교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 빅데이터 기초 활용 역량 강화 (5/10~6/9) - 데이터 분석
- 강사: 조미정 강사님 (빅데이터, 머신러닝, 인공지능)
- 강의 계획:
1. 파이썬 언어 기초 프로그래밍
2. 크롤링 - 데이터 분석을 위한 데이터 수집(파이썬으로 진행)
3. 탐색적 데이터 분석, 분석 실습
- 분석은 파이썬만으로는 할 수 없으므로 분석 라이브러리/시각화 라이브러리를 통해 분석
4. 통계기반 데이터 분석
5. 미니프로젝트
1. 시각화
시각화 라이브러리
- matplotlib 라이브러리
matplotlib 공식 문서
- seaborn 라이브러리
- matplotlib을 기반으로 한 시각화 라이브러리
- 통계그래픽을 그리기 위한 고급 인터페이스 제공
- 다양한 색상과 차트를 지원
- 쉬운 사용성
seaborn 공식 문서
seaborn api - 차트 종류
📕 위 링크에서 Function interface탭을 보면 seaborn에서 지원하는 차트 종류를 확인 할 수 있음# import import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np import warnings warnings.filterwarnings('ignore')
Plots
lineplot
#pyplot x = [1,2,3,4,5,6] y = [1,2,3,4,5,6] y1 = [3,5,2,6,2,3] plt.plot(x,y,'--' , marker = 'v', label='man') plt.plot(x,y1,'--', marker = '.', label='woman') # 다양한 옵션이 사용 가능함 - 공식 문서 참고 plt.title("line plot") plt.xlabel("x value") plt.ylabel("y value") plt.legend() # 범례 plt.show() # 시각화된 자료만 깔끔하게 볼수 있음
# seaborn sns.lineplot(x = x,y = y) # x =, y = 을 필수로 넣어줘야 함 plt.show()
histogram
- 히스토그램은 연속형 변수의 값 또는 분포 형태를 보여줌
- 히스토그램을 사용하면 데이터 집합의 중심, 산포 및 형태를 볼 수 있음.
- 정규성을 확인하기 위한 시각적인 도구로도 활용
iris = sns.load_dataset('iris') # 많이 사용되는 데이터 셋 plt.hist(iris['sepal_width']) # default bins = 10 (구간 10등분, bins = 옵션에서 변경 가능) plt.show()
# seaborn sns.histplot(iris['sepal_width']) # 축이름on이 default
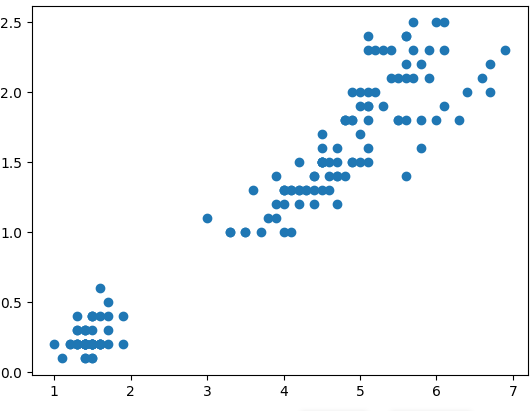
scatterplot(산점도)
- 두 연속형 변수들 사이의 상관관계
- 산점도를 통해 상관관계의 형식(선형, 비선형), 방향(양,음), 크기(강함, 약함)와 더불어 이상치(경향 밖의 값)의 존재 여부를 확인할 수 있음
#plt plt.scatter('petal_length', 'petal_width', data = iris) plt.show() #seaborn sns.scatterplot(x= 'petal_length', y= 'petal_width', data = iris) plt.show()
- hue옵션을 주면 차원을 하나 더 추가할 수 있음
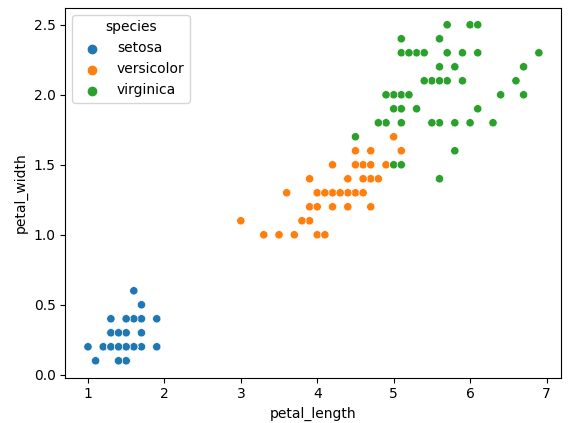
sns.scatterplot(x= 'petal_length', y= 'petal_width',hue='species', data = iris) plt.show()
- 위 그래프에서 hue값인 species에 따라 분포가 확연히 갈리므로 본 그래프가 species 구분에 적합함을 알 수 있음
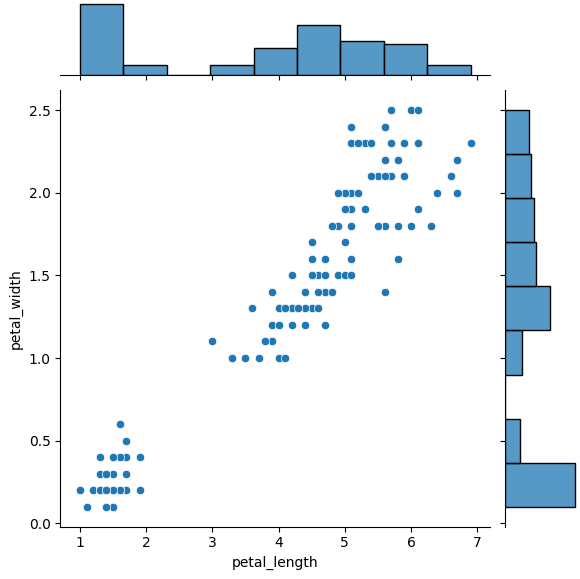
sns.jointplot
- 두 개의 수치형 변수간의 관계
- 차트의 중앙에 상관 관계 그래프 사용 ( 산점도, 헥스 빈 플롯, 히스토그램, kde)
- 그래프 상단과 오른쪽에 각 변수의 분포를 보여줌
sns.jointplot(x = 'petal_length' , y= 'petal_width', data = iris)
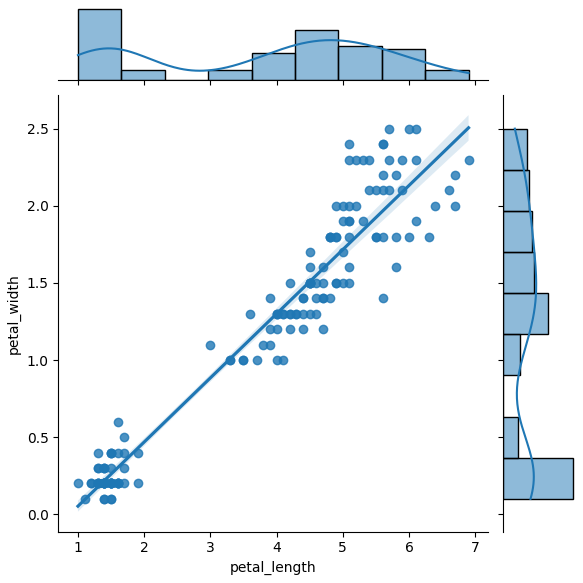
sns.jointplot(x = 'petal_length' , y= 'petal_width', data = iris, kind = 'reg') # kind 옵션을 사용하여 상관관계 그래프 종류 변경
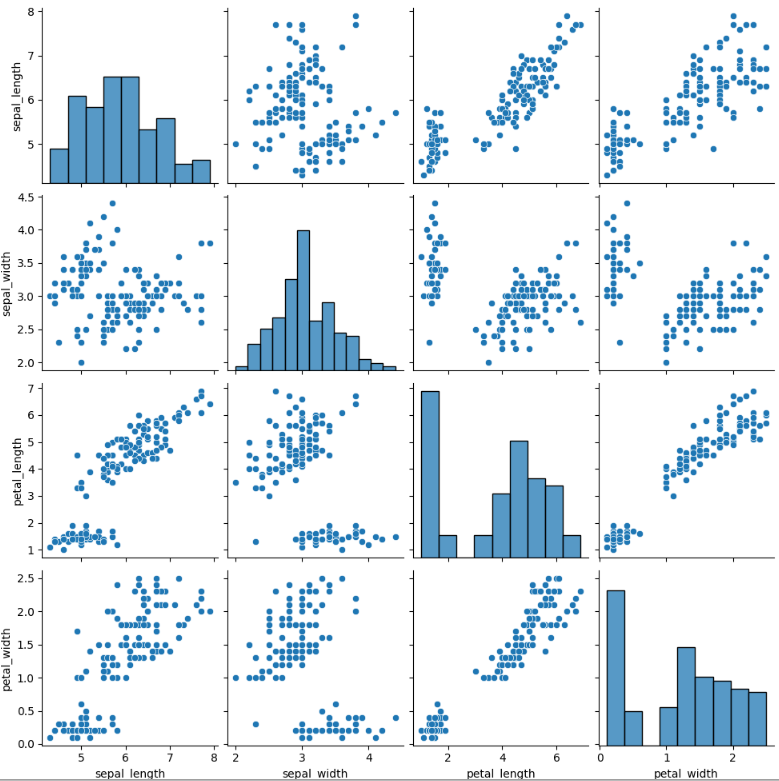
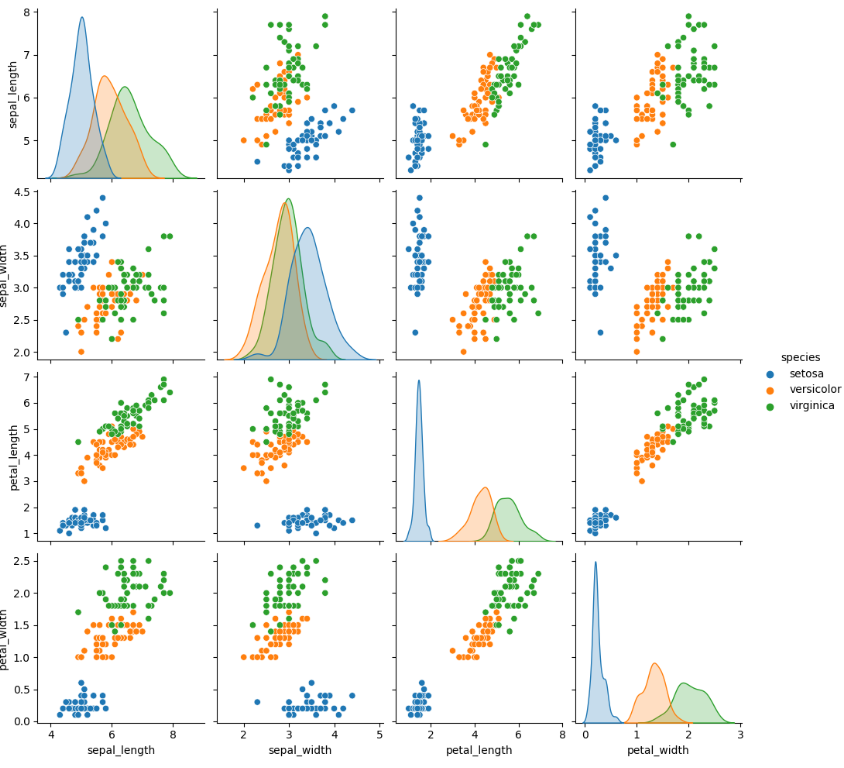
sns.pairplot
- pairplot은 데이터프레임을 인수로 받아 그리드(grid) 형태로 각 데이터 열의 조합에 대해 scatterplot을 그림
- 같은 데이터가 만나는 대각선 영역에는 해당 데이터의 히스토그램을 그림
sns.pairplot(iris) #좌상단에서 우하단으로 이어지는 대각선은 하나의 변수의 분포이고 나머지는 두 수치의 관계를 나타냄
hue 옵션을 사용해서 hue 항목에 영향을 주는 혹은 받는 특성이 무엇인지 시각적으로 확인 가능sns.pairplot(iris, hue = 'species')
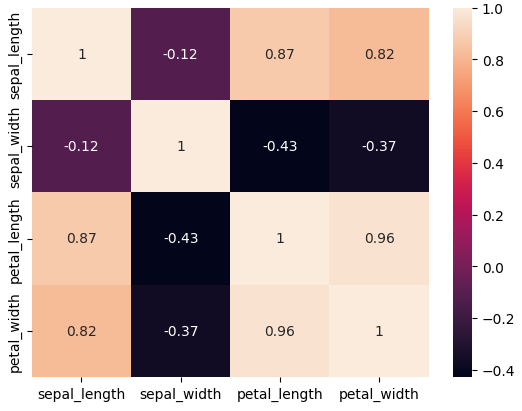
sns.heatmap
- 정사각형 그림에 데이터에 대한 정도 차이를 색 차이로 보여주는 plot
- 변수들 간의 상관관계를 알수 있다
- pairplot과 비슷하게 feature간 관계를 시각화할 때 많이 사용
corr = iris.corr() sns.heatmap(corr, annot = True) # 상관계수를 눈에 잘 보이게 하기 위해서 사용하는게 heatmap
subplots
- 하나의 figure안에 많은 axis와 plot을 넣고자할떄 subplot 사용
plt.subplot, plt.subplots
- plt.subplot(row, col, idx) 📕 idx가 1부터 시작하니 주의
- 하나 생성 - plt.subplot
#plt.subplot 예 plt.subplot (2,1,1) plt.subplot (2,1,2) #빈 플롯 생성 (한개씩)
- 여러개 생성 - plt.subplots
#plt.subplots 예 fig,axis = plt.subplots(nrows = 2, ncols =1)
- 둘다 결과는 아래와 같음

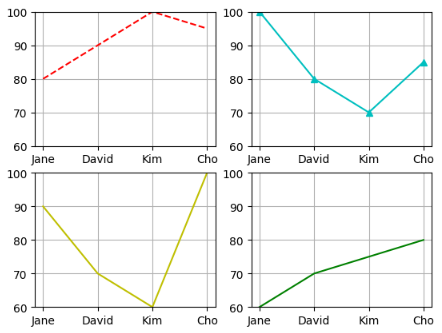
subplot 사용
import pandas as pd name = ["Jane", "David", "Kim", "Cho"] eng = [80, 90, 100, 95] kor = [100, 80, 70, 85] math = [90, 70, 60, 100] music = [60, 70, 75, 80] exam = {'name' : name, 'kor' : kor, 'eng' : eng, 'math' : math, 'music' : music} df = pd.DataFrame(exam) # 데이터를 df 변수에 저장 plt.subplot (2,2,1) plt.plot('name','kor','r--',data = df) plt.ylim(60,100) plt.grid() # 첫번째 그래프 (1 axes) plt.subplot (2,2,2) plt.plot('name','eng','c^-',data = df) plt.ylim(60,100) plt.grid() # 두번째 그래프 (2 axes) plt.subplot (2,2,3) plt.plot('name','math','y',data = df) plt.ylim(60,100) plt.grid() # 세번째 그래프 (3 axes) plt.subplot (2,2,4) plt.plot('name','music','g',data = df) plt.ylim(60,100) plt.grid() # 4번째 그래프 (4 axes)
for 문 + subplot
x= 'name' y= ['kor','eng','math','music'] fmt = ['r--','c^-','y','g'] for idx, subject in enumerate(y): plt.subplot(2,2,idx+1) plt.plot(x, subject, fmt[idx], data = df) plt.ylim(60,100) plt.grid() plt.show()
- 그래프를 하나씩 그렸을때와 동일한 결과를 가짐
subplots 사용
- 전체 프레임을 한 번에 지정하고 axes 값을 통해 각 그래프에 접근함
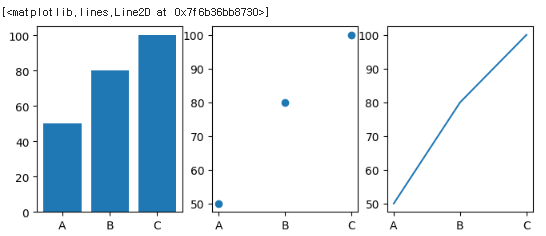
group = ['A', 'B', 'C'] score = [50,80,100] graphs = [plt.bar, plt.scatter, plt.plot] # subplots의 예 fig, axes = plt.subplots(1,3, figsize=(8,3)) # plt.subplots(1,3) 이부분에서 전체 프레임을 지정 # axes 는 전체 프레임(여기서는 plt.subplots(1,3))에서 몇번째 자리인지 지정 axes[0].bar(group, score) axes[1].scatter(group, score) axes[2].plot(group, score) #이미 지정된 자리에 axes[n]을 사용해서 접근, 그래프를 그림
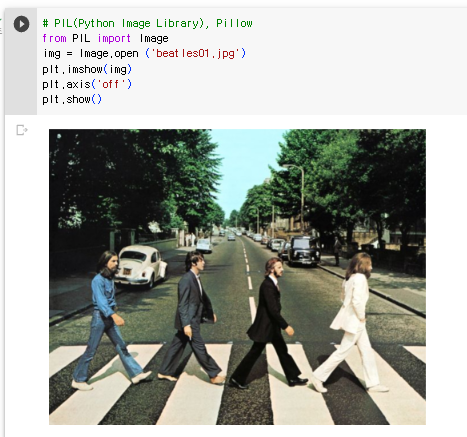
이미지
https://raw.githubusercontent.com/mjcho7/dataset/main/beatles01.jpg 이미지를 다운받아서 출력
# 이미지 다운로드 받기 # !wget !wget https://raw.githubusercontent.com/mjcho7/dataset/main/beatles01.jpg !pip install Pillow # PIL(Python Image Library), Pillow from PIL import Image img = Image.open ('beatles01.jpg') plt.imshow(img) plt.axis('off') # default로 축이 표시되므로 꺼줌 plt.show()
지도(folium)
- folium은 python에서 제공하는 지도를 다루는 대표적인 라이브러리
- 지도를 생성하고 Marker를 추가하여 시각화하거나 원으로 범위를 표기하고 html 파일로 내보내기 등을 수행할 수 있음
folium 공식문서# import import folium import json
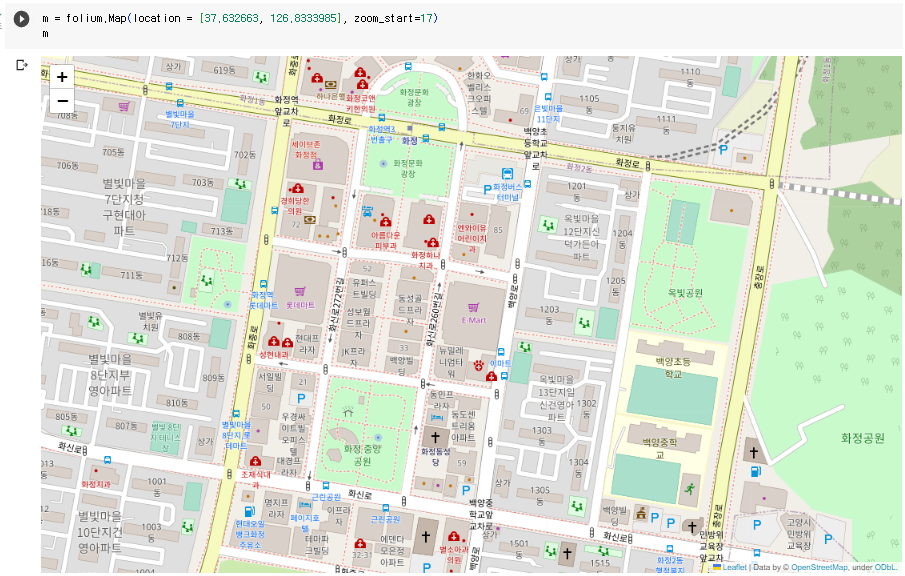
지도 띄우기 - folium.Map
- folium.Map(location=[위도, 경도], zoom_start=숫자)
- location은 지도의 기준이 될 위도와 경도의 좌표를 전달
m = folium.Map(location = [37.632663, 126.8333985], zoom_start=16) m
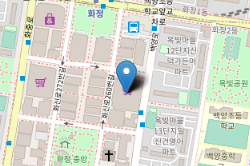
마커(Markers)
- folium.Marker([위도, 경도], ... ).add_to(지도)
- add_to()의 인수로는 우리가 만든 지도인 folium.Map() 객체를 전달
- Marker()의 인수로는 [위도, 경도] 이외에도 여러 옵션을 설정하여 마커를 표시할 수 있음
- location: 마커를 추가할 위도/경도 좌표를 입력
- popup: 표기할 팝업 문구 지정 (마우스 클릭시 표기되는 문구)
- tooltip: 표기할 툴팁 지정 (마우스 오버시 표기되는 문구)
- icon : 마커 아이콘 변경
tooltip='find it' folium.Marker([37.632663, 126.8333985], popup = '이마트 화정점', tooltip= tooltip).add_to(m) folium.Marker([37.6505496, 126.8388914], popup = '성라공원', tooltip= tooltip, icon=folium.Icon(color = 'red', icon='info-sign') ).add_to(m) m
GeoJson
- GeoJSON은 다양한 지리 데이터 구조를 JSON 형식으로 인코딩하기 위한 포맷.
- 애플리케이션에서 지리적 데이터 구조를 표현하고 통신 교환할 수 있도록 도와줌
- base url : https://raw.githubusercontent.com/python-visualization/folium/master/examples/data
- json : us-states.json
- data : US_Unemployment_Oct2012.csv
url = 'https://raw.githubusercontent.com/python-visualization/folium/master/examples/data' state_geo = f'{url}/us-states.json' state_csv = f'{url}/US_Unemployment_Oct2012.csv' df = pd.read_csv(state_csv) #해당 경로의 csv 파일을 df에 저장함!wget https://raw.githubusercontent.com/python-visualization/folium/master/examples/data/us-states.json #해당 경로의 jdon파일을 다운로드 함 # -> (json뷰어 활용)json파일 분석해서 위의 csv 파일과 매핑하고자 함 # -> 지도에서 csv의 unemployment에 접근 가능# df -> dictionary(or series) convert df_ser = df.set_index('State')['Unemployment'] # set_index 사용해서 state와 Unemployment를 시리즈로 만듦 print(type(df_ser)) df_serfrom branca.colormap import linear colormap = linear.YlGnBu_09.scale( df.Unemployment.min(), df.Unemployment.max() ) colormap #맵에서 사용할 칼라맵을 미리 설정
m= folium.Map(location= [43,-100],zoom_start=4) #미국 중심을 기준으로 맵 생성 folium.GeoJson( state_geo, #제일 먼저 json파일 name = 'unemployment', style_function=lambda feature:{ 'fillColor':colormap(df_ser[feature['id']]), #채우기 색 미리 지정한 색을 df-ser의 데이터와 feature의 id를 기준으로 매핑해서 가져오기 #결국 저 괄호 안이 csv의 숫자와 같게 됨 ! 'weght': 1, # 경계선 ?? 'dashArray': '5,5', #경계선 선종류 'fillOpacity': 0.6 } ).add_to(m) #json파일 기초로 위치별 unemployment를 수치에 따라 색이 다르게 표현하고자 함 m

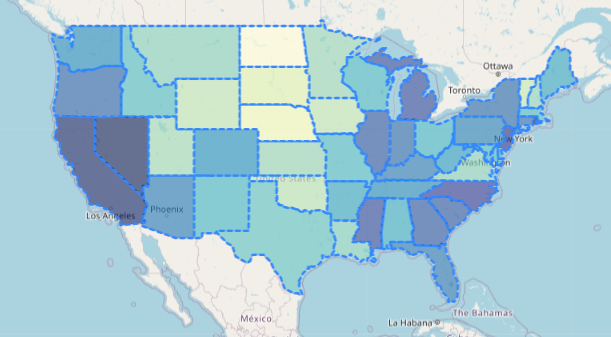
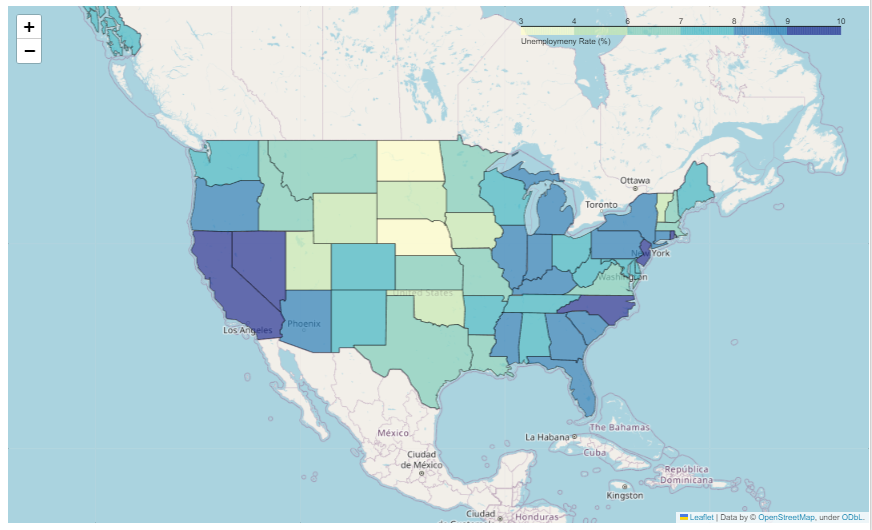
Choropleth
folium.Choropleth(
geo_data = "지도 데이터 파일 경로 (.geojson, geopandas.DataFrame)",
data = "시각화 하고자 하는 데이터파일. (pandas.DataFrame)",
columns = (지도 데이터와 매핑할 값, 시각화 하고자하는 변수),
key_on = "feature.데이터 파일과 매핑할 값", (앞에 feature는 고정임)
fill_color = "시각화에 쓰일 색상",
legend_name = "칼라 범주 이름",
).add_to(m)m= folium.Map(location= [43,-100],zoom_start=4) folium.Choropleth( geo_data = state_geo, data = df, columns=['State', 'Unemployment'], key_on = 'feature.id', fill_color = 'YlGnBu', fill_opacity = 0.7, line_opacity = 0.5, legend_name = 'Unemploymeny Rate (%)' ).add_to(m) m
{kind=link}

:D