예제 실습 - K-Fold 분할
from sklearn.model_selection import KFold
import numpy as np
data = np.array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6])
kfold = KFold(n_splits=3, shuffle=True, random_state=42) # 3개 분할, 분할하기전 데이터셋 섞어줌, 랜덤
# kfold의 split() k번 train/test 각각 나눔
for train, test in kfold.split(data): # data를 K-Fold 교차검증 방식으로 분할
# [test] [train] [train] 1번째 학습/평가
# [train] [test] [train] 2번째 학습/평가
# [train] [test] [test] 3번째 학습/평가
print(f'train: {data[train]}, test: {data[test]}')# 훈련, 테스트 데이터셋 출력
# data[train]: 현재 Fold의 훈련 데이터들
# data[test]: 현재 Fold의 테스트 데이터 조각
# model = LinearRegression()
# model.fit(X_data[train], y_data[train])
# model.predict(X_data[test])
#
# 데이터 교차로 분할하기train: [0.3 0.4 0.5 0.6], test: [0.1 0.2]
train: [0.1 0.2 0.4 0.5], test: [0.3 0.6]
train: [0.1 0.2 0.3 0.6], test: [0.4 0.5]
예제 실습 - K-Fold 교차 검증
import numpy as np
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
# 데이터셋 읽기
df = pd.read_csv('diabetes.csv')
print(df.shape)
# feature, target(Outcome) 분리
X = df.drop('Outcome', axis=1)
y = df['Outcome'] # 당뇨병 여부 (0: 당뇨병 X, 1: 당뇨병 O)
# 1. Hold-out 방법으로 KNN 모델 평가해보기
# 훈련/테스트 데이터 분할(8:2), stratify 옵션 추가
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y # 층화추출 방식
)
# stratify=y: 원본 타겟 변수의 각 클래스 비율을 훈련/테스트에도 각각 유사한 비율로 분할하게끔
# K=3 기본 KNN 모델 생성 및 훈련
knn = KNeighborsClassifier(n_neighbors=3) # K=3
knn.fit(X_train, y_train)
# 성능 평가
y_pred = knn.predict(X_test)
print(knn.score(X_test, y_test)) # 이 또한 운빨 값
# print(accuracy_score(y_test, y_pred))
# 교차 검증
cv_scores = cross_val_score(knn, X, y, cv=5)
# 1. 모델, 2. X 전체 데이터 3. y 전체 데이터, cv = K-Fold의 K 값(분할 개수)
# scoring: 평가 기준 지표; (분류의 디폴트: accuracy)
# cv_scores: 각 Fold에 대한 평가들에 대한 결과 리스트
print(cv_scores)
print(np.mean(cv_scores)) # 점수들의 평균
(768, 9)
0.6948051948051948
[0.68181818 0.69480519 0.75324675 0.75163399 0.68627451]
0.7135557253204311
예제 실습 - 하이퍼 파라미터 튜닝
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, roc_auc_score
import pandas as pd
#튜닝 했다고 반드시 성능 올라가는건 아님 반드시 최적의 성능을 보장하는게 아니다.
# 데이터셋 읽기
df = pd.read_csv('diabetes.csv')
print(df.shape)
# feature, target 분리
X = df.drop('Outcome', axis=1)
y = df['Outcome'] # 당뇨병 여부 (0: 당뇨병 X, 1: 당뇨병 O)
# 훈련/테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 여기서의 Train: 하이퍼 파라미터 찾기 및 모델 학습을 위함
# 최종적으로 하이퍼 파라미터로 학습된 모델을 평가하기 위한 테스트 데이터
# Base 모델 생성
knn = KNeighborsClassifier() # Base Model
# 튜닝할 파라미터 범위 설정
param_grid = {'n_neighbors' : np.arange(1, 25)}
# 각 하이퍼 파라미터마다의 시험하고자 하는 범위(key:value = hyper:range)
# 5-Fold CV와 GridSearch로 튜닝
knn_gscv = GridSearchCV(knn, param_grid, cv=5)
# cv=5: 5-Fold로 교차검증하면서 튜닝
knn_gscv.fit(X_train, y_train)
print(knn_gscv.best_params_)
# best_params: 지정한 param_grid에 대해 각 최적의 하이퍼 파라미터 값 반환
print(knn_gscv.best_score_)
# best_score_: Train 데이터 안에서 수행된 CV(교차 검증) 평균 점수(Accuracy)
# 구해진 최적의 모델
best_model = knn_gscv.best_estimator_
# best_estimator_ : 최적의 파라미터로학습이 된 모델
# 해당 모델로 예측 및 평가 진행
#최적의 모델로 평가
y_pred = best_model.predict(X_test)
print(accuracy_score(y_test, y_pred))예제 실습 - 성능 향상
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
df = pd.read_csv("diabetes.csv")
X = df.drop("Outcome", axis=1)
y = df["Outcome"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train: 하이퍼 파라미터 튜닝과 최적의 모델 학습을 위함
# Test: 최적의 모델을 평가하기 위함
# 스케일링
# 어떤방법 쓰느냐에 따라 또 달라짐
scaler = StandardScaler()# 여기선 스탠다드
X_train_scaled = scaler.fit_transform(X_train) # 훈련 데이터 스케일링
X_test_scaled = scaler.transform(X_test) # 테스트 데이터 스케일링
# 기본적인 모델 학습
model = KNeighborsClassifier()
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled) # 예측 값
print(f'기본 KNN 정확도: {accuracy_score(y_test, y_pred)}')
# 하이퍼 파라미터 조합
param_grid = {
'n_neighbors': list(range(3, 31, 2)), # 홀수 k
'weights': ['uniform', 'distance'], # uniform(디폴트), distance: 가까운 이웃한테 가중치( 주는 파라미터)
'metric': ['minkowski'], # (거리측정 파라미터 )
'p': [1, 2] # manhattan, euclidean
}
# Base Model 생성
knn = KNeighborsClassifier()
# 튜닝
grid = GridSearchCV(
estimator=knn, # 어떤 모델에 대해서 수행할 것인지 모델 객체
param_grid=param_grid, # 하이퍼 파라미터 격자 조합
cv=5, # 5-Fold 교차 검증
scoring='accuracy' # 평가 및 최적의 파라미터를 찾을 때 기준 지표
)
grid.fit(X_train_scaled, y_train)
print(f'최적 하이퍼 파라미터: {grid.best_params_}')
print(f'교차 검증 최고 정확도: {grid.best_score_ }')
# 얻은 최적의 모델
best_model = grid.best_estimator_
# 최적의 모델로 예측 및 평가 진행
pred_best = best_model.predict(X_test_scaled) # 튜닝후 개선된 정확도
print(f'최적 모델 정확도: {accuracy_score(y_test, pred_best)}')# 성능향상요소들 전처리, 데이터 퀄리티, 스케일링, 하이퍼파라미터 예제 실습 - 앙상블; 랜덤포레스트
Iris 데이터셋으로 품종(Species)을 예측하는 RandomForestClassifier
내가 한 풀이
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
# 1. 데이터 불러오기 및 feature/target 분리
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
# 2. 훈련/테스트 데이터 분할(8:2, stratify)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42 , stratify=y) # 층화 추출(Stratified Sampling)**을 수행
# 3. 랜덤포레스트 모델 생성 및 학습
# - n_estimators=200
# - max_depth=None
# - random_state=42
model = RandomForestClassifier(n_estimators=200, max_depth=None, random_state=42)
model.fit(X_train, y_train)
# 4. 예측 및 평가
pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, pred))
print("Classification Report:", classification_report(y_test, pred))
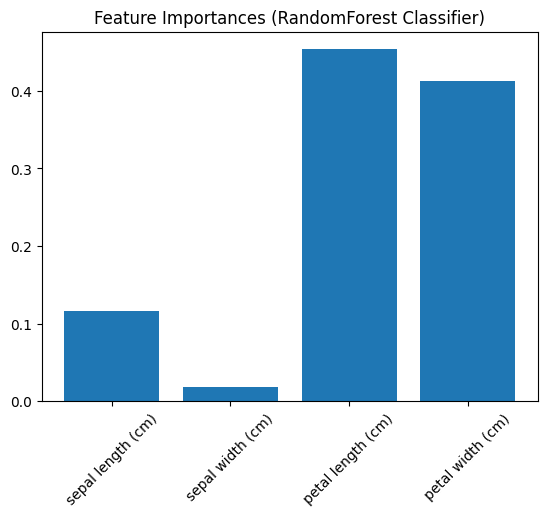
# 5. Feature Importance 시각화
importances = model.feature_importances_ # 중요도 가져오기
features = X.columns
# 컬럼별 중요도 점수 막대 그래프 시각화
plt.bar(features, importances)
plt.xticks(rotation=45)
plt.title("Feature Importances (RandomForest Classifier)")
plt.show()
# 6. GridSearchCV를 통한 하이퍼파라미터 튜닝
param_grid = {
"n_estimators": [100, 200, 300],
"max_depth": [None, 5, 10],
"min_samples_split": [2, 5],
"min_samples_leaf": [1, 2]
}
# GridSearch로 하이퍼 파라미터 튜닝하기
# - CV: 5
# - 성능 평가 지표 기준: 정확도
grid = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring='accuracy',
)
# 튜닝 수행하기
grid.fit(X_train, y_train)
# # 최적의 파라미터들과 점수 출력
print("Best Params:", grid.param_grid)
print("Best CV Score:", grid.cv)
# 7. 최적 모델로 다시 평가
best_model = grid.best_estimator_
print('best_model',best_model)
best_pred = best_model.predict(X_test)
print('best_pred',best_pred)
print("[Best Model Accuracy]:", accuracy_score(y_test, best_pred))Accuracy: 0.9
Classification Report: precision recall f1-score support
0 1.00 1.00 1.00 10
1 0.82 0.90 0.86 10
2 0.89 0.80 0.84 10
accuracy 0.90 30 macro avg 0.90 0.90 0.90 30
weighted avg 0.90 0.90 0.90 30
Best Params: {'n_estimators': [100, 200, 300], 'max_depth': [None, 5, 10], 'min_samples_split': [2, 5], 'min_samples_leaf': [1, 2]}
Best CV Score: 5
best_model RandomForestClassifier(random_state=42)
best_pred [0 2 1 1 0 1 0 0 2 1 2 2 2 1 0 0 0 1 1 1 0 2 1 1 2 2 1 0 2 0]
트러블 슈팅
importances = model.feature_importances_중요도 가져오기 문법
# 6. GridSearchCV를 통한 하이퍼파라미터 튜닝
param_grid = {
"n_estimators": [100, 200, 300],
"max_depth": [None, 5, 10],
"min_samples_split": [2, 5],
"min_samples_leaf": [1, 2]
}GridSearchCV param_grid 설정 후
하이퍼파라미터 튜닝
# GridSearch로 하이퍼 파라미터 튜닝하기
# - CV: 5
# - 성능 평가 지표 기준: 정확도
grid = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring='accuracy',
)튜닝수행=학습
grid.fit(X_train, y_train)이런 흐름이 생소했음.
최적모델 찾기 및 평가
best_model = grid.best_estimator_
best_pred = best_model.predict(X_test)위의 예제랑 같은 흐름
타이타닉 생존자 예측
요구사항
- titanic3.csv 데이터셋을 읽어옵니다.
- 결측치는 간단히 처리합니다.
- age : 평균 또는 중앙값으로 대체
- embarked : 최빈값으로 대체
- 사용할 feature는 다음과 같이 한다.
- pclass, sex, age, sibsp, parch, fare, embarked
- 범주형 변수(sex, embarked)는 OneHotEncoder로 처리한다.
- survived를 타깃으로,
- train_test_split(..., stratify=y, test_size=0.2)로 분할한다.
- RandomForestClassifier에 대해 아래 파라미터로 GridSearchCV를 수행한다.
- n_estimators:
[100, 200] - max_depth:
[None, 5, 10] - min_samples_split:
[2, 5] - cv=5, scoring='accuracy'
- 최적 모델에 대해
-
교차 검증 평균 정확도,
-
테스트 세트 정확도를 출력한다.
내가 한 풀이
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import accuracy_score
# 1. 데이터 불러오기
df = pd.read_csv("titanic3.csv")
# 2. 결측치 처리
df["age"] =df['age'].fillna(int(df['age'].mean()))
df["embarked"] = df['embarked'].fillna(df['embarked'].mode())
# 3. feature와 target 분리
features = ["pclass", "sex", "age", "sibsp", "parch", "fare", "embarked"]
X = df[features]
y = df['survived']
print(y.isna().sum())
# 4. Stratified train/test 분할 (8:2) 범주형 변수(sex, embarked)는 OneHotEncoder로 처리한다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
ohe = OneHotEncoder(sparse_output=False)
encoded = ohe.fit_transform(df[['sex', 'embarked']])
# 5. 범주형 인코딩: get_dummies 사용 survived를 타깃으로,
# - train에는 fit 개념으로 get_dummies
# - test는 같은 컬럼 구조로 맞춰줘야 함
categorical_cols = ["sex", "embarked"]
# 5-1. 훈련 데이터에 대한 인코딩
X_train_encoded = pd.get_dummies(
X_train,
columns=categorical_cols,
drop_first=True # 더미 변수 함정 방지를 위해 첫 카테고리 드롭
)
# 5-2. 테스트 데이터에 대한 인코딩
X_test_encoded = pd.get_dummies(
X_test,
columns=categorical_cols,
drop_first=True
)
# train과 test의 컬럼(더미 변수)이 다를 수 있으므로, test를 train에 맞춰 재정렬
X_test_encoded = X_test_encoded.reindex(
columns=X_train_encoded.columns,
fill_value=0
)
# 6. RF + GridSearchCV (전처리 분리, 모델만 튜닝)
rf = RandomForestClassifier(random_state=42)
# 6-1. 탐색할 최적의 하이퍼 파라미터 격자 정의
param_grid = {
'n_estimators': [100, 200],
'max_depth': [None, 5, 10],
'min_samples_split': [2, 5]
}
# # GridSearch 정의
grid_search = GridSearchCV(
rf,
param_grid=param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1
)
print(grid_search)
# 튜닝 수행하기
grid_search.fit(X_train_encoded, y_train)
print(f"최적 하이퍼파라미터: {grid_search.best_params_}")
print(f"최적 CV 평균 정확도: {grid_search.best_score_:.4f}") # cv인데 best_score인지 헷갈림
# 최적의 튜닝된 모델 가져오기
best_model = grid_search.best_estimator_# best_model이아닌 estimator_
# 7. 테스트 세트 평가
y_pred = best_model.predict(X_test_encoded)
test_acc = accuracy_score(y_test, y_pred)
print(f"테스트 정확도: {test_acc:.4f}")트러블 슈팅
print(f"최적 하이퍼파라미터: {grid_search.best_params_}")
print(f"최적 CV 평균 정확도: {grid_search.best_score_:.4f}") # cv인데 best_score인지 헷갈림맨처음에 평균정확도에grid_search.cv 값을 넣음
평균정확도는 .best_score다. 튜닝을하면서 구해낸 값
