교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼: 빅데이터 기초 활용 역량 강화 (5/10~6/9) - 데이터 분석
- 강사: 조미정 강사님 (빅데이터, 머신러닝, 인공지능)
- 강의 계획:
1. 파이썬 언어 기초 프로그래밍
2. 크롤링 - 데이터 분석을 위한 데이터 수집(파이썬으로 진행)
3. 탐색적 데이터 분석, 분석 실습
- 분석은 파이썬만으로는 할 수 없으므로 분석 라이브러리/시각화 라이브러리를 통해 분석
4. 통계기반 데이터 분석
5. 미니프로젝트
Numpy 기본 문법
배열생성
np.array()
np.array(object, dtype=None, ndim=0)
ar = np.array([10,20,30])
print(ar) #
print(type(ar)) #
print(ar.shape) # 튜플 형태
print(ar.ndim)
print(ar.dtype) #int64-> array는 하나의 데이터 타입만받을 수 있음 (그래서 빠름)
#
# 결과
[10 20 30]
<class 'numpy.ndarray'>
(3,)
1
int641차원 배열
array = np.array([1,2,3,4,5])
print(array)
printinfo(array)
#
#결과
[1 2 3 4 5]
shape:(5,), dimension:1, dtype:int642차원 배열
data = [[1,2,3,],[4,5,6]] #(2,3)
ar = np.array(data)
print(ar.shape, ar.ndim, ar.dtype)
#
#결과
(2, 3) 2 int643차원 배열
data = [[[[1,2],[3,4,],[5,6,]],[[3.6],[9,3],[4.7]]],[[[1,2],[3,4,],[5,6,]],[[3.6],[9,3],[4.7]]]]
ar = np.array(data)
print(ar.shape, ar.ndim, ar.dtype)
#
#결과
(2, 2, 3) 3 objectnp.arange()
np.arange((start), stop, (step))
ar = np.arange(5)
ar
#
#결과
array([0, 1, 2, 3, 4])ar = np.arange(3,10,2)
ar
#
#결과
array([3, 5, 7, 9])ar = np.arange(10,3,-1)
ar
#
#결과
array([10, 9, 8, 7, 6, 5, 4])zeros(), ones(), full(), emtpy()
지정된 shape의 배열을 생성하는 함수
- np.zeros(shape, dtype=float, order='C')
: 배열을 생성하고 모든 요소를 0으로 초기화- np.ones(shape, dtype=None, order='C')
: 배열을 생성하고 모든 요소를 1으로 초기화- np.full(shape, fill_value, dtype=None, order='C')
: 배열을 생성하고 모든 요소를 fill_value으로 초기화- np.empty(shape, dtype=float, order='C')
: 배열을 생성하고 초기화를 하지 않음 (메모리값 그대로 사용)
array= np.full((3,4),1234)
print(array)
printinfo(array)
#
#결과
[[1234 1234 1234 1234]
[1234 1234 1234 1234]
[1234 1234 1234 1234]]
shape:(3, 4), dimension:2, dtype:int64eye() 단위행렬
np.eye(N, dtype=float, order='C')
주 대각선의 원소가 모두 1이며 나머지 원소는 모두 0인 정사각형 행렬을 반환
array = np.eye(4)
print(array)
printinfo(array)
#
#결과
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
shape:(4, 4), dimension:2, dtype:float64*like 함수
지정된 배열과 shape이 같은 행렬을 만드는 함수
np.zeros_like()
np.ones_like()
np.full_like()
np.empty_like()
array= np.array([[1,2,3], [4,5,6]]) # (2,3)
print(array)
one_array = np.ones_like(array)
print(one_array)
zero_array = np.zeros_like(array)
print(zero_array)
full_array = np.full_like(array, 9)
print(full_array)
empty_array = np.empty_like(array)
print(empty_array)
#
#결과
# Original
[[1 2 3]
[4 5 6]]
# ones
[[1 1 1]
[1 1 1]]
# zeros
[[0 0 0]
[0 0 0]]
# full(9)
[[9 9 9]
[9 9 9]]
# empty(메모리값)
[[91951264 0 0]
[ 0 0 0]]배열의 속성
- 배열의 크기 : ndarray.shape
- 배열의 차원 : ndarray.ndim
- 배열의 요수 수 : ndarray.size (전체 요소의 수)
- 배열의 데이터타입 : ndarray.dtype
- 배열 길이 : len (가장 바깥쪽 shape의 갯수)
dnarray.astype()
ndarray.dtype 데이터 타입 확인
arr = np.arange (1,5)
print(arr.dtype)
print(arr)
#
#결과
int64
[1 2 3 4]ndarray.astype() 데이터 타입 변환 (반환)
array = np.random.random((3,4))
array.dtype
print(array.astype(int))
print(array) # 원본이 바뀌지는 않음
print(array.dtype)
#
#결과
dtype('float64')
[[0 0 0 0]
[0 0 0 0]
[0 0 0 0]]
[[0.77102721 0.49226259 0.25878122 0.71056187]
[0.82218096 0.42926292 0.45293523 0.69919298]
[0.83455701 0.59013263 0.89802688 0.8628185 ]]
# 원본 데이터가 바뀌지는 않음
float64dnarray.shape
dnarray.shape(newshape)
ar= np.arange(24) # 차원이 24인 벡터
print(ar)
print(ar.shape)
ar.shape=(4,6)
print(ar)
ar.shape=(2,2,6)
print(ar)
#
#결과
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
(24,)
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
# 2차원 데이터 (4,6) shape로 변경됨
[[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
[[12 13 14 15 16 17]
[18 19 20 21 22 23]]]
# 3차원 데이터 (2,2,6) shape로 변경됨reshape()
np.reshape(array, newshape, order='C')
array.reshape(newshape)
기존 데이터는 유지하고 차원과 형상을 바꾼 배열을 반환하는 함수
ar = np.arange(24)
print(ar)
ar = np.reshape(ar, (4,6)) #원본 배열 업데이트
print(ar)
#
#결과
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]-1 인자를 사용하면 호환되는 shape로 자동 변환
array1 = np.arange(10)
print(array1)
array1 = array1.reshape((-1,5))
print(array1)
#
#결과
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]reshape(-1,1)형태로 2차원 변환에 자주 사용됨 (여러 ndarray 연산 혹은 결합시 많이 사용)
array1 = np.arange(8)
print(array1)
ar = array1.reshape(2,2,2)
# 3차원 변환
print(ar)
ar = ar.reshape(-1,1)
# 2차원 변환
print(ar)
#
#결과
[0 1 2 3 4 5 6 7]
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
# 3차원
[[0]
[1]
[2]
[3]
[4]
[5]
[6]
[7]]
# 2차원연산
일반연산
기본 연산자(+, -, * , /, //,%, **, > , < , ==, != 등)로 배열의 각 요소별로 적용되는 연산을 할 수 있음 (np모듈에 포함)
np.add, subtract, multiply, devide 형태로도 사용 가능
많은 연산을 빠르게 수행할 수 있음
a = np.arange (1,10).reshape(3,3)
print(a)
b = np.arange(9,0,-1).reshape(3,3)
print(b)
# 연산을 위한 객체 생성
#
#결과
[[1 2 3]
[4 5 6]
[7 8 9]]
[[9 8 7]
[6 5 4]
[3 2 1]]더하기 연산
a+b
np.add(a,b)
#
#결과
[[10 10 10]
[10 10 10]
[10 10 10]]빼기 연산
a-b
np.subtract(a,b)
#
#결과
[[-8 -6 -4]
[-2 0 2]
[ 4 6 8]]나누기 연산
a/b
np.divide(a,b)
#
#결과
[[0.11111111 0.25 0.42857143]
[0.66666667 1. 1.5 ]
[2.33333333 4. 9. ]]*연산
print(a*b)
print(np.multiply(a,b))
#
#결과
[[ 9 16 21]
[24 25 24]
[21 16 9]]** 연산
print(a**b) #a에 b제곱
print(np.square(a,b)) # 그냥 a가 제곱됨!
#
#결과
[[ 1 256 2187]
[4096 3125 1296]
[ 343 64 9]]
[[ 1 4 9]
[16 25 36]
[49 64 81]]비교 연산
print(a<b)
print(a==b)
print(a!=b)
#
#결과
[[ True True True]
[ True False False]
[False False False]]
[[False False False]
[False True False]
[False False False]]
[[ True True True]
[ True False True]
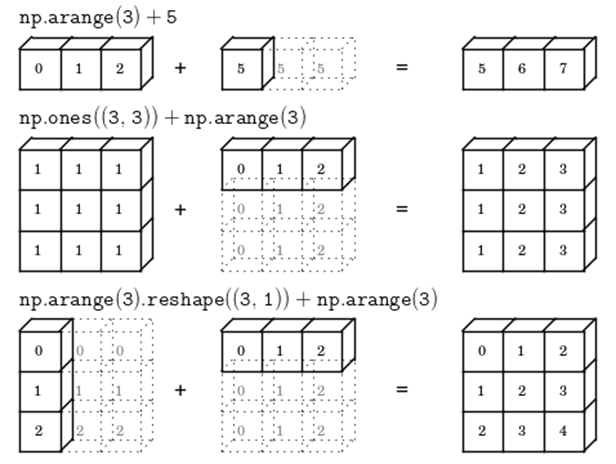
[ True True True]]브로드캐스팅 (Broadcasting)
집계함수
sum, mean, median, std , max, min 등
집계함수는 배열 데이터의 집계 방향을 지정하는 axis 옵셥을 지정할 수 있음
- shape = (4,5,6) 이면 axis는 앞에서부터 0,1,2
- axis = None (default) : 대상 데이터의 모든 요소가 연산 대상이 됨
ar = np.arange(1,13).reshape(4,3)
print(ar)
print(ar.sum())
print(ar.mean())
print(ar.std())
print(ar.max())
print(ar.min())
print(np.median(ar)) #median은 np.median형태만 되는듯
#
#결과
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
78
6.5
3.452052529534663
12
1
6.5axis = 0
ar = np.arange(1,13).reshape(4,3)
print(ar.shape)
print(ar)
ar.sum(axis=0) # 1,4,7,10 방향으로 더함
#
#결과
(4, 3)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
array([22, 26, 30])axis = 1
ar.sum(axis=1) # 1,2,3 방향으로 더함
ar.sum(axis=-1) # 가장 아래 단위 모든 열을 더함
#
#결과
array([ 6, 15, 24, 33])인덱싱
dnarray.[]
높은 차원에서부터 낮은 차원으로 인덱싱(0부터 시작)
ex)
1차원
[0,1,2,3,4,5,6,...]
2차원
[[(0,0), (0,1)],
[(1,0),(1,1)],
[(2,0),(2,1)]]
예제)
1 로 채워져 있는 10 * 10 형태를 갖는 행렬을 생성
행렬의 가장자리 값만 '1', 나머지는 0 이 되도록 행렬 수정
ar = np.ones((10,10)).astype(int)
ar[1:-1, 1:-1] = 0
print(ar)
#
#결과
[[1 1 1 1 1 1 1 1 1 1]
[1 0 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[1 1 1 1 1 1 1 1 1 1]]8*8 matrix 에 체크무늬 만들기
ar=np.zeros((8,8))
ar[1::2, ::2] = 1
ar[::2, 1::2] = 1
print(ar)
#
#결과
[[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.]]불린 인덱싱 (boolean indexing)
조건 필터링과 검색을 동시에 할 수 있기 때문에 매우 자주 사용되는 인덱싱 방식
array = np.arange(0,10)
print(array)
ar = array > 5
array[ar]
#
#결과
[0 1 2 3 4 5 6 7 8 9]
array([6, 7, 8, 9])ar = array[(array > 5)]
print(ar)
#
#결과
[6 7 8 9]
# 불린배열에서 True에 해당하는 인덱스의 값만 출력 np.where()
조건에 맞는 값의 index를 반환
1차원
import numpy as np
array = np.array([0,4,5,8,1,9])#.reshape(2,3)
print(array)
print(np.where(array<5))
#
#결과
[0 4 5 8 1 9]
(array([0, 1, 4]),)2차원
2차원이상에서 np.where을 사용하면 axis를 기준으로 인덱스 반환
import numpy as np
array = np.array([0,4,5,8,1,9]).reshape(2,3)
print(array)
print(np.where(array<5))
#
#결과
[[0 4 5]
[8 1 9]]
(array([0, 0, 1]), array([0, 1, 1]))
# axis 기준 인덱스이므로 (0,0), (0,1),(1,1)항목이 조건을 만족함 브로드캐스팅: np.where(조건, True일때 값, False일때 값)
ar = np.array([0,4,5,8,1,9]).reshape(2,3)
np.where(ar > 5, ar, 10) #5 보다 큰 요소는 그대로, 그렇지 않으면 10으로 대체
#
#결과
array([[10, 10, 10],
[ 8, 10, 9]])array를 index로 이용하기
# 4-18 1차원 array를 index로 이용하기
array = np.array([32, 45, 67, 86, 30])
print(array)
index = np.array([4,2,1,0,3]) # 인덱스 값을 줘서 값 위치 재배치
array[index]
#
#결과
[32 45 67 86 30]
array([30, 67, 45, 45, 86])# 4-19 2차원 array를 index로 이용하기
array = np.array([32, 45, 67, 86, 30])
index = np.array([[3, 2, 1],
[2, 1, 3],
[1, 2, 3]])
array[index]
#
#결과
array([[86, 67, 45],
[67, 45, 86],
[45, 67, 86]])데이터 정렬
sort()
np.sort() : 원 행렬은 그대로 유지한 채 원 행렬의 정렬된 행렬을 반환
# 배열 생성
org_array = np.array([2,5,8,1])
print("org_array: ", org_array)
# np.sort() 정렬
sort_array1 =np.sort(org_array)
print("np.sort() 호출 후 반환된 정렬 행렬 :", sort_array1)
print("np.sort() 호출 후 원본 행렬 :", org_array)
#
#결과
org_array: [2 5 8 1]
np.sort() 호출 후 반환된 정렬 행렬 : [1 2 5 8]
np.sort() 호출 후 원본 행렬 : [2 5 8 1]ndarray.sort() : 원 행렬 자체를 정렬한 형태로 변환하며 반환 값은 None
sort_array2 = org_array.sort()
print("ndarray.sort() 호출 후 반환된 정렬 행렬:", sort_array2)
print("ndarray.sort() 호출 후 원본 행렬 :", org_array)
#
#결과
ndarray.sort() 호출 후 반환된 정렬 행렬: None
ndarray.sort() 호출 후 원본 행렬 : [1 2 5 8]sort_array3 = np.sort(org_array)[::-1]
print("내림차순 : ", sort_array3)
#
#결과
내림차순 : [8 5 2 1]행렬이 2차원 이상일 경우 axis 축 값 설정을 통해 row방향, column 방향으로 정렬을 수행
# 6-4 2차원 배열 행 축 기준 정렬 : np.sort(x, axis=0)
# 배열 생성
array2d = np.array([[9,11],[5,1]])
print(array2d)
# axis = 0
sort_array3 = np.sort(array2d, axis =0)
print(sort_array3)
#
#결과
[[ 9 11]
[ 5 1]]
[[ 5 1]
[ 9 11]]argsort()
np.argsort() :정렬된 행렬의 인덱스를 반환
org_array = np.array([3,1,9,5])
sort_indexes = np.argsort(org_array) #sort 하고 인덱스 반환
print(type(sort_indexes))
print("원본 행렬의 인덱스:", sort_indexes)
print(org_array[np.argsort(org_array)])
#
#결과
<class 'numpy.ndarray'>
원본 행렬의 인덱스: [1 0 3 2]
[1 3 5 9]
- ndarray는 칼럼 정보 같은 메타 정보를 가질 수 없어 이를 별도의 ndarray로 저장하는 경우가 많아서 하나의 요소를 정렬할때 다른 연관 항목을 같이 정렬하기 위해서 argsort로 출력한 인덱스 값을 사용 - 아주 자주 사용되는 방법
name_array = np.array(['John','Samuel','Kate','Mike','Sarah'])
score_array = np.array([78,84,96,88,82]) # 성적순으로 학생ㅇ ㅣ름을 나열하고 싶음
sort_indexes = np.argsort(score_array)
print("성적 오름차순 정렬 시 score_array 인덱스 : ", sort_indexes)
print("성적 오름차순으로 name_array의 이름 출력 :", name_array[sort_indexes])
#
#결과
성적 오름차순 정렬 시 score_array 인덱스 : [0 4 1 3 2]
성적 오름차순으로 name_array의 이름 출력 : ['John' 'Sarah' 'Samuel' 'Mike' 'Kate']