본 포스팅 시리즈는 다양한 머신러닝 테크닉에 대해 수학적 관점과 실용적 관점에서 정리한다.
필자는 수학을 전공했기 때문에 수학적 접근과 용어에 대해 익숙하게 사용한 것이 있지만, 수학을 전공하지 않은 사람들에겐 다소 낯선 접근과 용어가 있을 수 있다.
최대한 그러한 부분을 자세히 설명하려 노력하였지만 필자의 타전공자에 대한 '공감능력부족'으로 효과적으로 전달되지 못한 부분이 있을 것으로 생각된다.
이 글을 읽어주시는 분께 일차적으로 감사드리며, 해당 부분에 대해 질문이나 코멘트를 남겨주시는 분께는 거듭제곱으로 감사드림을 말씀드린다.
Support Vector Machine
서포트 벡터 머신은 딥러닝이 등장하기 이전에 가장 유명하고 성능 좋은 머신러닝 모델이었다고 한다.
현재는 다소 실무에서 사용되는 정도가 줄어들었겠지만, 서포트 벡터 머신에 적용되는 다양한 수학적 테크닉들은 인공지능을 이해하고 연구하는 데에 여전히 훌륭한 인사이트를 준다고 생각한다.
특히 서포트 벡터 머신의 아이디어는 유클리드 기하학과 최적화 이론으로 설명이 된다는 점은 수학자들에게 있어서 굉장히 매력적이다.
본 포스팅의 내용은 다음의 자료들을 참고했다.
- Mathematics for Machine Learning (Deisenroth, Marc Peter and Faisal, A. Aldo and Ong, Cheng Soon)
- The Elements for Statistical Learning (Trevor Hastie, Robert Tibshirani, Jerome Friedman)
- 김민준님(이화여자대학교, 수학과 석사)의 SVM Lecture note
- 김원화 교수님(포항공과대학교, 인공지능대학원 교수)의 데이터 마이닝 Lecture note
- Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow (Aurelien, Geron)
1. Introduction
📌 핵심 Keyword
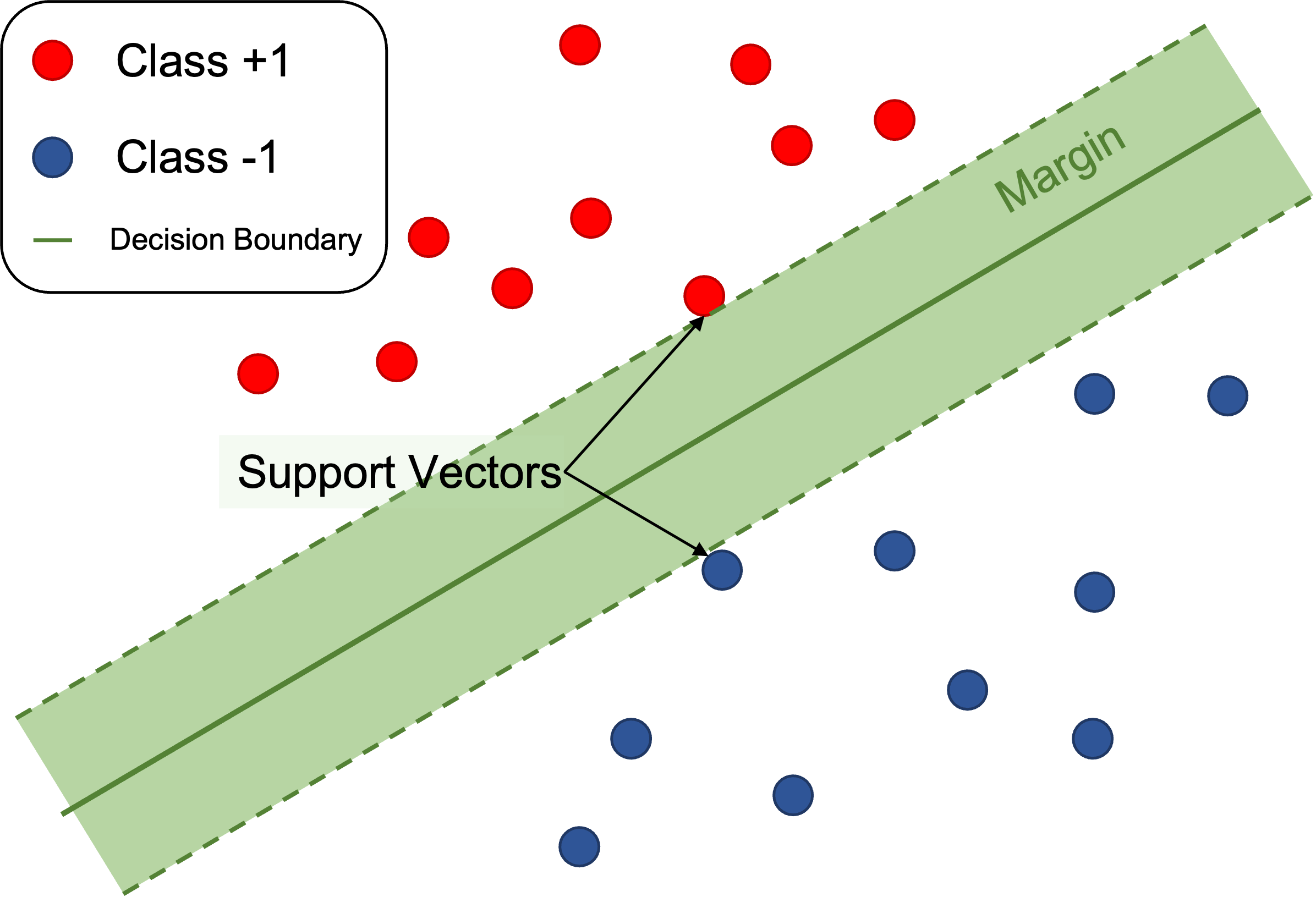
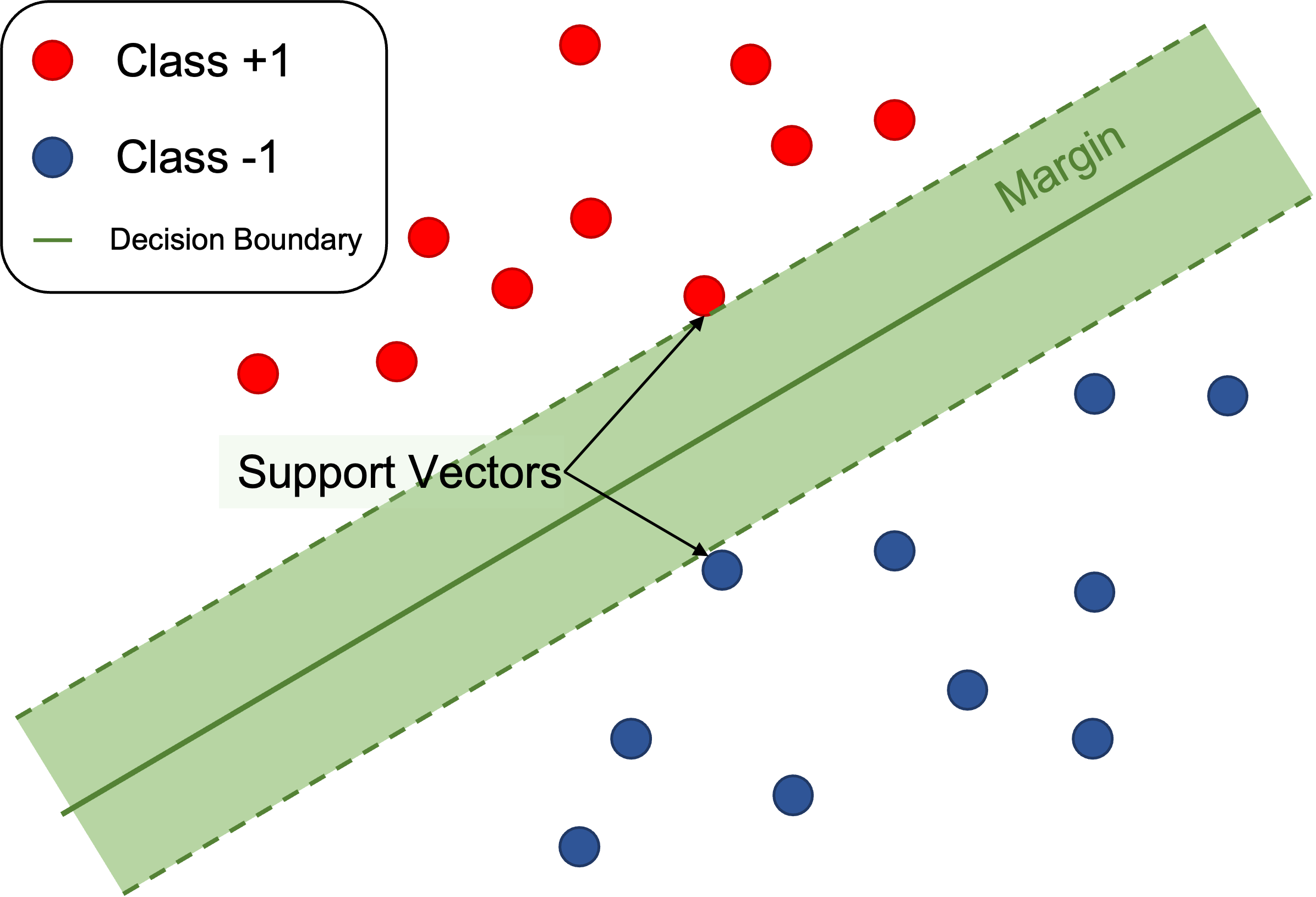
- 서포트 벡터 (Support Vector) : 새로운 데이터가 들어왔을 때, 해당 데이터를 구분시켜줄 기준이 되는 샘플
- 결정 경계 (Decision Boundary) : 모델에 의해 만들어진 클래스를 구분할 기준이 되는 초평면
- 마진 (Margin) : 결정 경계를 중심으로 서포트 벡터까지의 거리만큼 나란하게 떨어진 영역
Support Vector Machine(SVM)은 데이터를 분류하기 위해 클래스 사이의 마진(margin)을 최대화하는 초평면을 찾는다.
예를들어, 두 개의 특성변수를 가지는 이진분류 문제는 데이터를 2차원 평면상에 표현할 수 있으며, SVM은 이들 두 클래스를 분할하면서 마진(직선 양 옆으로 평행하게 뻗은 띠)을 최대화하는 직선을 찾는다.
SVM은 확률모델에 기반으로한 머신러닝 모델들과는 다른 두 가지 특징을 가진다.
- SVM은 이진분류 문제를 기하학적인 방법으로 접근한다. 이는 확률모델의 관점으로 접근하는 많은 머신러닝 모델들과 구별되는 점이다.
- (soft-margin) SVM의 최적화 문제는 해석적 해를 구하기 어렵다. 따라서 다양한 최적화 방법론(e.g. 경사하강법)에 의존해야 한다.
확률모델에 기반한 머신러닝 모델은 최대우도추정(Maximum Likelihood Estimation)과 베이지안 추정(Bayesian inference)를 취하고 있다.
이러한 관점에서 확률기반 모델은 데이터의 유사성에 대한 확률론적 시각(e.g. 확률분포)을 기반으로한 최대우도를 추정하는 최적화문제로 모델추론에 접근한다.
그러나 SVM은 데이터의 유사성에 대한 기하학적 시각을 기반으로 최적화문제를 제시한다.
데이터의 유사성에 대한 기하학적 시각은 내적(inner product)과 거리(metric) 개념에 의존한다.
SVM은 두 클래스 간의 거리(margin)를 가장 크게 만드는 최적화문제로 모델추론에 접근한다.
SVM은 훌륭한 모델이지만, 현재는 딥러닝 모델이 훨씬 범용적으로 사용되고 좋은 성능을 보여준다.
이러한 점에서 필자는 단순히 SVM을 얕게 이해하고 모델을 구현하는 방법을 익히는 것이 그렇게 큰 도움이 될 것이라고 생각하지 않는다.
SVM 이론에 포함된 기하학적 인사이트, 선형분류의 한계를 뛰어넘기 위한 다양한 전략들은 수학적으로 잘 formulation 되어 있기 때문에 수학적으로 훈련된 이들에겐 SVM만큼 다양한 인사이트를 제공하는 모델이 없다고 생각한다.
본 포스팅을 작성하는 필자나 읽는 독자나 이 시리즈가 마쳤을 때에 자신만의 훌륭한 인사이트를 가지고 떠나길 바라는 바이다.
📌 요약 Summary
- 서포트 벡터 머신은 마진을 최대화 하는 결정경계를 만드는 것으로 분류문제를 기하학적으로 접근하여 최적화된 모델을 찾는다.
