교육 정보
- 교육 명: 경기미래기술학교 AI 교육
- 교육 기간: 2023.05.08 ~ 2023.10.31
- 오늘의 커리큘럼:
파이썬 기반의 머신러닝 이해와 실습 (06/14~07/07)- 강사: 양정은 강사님
- 강의 계획:
1. 개발환경세팅 - IDE, 가상환경
2. 인공지능을 위한 Python
3. KNN 구현을 위한 NumPy
4. K Nearest Neighbors Classification 구현
5. K Means Clustering Mini-project
6. Scikit-learn을 이용한 SVM의 학습
7. Decision Tree의 개념
8. ID3 Algorithm
9. Impurity Metrics - Information Gain Ratio, Gini Index
10. Decision Tree 구현
11. 확률 기초
12. Bayes 정리 예시
13. Naive Bayes Classifier
14. Gaussian Naive Bayes Classifier
Decision Tree(with scikit-learn)그리면서 Categorical value → Continuous value로 Encoding하는 두가지 방법 사용해보기
- 6/23 강의 보충 (2023.06.23. TIL)
Label Encoder
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn import tree
import warnings
warnings.filterwarnings('ignore')
# 데이터 베이스 생성
df = pd.read_csv('register_golf_club.csv')
print(df)
print()
# class 지정
df_class = 'register_golf_club'
# 제외 column 설정
except_cols = ['Index']
# target col 지정
target_col = df_class
# 데이터에서 전체 column 추출
feature_name = list(df.columns)
# 전체 column에서 target, except column 제거 → feature list 생성
feature_name = [x for x in feature_name if (x not in target_col) and (x not in except_cols)]
print(f'{feature_name = }')
print(f'{type(feature_name) = }')
print()
data = df[feature_name]
target = df[target_col]
target_name = target.unique()
print(f'{target_name = }')
print(f'{type(target_name) = }')
print()
''' ================모델 학습을 위해 데이터를 Numeric 자료형으로 변환 ================'''
print(data)
le = LabelEncoder()
data = data.apply(le.fit_transform)
print(data)
print(f'{type(data) = }')
print()
#shape check
print('data/target shape')
print(data.shape, target.shape)
print()
# train test split
X_train, X_test, y_train, y_test = train_test_split(data, target,
test_size=0.2, random_state=15)
model = DecisionTreeClassifier(criterion='entropy')
model.fit(X_train, y_train)
print(f'{model.get_depth() = }')
print(f'{model.get_n_leaves() = }')
accuracy = model.score(X_test, y_test)
print(f'{accuracy = :.4f}')
plt.figure(figsize=(10, 10))
tree.plot_tree(model,
class_names=target_name,
feature_names=feature_name,
impurity=True, filled=True, rounded=True)
plt.show()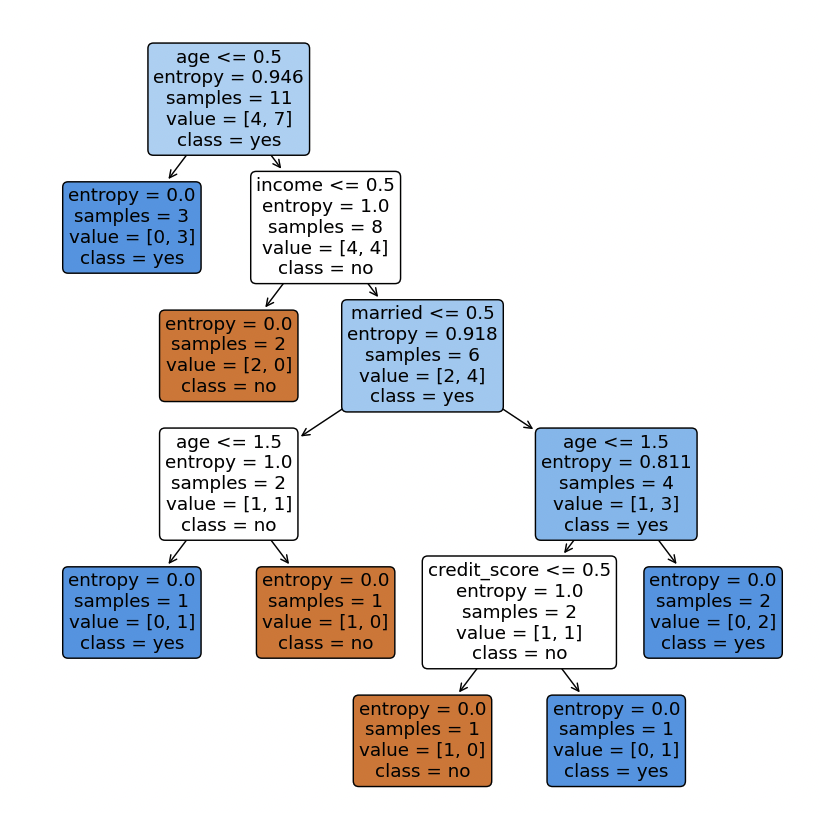
One Hot Encoding
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn import tree
import warnings
warnings.filterwarnings('ignore')
# 데이터 베이스 생성
df = pd.read_csv('register_golf_club.csv')
print(df)
print()
# class 지정
df_class = 'register_golf_club'
# 제외 column 설정
except_cols = ['Index']
# target col 지정
target_col = df_class
# 데이터에서 전체 column 추출
feature_name = list(df.columns)
# 전체 column에서 target, except column 제거 → feature list 생성
feature_name = [x for x in feature_name if (x not in target_col) and (x not in except_cols)]
print(f'{feature_name = }')
print(f'{type(feature_name) = }')
print()
data = df[feature_name]
target = df[target_col]
target_name = target.unique()
print(f'{target_name = }')
print(f'{type(target_name) = }')
print()
''' ================모델 학습을 위해 데이터를 Numeric 자료형으로 변환 ================'''
data_encoded = pd.get_dummies(data, columns=feature_name)
target_encoded = target.map({'no': 0, 'yes': 1})
#shape check
print('data/target shape')
print(data.shape, target.shape)
print()
# train test split
X_train, X_test, y_train, y_test = train_test_split(data_encoded, target_encoded,
test_size=0.2, random_state=15)
model = DecisionTreeClassifier(criterion='entropy')
model.fit(X_train, y_train)
print(f'{model.get_depth() = }')
print(f'{model.get_n_leaves() = }')
accuracy = model.score(X_test, y_test)
print(f'{accuracy = :.4f}')
plt.figure(figsize=(10, 10))
tree.plot_tree(model,
class_names=target_name,
feature_names=data_encoded.columns,
impurity=True, filled=True, rounded=True)
plt.show()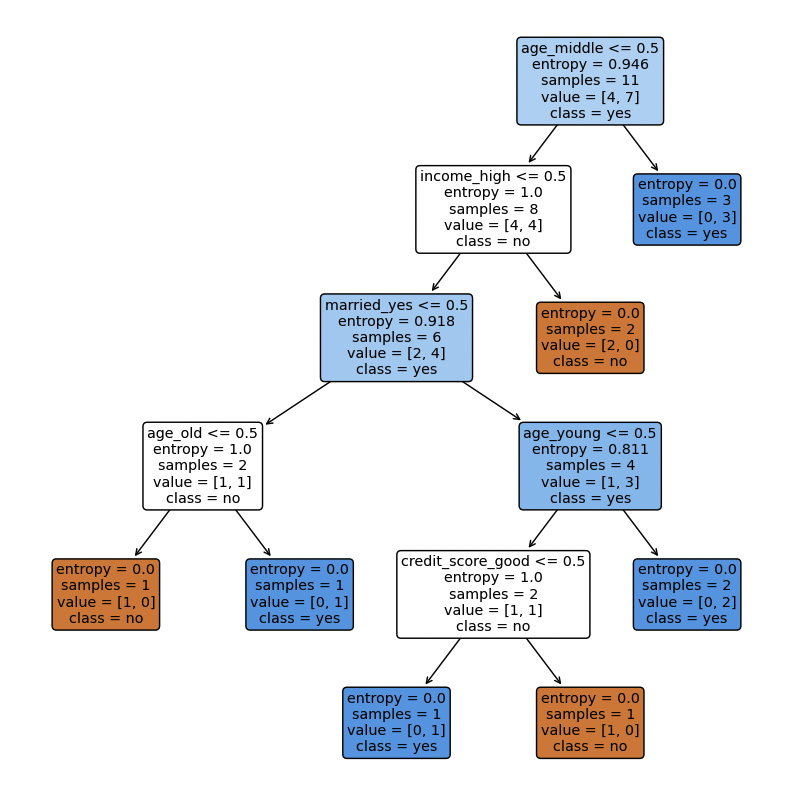
두 코드 다른 부분 비교
- Label Encoder
''' ================모델 학습을 위해 데이터를 Numeric 자료형으로 변환 ================''' print(data) le = LabelEncoder() data = data.apply(le.fit_transform) print(data) print(f'{type(data) = }') print()
- One Hot Encoding (get_dummies)
''' ================모델 학습을 위해 데이터를 Numeric 자료형으로 변환 ================''' data_encoded = pd.get_dummies(data, columns=feature_name) target_encoded = target.map({'no': 0, 'yes': 1})→ plot 보면 알수있듯 두 코드는 동일한 결과를 도출
다만 표현이 label encoder를 사용할 경우 수치 (> 0.5, > 1.5)로 나누어지는지
항목 (age_middle, age_high)으로 나누어지는지가 달라짐
get_dummies에서 alias 설정 하는 법
원하는 데이터를 따로 get_dummies에 넣어 prefix를 설정하고 원래 데이터에 합칠 수 있음dums1 = pd.get_dummies(df["fuel_type"], prefix="ft", drop_first =True)
더미 concat
all = [df, dums1]
df = pd.concat(all, axis=1)
'fuel_type'삭제
df.drop(['fuel_type'], inplace=True, axis=1)

:D