
본 포스팅은 2023년 1월 16일 - 17일 양일간 진행된 부산대학교 수학과 빅데이터 기반 미래 교육 인재 양성 프로그램(주최 : 부산대학교 빅데이터 기반 금융 수산 제조 혁신 산업수학센터)에서 필자가 시연한 TDA 튜토리얼을 기반으로 하고 있습니다.
Python 코드 실습 자료는 필자의 Github repository에서 확인하실 수 있습니다.
이번 포스팅의 프로그래밍 실습 자료는 위 깃허브 저장소에 포함되어 있습니다.
프로그래밍 구현이 궁금하신 분은 깃허브를 참고해주세요
4. Machine Learning

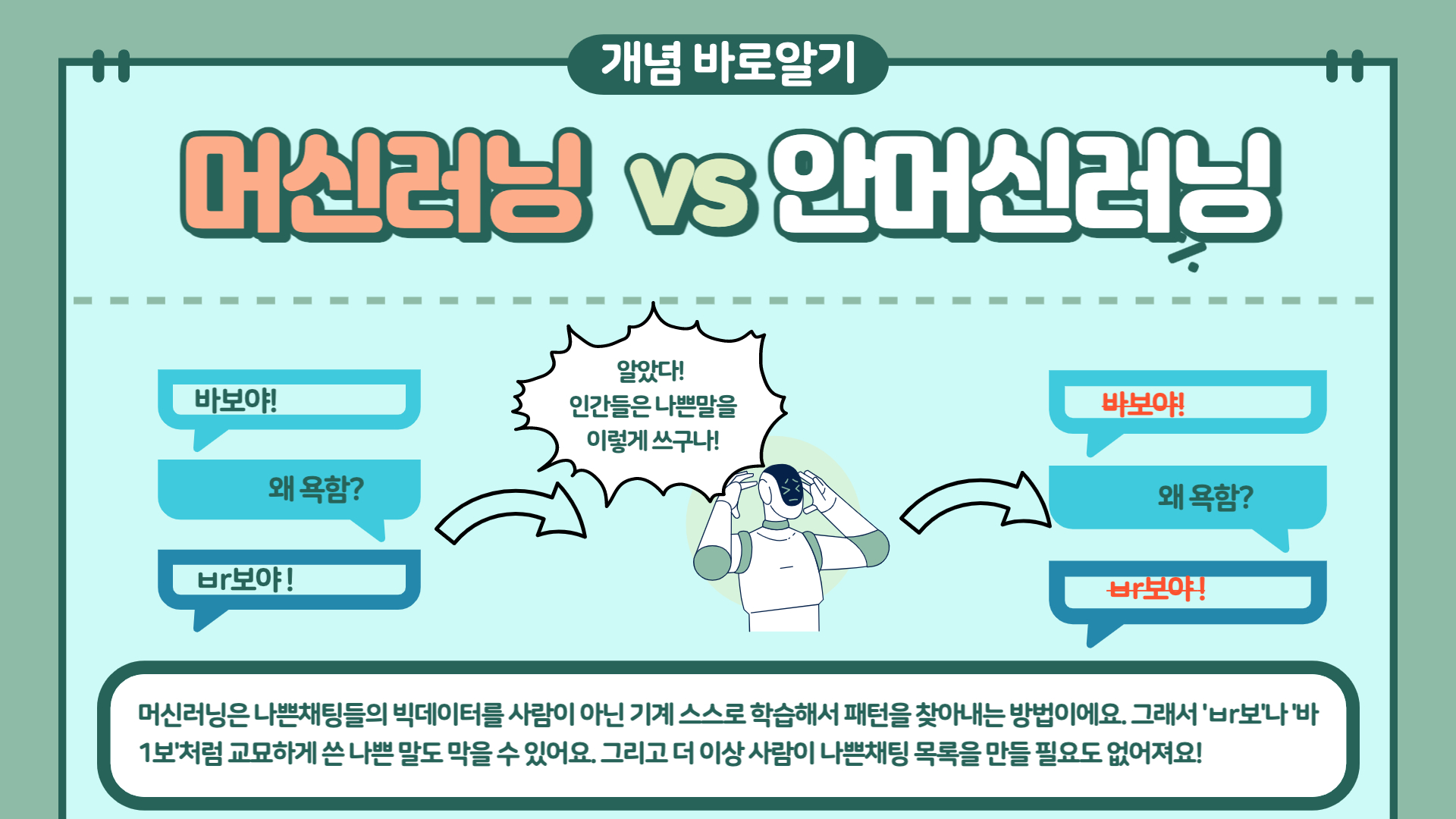 머신러닝이 아닌 알고리즘은 데이터에서 사람의 지식을 기반으로 패턴을 찾아 원하는 작업을 자동화하는 방식으로 작동한다. 그러나, 머신러닝은 데이터에서 원하는 작업에 최적화된 패턴을 기계 스스로 찾아 작동한다.
머신러닝이 아닌 알고리즘은 데이터에서 사람의 지식을 기반으로 패턴을 찾아 원하는 작업을 자동화하는 방식으로 작동한다. 그러나, 머신러닝은 데이터에서 원하는 작업에 최적화된 패턴을 기계 스스로 찾아 작동한다.
먼저 간단하게 머신러닝이란 무엇인지, 그리고 머신러닝은 전반적으로 어떤 과정을 거쳐 문제를 해결하는지 살펴봅시다.
머신러닝이란, 주어진 문제를 해결하기 위해 기계가 데이터에 잠재된 패턴을 스스로 학습하고 문제 해결에 최적화된 솔루션을 스스로 만들어내는 모델이라고 할 수 있습니다.
이때, 데이터가 가진 특징을 사용하는 방법을 사람이 지정해주는 것이 아니라 기계 스스로 학습하여 만들어내기 때문에 인공지능의 한 방법론이라 할 수 있습니다.
머신러닝은 일반적으로 다음과 같은 파이프라인을 거쳐 문제를 해결합니다.
Machine Learning Pipeline
문제정의 : 개와 고양이 사진을 구분하는 분류, 미래의 주가를 예측하는 회귀, 유사한 데이터를 모으는 군집 등으로 문제를 적절하게 정의합니다.
데이터 정제 및 가공 : 풀고자 하는 문제에 대한 데이터를 수집하고 머신러닝에 사용할 수 있도록 가공합니다.
모델 선택 및 학습 : 수집된 데이터의 포멧에 따라 혹은 정의된 문제에 따라 가장 적합한 머신러닝 모델을 선택하고 훈련 데이터를 학습시킵니다.
모델 평가 : 아직 관측되지 않은 데이터에 대해서도 훈련 상황과 유사한 성능이 나오는지를 평가합니다.
론칭 : 적절한 수준의 평가점수를 얻은 머신러닝 모델을 론칭합니다.
4.1) 데이터 소개 및 문제 정의
MNIST 손글씨 숫자 이미지 데이터
 MNIST handwritten digit database, Yann LeCun et al.
MNIST handwritten digit database, Yann LeCun et al.
MNIST 손글씨 숫자 데이터는 머신러닝을 입문하기 위한 가장 대표적인 데이터로, 0~9까지의 손글씨 숫자가 7만장 준비되어 있습니다.
각 이미지는 0~255까지의 그래이 스케일 값을 가지는 28x28(784개)의 픽셀로 구성되어 있습니다.
또한 각 이미지가 어떤 숫자를 나타내는지 정답지도 구비되어 있습니다.
이미지 분류 (Classification)
분류 문제는 가장 대표적인 머신러닝 문제입니다.
분류 문제의 목표는 사진 데이터를 입력받으면, 이 사진이 어떤 숫자인지 말해주는 머신 혹은 함수를 만드는 것입니다.
머신러닝이 하는 역할은 이 문제를 위해 손수 모델링을 하는 것이 아니라, 모델이 훈련 데이터를 학습하여 출력 함수를 스스로 설계하도록 만드는 것입니다.
호몰로지 클래스 분류 (Homology classification)
일반적인 MNIST 분류는 단순히 이미지가 어떤 숫자인지를 알아 맞히는 문제입니다.
그러나, 호몰로지 클래스 분류는 이미지가 가진 구멍의 개수를 알아 맞히는 문제입니다.
예를들어, 숫자 이미지 1은 구멍이 없으므로 0으로 예측하고, 숫자 이미지 0은 구멍이 하나 있으므로 1로 예측하고, 숫자 이미지 8은 구멍이 두 개 있으므로 2로 예측하길 원하는 것입니다.
4.2) 데이터 정제 및 가공
우리는 다음과 같이 데이터를 정제하고 가공할 것입니다.
-
훈련 데이터 샘플 수 : 7,000 개 (실험을 위한 성능의 제약과 메모리 사용량 완화를 위해)
-
데이터 포맷 : 이미지를 길이가 784인 벡터 형태로 입력받아 사용할 것입니다.
-
정규화 : 일부 머신러닝 모델들은 데이터의 스케일에 영향을 받으므로 0~255까지인 픽셀 값을 0~1까지의 값으로 정규화해줍니다.
-
레이블 수정 : MNIST 데이터의 기본 레이블(정답)은 이미지가 나타내는 0~9 까지의 숫자로 되어 있습니다. 그러나, 우리가 풀 문제는 호몰로지 클래스를 분류하는 문제이므로, 숫자의 구멍의 개수에 따라 레이블을 수정해줍니다.
from sklearn.datasets import fetch_openml from sklearn.model_selection import train_test_split # data load mnist = fetch_openml('mnist_784', as_frame=False) # training/test data split X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, >train_size=0.1, random_state=seed) # data normalization X_train = X_train / 255.0 X_test = X_test / 255.0 X_train.shape, X_test.shape, y_train.shape, y_test.shape
# label transform def homology_class(label): if label == '8': return 2 elif label == '0' or label == '6' or label == '9': return 1 else: return 0 y_train_hom = np.array(list(map(homology_class, y_train))) y_test_hom = np.array(list(map(homology_class, y_test)))
 MNIST 데이터의 일부 샘플. 기존 MNIST 분류 문제와는 달리, 숫자가 가진 구멍의 개수로 레이블링 되어 있다.
MNIST 데이터의 일부 샘플. 기존 MNIST 분류 문제와는 달리, 숫자가 가진 구멍의 개수로 레이블링 되어 있다.
4.3) 모델 선택 및 학습
우리는 가장 단순한 머신러닝 분류기인 '퍼셉트론'을 사용할 것입니다.
퍼셉트론은 뉴럴 네트워크의 기본 단위가 되는 선형 모델입니다.
 퍼셉트론의 작동방식 도식화
퍼셉트론의 작동방식 도식화
퍼셉트론에 대한 자세한 설명은 다음 자료를 참고해주세요.
[머신러닝 정리] 퍼셉트론 (Perceptron)
사이킷런(scikit-learn) 라이브러리를 이용하면 퍼셉트론과 같은 머신러닝 모델을 쉽게 불러오고 학습시킬 수 있습니다.
from sklearn.linear_model import Perceptron # Model training model = Perceptron(random_state=seed) model.fit(X_train, y_train_hom)
4.4) 모델 평가
모델 평가는 모델 학습에 사용되지 않은 테스트 데이터를 사용합니다.
이렇게 해서 모델이 얼마나 일반적인 상황에서 이 문제를 잘 해결할 수 있는지 평가합니다.
분류 모델 평가에는 '정확도(accuracy score)'를 사용합니다.
정확도는 테스트 데이터에 대한 모델의 예측 레이블과 정답 레이블을 각각 비교하여, 정답을 맞춘 비율을 계산합니다.
from sklearn.metrics import accuracy_score # Compute accuracy y_pred = model.predict(X_test) accuracy_score(y_pred, y_test_hom) > output 0.8229206349206349
우리 모델의 정확도가 약 82퍼센트가 나왔습니다.
모델의 성능을 조금 더 자세히 살펴보기 위해 오답분석표를 관찰할 수 있습니다.
혼동행렬(Confusion matrix)는 모델 예측의 정오표를 한눈에 쉽게 관찰할 수 있게 해줍니다.
혼동행렬의 각 행은 정답 레이블을, 각 열은 예측 레이블을 의미합니다.
혼동행렬의 대각성분은 예측을 정확히 한 데이터의 개수를 나타냅니다.
또한 대각성분이 아닌 성분을 관찰하면 모델이 주로 어떤 레이블에서 오답을 범했는지 직관을 얻을 수 있습니다.
 7,000장의 이미지를 학습시킨 퍼셉트론 모델의 혼동행렬. 구멍이 없는 이미지를 구멍이 있다고 예측한 케이스(1행)가 상대적으로 많다.
7,000장의 이미지를 학습시킨 퍼셉트론 모델의 혼동행렬. 구멍이 없는 이미지를 구멍이 있다고 예측한 케이스(1행)가 상대적으로 많다.
이 모델은 약 82퍼센트의 정확도를 가지고 있습니다.
오답을 분석하면 구멍이 없는 (True label = 0) 데이터를 상당히 많이 틀렸다는 것을 알 수 있습니다.
