교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 빅데이터 기초 활용 역량 강화 (5/10~6/9) - 데이터 분석
- 강사: 조미정 강사님 (빅데이터, 머신러닝, 인공지능)
- 강의 계획:
1. 파이썬 언어 기초 프로그래밍
2. 크롤링 - 데이터 분석을 위한 데이터 수집(파이썬으로 진행)
3. 탐색적 데이터 분석, 분석 실습
- 분석은 파이썬만으로는 할 수 없으므로 분석 라이브러리/시각화 라이브러리를 통해 분석
4. 통계기반 데이터 분석
5. 미니프로젝트
탐색적 데이터 분석 - 공공자전거 현황 분석
개요
목적
대여소그룹별(자치구) 자전거 대여건수 파악
대여건수가 많은 상위의 대여소 파악
월별 자전거 대여수 비교 분석
이동거리/평균사용시간이 높은 대여소 파악
요일별 연령대별 평균 사용시간 비교
구별 거치대 분포 현황(구별 설치 거치대 개수) 파악과 지도 시각화
데이터
서울열린 데이터 광장
따릉이데이터
Data1 : 서울특별시 공공자전거 대여소 정보
http://data.seoul.go.kr/dataList/OA-13252/F/1/datasetView.do
파일 : 공공자전거 대여소 정보(21.06월 기준).xlsx
대여소이름, 관리번호, 위치정보, 거치대수 정보제공
Data2 : 서울특별시 공공자전거 대여소별 이용정보(월별)
http://data.seoul.go.kr/dataList/OA-15249/F/1/datasetView.do
파일 : 공공자전거 대여소별 이용정보_21.02~21.06.csv
서울특별시 공공자전거 대여소별 대여, 반납정보
년월, 대여소번호, 대여소명, 대여건수, 반납건수
Data3 : 서울특별시 공공자전거 이용정보(시간대별)
http://data.seoul.go.kr/dataList/OA-15245/F/1/datasetView.do
다운로드 : 서울특별시 공공자전거 이용정보(시간대별)_2021년.zip
파일 : 서울특별시 공공자전거 이용정보(시간대별)_21.06.csv
대여일시, 대여시간, 대여소번호, 대여소명, 정기권유무, 성별, 연령대, 탄소량, 이동거리, 이동시간
0. 한글 사용 설정
#글꼴 설치
!sudo apt-get install -y fonts-nanum # 나눔폰트 설치
!sudo fc-cache -fv # 폰트가 캐시에 저장되므로 위에서 설치한 폰트가 적용되도록 폰트 캐시 재 조성
!rm ~/.cache/matplotlib -rf # matplotlib의 폰트 캐시를 삭제
#이거 한 다음에 런타임을 재시작 해야함 (런타임-다시시작)
# 라이브러러 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
# font 설정
plt.rc('font', family='NanumBarunGothic')
# 한글 깨짐 테스트
plt.scatter([0, 1, 2, 3, 4, 5], [0, 1, 2, 3, 4, 5])
plt.title('산점도')
plt.xlabel('키')
plt.ylabel('몸무게')
plt.show()
from google.colab import drive
drive.mount('/content/drive')1. 데이터 불러오기
!wget https://raw.githubusercontent.com/mjcho7/dataset/main/public_bicycle.zip -O public_bicycle.zip
# 압축 풀기
import zipfile
zipfile.ZipFile('public_bicycle.zip').extractall()
#데이터 불러오기
import pandas as pd
bk_df1 = pd.read_csv('공공자전거 대여소 정보(21.06월 기준).csv', encoding='cp949')
bk_df2 = pd.read_csv('공공자전거 대여소별 이용정보_21.02_21.06.csv' ,encoding='cp949')
bk_df3 = pd.read_csv('공공자전거 이용정보(시간대별)_21.06.csv',encoding='cp949')2. Preview
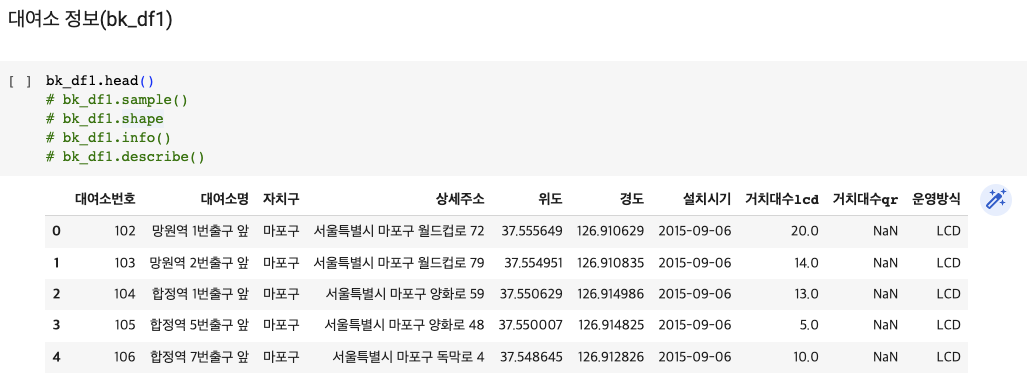
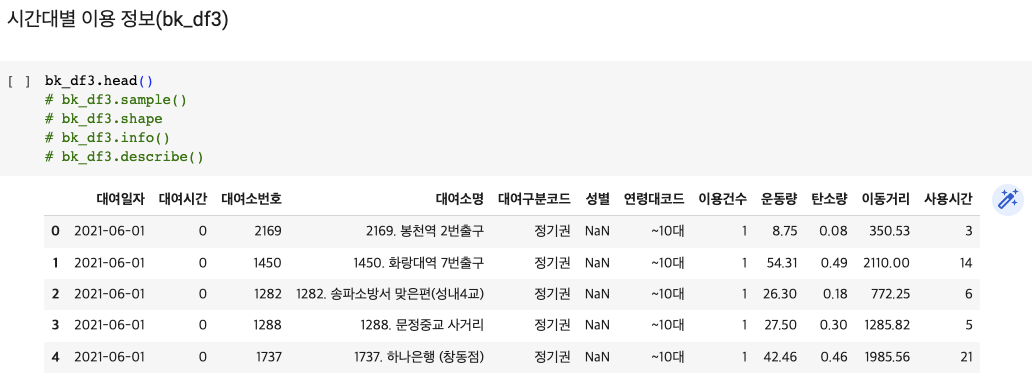
데이터 미리보기 : df.head() , df.tail(), df.sample()
데이터 건수 확인 : df.shape
데이터 컬럼,컬럼type 확인 : df.info()
데이터 분포 정보 : df.describe()

key 컬럼
- 세 데이터 프레임이 공통적으로 대여소 번호 컬럼을 가지므로 key 컬럼으로 사용
전처리 - 전체: 대여소 번호는 object로 통일
- bk_df1
- 총 거치대 수 컬럼 추가
- bk_df2
- 대여 일자, 월 변경 (float->object, daytime)
- 대여소 명에서 대여소 번호 추출
- bk_df3:
- 대여 일자 daytime으로 변경, 파생변수 생성
- 대여소 명에서 대여소 번호 추출
3. 전처리
bk_df1
- 결측치 처리
bk_df1.isnull().sum()
#
#결과
대여소번호 0
대여소명 0
자치구 0
상세주소 0
위도 0
경도 0
설치시기 0
거치대수lcd 1013
거치대수qr 1453
운영방식 0
dtype: int64결측치가 거치대 수에만 있으나 추후 총 거치대수 칼럼을 만들것이므로 넘어감
- 대여소번호 변환
bk_df1['대여소번호'] = bk_df1['대여소번호'].astype('str')#str, object 다 되는듯
bk_df1.info()
#
# 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2467 entries, 0 to 2466
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 대여소번호 2467 non-null object
1 대여소명 2467 non-null object
2 자치구 2467 non-null object
3 상세주소 2467 non-null object
4 위도 2467 non-null float64
5 경도 2467 non-null float64
6 설치시기 2467 non-null object
7 거치대수lcd 2467 non-null float64
8 거치대수qr 2467 non-null float64
9 운영방식 2467 non-null object
dtypes: float64(4), object(6)
memory usage: 192.9+ KBbk_df2
- 결측치 처리
bk_df2.isnull().sum()
bk_df2[bk_df2['대여소 그룹'].isnull()] 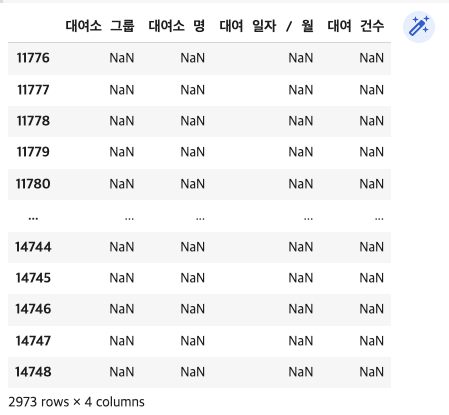
11776 ~ 14748 가 전부 비었으며 그 위쪽으로는 결측치 없으므로 해당 행을 drop
bk_df2=bk_df2.dropna()
# 해당하는 모든 행의 전체 값이 비어있으므로 조건없이 drop 가능- 대여소번호와 대여소명 분리하기
bk_df2['대여소번호'] = bk_df2['대여소 명'].str.split('.',expand=True)[0] #expand 쓰면 칼럼형태 안쓰면 리스트로 출력해줌
bk_df2['대여소명_new'] = bk_df2['대여소 명'].str.split('.',expand=True)[1]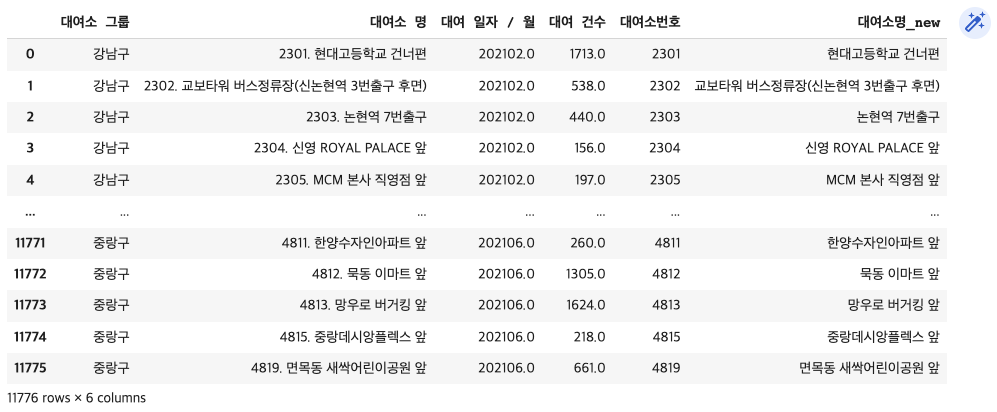
새로 만든 컬럼에 결측치 확인
bk_df2.isnull().sum()
#
#결과
대여소 그룹 0
대여소 명 0
대여 일자 / 월 0
대여 건수 0
대여소번호 0
대여소명_new 29
dtype: int64대여소 명에 결측치 있음 → 확인하고 채워주기
bk_df2[bk_df2['대여소명_new'].isnull()]
bk_df2[bk_df2['대여소 그룹']=='정비센터']
#결측치 있는 행 확인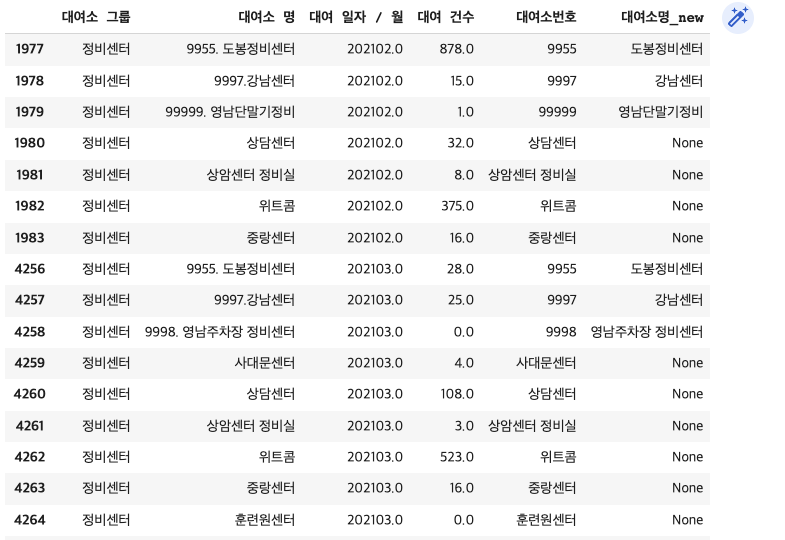
대부분 대여소 그룹이 정비센터인 경우라서 정비센터값을 가지는 행을 처리 (예외 1건 drop)
# 인덱스 저장 (조건에 의해 불러온 값이므로 일괄 처리 및 추후 확인에 필요)
null_index = bk_df2[bk_df2['대여소명_new'].isnull()].index
len(null_index)
null_index
bk_df2.loc[null_index]
# 대여소명_new <- 대여소번호
bk_df2.loc[null_index, '대여소명_new'] = bk_df2['대여소번호']
bk_df2.loc[null_index]
# 대여소 번호 <- 9999
bk_df2.loc[null_index, '대여소번호'] = 9999
bk_df2.loc[null_index]
# 대여소그룹 '그룹명 없음' drop
bk_df2.drop(2234, inplace=True)- 대여일자/월 변환
bk_df2['대여 일자 / 월'] = bk_df2['대여 일자 / 월'].astype(str)
bk_df2['대여 일자 / 월'] = bk_df2['대여 일자 / 월'].str[:6]bk_df3
- 결측치 처리
bk_df3.isnull().sum()
#
#결과
대여일자 0
대여시간 0
대여소번호 0
대여소명 0
대여구분코드 0
성별 1151099
연령대코드 0
이용건수 0
운동량 0
탄소량 0
이동거리 0
사용시간 0
dtype: int64결측된 항목이 많고 예측이 불가능하므로 있는 값만 정리
bk_df3['성별'].value_counts()
#
#결과
M 871251
F 593525
m 502
f 221
Name: 성별, dtype: int64# 대문자로 통일 (다 대체하거나 없앨수는 없음)
# f --> F , m --> M
bk_df3.loc[bk_df3['성별']=='f', '성별'] = 'F'
bk_df3.loc[bk_df3['성별']=='m', '성별'] = 'M'
bk_df3['성별'].unique()
#
#결과
array([nan, 'F', 'M'], dtype=object)
# nan, F, M 만 남은것을 확인할 수 있음 - 이상치 확인
bk_df3.describe().round()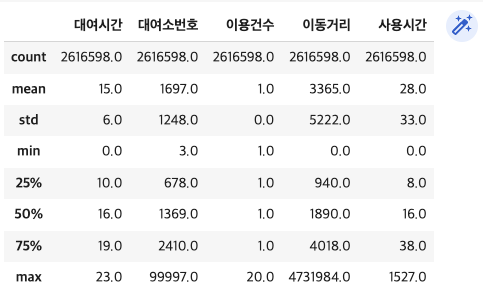
max값에서 이상치 확인 가능
boxplot을 그려보면
sns.boxplot(bk_df3['이동거리'])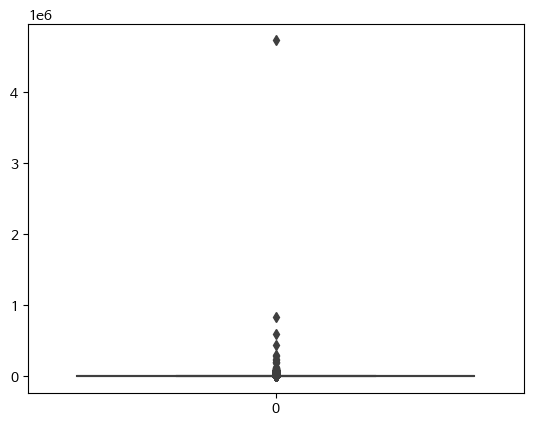
아주 큰 이상치가 있음
bk_df3[bk_df3['이동거리'] > 1000000]
#이상치 찾아서
print(bk_df3.shape)
bk_df3.drop(1763924, inplace=True)
print(bk_df3.shape)
# Drop
하지만 박스플롯 다시 그려보면 여전히 이상치가 있음
sns.boxplot(bk_df3['이동거리'])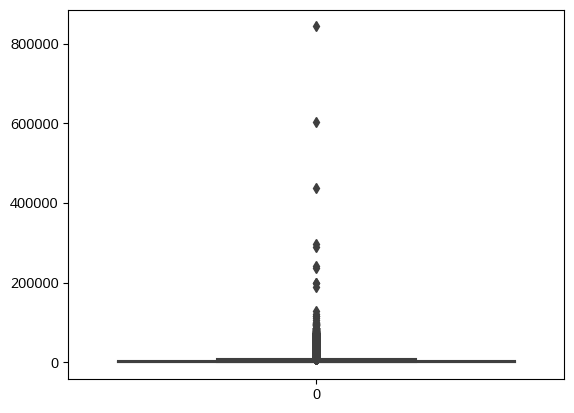
→IQR 활용한 이상치 함수를 구현하여 나머지 이상치를 처리
def outliers_iqr(data):
q1 = np.percentile(data, 25)
q3 = np.percentile(data, 75)
iqr = q3 - q1
lower_bound = q1 - (iqr * 1.5)
upper_bound = q3 + (iqr * 1.5)
return data[(data > upper_bound) | (data < lower_bound)].index
#이상치 함수
o_index = outliers_iqr(bk_df3['이동거리'])
#이상치 함수를 적용하여 이상치를 뽑아냄
len(o_index)
#이상치 건수 확인
len(o_index)/bk_df3.shape[0]
#이상치 비율 확인- 대여소 번호와 대여소 명 분리
bk_df3['대여소명_new'] = bk_df3['대여소명'].str.split(".",expand=True)[1]
bk_df3['대여소번호'] = bk_df3['대여소번호'].astype(object)
# 대여소 명을 문자형으로 변환- 대여 일자 타입 변환 및 파생 변수 생성
# 년,월,일,요일 생성
bk_df3['대여일자'] = pd.to_datetime(bk_df3['대여일자'] )
bk_df3['년도'] = bk_df3['대여일자'].dt.year
bk_df3['월'] = bk_df3['대여일자'].dt.month
bk_df3['일'] = bk_df3['대여일자'].dt.day
bk_df3['요일'] = bk_df3['대여일자'].dt.dayofweek
# 0-> 월 dictionary를 생성해서 map
# 1:'월'
week_list = list("월화수목금토일")
week_map = {i:week_list[i] for i in range(7)}
bk_df3['요일'] = bk_df3['요일'].map(week_map)
bk_df3.head()
#요일을 한글로 변경
4. EDA(Exploratory Data Analysis탐색적 데이터 분석) & Visualization
- 요일별 사용시간 평균
bk_df3.groupby('요일')['사용시간'].mean().sort_values()
#
# 결과
요일
목 24.584474
화 26.607482
월 26.839068
수 27.301006
금 28.451689
토 33.010203
일 33.338179
Name: 사용시간, dtype: float64- 일일평균대여량
bk_df3['이용건수'].sum()/bk_df3['대여일자'].nunique()
# 전체 이용건수를 대여일자 수로 나눔
#
# 결과
98974.3- 자치구별 대여건수 (자치구 기준)
bk_mg12 = pd.merge(bk_df2,
bk_df1,
on='대여소번호')
bk_mg12_sp = bk_mg12[['대여소 그룹','자치구','대여소번호','대여소명','대여 일자 / 월','대여 건수']]
df = bk_mg12_sp.groupby('자치구').sum().sort_values('대여 건수', ascending = False).reset_index()
df[:10]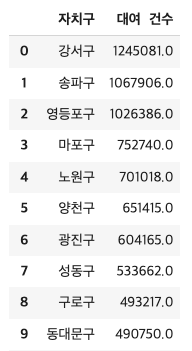
#시각화
plt.figure(figsize = (15,5))
ax = sns.barplot(data = df, x='자치구',y = '대여 건수')
ax.bar_label(ax.containers[0])
plt.show()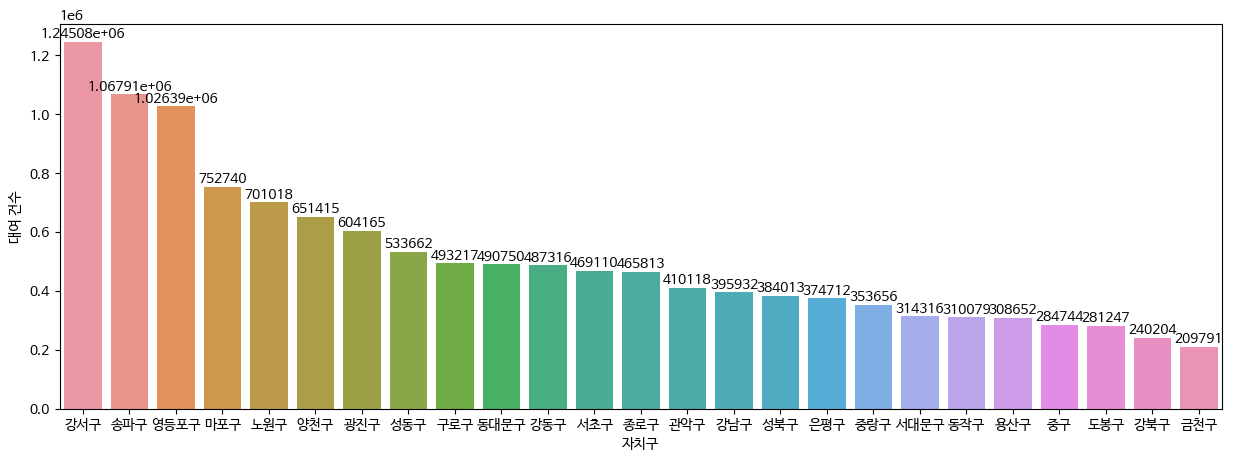
- 대여소별 대여건수
df2 = bk_mg12_sp.groupby(['대여소번호','대여소명','대여소 그룹']).sum().sort_values('대여 건수', ascending = False).reset_index()
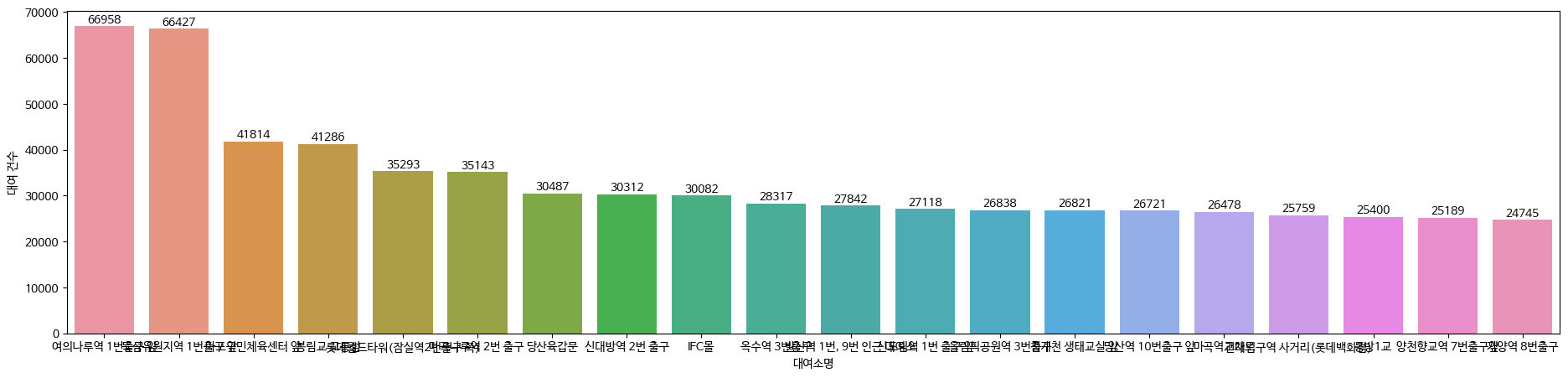
plt.figure(figsize=(23,5))
ax2 = sns.barplot(data = df2[:20], x = '대여소명', y = '대여 건수')
ax2.bar_label(ax2.containers[0])
plt.show()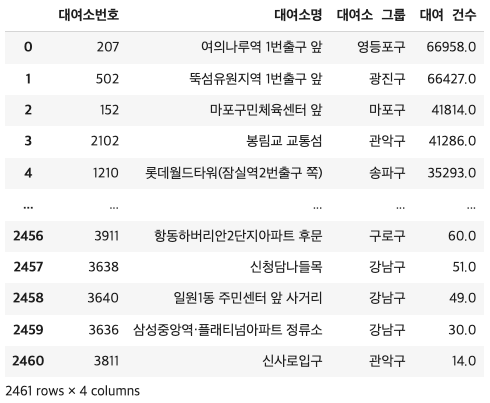
- 상위 10개소 월별 이용량 추이
top10 = bk_mg12_sp.groupby(['대여소번호','대여소명','대여소 그룹']).sum().sort_values('대여 건수', ascending = False).reset_index()[:10]
top10_id = list(top10['대여소번호'])
#상위 10 개소 리스트화
top10_m = bk_df2[bk_df2['대여소번호'].isin(top10_id)]
sns.lineplot(data = top10_m, x= '대여 일자 / 월', y = '대여 건수', hue = '대여소번호')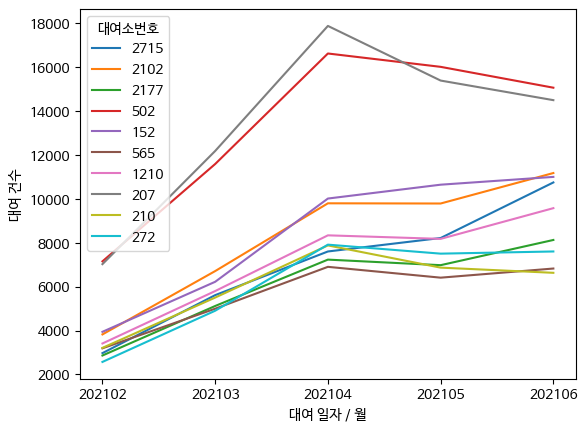
- 평균이동거리가 많은 대여소 순
bk_df3.groupby(['대여소번호','대여소명']).mean().sort_values('이동거리', ascending = False).reset_index()
top10_dist = bk_df3.groupby(['대여소번호','대여소명']).mean().round().sort_values('이동거리', ascending = False).reset_index()[:20]
sns.barplot(data = top10_dist, y = '대여소명', x ='이동거리')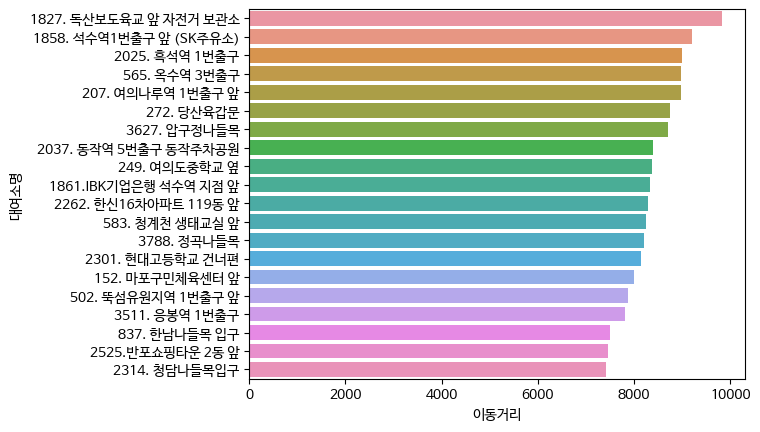
- 평균사용시간이 많은 대여소 순
bk_df3.groupby(['대여소번호','대여소명']).mean().sort_values('사용시간', ascending = False).reset_index()
top10_time = bk_df3.groupby(['대여소번호','대여소명']).mean().round().sort_values('사용시간', ascending = False).reset_index()[:20]
sns.barplot(data = top10_time, y = '대여소명', x ='사용시간')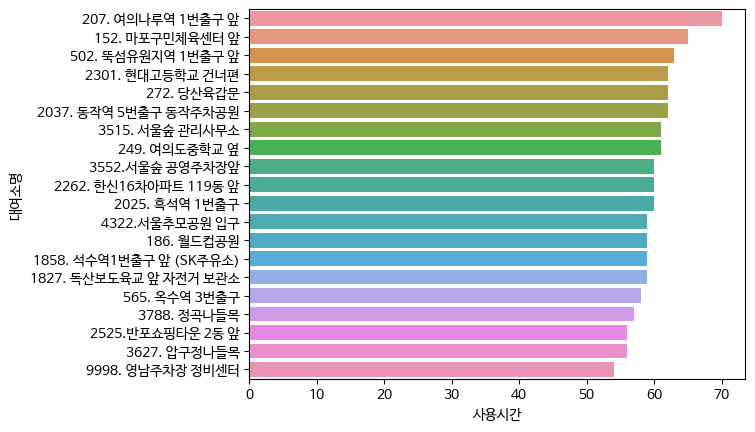
- 요일별 이용건수 시각화
week_order = ['월', '화', '수', '목', '금','토','일']
bk_df3_dofw = bk_df3[['대여시간','이용건수','이동거리','사용시간','요일']].groupby('요일').sum().reset_index() #.sort_values('사용시간', ascending = False)
bk_df3_dofw
sns.barplot(data = bk_df3_dofw, x='요일',y='이용건수',order=week_order)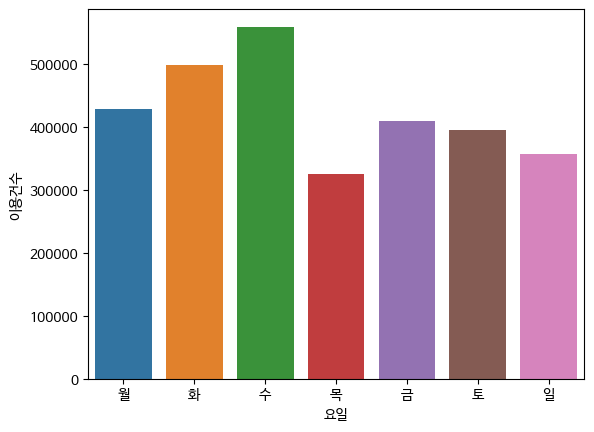
📕 위 방법으로 plot을 원하는 순서대로 그릴 수 있음
- 구별 거치대 개수 지도로 나타내기
import folium
uses_df = bk_df1.groupby('자치구')['총거치대수'].sum().reset_index().sort_values('총거치대수',ascending=False)
geo_url = 'https://raw.githubusercontent.com/mjcho7/dataset/main/seoul_municipalities_geo_simple.json'
data = uses_df[['자치구', '총거치대수']].copy()
map = folium.Map(location=[37.5502, 126.982], zoom_start=10)
folium.Choropleth(
geo_data=geo_url,
data=data,
columns=['자치구', '총거치대수'],
key_on='feature.properties.name',
fill_color='YlOrRd',
fill_opacity=0.7,
line_opacity=0.5,
legend_name='총거치대수'
).add_to(map)
map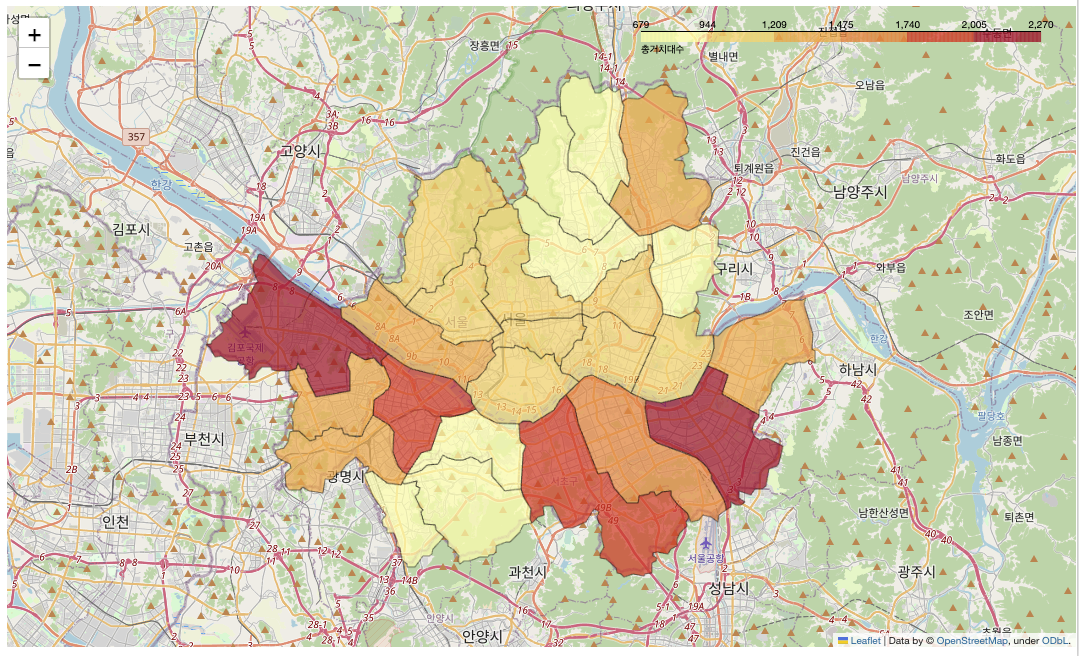
- 구별 거치대 개수 지도위에 원으로 나타내기
# 거치대 수에 따라서 원을 그림
bk_df1_gu_sum = bk_df1.groupby("자치구").agg({'총거치대수':'sum','경도':'mean', '위도':'mean'}).reset_index()
#노원구는 이상치 있으니까 처리 해줘야 함
for i in bk_df1_gu_sum.index:
bk_lat = bk_df1_gu_sum.loc[i, "위도"]
bk_long = bk_df1_gu_sum.loc[i, "경도"]
gu = bk_df1_gu_sum.loc[i,'자치구']
cnt = bk_df1_gu_sum.loc[i,'총거치대수']
# 원의 반지름
if cnt > 2000 :
radius = 50
elif cnt > 1000:
radius = 35
elif cnt > 500:
radius = 20
else:
radius = 10
# 마우스 갖다댔을 때
title = f'{gu} : {cnt}'
#radius = np.sqrt(cnt)
folium.CircleMarker(
[bk_lat,bk_long ],
radius=radius,
fill = True,
color='blue',
tooltip=title).add_to(map)