교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 빅데이터 분석을 위한 기획과 탐색(5/10~5/24) - 데이터 수집
- 강사: 조미정 강사님 (빅데이터, 머신러닝, 인공지능)
- 강의 계획:
1. 파이썬 언어 기초 프로그래밍
2. 크롤링 - 데이터 분석을 위한 데이터 수집(파이썬으로 진행)
3. 탐색적 데이터 분석, 분석 실습
- 분석은 파이썬만으로는 할 수 없으므로 분석 라이브러리/시각화 라이브러리를 통해 분석
4. 통계기반 데이터 분석
5. 미니프로젝트
1. 네이버 쇼핑 상품 검색 데이터 수집
네이버 쇼핑 상품 검색 사이트에서 검색어를 넣고 검색된 내용을 크롤링 해보기
: https://shopping.naver.com/home 에서 상품정보 크롤링
- 브라우저 열기
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup url = "https://shopping.naver.com/home" driver = webdriver.Chrome(service = Service(ChromeDriverManager().install())) driver.get(url)
- 검색어 넣고 엔터
search = driver.find_element(By.CSS_SELECTOR, "._searchInput_search_text_3CUDs") srchwrd = input("검색어 :") search.send_keys(srchwrd) search.send_keys(Keys.ENTER)
- 스크롤 높이 (scrollY)가 더이상 변하지 않을때까지 내린 다음에 데이터를 수집하고자 함
- execute_script → 자바스크립트를 사용해서 페이지 제어 가능
import time past_h = driver.execute_script("return window.scrollY") #현재 스크롤 놓이를 저장 while True: driver.find_element(By.CSS_SELECTOR, "body").send_keys(Keys.PAGE_DOWN) #스크롤 다운 time.sleep(1) #로딩시간 1초 - 로딩 안돼서 그냥 break 될 수 있음 new_h = driver.execute_script("return window.scrollY") if new_h == past_h: break #스크롤 위치 이동이 없으면(전후높이가 같으면) break past_h = new_h # 스크롤 높이가 바뀌었으면 past_h 갱신
- 페이지 소스를 가져와서 각 아이템의 이름과 가격 리스트를 가져오기
html = driver.page_source soup = BeautifulSoup(html, "lxml") item_list = soup.select(".basicList_list_basis__uNBZx > div > div") #item을 리스트로 가지고 와서 #for 문으로 아이템을 하나씩 꺼내서 이름과 가격을 찾아 리스트에 넣기 item_title_list = [] item_price_list = [] for item in item_list: item_title_list.append(item.select_one("div.basicList_title__VfX3c > a").text) try: item_price_list.append(item.select_one("span.price_num__S2p_v").text) except: item_price_list.append("None") #판매 중단 된 경우 가격이 없어서 예외처리 item_title_price_list = [] for i in zip(item_title_list, item_price_list): item_title_price_list.append(i) #이름과 가격 정보를 tuple 형태로 저장
2. 지마켓 베스트 셀러 상품 데이터 수집
지마켓 베스트 셀러 상품 전체를 클릭해서 상세페이지 크롤링 해보기
: https://corners.gmarket.co.kr/Bestsellers
: 모든 상품에 대해 이미지를 클릭 -> 상세페이지에서 상품명, 가격, 카테고리 크롤링
- 브라우저 열기
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup import pandas as pd url = "https://corners.gmarket.co.kr/Bestsellers" driver = webdriver.Chrome(service = Service(ChromeDriverManager().install())) driver.get(url)
- 이미지 200개 다 나오도록 스크롤
import time past_h = driver.execute_script("return window.scrollY") while True: driver.find_element(By.CSS_SELECTOR, "body").send_keys(Keys.PAGE_DOWN) time.sleep(1) new_h = driver.execute_script("return window.scrollY") if new_h == past_h: break past_h = new_h
- 이미지 찾기
- 클래스 명에 스페이스가 있으면 .으로 대체 해줘야 함!!!
images = driver.find_elements(By.CSS_SELECTOR, "div.thumb") print(len(images)) #이미지의 갯수 확인해서 실제 페이지와 비교, 본 사이트에서는 200개
- 200개의 이미지를 for문돌려서 하나씩 상세 페이지로 들어감
title_list = [] price_list = [] category_list = [] for i in range(len(images)): thumb = driver.find_elements(By.CSS_SELECTOR, "div.thumb") #이미지를 선택하고 thumb[i].click() #이미지를 클릭하여 상세페이지로 이동 detail_page = driver.page_source #상세페이지의 소스를 받아서 soup = BeautifulSoup(detail_page, "lxml") title_list.append(soup.select_one(".itemtit").text) price_list.append(soup.select_one(".price_real").text) category_list.append(soup.select_one("li.on>a").text) #상세페이지 소스에서 상품명, 가격, 카테고리를 찾아 list에 담음 driver.back()📕 그냥 클릭하고 돌아오는(driver.back()) 방법 말고 새탭에서 여는 방법도 해보기!!
3. 네이버 이미지 검색 이미지 수집
네이버 이미지검색에서 검색어를 넣고 검색된 이미지들을 크롤링 해보기
: https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query=
- 필요한 라이브러리 import
from selenium import webdriver import time from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager import os크롤링 코드
초기 코드
kword = "햄스터" #input("키워드 :") url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query=" + kword driver = webdriver.Chrome(service = Service(ChromeDriverManager().install())) driver.get(url) time.sleep(3) images = driver.find_elements(By.CSS_SELECTOR, "._image._listImage") print(len(images)) #폴더 있는지 체크 img_path = "C:/Users/User/documents/hamster/" if not os.path.exists(img_path): # 폴더가 없으면 폴더 만들기 os.mkdir(img_path) print(f"{img_path} 폴더가 생성되었습니다.") else: print(f"{img_path} 경로에 폴더가 이미 존재합니다.") for i,image in enumerate(images): img_src = image.get_attribute("src") print(i+1, img_src) import urllib.request urllib.request.urlretrieve(img_src, f"{img_path}{kword}img{i+1}.png") print("다운로드 완료")썸네일 이미지의 소스를 확인해서 src 속성을 받아와서 파일을 다운로드 했는데
아래와 같이 받아와지지 않는 파일이 있음
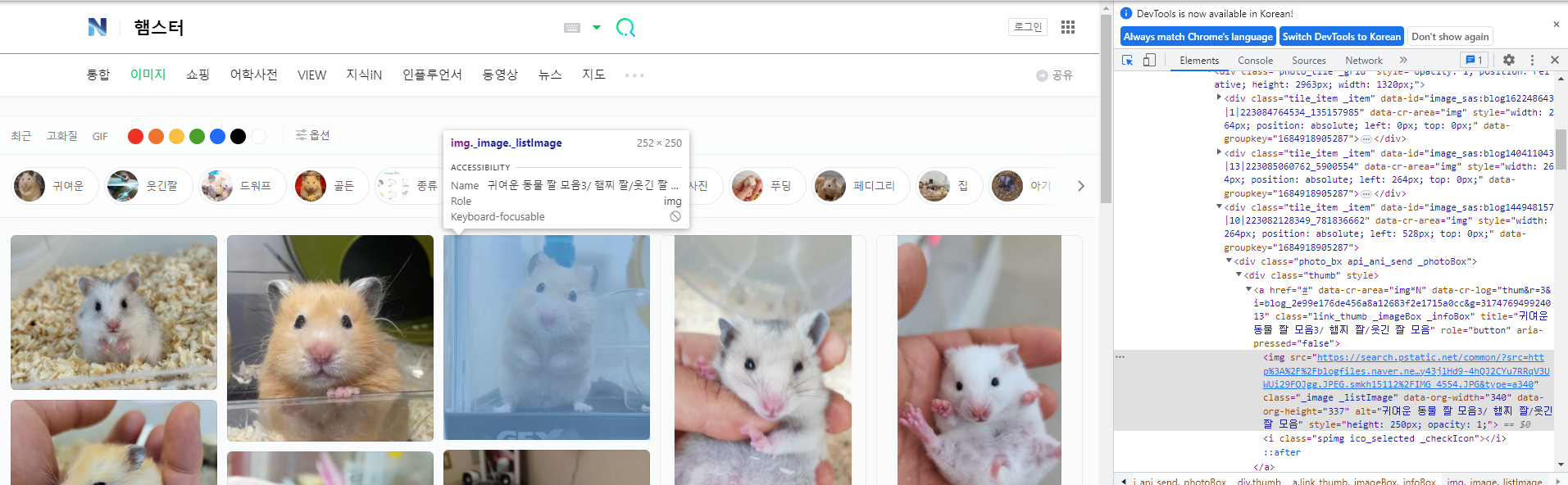

일부 수정 코드
kword = "햄스터" #input("키워드 :") url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query=" + kword driver = webdriver.Chrome(service = Service(ChromeDriverManager().install())) driver.get(url) time.sleep(3) driver.maximize_window() # 보이는것만 다운로드 하니까 화면을 최대로 키움 images = driver.find_elements(By.CSS_SELECTOR, "._image._listImage") print(len(images)) #폴더 있는지 체크 img_path = "C:/Users/User/documents/hamster/" if not os.path.exists(img_path): # 폴더가 없으면 폴더 만들기 os.mkdir(img_path) print(f"{img_path} 폴더가 생성되었습니다.") else: print(f"{img_path} 경로에 폴더가 이미 존재합니다.") for i,image in enumerate(images): img_src = image.get_attribute("src") print(i+1, img_src) import urllib.request urllib.request.urlretrieve(img_src, f"{img_path}{kword}img{i+1}.png") print("다운로드 완료")
화면에 보이는 이미지만 받아와진다는 가정을 화면을 최대로 키우면 기존 코드에 비해 많은 이미지가 받아와지지만 전체가 다 다운되지는 않음
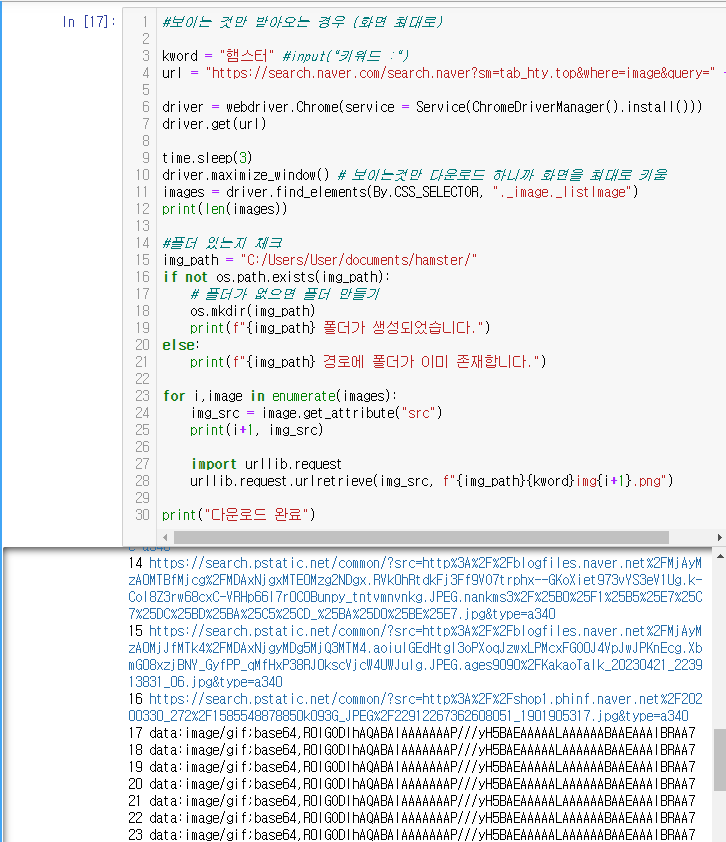
경로 재 확인
화면에 노출된 이미지는 src 속성에서 이미지 주소를 받아올 수 있지만
화면에 노출되지않은 이미지는 이렇게 소스코드가 로딩이 안된것을 확인
(로딩 안된 부분의 코드를 보면서 스크롤하면 해당 이미지가 로딩될때 소스 업데이트 됨)
→ 로딩 안된 이미지에는 data-lazy-src 속성에 링크가 담겨있음을 알 수 있음
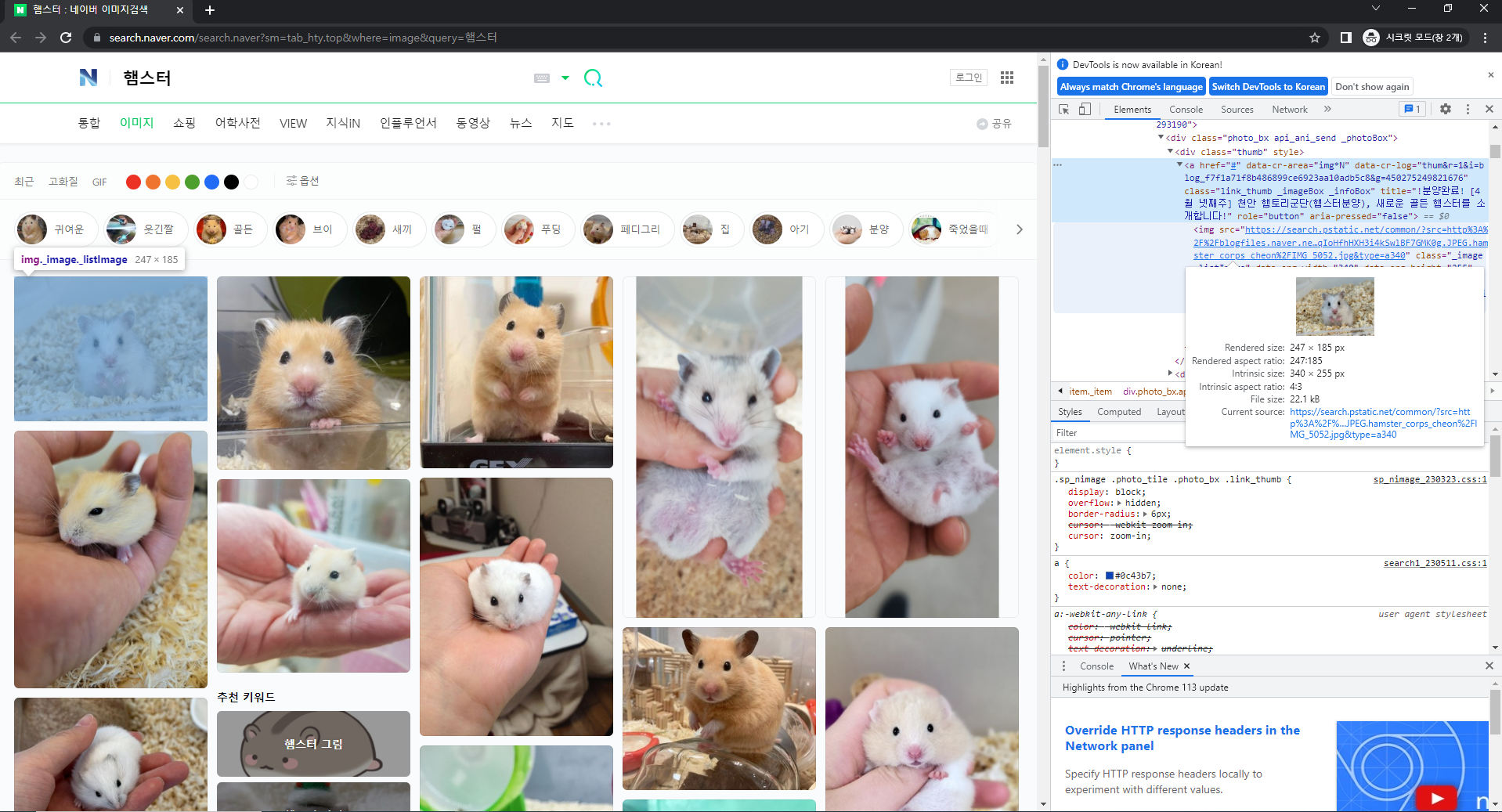
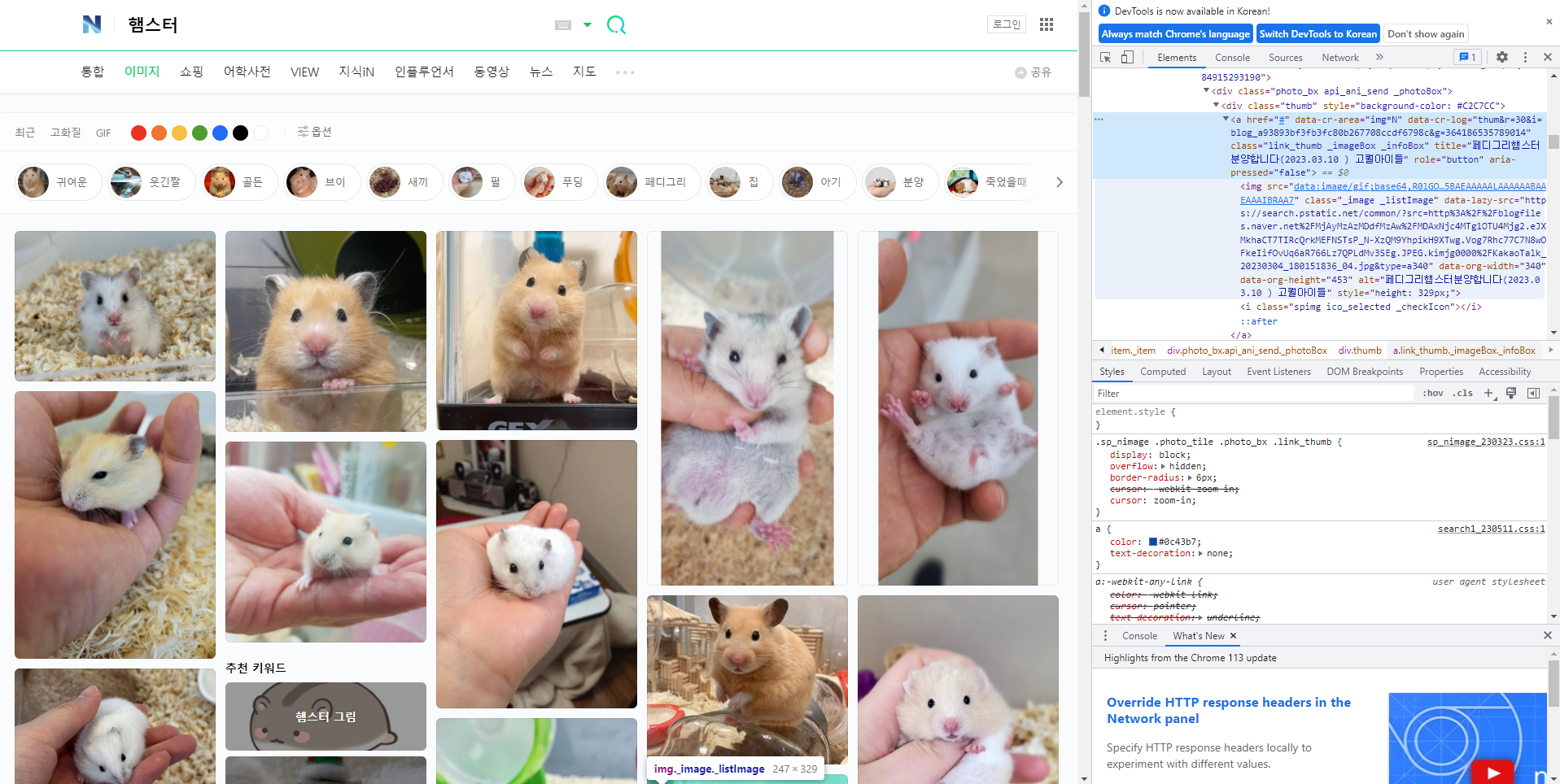
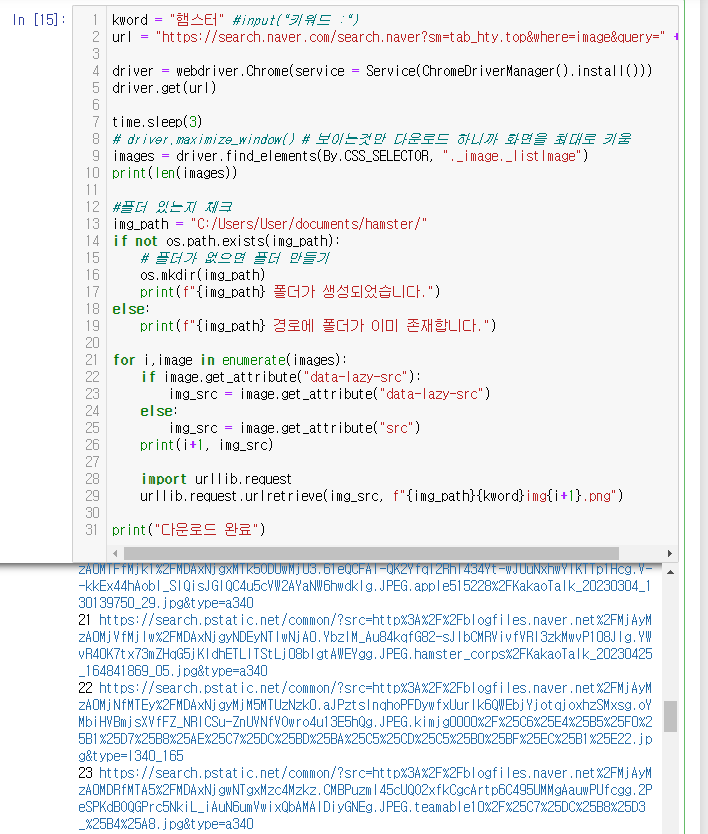
수정 후 코드
kword = "햄스터" #input("키워드 :") url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query=" + kword driver = webdriver.Chrome(service = Service(ChromeDriverManager().install())) driver.get(url) time.sleep(3) images = driver.find_elements(By.CSS_SELECTOR, "._image._listImage") print(len(images)) #폴더 있는지 체크 img_path = "C:/Users/User/documents/hamster/" if not os.path.exists(img_path): # 폴더가 없으면 폴더 만들기 os.mkdir(img_path) print(f"{img_path} 폴더가 생성되었습니다.") else: print(f"{img_path} 경로에 폴더가 이미 존재합니다.") for i,image in enumerate(images): if image.get_attribute("data-lazy-src"): img_src = image.get_attribute("data-lazy-src") else: img_src = image.get_attribute("src") print(i+1, img_src) import urllib.request urllib.request.urlretrieve(img_src, f"{img_path}{kword}img{i+1}.png") print("다운로드 완료")
data-lazy-src 속성 존재 여부에 따라 조건문을 설정한 결과 이미지가 모두 잘 받아와졌음

:D

대단 합니다 !