교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 빅데이터 기초 활용 역량 강화 (5/10~6/9) - 데이터 분석
- 강사: 조미정 강사님 (빅데이터, 머신러닝, 인공지능)
- 강의 계획:
1. 파이썬 언어 기초 프로그래밍
2. 크롤링 - 데이터 분석을 위한 데이터 수집(파이썬으로 진행)
3. 탐색적 데이터 분석, 분석 실습
- 분석은 파이썬만으로는 할 수 없으므로 분석 라이브러리/시각화 라이브러리를 통해 분석
4. 통계기반 데이터 분석
5. 미니프로젝트
1. Pandas 연습
와인 리뷰 데이터를 활용한 예제
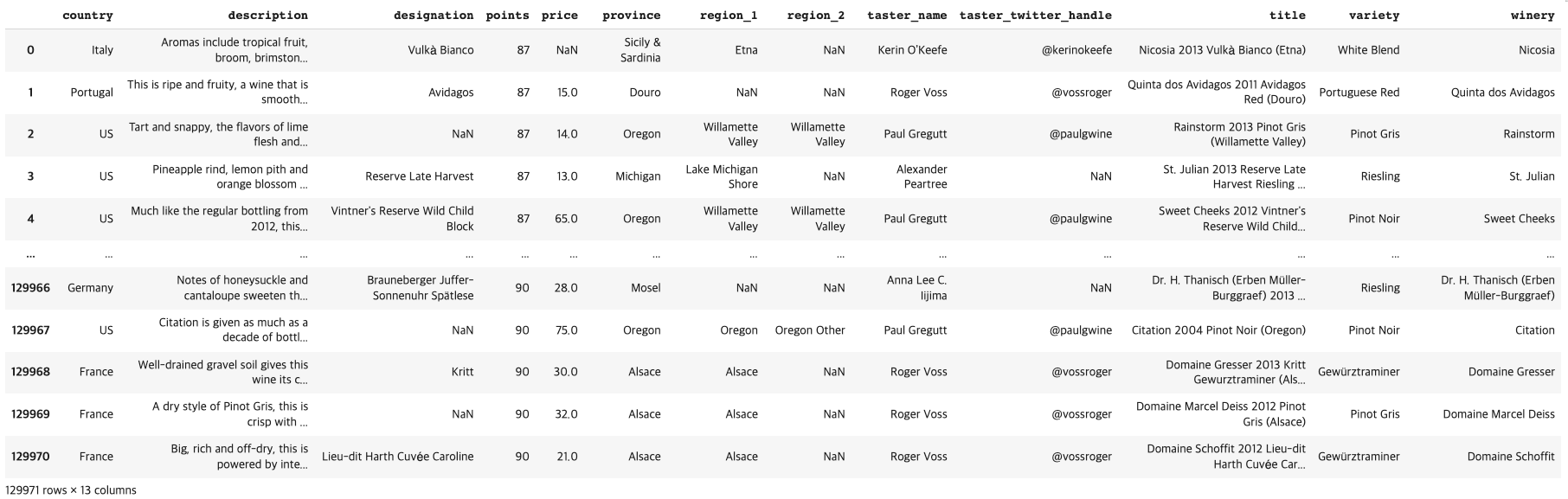
- points 가 95점 이상인 데이터는 총 몇 건인가요? 전체에서 비율은?
print(f"95점 이상: {(df['points']>=95).value_counts()[True]}") print(f"95점 이상 비율: {(df['points']>=95).value_counts()[True]/df['points'].shape[0]}") # #결과 95점 이상: 2416 95점 이상 비율: 0.018588762108470352
- 'province' 가 'Bordeaux'인 것에 참여한 'taster_name'들은 몇 명인가
(df[(df['province']=='Bordeaux')])['taster_name'].unique().shape[0] # #결과 4
- Australia 와 New Zealand 에서 만들어진 와인중에 points 가 95점 이상인 데이터를 선택하여 top_oceania_wines 변수에 할당하시오. 총 건수는?
oceania_wines = (df[(df['country'].isin(['Australia','New Zealand']))]) top_oceania_wines = oceania_wines[(oceania_wines['points']>=95)] top_oceania_wines.shape[0] # top_oceania_wines # #결과 49
- 나라별로 몇개의 리뷰가 존재하는지 계산하여 출력 하시오
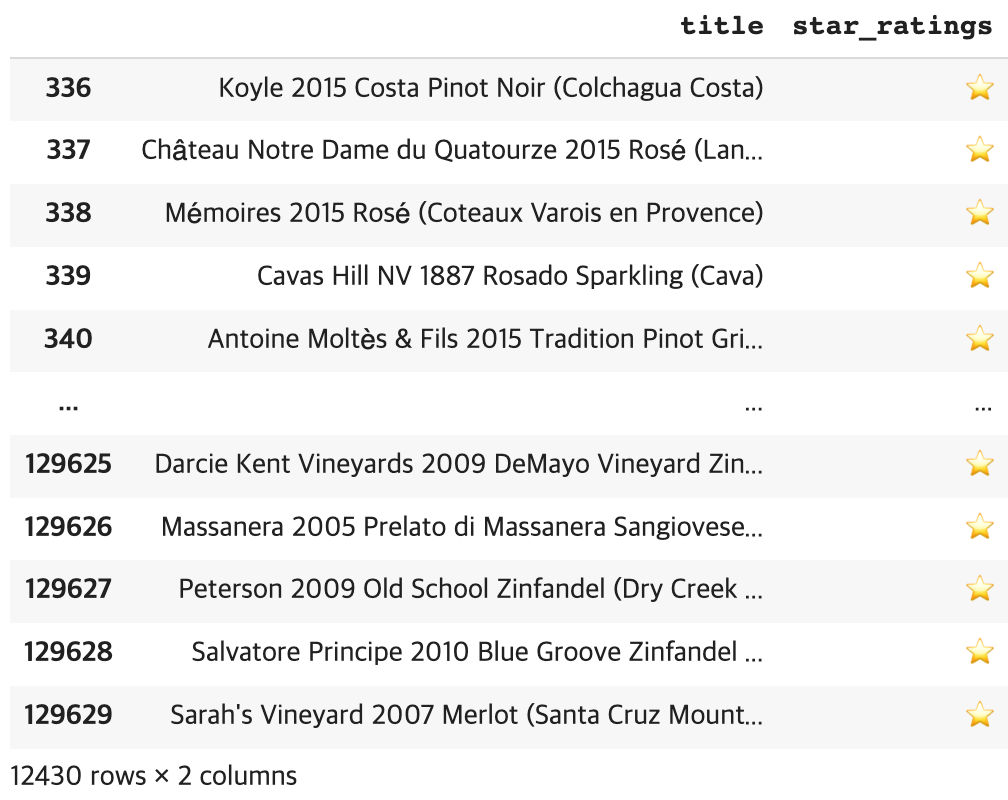
df['country'].value_counts() # #결과 US 54504 France 22093 Italy 19540 Spain 6645 Portugal 5691 Chile 4472 Argentina 3800 Austria 3345 Australia 2329 Germany 2165 New Zealand 1419 South Africa 1401 Israel 505 Greece 466 Canada 257 Hungary 146 Bulgaria 141 Romania 120 Uruguay 109 Turkey 90 Slovenia 87 Georgia 86 England 74 Croatia 73 Mexico 70 Moldova 59 Brazil 52 Lebanon 35 Morocco 28 Peru 16 Ukraine 14 Serbia 12 Czech Republic 12 Macedonia 12 Cyprus 11 India 9 Switzerland 7 Luxembourg 6 Bosnia and Herzegovina 2 Armenia 2 Slovakia 1 China 1 Egypt 1 Name: country, dtype: int64-point 점수가 95점 이상은 별 3개 85점 이상 95점 미만은 별 2개 나머지는 별 1개 가 되도록 별점을 매기고 star_ratings 칼럼에 해당 값을 할당 하시오
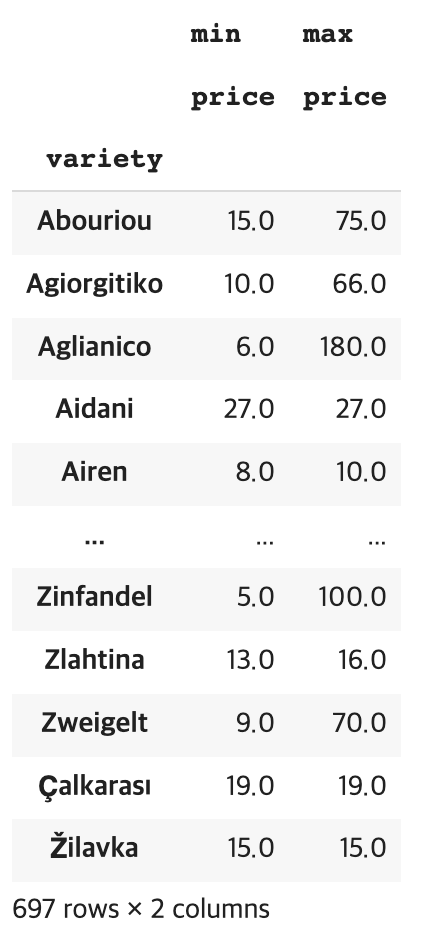
def rating(point): if point >= 95: return "⭐️⭐️⭐️" elif point >= 85: return "⭐️⭐️" else: return "⭐️" df['star_ratings'] = df["points"].apply(rating) df['star_ratings'] df.loc[df['star_ratings']=="⭐️⭐️⭐️",['title','star_ratings']] df[df['star_ratings']=="⭐️"][['title','star_ratings']]- 와인의 종류인 'variety'컬럼을 기준으로 와인 종류 별 'min', 'max' 가격을 price_extremes 변수에 할당 하시오
price_extremes = df.pivot_table(index='variety',values= 'price',aggfunc=[min,max]) price_extremes # 그룹바이 쓰면 # price_extremes = df.groupby('variety')['price'].agg(['min','max']) # price_extremes
급여 데이터를 활용한 예제
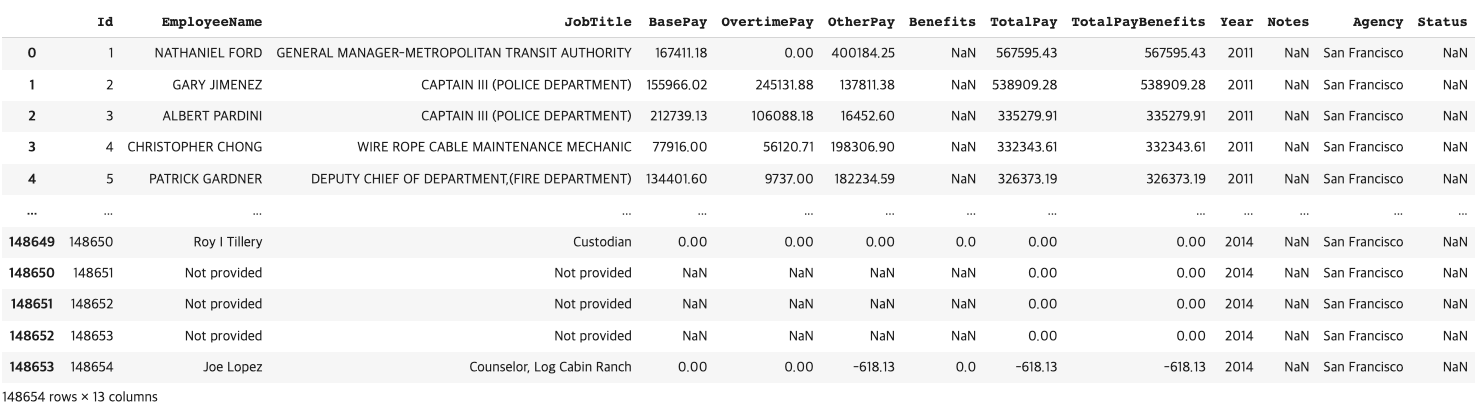
- 직원이름('EmployeeName')이 'Miranda A Moffitt' 인 사람의 직책('job title')은 무엇인가?
df.loc[(df['EmployeeName']=='Miranda A Moffitt'),['JobTitle']]
- 가장 많은 급여('TotalPayBenefits')를 받은 사람은 누구인가?
print(df.loc[(df['TotalPayBenefits'] == df['TotalPayBenefits'].max()),['EmployeeName']]) print(type(df.loc[(df['TotalPayBenefits'] == df['TotalPayBenefits'].max()),['EmployeeName']])) #idxmax없이 조건식을 사용 (dataframe 타입) print(df['EmployeeName'][df['TotalPayBenefits'].idxmax()]) print(type(df['EmployeeName'][df['TotalPayBenefits'].idxmax()])) #최대값의 index를 출력하는 idxmax함수를 사용 (str 타입) # #결과 EmployeeName 0 NATHANIEL FORD <class 'pandas.core.frame.DataFrame'> NATHANIEL FORD <class 'str'>
- 연도('Year')별로 전체 직원들의 기본급 평균은 얼마씩인가?
base_pay_by_year=df.groupby('Year')['BasePay'].mean() print(base_pay_by_year) # #결과 Year 2011 63595.956517 2012 65436.406857 2013 69630.030216 2014 66564.421924 Name: BasePay, dtype: float64
- 가장 많은 직무('JobTitle') 상위 5개는 무엇인가?
(df['JobTitle'].value_counts()).sort_values(ascending = False)[0:5] # #결과 Transit Operator 7036 Special Nurse 4389 Registered Nurse 3736 Public Svc Aide-Public Works 2518 Police Officer 3 2421 Name: JobTitle, dtype: int64
- 2013년도에 유일하게 직무자가 1명이었던 직무('JobTitle')는 몇 개인가?
df_2013= df[df['Year'] == 2013].groupby('JobTitle')['jobTitle'].count() df_2013[year_2013_employes==1].shape[0] #결과 202
- 직무('JobTitle')에 'Chief'가 들어가는 사람은 몇 명인가?(대소문자 구분 X)
df[df['JobTitle'].apply(lambda x : x.lower()).str.contains('chief') ] df[df['JobTitle'].str.contains('chief',case=False)] #대소문자 구분 case 옵션으로 줄 수 있음


:D