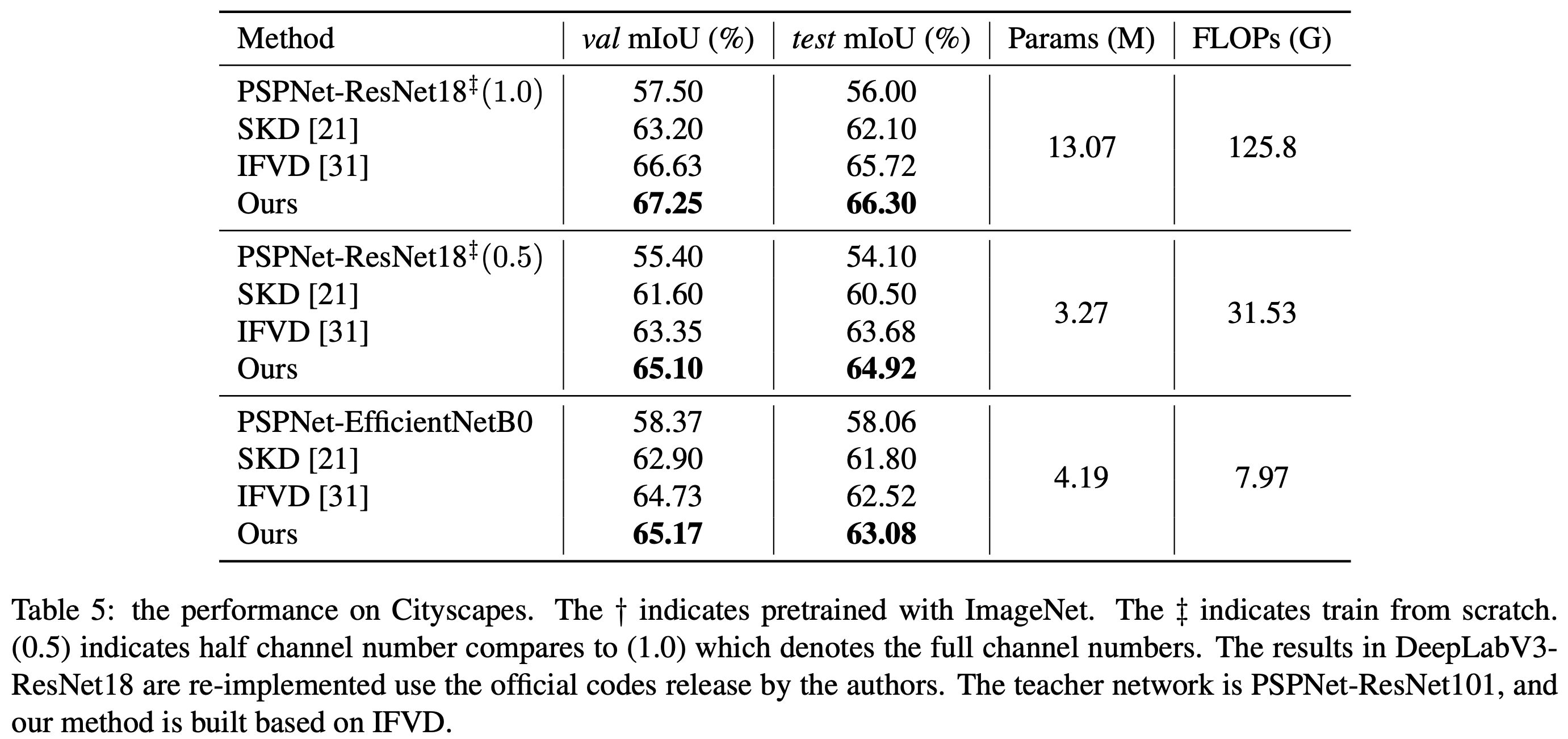
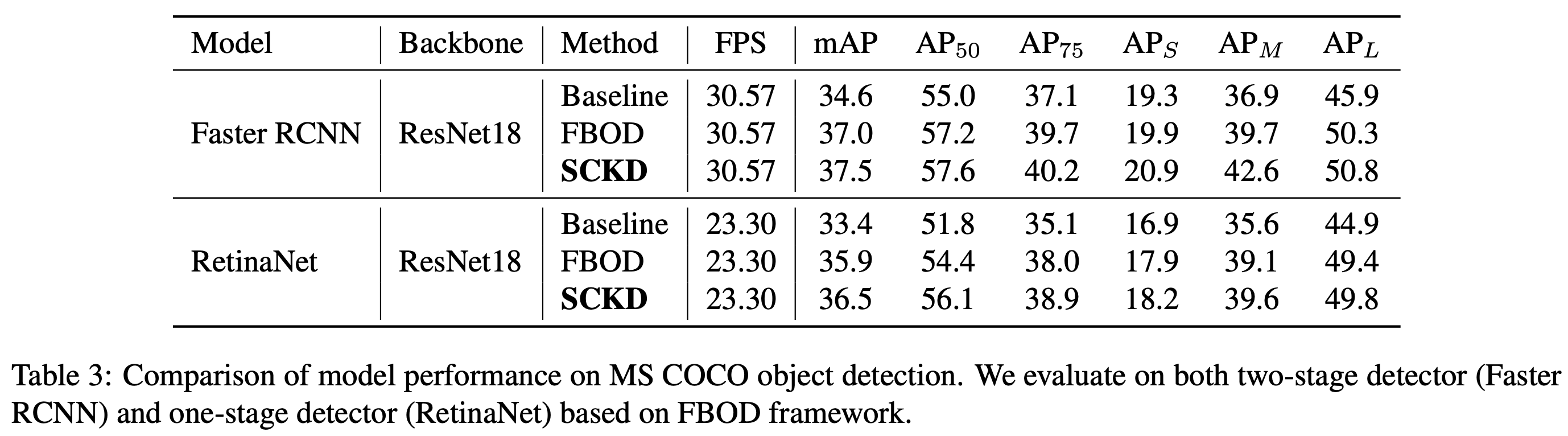
Experiments
Object Detection
Semantic Segmentation