교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 빅데이터 기초 활용 역량 강화 (5/10~6/9) - 데이터 수집
- 강사: 조미정 강사님 (빅데이터, 머신러닝, 인공지능)
- 강의 계획:
1. 파이썬 언어 기초 프로그래밍
2. 크롤링 - 데이터 분석을 위한 데이터 수집(파이썬으로 진행)
3. 탐색적 데이터 분석, 분석 실습
- 분석은 파이썬만으로는 할 수 없으므로 분석 라이브러리/시각화 라이브러리를 통해 분석
4. 통계기반 데이터 분석
5. 미니프로젝트
1. 셀레니움 selenuium 라이브러리
셀레니움 라이브러리의 개념
- 웹브라우저를 제어하는 라이브러리
- requests로는 동적 웹의 데이터를 받아오지 못하기 때문에 그런 경우 셀레니움을 사용함
- 웹브라우저를 직접 제어하여 검색, 버튼입력 등을 수행하고 현 위치의 데이터를 받아올 수 있음
실습 - 셀레니움 사용해보기
환경 세팅
(버전4 미만일 경우 따로 크롬 브라우저를 설치하는 작업이 필요함)
!pip install selenium !pip install webdriver_manager from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager driver = webdriver.Chrome(service=Service(ChromeDriverManager().install())) from bs4 import BeautifulSoup경고발생시 아래 코드로 무시할 수 있음
from selenium.webdriver.chrome.options import Options import warnings chrome_options = Options() chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"]) # 셀레니움 로그 무시 warnings.filterwarnings("ignore", category=DeprecationWarning) # Deprecated warning 무시웹 페이지 접근
url = "https://www.starbucks.co.kr/menu/product_list.do" # 동적 웹페이지인 스타벅스 MD페이지를 사용 driver = webdriver.Chrome("c;/chromedriver.exe") driver.get(url) # requests.get와 같은 역할페이지 소스 받아오기
html = driver.page_source #페이지소스를 가져와서 html 변수에 넣음BeautifulSoup으로 파싱
soup = BeautifulSoup(html, "lxml") #파싱 products = soup.select("li.menuDataSet dd") #태그값으로 상품명 찾기 # request로는 받아지지 않았던 데이터를 받아올 수 있음
실습 - 셀레니움으로 네이버 검색창에 key input 해보기
- 환경 세팅 및 웹페이지 열기
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup url = "http://naver.com" driver = webdriver.Chrome("c:/chromedriver.exe") driver.get(url)
- 네이버 메인 검색창 찾기
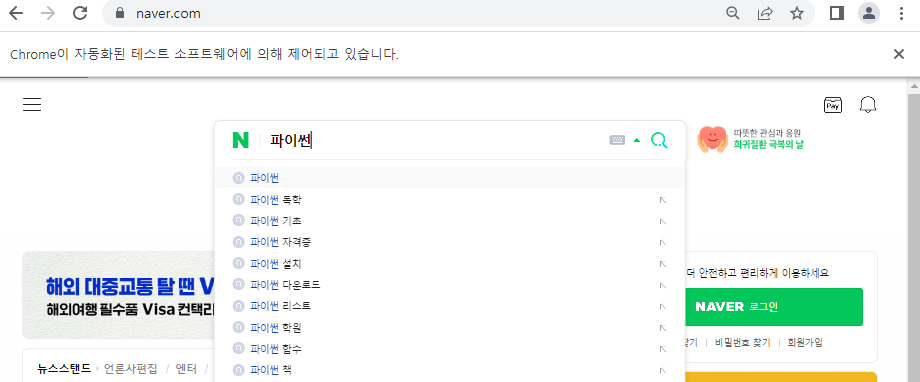
search = driver.find_element(By.CSS_SELECTOR, "input#query")
- 검색창에 "파이썬"입력
search.send_keys("파이썬")
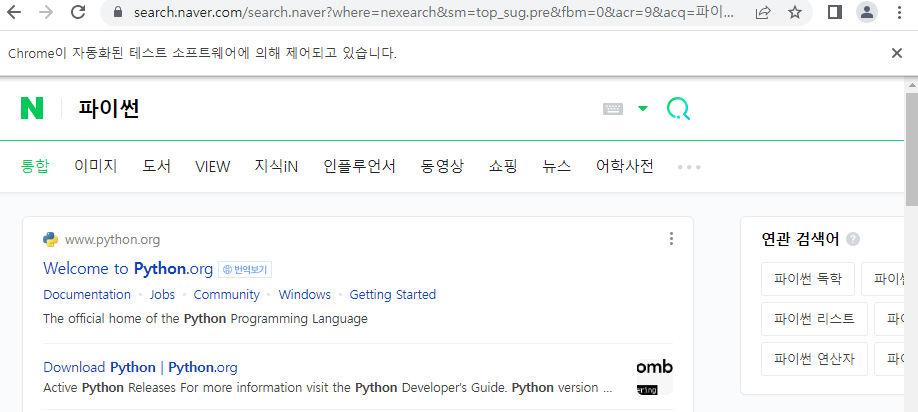
- 검색창에서 엔터를 누름
search.send_keys(Keys.ENTER)
→ 코드 실행시마다 실제 웹 브라우저가 제어되는 것을 확인 할 수 있음

:D