
Queue (큐)
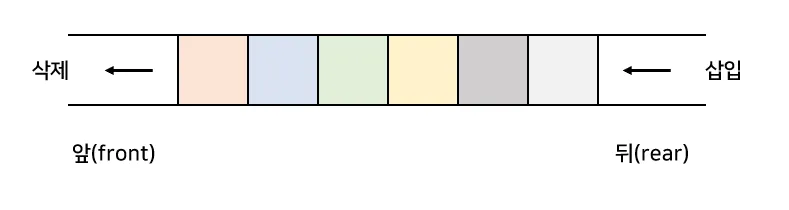
큐는 데이터를 먼저 넣은 것이 먼저 나오는(FIFO: First In, First Out) 방식의 자료구조.
줄을 서서 기다리는 상황과 유사하며, 가장 먼저 들어간 데이터가 가장 먼저 처리됨.
큐의 주요 연산 및 시간 복잡도
| 연산 | 설명 | 시간 복잡도 |
|---|---|---|
| enqueue | 데이터를 큐에 추가 | O(1) |
| dequeue | 큐에서 가장 앞의 데이터를 제거 | O(n) |
| front | 큐의 맨 앞 요소 확인 | O(1) |
| rear | 큐의 맨 끝 요소 확인 | O(1) |
| isEmpty | 큐가 비어 있는지 확인 | O(1) |
일반적인 리스트(List)를 사용하면 dequeue 연산이 O(n) (앞에서 제거하면 전체 이동) 발생.
이를 해결하기 위해 Deque(Double-ended Queue) 또는 링 버퍼를 활용.
큐의 구현 방법
1. 리스트를 이용한 큐 구현 (비효율적)
python
복사편집
queue = []
queue.append(1) # Enqueue
queue.append(2)
queue.append(3)
print(queue.pop(0)) # Dequeue, 1 출력
pop(0) 사용 시 O(n) 발생 → 비효율적
2. collections.deque를 이용한 큐 구현 (권장)
python
복사편집
from collections import deque
queue = deque()
queue.append(1)
queue.append(2)
queue.append(3)
print(queue.popleft()) # Dequeue, 1 출력
popleft() 사용 시 O(1) → 효율적
링 버퍼(Ring Buffer) - 고정 크기 큐
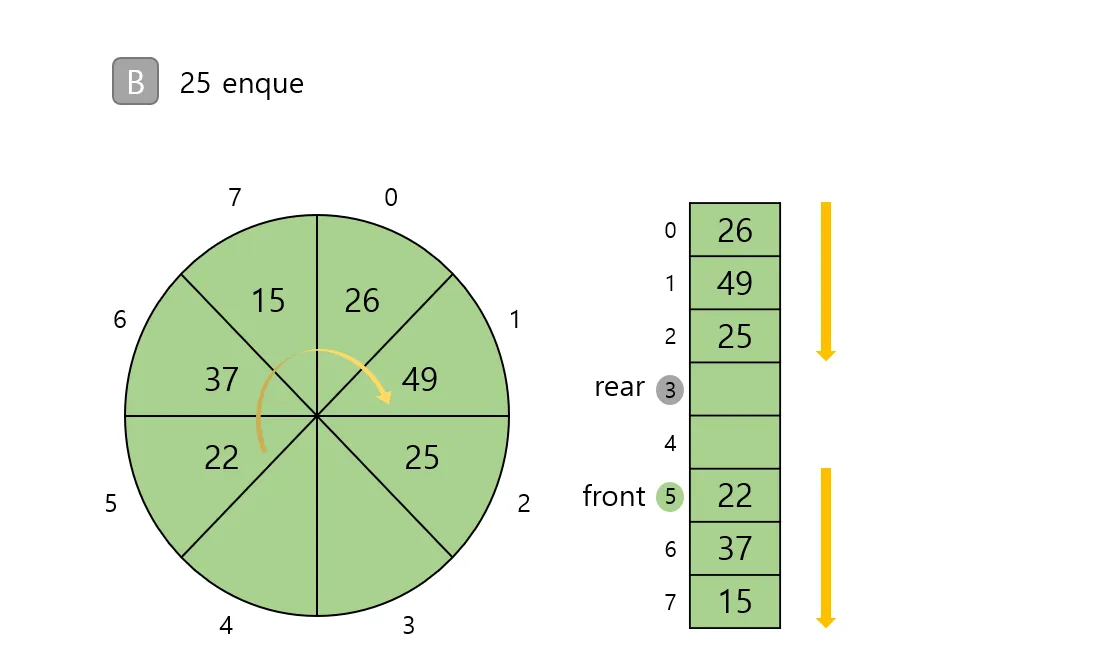
링 버퍼란?
- 큐의 크기를 고정하여 배열의 맨 끝과 맨 앞을 연결하는 구조
- 데이터가 가득 차면 가장 오래된 데이터를 덮어쓰기 가능
- 모든 연산이 O(1) → 매우 효율적
링 버퍼 구현 (고정 크기 큐)
python
복사편집
class RingBuffer:
def __init__(self, size):
self.buffer = [None] * size
self.max_size = size
self.front = 0
self.rear = 0
self.count = 0
def enqueue(self, value):
if self.count == self.max_size:
print("Queue is full")
return
self.buffer[self.rear] = value
self.rear = (self.rear + 1) % self.max_size
self.count += 1
def dequeue(self):
if self.count == 0:
print("Queue is empty")
return None
value = self.buffer[self.front]
self.front = (self.front + 1) % self.max_size
self.count -= 1
return value
queue = RingBuffer(3)
queue.enqueue(1)
queue.enqueue(2)
queue.enqueue(3)
print(queue.dequeue()) # 1 출력
queue.enqueue(4)
print(queue.dequeue()) # 2 출력
고정된 크기 내에서 O(1)로 동작하는 큐
우선순위 큐 (Priority Queue)
일반적인 큐는 순서대로 데이터를 꺼내지만, 우선순위 큐는 더 높은 우선순위를 가진 데이터를 먼저 처리
우선순위 큐 연산 및 시간 복잡도
| 연산 | 설명 | 시간 복잡도 |
|---|---|---|
| enqueue | 데이터를 추가하며 정렬 유지 | O(log n) |
| dequeue | 가장 우선순위가 높은 요소 제거 | O(log n) |
| peek | 가장 우선순위가 높은 요소 확인 | O(1) |
우선순위 큐 구현 (heapq 사용)
python
복사편집
import heapq
pq = []
heapq.heappush(pq, (2, "task2")) # 우선순위 2
heapq.heappush(pq, (1, "task1")) # 우선순위 1 (가장 먼저 처리됨)
heapq.heappush(pq, (3, "task3")) # 우선순위 3
print(heapq.heappop(pq)) # (1, 'task1') 출력
print(heapq.heappop(pq)) # (2, 'task2') 출력
# 파이썬 Priority Queue 라이브러리
from Queue import Priority Queue
최소 힙(Min-Heap) 구조로 자동 정렬됨
우선순위가 낮을수록 먼저 나옴 (높은 우선순위를 원하면 -값 사용)
큐의 장단점
장점
- 순차적 처리에 최적화됨 → FIFO 구조로 데이터 흐름을 단순화
- O(1) 연산 가능 (Deque, 링 버퍼 사용 시)
- 멀티스레딩 환경에서 유용 (생산자-소비자 패턴 적용 가능)
단점
- 일반 리스트로 구현 시 비효율적 (
pop(0)시 O(n) 발생) - 크기가 고정된 경우 (링 버퍼) 데이터 손실 가능
- 일반적인 큐는 특정 요소 접근이 느림 (O(n))
정리
- 큐는 FIFO(First In, First Out) 구조로 데이터 처리에 적합한 자료구조
- 일반 리스트 대신 deque 또는 링 버퍼를 사용하면 O(1) 연산 가능
- 우선순위 큐는 heapq를 사용하여 O(log n)으로 높은 우선순위를 가진 요소를 빠르게 처리
- 멀티스레딩, 데이터 스트리밍, CPU 스케줄링 등에 자주 사용됨

Bello! NewOld velog~