네트워크 성능 모니터링(NPM)?
네트워크 옵저버빌리티 스토리
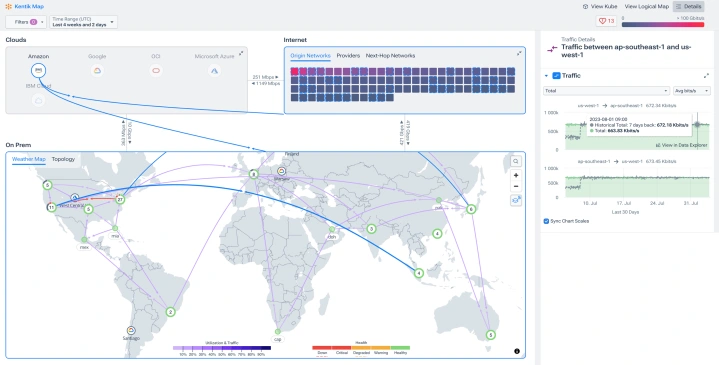
클라우드, SaaS, AI 등 다양한 IT 기술의 발전과 동시에 네트워크는 계속해서 복잡해지고 있습니다.
이 복잡한 네트워크의 성능을 이해하고 최적화하려면 네트워크 성능 모니터링(NPM)이 필요합니다.
네트워크 운영팀(NetOps)은 기본적인 NPM을 통해
- 네트워크 이슈를 사전에 감지하여 해결하고,
- 전반적인 네트워크 성능을 최적화하며
- 우수한 네트워킹 서비스 수준(SLA)을 보장합니다.
적절한 NPM 솔루션을 찾으려면 클라우드 기반 네트워크의 복잡성과 NPM 솔루션의 기능을 이해하는 네트워크 전문가가 필요합니다.
네트워크 성능 모니터링(NPM)은 무엇인가?
NPM은 유저가 경험하는 네트워크 서비스 품질을 측정, 진단, 최적화하는 프로세스입니다.
NPM 솔루션은 다양한 유형의 네트워크 데이터(ex. packet, flow, metric, test result)를 결합하여 네트워크의 성능과 가용성, 그리고 유저의 비즈니스와 연관된 네트워킹 결과값(metric)들을 분석합니다.
NPM 솔루션은 실시간으로, 또 시간 흐름에 따라 네트워크의 성능을 기록하고 분석하여 예측합니다.
하지만 단순하게 네트워크 성능 데이터(packet, snmp, flow...)를 수집하는 수동적인 과거의 네트워크 모니터링과는 다릅니다.
NPM은 네트워크 테스트(Synthetic test)를 통해 수집한 데이터까지 활용하여 실제 네트워크 유저가 경험하는 네트워킹 서비스 품질을 이해하는 데 중요한 역할을 할 수 있습니다.
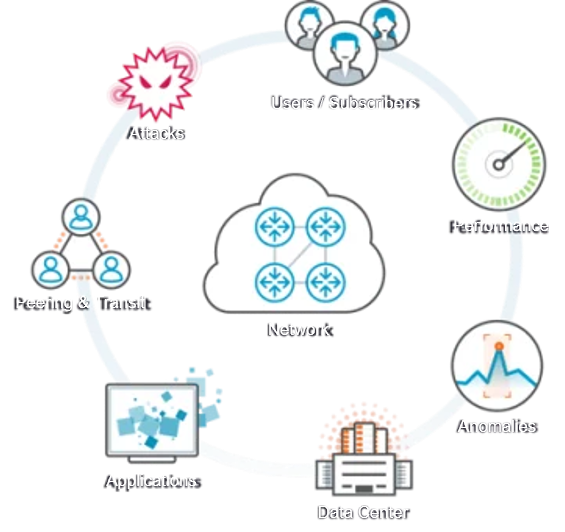
주요 네트워크 성능 지표와 데이터
NPM은 엔지니어가 네트워크를 진단하고 분석할 수 있도록 다양한 네트워크 성능 데이터를 활용합니다.
네트워크 성능 데이터의 예를 들자면,
-
대역폭(Bandwidth) : 네트워크에서 데이터가 전송되는 실제 속도와 논리적으로 사용 가능한 최대 속도를 측정합니다.
-
스루풋(Throughput) : 실제로 전송되는 데이터의 양을 측정합니다.
-
지연시간(Latency) : 네트워크 장비의 관점에서 네트워크 지연 시간을 측정합니다. 보통 양방향으로 왕복하는 시간(Round trip time), 즉 패킷이 출발지에서 목적지까지 이동하고 출발지에서 최종적으로 응답을 받는 시간을 측정합니다.
-
패킷손실(Packet loss) : 목적지에 도달하지 못한 데이터 패킷의 비율을 측정합니다. 패킷 손실률이 높으면 출발지에서 손실된 패킷을 재전송해야 하므로 지연 시간이 길어져 데이터 전송이 더욱 지연될 수 있습니다.
-
지터(Jitter) : 데이터 패킷 도착 간격이 일정하지 않은, 즉 지연시간이 들쑥 날쑥한 정도를 의미합니다. 핑(Ping)이 튀는 현상이 있다면 지터가 높은 것입니다.
-
오류(Error) : bit error, TCP 재전송, Out-of-order 패킷 등의 오류가 있는 패킷이 얼마나 많은지 측정합니다.
NPM? NPMD?
NPM : Network performance monitoring
NPMD : Network performance monitoring and Diagnostics
NPM 솔루션은 NPMD라는 이름으로 불리기도 합니다. 글로벌 IT 기술 분석 기관인 Gartner는 네트워크 성능 모니터링 시장을 NPMD 시장으로 명명하고 다양한 데이터를 조합하여 활용하는 솔루션이라고 정의했습니다.
다양한 데이터... 애매하네요.
예시는 이렇습니다.
- 네트워크 장비에서 자체적으로 생성하는 상태 지표, 이벤트 (snmp, log)
- 네트워크 장비에서 자체적으로 생성하는 트래픽 지표 (flow)
- 실제로 전송되는 데이터 패킷 등
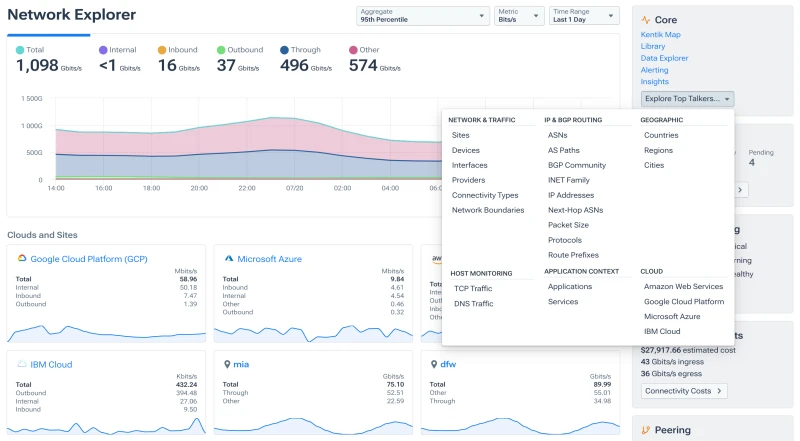
NPM 솔루션은 어떻게 데이터를 수집할까?
NPM은 네트워크 장비의 상태를 파악하기 위해 snmp polling, flow export, 패킷 캡처(PCAP) 장비와 같은 데이터에 의존해 왔습니다.
하지만 빅데이터 시대, IT인프라 환경에서의 네트워크는
클라우드 네트워크 환경에 적합한(Cloud-native) 접근 방식을 필요로 합니다.
따라서 NPM은 이제 SaaS/빅데이터 백엔드 인프라를 구축한 뒤 서버(host)에 설치되는 모니터링 에이전트를 활용하여 클라우드 네이티브한 방식으로 네트워크를 분석합니다.
최신 NPM 솔루션은 퍼블릭 클라우드(ex. AWS, MS Azure, Google Cloud 등)에서 생성된 클라우드의 네트워크 데이터(Flow log, API)를 수집하고 분석할 수 있는 기능도 제공합니다.
SNMP Polling (SNMP 끌어당기기)
SNMP : Simple Network Management Protocol
SNMP는 IETF 표준 프로토콜이며 네트워크 장비의 인터페이스 별 대역폭, 사용률, 오류 측정 값을 수집하는 가장 기본적인 방법입니다.
SNMP는 MIB라는 관리용 정보 베이스를 사용하며, 네트워크 장비가 저장한 MIB 데이터를 Polling, 즉 요청하고 응답받는 방식으로 활용합니다. 보통 네트워크 과부화를 피하기 위해 5분 간격으로만 Polling합니다.
SNMP Polling은 5분 가량의 Polling 간격으로 인해 트래픽이 폭주하는 시점의 데이터를 확인할 수 없으며, 네트워크 장비의 인터페이스 관점에서만 데이터를 제공하기에 네트워크를 세분화하여 분석할 수 없다는 단점이 있습니다.
Traffic Flow Record Export (Flow 내보내기)
Flow는 라우터, 스위치, 그리고 flow 생성 프로그램을 통해 IP 주소, 프로토콜(ex. tcp, udp), 포트 번호, ToS 등의 네트워킹 정보를 실제 데이터 패킷의 헤더에서 추출한 정보입니다.
Flow는 단방향으로 정보를 기록하며, 이에 대한 통계값을 제공합니다.
네트워크 장비는 Flow가 종료되거나 설정한 타이머에 도달할 때마다 Flow 통계 수집을 중지하고 Flow 수집 서버로 전송(내보내기)합니다.
SNMP는 네트워크 장비에 요청을 해야 받을 수 있는 반면, Flow는 네트워크 장비가 직접 전송하는 특징이 있습니다.
Flow 표준 프로토콜은 NetFlow, sFlow, IPFIX를 비롯한 다양한 Flow 포맷이 있습니다. NetFlow는 Cisco에서 만든 프로토콜이며 사실상 업계 표준으로 사용됩니다. sFlow와 IPFIX는 모든 벤더에서 지원할 수 있는 표준 프로토콜입니다.
NPM이 Flow를 사용하는 이유
Flow는 SNMP 보다 훨씬 방대한 데이터 크기를 가지고 있으며,
실제 트래픽 흐름을 이해할 수 있도록 유용한 세부 정보를 제공합니다.
Flow는 실제 네트워크 사용량(Throughput)을 포함하고 있으며, 인터페이스 정보도 포함하고 있기에 네트워크 장비의 각 인터페이스 별 최대 대역폭 대비 실제 사용률을 계산하는데에도 사용됩니다.
또한 모든 Flow에 출발지/도착지 IP주소가 기록되어 있기에 BGP 인터넷 라우팅 경로와 결합하여 상세 분석을 진행하기도 합니다.
네트워크 성능은 인터넷 경로 상의 특정 네트워크(AS)와도 깊게 연관되기에 위와 같은 BGP 통합 분석은 NPM 솔루션의 필수적인 요소로 인지되고 있습니다.
Flow Sampling
Flow는 패킷의 실제 데이터 콘텐츠(Payload)를 수집하지 않습니다.
따라서 Flow 정보에는 우리의 ID와 PW는 기록되지 않죠.
대신 모든 패킷의 헤더(header) 정보를 수집합니다.
Flow에는 Sampling 기법이 사용할 수 있습니다. 모든 단방향 패킷의 헤더를 수집하여 Flow 정보를 기록할 수도 있지만, 적절한 수준의 샘플링을 거쳐 Flow를 기록하기도 합니다.
Flow를 사용하는 목적에 따라 샘플링 비율을 적절히 조절하여 사용하면 네트워크 장비와 분석 서버 모두의 리소스를 효율적으로 사용할 수 있기 때문입니다.
대규모 네트워크에서는 8000개 단방향 패킷 중에 1개를 샘플링하는 1:8000의 비율도
네트워크 성능 관리 목적에 적합한, 정확한 통계값을 제공한다고 알려져 있습니다.
VPC/Cloud Flow logs
네트워크 장비에서 생성하는 Flow와 마찬가지로 클라우드에서도 Flow 정보를 수집하고 내보낼(Export)수 있습니다. 예를 들면, AWS의 VPC는 특정 네트워크 인터페이스(ENI)를 지나가는 IP 트래픽에 대한 정보를 기록하는 'VPC Flow log' 기능을 제공합니다.
Flow 샘플링과 마찬가지로 VPC Flow log는 다양한 클라우드 인프라 구성 요소(ex. Instance, k8s node)에서 주고받는 패킷 헤더를 기록합니다.
클라우드에서 생성된 Flow 또한 NPM 솔루션에서 수집하여, 클라우드 네트워크에 대한 모니터링과 분석 용도로 사용됩니다.
패킷 캡처 (PCAP)
패킷 캡처는 특정 네트워크 인터페이스를 통과하는 모든 패킷을 기록합니다.
PCAP 데이터는 패킷 헤더와 전체 Payload를 모두 포함하므로 수집되는 정보가 세분화됩니다.
따라서 PCAP 데이터는 우리의 ID와 PW도 모두 포함하고 있죠.
인터페이스는 패킷이 들어오고 나가는 것을 모두 볼 수 있기 때문에 아웃바운드 패킷과 인바운드 응답 사이의 지연 시간을 정확하게 측정할 수 있습니다.
PCAP는 가장 풍부한 네트워크 성능 데이터를 제공합니다.
PCAP는 원하는 서버에서 tcpdump, Wireshark와 같은 오픈 소스 네트워크 유틸리티를 사용하여 수행할 수 있습니다. 이는 네트워크 담당자가 네트워크 성능 문제를 파악하는 데 매우 효과적인 방법이 될 수 있습니다.
하지만 이 방법은 유틸리티에 대해 상당히 심도 있는 지식이 필요한 수동 프로세스이므로 확장성이 떨어집니다. 소수의 네트워크 담당자가 네트워크 전체의 PCAP 데이터를 분석할 수는 없겠죠.
이러한 수동적인 접근 방식을 개선하기 위해 Appliance(장비) 기반 PCAP Probe를 사용할 수 있습니다. 이 Probe는 다수의 라우터/스위치의 Span 포트와 패킷 브로커 장비(ex. Gigamon, Ixia)에 연결됩니다. 경우에 따라 가상 Probe를 사용할 수 있지만 어떤 형태로든 네트워크 연결에 의존합니다.
패킷 캡처 장비(PCAP Probe)의 한계
PCAP 장비의 가장 큰 단점은 배포(확장) 비용입니다.
물리적인 PCAP 장비나 가상화된 PCAP Probe 모두 소프트웨어 라이선스 측면에서 비용이 많이 듭니다. 따라서 네트워크에서 가장 중요하다고 판단되는 소수의 구간에만 PCAP 장비를 배포하게 됩니다.
또한, PCAP 장비의 배포 모델은 제한된 규모의 중앙 집중식 데이터센터 네트워킹 아키텍처를 기반으로 개발되었습니다.
멀티클라우드와 분산형 애플리케이션 모델이 확산되면서, 애플리케이션 구성 요소가 다수의 가상머신과 컨테이너에 광범위하게 분산되어 있기 때문에 PCAP 장비를 도입하는 것은 매우 어려운 상황이 되었습니다.
심지어 다수의 클라우드 인프라에서는 가상화된 PCAP Probe를 배포하는 방법조차 없습니다.
서버/호스트 NPM 에이전트
클라우드 네이티브하며 확장성이 뛰어난 NPM 모델은 서버에서 수집한 PCAP 기반 통계를 내보내는 라이트한 호스트 에이전트와 HAProxy ,NGINX와 같은 오픈소스 프록시 서버를 결합하는 모델입니다.
내보낸 PCAP 기반 통계 데이터는 빅데이터 분석 서비스를 제공하기 위해 SaaS 방식으로 제공되곤 합니다.
서버/호스트 에이전트를 활용한 네트워크 성능 데이터는 실제 PCAP 데이터만큼 완전한 정보를 제공하지는 않지만, 네트워크 성능 분석에 주요한 데이터를 어디서나 수집하고 분석할 수 있는 확장성을 비용 효율적으로 제공하기에 PCAP을 보완하는 방식으로 사용되고 있습니다.
네트워크 옵저버빌리티 플랫폼 kentik은 kprobe, kappa라는 이름의 서버/호스트 NPM 에이전트를 지원합니다.
Synthetic test, monitoring
최근 현대적인 NPM 솔루션들은 모두 Synthetic test, 모니터링 기능을 탑재하는 추세입니다.
'Synthetic'이란 '인공적인'이란 의미로 해석할 수 있습니다.
즉, 네트워크에 인공적으로 트래픽을 발생시키고 그 성능을 분석하는 것을 의미합니다.
Synthetic test는 '디지털 경험 모니터링'(Digital Experience Monitoring, Real User Monitoring)의 영역과 연관되어 있습니다.
Flow 또는 PCAP과 달리 Synthetic 모니터링는 네트워크, 애플리케이션, 서비스의 성능과 상태를 선제적(Pro-active)으로 추적하는 방법론입니다.
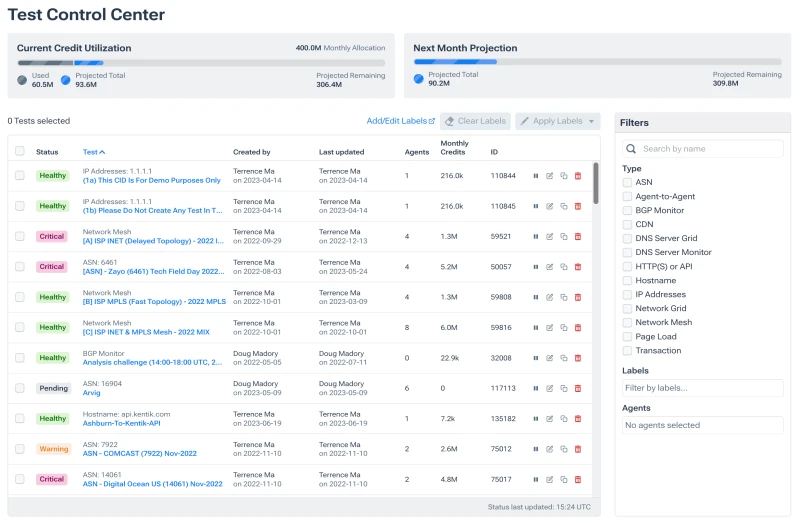
네트워크에서 Synthetic 모니터링은 다양한 유형의 네트워크 트래픽(ex. DNS, HTTPS/API, HTTP)을 생성하여 특정 도착지로 전송하고, 이 Synthetic 테스트와 관련된 네트워크 성능 지표를 측정, 분석하는 것을 의미합니다.
이를 통해 네트워크 성능과 관련된 KPI를 구축하고 달성할 수도 있습니다.
NPM, 네트워크 옵저버빌리티에 필요한 Context 데이터와 통합 분석
NPM에 필요한 데이터는 위에서 언급한 데이터에 국한되지 않습니다.
네트워크 옵저버빌리티를 이루기 위해서, NPM은 이벤트 로그, 장비에서 발생하는 메트릭, Streaming telemetry, DHCP 정보 등 다양한 맥락(Context)을 가진 데이터들을 필요로 합니다.
아래 5분 가량의 영상은 네트워크 옵저버빌리티에 필요한 데이터와 통합 분석 기능이 어떠한 것인지 논합니다. 영어로 된 영상이지만 잠깐 시청해보실 것을 권유해드립니다.
“5 Problems Your Current Network Monitoring Can’t Solve (That Network Observability Can)”

왜? 네트워크 성능 모니터링을 해야할까?
NPM 솔루션은 네트워크 운영팀(NetOps)과 조직에 다양한 이점(Benefit)을 제공합니다.
결론적으로 NPM 솔루션은 네트워크의 가시성, 안정성, 효율성을 개선하여 네트워크 거버넌스(Governance)를 증대하고 궁극적으로 더 나은 디지털 경험과 비즈니스 성과를 안겨줍니다.
NPM의 주요 이점 (Benefit) :
-
선제적인 문제 감지 : NPM 솔루션을 통해 네트워크 이슈를 조기에 식별하여 네트워크 사용자나 중요한 비즈니스 운영에 영향을 미치기 전에 네트워크 운영팀에서 문제를 미리 해결할 수 있습니다.
-
트러블슈팅 시간 단축 : 네트워크 트래픽과 성능에 대한 포괄적인 가시성을 통해 네트워크 팀에서는 문제의 근본 원인을 보다 효율적으로 파악하여 트러블슈팅 시간(MTTR)을 단축하고 네트워크 다운타임을 최소화할 수 있습니다.
-
네트워크 성능 최적화 : NPM 솔루션은 네트워크 병목 현상, 지연 시간 및 기타 성능 관련 문제에 대한 인사이트를 제공하여 조직이 더 나은 성능과 사용자 경험을 위해 네트워크를 최적화할 수 있도록 지원합니다.
-
네트워크 리소스 할당 계획 : NPM 솔루션은 네트워크 사용률과 성능 추이를 모니터링하여 조직이 현재와 미래의 트래픽을 감당할 수 있게 합니다. 즉, 네트워크 리소스 할당, 인프라 투자 시 데이터에 기반한 의사 결정을 내릴 수 있도록 지원합니다.
-
보안 강화: NPM 솔루션은 비정상적인 트래픽 패턴, 잠재적인 DDoS 공격과 네트워크 보안 위협을 식별하여 네트워크 보안 관점에서 신속한 조치를 취할 수 있도록 도와줍니다.
-
네트워크 서비스 경험 개선 : 네트워크 성능을 선제적으로 모니터링하고 최적화하면 궁극적으로 최종 사용자 경험이 향상되어 고객 만족도, 직원 생산성, 전반적인 비즈니스 성공에 직접적인 영향을 미칠 수 있습니다.
아쉽지만, NPM 솔루션이 모든 것을 해결해주지는 못합니다
NPM이 많은 Benefit을 가져다주지만 모든 것을 해결해주지는 않습니다.
따라서 NPM을 사용하더라도 네트워크 팀과 조직이 부딪혀야 하는 어려움이 몇가지 있습니다.
-
거대하고 복잡한 네트워크 : 현대 네트워크는 온프레미스, 클라우드, 하이브리드, 컨테이너 네트워킹(k8s)를 아우르며 계속해서 복잡해지고 있습니다. 특히 비즈니스에서 새로운 기술과 서비스를 도입함에 따라 다양한 유형의 대규모 네트워크가 형성됩니다. 이런 환경 속에서 적절한 NPM 솔루션을 통해 네트워크 전반의 성능을 관리하고 모니터링하는 것은 전문지식이 필요한 일입니다.
-
데이터 과부화 : 네트워크 모니터링 시스템은 Flow, PCAP, Host agent 등 다양한 데이터 소스에서 방대한 양의 데이터를 생성하고 수집합니다. 이 빅데이터를 관리하고 분석하여 의미있는 인사이트를 도출하는 것은 굉장히 어려운 일이며, 적절한 솔루션과 전문지식이 결합될 때에만 가능한 일이 될 수 있습니다.
-
다른 솔루션/시스템과의 연계, 통합 : 네트워크 모니터링 솔루션은 다른 네트워크 관리 솔루션, 보안 시스템, IT 인프라 구성 요소와 연계되고 통합되어야 하는 경우가 많습니다. 이런 서로 다른 시스템 간 원활한 데이터 공유, 연계, 통합은 NPM 솔루션의 통합/연계 용이성과 사용자 기업에서의 협업 문화가 동시에 갖춰져야 가능한 일입니다.
-
비용/리소스 제약 : PCAP Probe를 사용하거나 대규모 네트워크에서 NPM 솔루션을 배포하고 유지관리하려면 많은 비용과 리소스가 투입되어야 합니다. 기업은 포괄적인 네트워크 가시성의 필요성과 비용/리소스 제약 사이의 균형을 유지해야 합니다.
-
빠르게 발전하는 IT 기술 습득 : 네트워크 기술이 빠르게 발전함에 따라 네트워크 모니터링 솔루션과 방법론도 이에 발맞춰 발전해야 합니다. 네트워크 팀에서는 기업의 민첩성과 경쟁력을 유지하기 위해 NPM의 최신 기술과 Best practice, 사용 사례에 대한 정보를 지속적으로 파악해야 합니다.
NPM Best Practices (모범 사례)
네트워크 팀(NetOps)은 어떻게 NPM의 가치를 극대화하고 위와 같은 Challenge를 극복할 수 있을까요?
-
다양한 데이터 소스 활용 : SNMP polling, flow, pcap, host agent, synthetic test 등 다양한 데이터를 활용하여 네트워크 성능에 대한 포괄적인 가시성을 확보해야 합니다.
-
네트워크 성능에 대한 기준 설정 : 네트워크 성능의 기준이 되는 지표를 결정하고 Metric이 얼마나 흔들리는지, 잠재적 문제는 없는지 신속하게 파악합니다. 네트워크가 변화할 때마다 이 기준을 정기적으로 검토하고 업데이트합니다.
-
장애를 사전에 감지할 수 있는 Pro-acitve 모니터링과 알림 프로세스 구축 : 네트워크 성능 문제가 최종 사용자나 비즈니스 운영에 영향을 미치기 전에 문제를 감지할 수 있도록 Pro-active한 모니터링과 실시간 알림 체계를 구축합니다. 나아가 알림의 임계값(Threshold)을 미세 조정하여 오탐을 최소화하면서 Slack, Teams, Webex 등 비즈니스에 적합한 협업 툴에서 적시에 알림을 받을 수 있도록 합니다.
-
클라우드 네이티브한 NPM 솔루션 투자 : 네트워크의 복잡도와 규모에 상관없이, 하이브리드/멀티클라우드, 쿠버네티스 환경까지 커버할 수 있는 NPM 솔루션에 과감히 투자합니다.
-
주기적인 네트워크 최적화, 검증 프로세스 구축 : 네트워크 성능 모니터링은 지속적이고 반복적인 프로세스가 되어야 합니다. 네트워크 환경이 변화함에 따라 네트워크 팀에서는 모니터링 전략, 성능에 대한 기준, 최적화 프로세스를 지속적으로 검토하고 개선하여 네트워크가 최적의 상태로 유지되도록 노력합니다.
마치며
읽어주셔서 감사합니다.
네트워킹 기술과 시장에 대한 소통, 언제나 환영합니다! 🙌
Coffee chat 신청하기
메모 남겨주시면 간단한 커피챗을 통해 저희 팀의 경험을 공유해드릴게요 😊
에어키는 네트워크 옵저버빌리티 플랫폼, kentik의 파트너로 활동하고 있습니다.
문의처 - 에어키 MSP팀 김상휘 프로 (shkim0730@airquay.com, +82-10-2914-9400)
이 글은 kentik의 kentipedia 문서의 번역/수정본이며 오역이 있을 수 있습니다. (출처)
