주택 가격 예측 모델 평가 및 비교
캘리포니아 주택 가격 데이터셋을 사용하여 세 가지 회귀 모델(Linear Regression, Decision Tree, Random Forest)의 성능을 비교하세요.
- 데이터셋:
fetch_california_housing.csv
요구사항
- 데이터셋을 읽고 구조를 파악하세요.
- 그리고 데이터를 feature/target으로 분리, 그리고 훈련/테스트 세트로 분할 (8:2)
- target 변수:
MedHouseVal
- 두 가지 모델을 반복문에서 학습/예측을 진행합니다.
- LinearRegression
- DecisionTreeRegressor
- 각 모델에 대해 다음 지표를 계산:
- MAE (Mean Absolute Error)
- MSE (Mean Squared Error)
- RMSE (Root Mean Squared Error)
- R² Score
- 각 결과를 저장하고, 마지막에 최종 데이터프레임으로 만들어서 출력합니다.
- r^2 score 성능이 높은 모델과 RMSE 성능이 제일 높은 모델을 추출하여 출력합니다.
내가 한 풀이
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import numpy as np
import pandas as pd
# 데이터 로드 및 feature와 target 분리
df = pd.read_csv('fetch_california_housing.csv')
X = df.drop('MedHouseVal', axis=1)
y = df['MedHouseVal']
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
# stratify=y # 클래스 비율 유지
)
print(f"학습 데이터 크기: {X_train.shape}")
print(f"테스트 데이터 크기: {X_test.shape}\n")
# 모델 정의 (key: 모델 이름, value: 모델 객체)
models = {
'Linear Regression': LinearRegression(),
'Decision Tree': DecisionTreeRegressor(random_state=42),
}
# 결과 저장
results = []
# 각 모델 학습 및 평가
for name, model in models.items():
# 모델 학습
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 평가 지표 계산(MAE, MSE, RMSE, R^2)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
# 결과 저장
results.append({
'Model': name,
'MAE': mae,
'MSE': mse,
'RMSE': rmse,
'R² Score': r2
})
print(f"MAE: {mae:.4f}")
print(f"RMSE: {rmse:.4f}")
print(f"R² Score: {r2:.4f}\n")
# 결과를 DataFrame으로 변환 후 출력
results_df = pd.DataFrame(results)
results_df = results_df.set_index('Model')
print(results_df.round(4))
# 위 데이터프레임에서 지표 별 최고 성능 모델 찾기
best_model_r2 = results_df['R² Score'].idxmax()# list('R² Score')[results_df.index(max(results_df))]
best_model_rmse = results_df['RMSE'].idxmin() # list('RMSE')[results_df.index(max(results_df))]
print(f"R² Score 기준 최고 모델: {best_model_r2} (R²={results_df.loc[best_model_r2, 'R² Score']:.4f})")
print(f"RMSE 기준 최고 모델: {best_model_rmse} (RMSE={results_df.loc[best_model_rmse, 'RMSE']:.4f})")학습 데이터 크기: (16512, 8)
테스트 데이터 크기: (4128, 8)
MAE: 0.5332
RMSE: 0.7456
R² Score: 0.5758
MAE: 0.4547
RMSE: 0.7037
R² Score: 0.6221
| Model | MAE | MSE | RMSE | R² Score |
|---|---|---|---|---|
| Linear Regression | 0.5332 | 0.5559 | 0.7456 | 0.5758 |
| Decision Tree | 0.4547 | 0.4952 | 0.7037 | 0.6221 |
트러블 슈팅
best_model_r2 = results_df['R² Score'].idxmax()# list('R² Score')[results_df.index(max(results_df))]
best_model_rmse = results_df['RMSE'].idxmin() idmax, idmin 메서드는 처음봐서 당황함
-
idxmax()
기능: Series 또는 DataFrame에서 가장 큰 값을 가진 항목의 인덱스 레이블을 반환한다.
R² 점수가 가장 높은 모델의 이름을 찾게 된다. -
idxmin()
기능: Series 또는 DataFrame에서 가장 작은 값을 가진 항목의 인덱스 레이블을 반환한다.
RMSE가 가장 낮은 최고 성능 모델의 이름을 찾게 된다.
암 진단 - 모델 성능 비교
유방암 진단 데이터셋을 불러와서
- 데이터를 훈련/테스트 데이터로 분할합니다.
- 분류 모델 3개에 대해서 각각 모델을 생성하고 학습을 진행합니다.
- Logistic Regression
- KNN (K=5)
- Decision Tree (max_depth=3)
- 각 모델에 대한 다음 지표를 계산하세요.
- 함수 get_scores() 정의하기
- 매개변수: y_true: 실제 정답 데이터, y_pred: 모델이 예측한 결과
- 리턴: 실제 정답과 예측한 결과에 대한 평가지표(Accuracy, Precision, Recall, F1-Score)를 튜플로 묶어서 반환
- 정의된 함수를 바탕으로 위에서 학습한 모델 3개에 대한 평가 지표 함수를 모두 호출하여 지표를 비교하세요.
- 성능을 데이터프레임 형태로 정리 후, 출력하세요.
- 모델 이름, 지표 각각을 컬럼으로 설정 (3행 5열 형태)
- 어느 지표를 기준으로 평가를 해야 할까요? 기준을 설정하고 해당 지표에 대한 해석
내가 한 풀이
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 1. 데이터 불러오고, feature와 target으로 분리
data = load_breast_cancer()
X = data.data
y = data.target # 1 = 양성(Benign), 0 = 악성(Malignant)
# 2. train/test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. 각각의 모델 정의
model_lr = LogisticRegression(max_iter=500)
model_knn = KNeighborsClassifier(n_neighbors=3)
model_tree = DecisionTreeClassifier(max_depth=3)
# 4. 각 모델을 학습
model_lr.fit(X_train, y_train)
model_knn.fit(X_train, y_train)
model_tree.fit(X_train, y_train)
# 5. 각 모델을 예측
pred_lr = model_lr.predict(X_test)
pred_knn = model_knn.predict(X_test)
pred_tree = model_tree.predict(X_test)
# 6. 지표 계산 함수
def get_scores(y_true, y_pred):
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
# 분류 모델에 맞는 지표, 회귀 모델에 맞는 지표가 있음 분류 모델에 맞는 지표 쓰기
return (
accuracy,
precision ,
recall,
f1
)
# 위 함수를 통해 각 모델의 지표를 저장합니다.
lr_scores = get_scores(y_test, pred_lr)
knn_scores = get_scores(y_test, pred_knn)
tree_scores = get_scores(y_test, pred_tree)
results = [
["LogisticRegression"] + list(lr_scores),
["KNN"] + list(knn_scores),
["DecisionTree"] + list(tree_scores)
]
# 컬럼명
columns = ["Model", "Accuracy", "Precision", "Recall", "F1"]
# DataFrame 생성
df_scores = pd.DataFrame(results, columns=columns)
print(df_scores)| Index | Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| 0 | LogisticRegression | 0.956140 | 0.945946 | 0.985915 | 0.965517 |
| 1 | KNN | 0.929825 | 0.931507 | 0.957746 | 0.944444 |
| 2 | DecisionTree | 0.938596 | 0.944444 | 0.957746 | 0.951049 |
트러블 슈팅
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
# 분류 모델에 맞는 지표, 회귀 모델에 맞는 지표가 있음 분류 모델에 맞는 지표 쓰기 여기서도 아예 다른 함수 넣어서 다른 값이 나왔다.
lr_scores = get_scores(y_test, pred_lr)
knn_scores = get_scores(y_test, pred_knn)
tree_scores = get_scores(y_test, pred_tree)get_scores 함수로 지표 지정
results = [
["LogisticRegression"] + list(lr_scores),
["KNN"] + list(knn_scores),
["DecisionTree"] + list(tree_scores)
]이런 함수도 있으니 기억하기
Threshold 변화에 따른 분류 모델 성능 분석
분류 모델은 기본적으로 예측 확률을 threshold(임계값)을 기준으로 분류합니다.
일반적으로 threshold는 0.5로 설정되지만, 실제 문제 상황에 따라 이 값은 크게 달라질 수 있는데,
threshold를 조절하면 Precision, Recall, F1-Score가 서로 trade-off 관계를 보이며 변합니다.
따라서 threshold를 단순히 0.5로 고정하는 것이 아니라, 문제 목적에 맞는 최적 threshold를 찾아봅시다.
Logistic Regression 모델을 활용하여 threshold 변화에 따른 성능 지표의 변화를 관찰하고, 최적의 threshold를 탐색해봅시다.
- LogisticRegression 모델을 생성하고 학습 및 '예측 확률(probability)' 계산합니다.
- 예측 확률 중에서 1일 확률(양성(= 1)일 확률)을 추출합니다.
- Threshold 값을 0.1 ~ 0.9까지 변화시키며 성능 측정
- threshold를 0.1부터 0.9까지 0.05 간격으로 변경한다.
- 반복문을 통해 각 threshold 기준에 의해 얻은 클래스 예측 결과로 다음 성능 지표를 계산합니다.
- Precision
- Recall
- F1-Score
- 각 threshold에 대해 계산한 값을 각 지표 리스트로 저장합니다.
- 성능 지표변화 시각화
- threshold를 x축으로 하고, Precision, Recall, F1-Score를 y축으로 하여, 한 그래프에 함께 시각화 수행
- 최적 Threshold 찾기
- 계산한 F1-Score 리스트 중 가장 높은 값을 갖는 threshold를 찾고 출력 (F1-Score가 가장 높을 때가 Precision/Recall 성능이 제일 좋은 지점)
- 해당 threshold가 F1 기준으로 가장 적합한 threshold
- 기본 threshold(0.5)와 최적 threshold의 성능 비교
- threshold=0.5일 때의 Precision, Recall, F1-Score를 계산
- 그리고 최적 threshold에서의 성능 지표와 그래프를 비교하여 threshold 조정의 효과를 분석해보세요!
내가 한 풀이
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_score, recall_score, f1_score
import numpy as np
import matplotlib.pyplot as plt
# 시각화 한글 깨짐 방지 설정
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams["axes.unicode_minus"] = False
# 데이터 생성
X, y = make_classification(n_samples=500, n_features=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 1. LogisticRegression 모델을 학습하고 예측 확률을 구하세요
model = LogisticRegression(max_iter=1000, random_state=42)
model.fit(X_train, y_train)
# 양성 클래스(1)에 대한 예측 확률
y_pred_proba= model.predict_proba(X_test)
# print('y_pred_proba', y_pred_proba)
# 2. threshold를 0.1부터 0.9까지 0.05씩 변화시키면서 지표 계산
thresholds = np.arange(0.1, 0.91, 0.05)
precisions = []
recalls = []
f1_scores = []
# 각 threshold에서의 Precision, Recall, F1-Score를 계산 후, 각 리스트에 저장
for thr in thresholds:
# 양성일 예측 확률이 현재 threshold 이상이면 1, 그렇지 않으면 0
y_pred_thr = (y_pred_proba[:, 1] >= thr).astype(int)
# 현재 threshold로 구한 예측 클래스로 각 지표 계산하기
p = precision_score(y_test, y_pred_thr, zero_division=0)
r = recall_score(y_test, y_pred_thr, zero_division=0)
f1 = f1_score(y_test, y_pred_thr, zero_division=0)
precisions.append(p)
recalls.append(r)
f1_scores.append(f1)
# 3. threshold에 따른 Precision, Recall, F1-Score '변화'를 그래프로 그리기
plt.figure(figsize=(10, 6))
plt.plot(thresholds, precisions, marker='o', label='Precision')
plt.plot(thresholds, recalls, marker='s', label='Recall')
plt.plot(thresholds, f1_scores, marker='^', label='F1-Score')
plt.xlabel('Threshold')
plt.ylabel('Score')
plt.title('Threshold에 따른 Precision / Recall / F1-Score 변화')
plt.legend()
plt.grid(True)
plt.show()
# 4. F1-Score가 최대가 되는 최적의 threshold를 찾기
print(f1_scores)
best_idx = f1_scores.index(max(f1_scores)) # f1_scores에서 최대가 되는 지점의 인덱스 찾기
print(best_idx)
best_threshold = thresholds[best_idx] # 해당 인덱스의 threshold 값
print(best_threshold)
best_f1 = f1_scores[best_idx] # 해당 인덱스의 f1-score 값
print(f"최적 F1-Score: {best_f1:.4f}, (Threshold = {best_threshold:.2f})")
# 5. 기본 threshold(0.5)와 최적 threshold의 성능 비교
# 기본 threshold = 0.5에 대한 예측 클래스를 구하고, 성능 지표 계산하기
# 양성일 예측 확률이 0.5 이상이면 1, 그렇지 않으면 0
y_pred_default = (y_pred_proba[:, 1] >= 0.5).astype(int) #
p_default = precision_score(y_test, y_pred_default)
r_default = recall_score(y_test, y_pred_default)
f1_default = f1_score(y_test, y_pred_default)
# 최적 threshold일 때에 대한 예측 클래스를 구하고, 성능 지표 계산하기
# 양성일 예측 확률이 최적 threshold 이상이면 1, 그렇지 않으면 0
y_pred_best = (y_pred_proba[:, 1] >= best_threshold).astype(int)
p_best = precision_score(y_test, y_pred_best, zero_division=0)
r_best = recall_score(y_test, y_pred_best, zero_division=0)
f1_best = f1_score(y_test, y_pred_best, zero_division=0)
print("*기본 Threshold (0.5) 성능")
print(f"Precision: {p_default:.4f}")
print(f"Recall: {r_default:.4f}")
print(f"F1-Score: {f1_default:.4f}")
print(f"*최적 Threshold ({best_threshold:.2f}) 성능")
print(f"Precision: {p_best:.4f}")
print(f"Recall: {r_best:.4f}")
print(f"F1-Score: {f1_best:.4f}")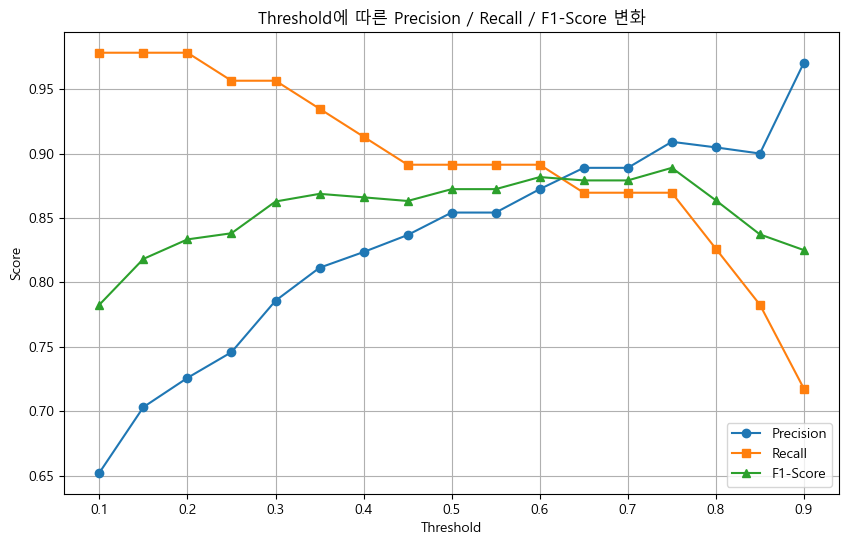
[0.782608695652174, 0.8181818181818182, 0.8333333333333334, 0.8380952380952381, 0.8627450980392157, 0.8686868686868687, 0.865979381443299, 0.8631578947368421, 0.8723404255319149, 0.8723404255319149, 0.8817204301075269, 0.8791208791208791, 0.8791208791208791, 0.8888888888888888, 0.8636363636363636, 0.8372093023255814, 0.825]
13
0.7500000000000002
최적 F1-Score: 0.8889, (Threshold = 0.75)
*기본 Threshold (0.5) 성능
Precision: 0.8542
Recall: 0.8913
F1-Score: 0.8723
*최적 Threshold (0.75) 성능
Precision: 0.9091
Recall: 0.8696
F1-Score: 0.8889트러블 슈팅
# 양성일 예측 확률이 현재 threshold 이상이면 1, 그렇지 않으면 0
y_pred_thr = (y_pred_proba[:, 1] >= thr).astype(int)여기서 애먹음 y_pred_proba가 2차원 행렬 이고 [1,2], [3,4] 이런 형태로 찍히는데
1이상일시 두번째 인덱스임
y_pred_best = (y_pred_proba[:, 1] >= best_threshold).astype(int)여기도 마찬가지
잔차(Residual) 분석
회귀 모델의 잔차(residual)를 분석하여 모델의 성능을 시각적으로 평가하세요.
- make_regression으로 데이터가 생성이 되어있습니다. (n_samples=200, n_features=1, noise=20)
- Linear Regression 모델로 학습을 진행합니다.
- 예측을 수행한 다음에 평가 지표를 구하고, 출력합니다.
- MAE, MSE, RMSE, R^2 Score
- 잔차(or 오차; Residual)를 계산합니다. y_actual = y_pred + residual
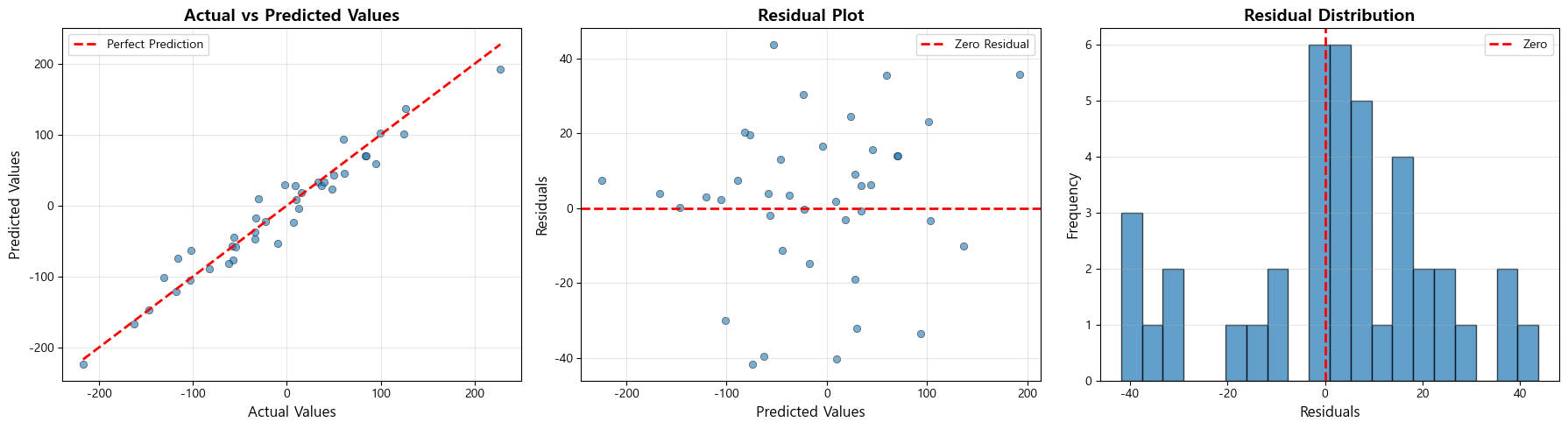
- 다음 시각화 생성:
- 실제값 vs 예측값 산점도 (45도 기준선 포함)
- 잔차 플롯 (예측값 vs 잔차) 0 기준선 포함)
- 잔차 히스토그램 (잔차 구간의 빈도)
- 잔차 분석을 하고 출력합니다. (평균, 표준편차, 최대, 최소)
- numpy 모듈의 mean(), std(), max(), min() 함수를 활용하세요.
- 최종적으로 3개의 시각화 그래프에 대한 해석을 기준을 참고하여 작성하세요.
내가 한 풀이
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 데이터 생성
X, y = make_regression(n_samples=200, n_features=1, noise=20, random_state=42)
# 데이터 분할 (8:2)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 모델 생성 및 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 예측 수행하기
y_pred = model.predict(X_test)
# 평가 지표 계산(MAE, MSE, RMSE, R^2 Score)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print("모델 평가 지표")
print(f"MAE: {mae:.4f}")
print(f"MSE: {mse:.4f}")
print(f"RMSE: {rmse:.4f}")
print(f"R² Score: {r2:.4f}")
# 잔차 계산하기 (y_actual = y_predicted + residuals)
residuals = y_test - y_pred
print(residuals)
# 시각화
fig, axes = plt.subplots(1, 3, figsize=(18, 5)) # 서브 플롯
# 1. 실제값(actual) vs 예측값(predicted)에 대한 산점도
axes[0].scatter(y_test, y_pred, alpha=0.6, edgecolors='k', linewidth=0.5)
axes[0].plot([y_test.min(), y_test.max()],
[y_test.min(), y_test.max()],
'r--', lw=2, label='Perfect Prediction')
axes[0].set_xlabel('Actual Values', fontsize=12)
axes[0].set_ylabel('Predicted Values', fontsize=12)
axes[0].set_title('Actual vs Predicted Values', fontsize=14, fontweight='bold')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 2. 잔차 Plot (X축: 예측값, Y축: 잔차에 대한 산점도)
axes[1].scatter(y_pred, residuals, alpha=0.6, edgecolors='k', linewidth=0.5)
axes[1].axhline(y=0, color='r', linestyle='--', lw=2, label='Zero Residual')
axes[1].set_xlabel('Predicted Values', fontsize=12)
axes[1].set_ylabel('Residuals', fontsize=12)
axes[1].set_title('Residual Plot', fontsize=14, fontweight='bold')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
# 3. 잔차 히스토그램(잔차에 대한 빈도/분포 확인. 구간은 20개로 설정)
axes[2].hist(residuals, bins=20, edgecolor='black', alpha=0.7)
axes[2].axvline(x=0, color='r', linestyle='--', lw=2, label='Zero')
axes[2].set_xlabel('Residuals', fontsize=12)
axes[2].set_ylabel('Frequency', fontsize=12)
axes[2].set_title('Residual Distribution', fontsize=14, fontweight='bold')
axes[2].legend()
axes[2].grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.show()
# 잔차 분석하기 (평균, 표준편차, 최소, 최대)
print("* 잔차 분석")
print(f"잔차 평균: {np.mean(residuals):.4f}")
print(f"잔차 표준편차: {np.std(residuals):.4f}")
print(f"잔차 최솟값: {np.min(residuals):.4f}")
print(f"잔차 최댓값: {np.max(residuals):.4f}")
'''
모델 진단
1. 실제값 vs 예측값 그래프
*해석 방법: 점들이 45도 선 주변에 분포하면 좋은 예측을 의미합니다 (선형 관계 여부)
분석: 현재 모델은 비교적 좋은 선형 관계를 보입니다
2. 잔차 플롯
*해석 방법: 잔차가 0을 중심으로 무작위로 분포하면 모델이 적절합니다 (패턴이 보이면 모델이 데이터의 일부 구조를 포착하지 못한 것)
분석: 현재 잔차는 비교적 균일하게 분포되어 있습니다
3. 잔차 히스토그램
*해석 방법: 정규분포에 가까우면 모델의 가정이 만족됩니다
분석: 현재 잔차는 0을 중심으로 종 모양 분포를 보입니다
'''모델 평가 지표
MAE: 16.0405
MSE: 437.5499
RMSE: 20.9177
R² Score: 0.9450
[ 13.92949113 -18.96480697 2.95358189 1.71439448 19.51398634
13.93708385 30.41084999 -0.23263024 3.99328268 2.27608417
24.46811331 3.34460348 -39.57263226 -32.0762766 7.43394693
7.28595933 12.93601078 -0.83264328 -3.18369413 6.25923943
15.6116959 -40.28694257 35.64751246 16.44550436 -1.88659954
8.95161196 -10.09388112 6.09639415 43.72307103 -3.24457474
35.55801852 20.3673979 23.0531887 -29.91622749 -14.81118657
-33.39486467 3.93362379 -11.4040237 -41.79056837 0.0854767 ]
- 잔차 분석
잔차 평균: 1.9560
잔차 표준편차: 20.8260
잔차 최솟값: -41.7906
잔차 최댓값: 43.7231
트러블 슈팅
# 평가 지표 계산(MAE, MSE, RMSE, R^2 Score)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)여기는 평가 지표계산 메서드이니 자동완성..
# 잔차 계산하기 (y_actual = y_predicted + residuals)
residuals = y_test - y_pred이것도 암기.. 이것도 맨첨에 1 - y_pred로 잘 못 넣어서
1번,2번 그래프가 이상하게 나옴
ROC Curve와 임계값 최적화
ROC Curve를 그리고 최적의 임계값(threshold)을 찾아 모델 성능을 개선하세요.
요구사항
- make_classification으로 불균형 데이터가 생성이 되어있습니다. (
weights=[0.9, 0.1])
- 구조 파악 및 훈련/테스트 데이터셋으로 분할하세요(7:3), (stratify=y)
- Logistic Regression 모델을 만들고 학습을 진행하세요.
- 예측을 진행하는데 '예측 확률(probability)'에 대해 양성(1)일 확률만 추출합니다.
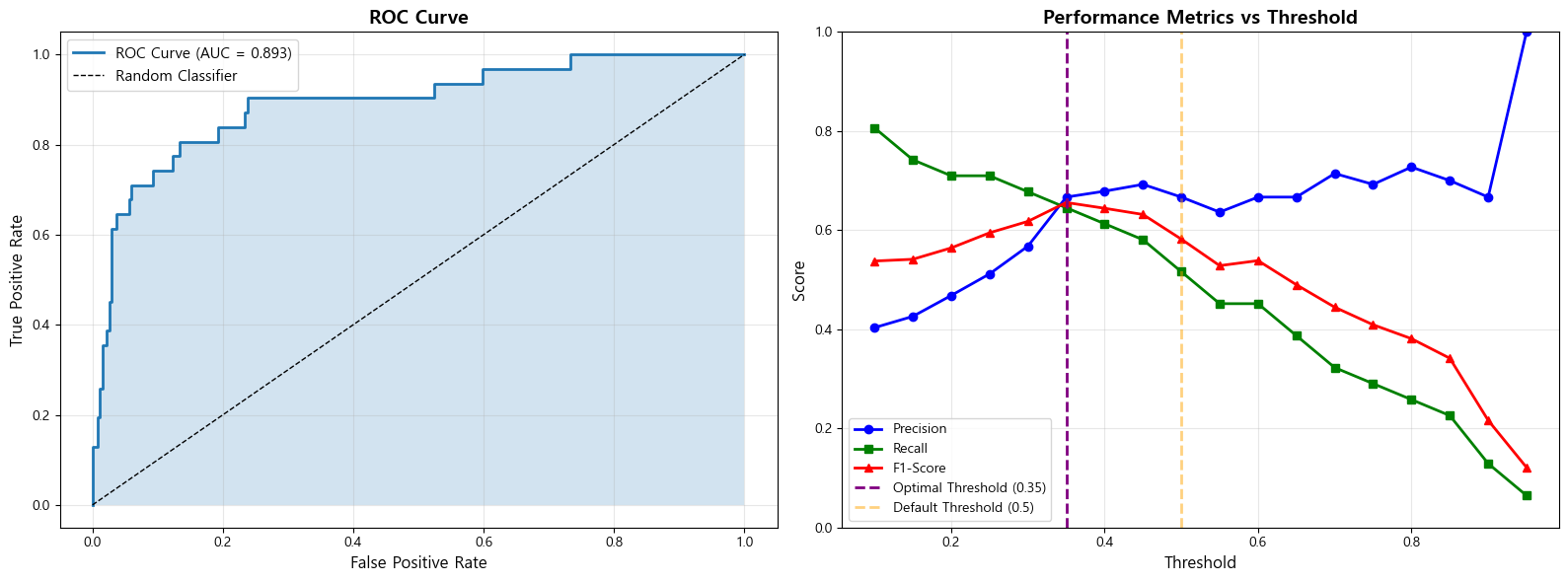
- ROC Curve 그리기 (AUC 값 표시)
- roc_curve와 roc_auc_score 함수를 활용하여 결과를 저장합니다.
- 임계값을 0.1 ~ 0.9까지 변경하면서: Precision, Recall, F1-Score 계산 결과를 비교
- F1-Score가 최대가 되는 최적 임계값 찾습니다.
- 기본 임계값(0.5)과 최적 임계값의 성능 비교
- 0.5일 때의 예측 결과와 최적의 임계값일 때의 예측 결과를 각각 지표(Precision, Recall, F1-Score)를 데이터프레임 형태로 정리합니다.
- 기본 임계값일 때의 Confusion Matrix을 만들고 FN(놓친 양성)을 출력합니다.
- 최적의 임계값일 때의 Confusion Matrix을 만들고 FN(놓친 양성)을 출력합니다.
- 최종적으로 결과에 대한 시각화를 진행합니다.
- ROC 커브를 시각화합니다.
- Threshold 변화에 따른 Precision/Recall/F1-Score의 변화를 하나의 그래프에 그립니다.
- 추가로, 기본 임계값(0.5)일 때의 수직선, 최적의 임계값일 때의 수직선을 추가합니다.
- 결과를 확인하고 분석해보세요!
내가 한 풀이
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score, precision_score, recall_score, f1_score, confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 불균형 데이터 생성 및 구조 확인
X, y = make_classification(
n_samples=1000,
n_features=20,
n_classes=2,
weights=[0.9, 0.1], # 10% 양성, 90% 음성
random_state=42
)
print(f"데이터 크기: {X.shape}")
# 1. 데이터 분할 (7:3), stratify=y 옵션 추가
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 2. 모델 학습
model = LogisticRegression(random_state=42, max_iter=1000)
model.fit(X_train, y_train)
# 양성(1)일 예측 확률 구하기
y_prob = model.predict_proba(X_test)[:, 1] # 양성(1)일 때
# ROC Curve 계산 (정답과 예측 확률로 평가)
fpr, tpr, thresholds_roc = roc_curve(y_test, y_prob)
roc_auc = roc_auc_score(y_test, y_prob)
# 임계값별 성능 계산
thresholds = np.arange(0.1, 1.0, 0.05) # 0.1부터 1.0 사이를 0.05 변화하면서
precision_scores = []
recall_scores = []
f1_scores = []
# for thr in thresholds:
# # 양성일 예측 확률이 현재 threshold 이상이면 1, 그렇지 않으면 0
# y_pred_thr = (y_pred_proba[:, 1] >= thr).astype(int)
# # 현재 threshold로 구한 예측 클래스로 각 지표 계산하기
# p = precision_score(y_test, y_pred_thr, zero_division=0)
# r = recall_score(y_test, y_pred_thr, zero_division=0)
# f1 = f1_score(y_test, y_pred_thr, zero_division=0)
for threshold in thresholds:
# 현재 threshold를 기준으로 했을 때의 성능 지표
y_pred_threshold = (y_prob > threshold).astype(int) # threshold 기준에 따른 클래스 예측
# 그에 따른 각 지표 계산 및 각 리스트에 저장
precision_scores.append(precision_score(y_test, y_pred_threshold, zero_division=0))
recall_scores.append(recall_score(y_test, y_pred_threshold, zero_division=0))
f1_scores.append(f1_score(y_test, y_pred_threshold, zero_division=0))
print(f1_scores)
# 최적 임계값 찾기 (f1-score가 제일 높을 때)
optimal_idx = f1_scores.index(max(f1_scores))
optimal_threshold = thresholds[optimal_idx]
max_f1 = f1_scores[optimal_idx]
print("*임계값 최적화 결과")
print(f"최적 임계값: {optimal_threshold:.2f}")
print(f"최대 F1-Score: {max_f1:.4f}")
print(f"해당 Precision: {precision_scores[optimal_idx]:.4f}")
print(f"해당 Recall: {recall_scores[optimal_idx]:.4f}")
# 기본 임계값(0.5)과 최적 임계값 비교
default_pred = (y_prob >= 0.5).astype(int)
optimal_pred = (y_prob >= optimal_threshold).astype(int)
# 기본 임계값 (0.5) vs 최적 임계값마다의 지표 성능 비교 데이터프레임
comparison_df = pd.DataFrame({
'Threshold': [0.5, optimal_threshold], # 0.5와 최적의 threshold
'Precision': [
precision_score(y_test, default_pred, zero_division=0), # 0.5일떄
precision_scores[optimal_idx]# 임계값일때
],
'Recall': [
recall_score(y_test, default_pred, zero_division=0),
recall_scores[optimal_idx]
],
'F1-Score': [
f1_score(y_test, default_pred, zero_division=0),
f1_scores[optimal_idx]
]
})
print(comparison_df)
# 각 임계값에 따른 Confusion Matrix 비교
cm_default = confusion_matrix(y_test, default_pred)
cm_optimal = confusion_matrix(y_test, optimal_pred)
# 각 Confusion Matrix에서 FN을 추출하세요
print("*기본 임계값 (0.5) Confusion Matrix:")
print(cm_default)
print(f"FN (놓친 양성): {cm_default[None]}")
print(f"*최적 임계값 ({optimal_threshold:.2f}) Confusion Matrix:")
print(cm_optimal)
print(f"FN (놓친 양성): {cm_optimal[None]}")
# 시각화
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# 1. ROC Curve 그리기
# X축: FPR, Y축: TPR
axes[0].plot(fpr, tpr, linewidth=2, label=f'ROC Curve (AUC = {roc_auc:.3f})')
axes[0].plot([0, 1], [0, 1], 'k--', linewidth=1, label='Random Classifier')
axes[0].fill_between(fpr, tpr, alpha=0.2)
axes[0].set_xlabel('False Positive Rate', fontsize=12)
axes[0].set_ylabel('True Positive Rate', fontsize=12)
axes[0].set_title('ROC Curve', fontsize=14, fontweight='bold')
axes[0].legend(fontsize=11)
axes[0].grid(True, alpha=0.3)
# 2. Threshold에 따른 지표 변화
# 2-1. 각 지표
axes[1].plot(thresholds, precision_scores, 'b-', linewidth=2, label='Precision', marker='o')
axes[1].plot(thresholds, recall_scores, 'g-', linewidth=2, label='Recall', marker='s')
axes[1].plot(thresholds, f1_scores, 'r-', linewidth=2, label='F1-Score', marker='^')
# 2-2. 기준 threshold(0.5와 최적)에 대한 수직선
axes[1].axvline(x=optimal_threshold, color='purple', linestyle='--',
linewidth=2, label=f'Optimal Threshold ({optimal_threshold:.2f})')
axes[1].axvline(x=0.5, color='orange', linestyle='--',
linewidth=2, alpha=0.5, label='Default Threshold (0.5)')
axes[1].set_xlabel('Threshold', fontsize=12)
axes[1].set_ylabel('Score', fontsize=12)
axes[1].set_title('Performance Metrics vs Threshold', fontsize=14, fontweight='bold')
axes[1].legend(fontsize=10)
axes[1].grid(True, alpha=0.3)
axes[1].set_ylim([0, 1])
plt.tight_layout()
plt.show()
'''
1. ROC Curve 해석 (AUC가 1에 가까울수록 좋은 모델)
분석:
2. 임계값 최적화
분석:
'''데이터 크기: (1000, 20)
[0.5376344086021505, 0.5411764705882353, 0.5641025641025641, 0.5945945945945946, 0.6176470588235294, 0.6557377049180327, 0.6440677966101694, 0.631578947368421, 0.5818181818181818, 0.5283018867924528, 0.5384615384615384, 0.4897959183673469, 0.4444444444444444, 0.4090909090909091, 0.38095238095238093, 0.34146341463414637, 0.21621621621621623, 0.12121212121212122]
임계값 최적화 결과
최적 임계값: 0.35
최대 F1-Score: 0.6557
해당 Precision: 0.6667
해당 Recall: 0.6452
Threshold Precision Recall F1-Score
0 0.50 0.666667 0.516129 0.581818
1 0.35 0.666667 0.645161 0.655738
기본 임계값 (0.5) Confusion Matrix:
[[261 8][ 15 16]]
FN (놓친 양성): [[[261 8][ 15 16]]]
*최적 임계값 (0.35) Confusion Matrix:
[[259 10][ 11 20]]
FN (놓친 양성): [[[259 10][ 11 20]]]
트러블 슈팅
axes[1].plot(thresholds, precision_scores, 'b-', linewidth=2, label='Precision', marker='o')
axes[1].plot(thresholds, recall_scores, 'g-', linewidth=2, label='Recall', marker='s')
axes[1].plot(thresholds, f1_scores, 'r-', linewidth=2, label='F1-Score', marker='^')처음에 y축에 다 같은 값을 넣어서 첫번째 그래프와 비슷하게 나옴
양성(1)일 예측 확률 구하기
y_prob = model.predict_proba(X_test)[:, 1] # 양성(1)일 때
ROC Curve 계산 (정답과 예측 확률로 평가)
fpr, tpr, thresholds_roc = roc_curve(y_test, y_prob)
roc_auc = roc_auc_score(y_test, y_prob)
앞서 본것 처럼 양성 일때 두번째 컬럼 추출
그리고 roc_curve 이 메서드 순간 배운거 기억 안남
각 임계값에 따른 Confusion Matrix 비교
cm_default = confusion_matrix(y_test, default_pred)
cm_optimal = confusion_matrix(y_test, optimal_pred)
컨퓨젼 매트릭스도 기억
각 Confusion Matrix에서 FN을 추출하세요
print("*기본 임계값 (0.5) Confusion Matrix:")
print(cm_default)
print(f"FN (놓친 양성): {cm_default[[1,0]]}")
print(f"*최적 임계값 ({optimal_threshold:.2f}) Confusion Matrix:")
print(cm_optimal)
print(f"FN (놓친 양성): {cm_optimal[1, 0]}")
FN 값
## KNN - 와인 품질
배경: 와인의 화학적 특성을 기반으로 와인의 품질을 분류하는 KNN 모델을 만드세요.
1. 데이터셋을 읽어오고, 기본적인 구조를 확인합니다.
2. feature와 target을 분리합니다.
- feature: 'Alcohol', 'Acidity', 'Sugar', 'pH'
- target: 'Quality'
3. 스케일링 없을 때, StandardScaler 적용했을 때, MinMaxScaler 적용했을 때의 정확도를 비교합니다.
- 3가지 경우에 대해 각각 훈련/테스트 데이터 분할과 K=5의 모델 생성/학습 진행
- scaling_comparison 변수에 스케일링 방법과 정확도를 기록합니다.
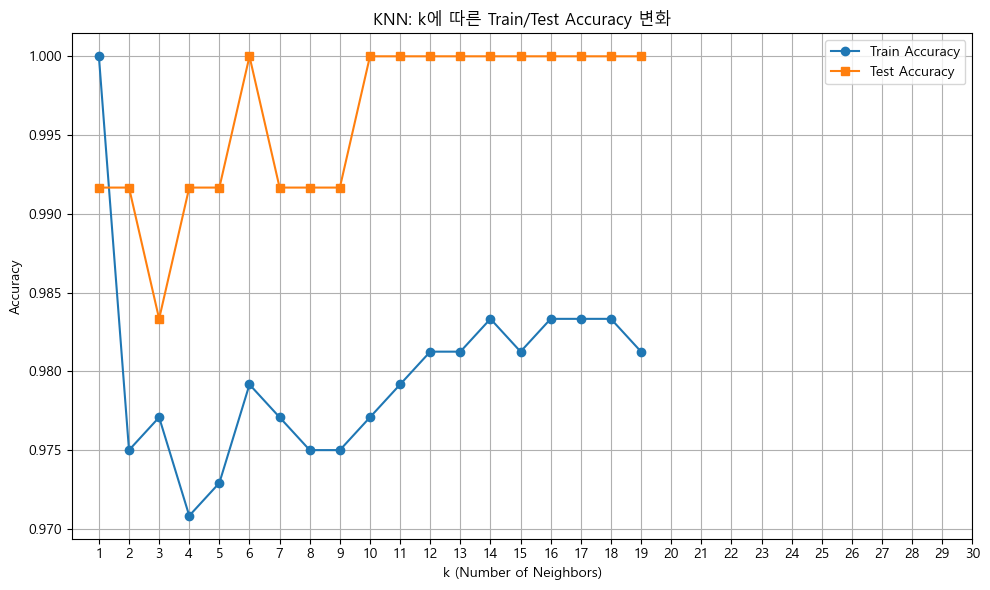
4. 1부터 19까지의 K를 반복하여 최적의 K를 찾습니다.
- 각 K에 대해 모델을 생성/학습을 진행
- k_results에다가 현재 k값과 훈련 정확도, 테스트 정확도를 기록합니다.
5. 테스트 성능이 제일 높은 최적의 K로 거리 측정 방식에 따라서 KNN 모델을 학습합니다.
- 거리 측정(metric 매개변수): 유클리드 거리, 맨해튼 거리
- 학습과 예측을 진행한 뒤, y_test와 y_pred에 대한 분류 평가 지표를 기록합니다.
- Accuracy, Precision, Recall, F1-score
- 기록한 결과를 데이터프레임 형태로 만들어서 출력하세요.
내가 한 풀이import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report,precision_score, recall_score, f1_score
import matplotlib.pyplot as plt
import seaborn as sns
1. 데이터셋을 읽고, 기본 구조를 확인하세요.
df = pd.read_csv('wine_quality.csv')
2. feature 와 target을 분리하세요:
X = df.drop('Quality', axis=1)
y = df['Quality']
스케일링 없이, StandardScaler 적용, MinMaxScaler 적용한 세 가지 경우의 정확도를 비교하세요:
scaling_comparison = [] # 3가지 경우에 대한 정확도를 기록하는 리스트
2-1. 스케일링 없음
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)
scaling_comparison.append({
'Scaling': 'None',
'Accuracy': model.score(X_test, y_test)
})
2-2. StandardScaler
scaler = StandardScaler()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model.fit(X_train_scaled, y_train) # 모델 학습
scaling_comparison.append({
'Scaling': 'StandardScaler',
'Accuracy': model.score(X_test_scaled, y_test)
})
2-3. MinMaxScaler
scaler = MinMaxScaler()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model.fit(X_train_scaled, y_train)# 모델 학습
scaling_comparison.append({
'Scaling': 'MinMaxScaler',
'Accuracy': model.score(X_test_scaled, y_test)
})
2-4. 결과를 데이터프레임으로 만들고 출력하기
comparison_df = pd.DataFrame(scaling_comparison)
print(comparison_df)
3. 최적의 K 찾기
k_results = [] # 결과를 저장하는 리스트(k값, 훈련 정확도, 테스트 정확도)
for k in range(1, 20):
model = KNeighborsClassifier(n_neighbors=k) # 모델 생성
model.fit(X_train_scaled, y_train) # 모델 학습(X_train과 y_train으로)
# 결과 저장
k_results.append({
'k': k,
'train_accuracy': model.score(X_train_scaled, y_train),
'test_accuracy': model.score(X_test_scaled, y_test),
})3-2. 결과를 데이터프레임으로 만들고 출력하기
k_df = pd.DataFrame(k_results)
print(k_df)
# 3-3. k의 변화에 따른 학습/테스트 정확도를 같은 그래프에 선그래프로 그리세요
plt.figure(figsize=(10, 6))
plt.plot(k_df['k'], k_df['train_accuracy'], marker='o', label='Train Accuracy')
plt.plot(k_df['k'], k_df['test_accuracy'], marker='s', label='Test Accuracy')
plt.xlabel('k (Number of Neighbors)')
plt.ylabel('Accuracy')
plt.title('KNN: k에 따른 Train/Test Accuracy 변화')
plt.xticks(range(1, 31))
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
3-4. 위 결과에서 테스트 정확도가 가장 높을 때의 최적의 k를 추출하세요
best_k_row = k_df.loc[k_df['test_accuracy'].idxmax()]
best_k = int(best_k_row['k'])
4. 최적 k 값으로 다양한 거리 측정 방식을 비교하세요:
metric_results = [] # 거리 측정 방식에 따른 정확도 저장 리스트
for metric in ['euclidean', 'manhattan']: # 유클리드, 맨해튼
# KNN 모델을 생성하고 학습과 예측을 진행하세요!
# n_neighbors: 최적의 k, metric: 거리 측정 방식
model = KNeighborsClassifier(n_neighbors=best_k, metric=metric)
model.fit(X_train, y_train) # 학습
y_pred = model.predict(X_test) # 예측
# 거리 측정 방식에 따른 성능지표(Accuracy, Precision, Recall, F1-Score)를 저장하세요
metric_results.append({
'Metric': metric,
'Accuracy': accuracy_score(y_test, y_pred),
'Precision': precision_score(y_test, y_pred, average='weighted'),
'Recall': recall_score(y_test, y_pred, average='weighted'),
'F1': f1_score(y_test, y_pred, average='weighted')
})# 4-1. 결과를 데이터 프레임으로 만들고 결과를 출력하세요.
metrics_df = pd.DataFrame(metric_results)
print(metrics_df)
Scaling Accuracy
0 None 0.991667
1 StandardScaler 0.991667
2 MinMaxScaler 0.991667
k train_accuracy test_accuracy
0 1 1.000000 0.991667
1 2 0.975000 0.991667
2 3 0.977083 0.983333
3 4 0.970833 0.991667
4 5 0.972917 0.991667
5 6 0.979167 1.000000
6 7 0.977083 0.991667
7 8 0.975000 0.991667
8 9 0.975000 0.991667
9 10 0.977083 1.000000
10 11 0.979167 1.000000
11 12 0.981250 1.000000
12 13 0.981250 1.000000
13 14 0.983333 1.000000
14 15 0.981250 1.000000
15 16 0.983333 1.000000
16 17 0.983333 1.000000
17 18 0.983333 1.000000
18 19 0.981250 1.000000
Metric Accuracy Precision Recall F1
0 euclidean 0.983333 0.983918 0.983333 0.983174
1 manhattan 0.991667 0.991815 0.991667 0.991628트러블 슈팅
일단 스탠다드, 민맥스 둘다 훈련데이터, 테스트데이터가 스케일링 된 데이터가 들어가야 함
# 2-2. StandardScaler
scaler = StandardScaler()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model.fit(X_train_scaled, y_train) # 모델 학습
scaling_comparison.append({
'Scaling': 'StandardScaler',
'Accuracy': model.score(X_test_scaled, y_test)
})
# 2-3. MinMaxScaler
scaler = MinMaxScaler()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model.fit(X_train_scaled, y_train)# 모델 학습
scaling_comparison.append({
'Scaling': 'MinMaxScaler',
'Accuracy': model.score(X_test_scaled, y_test)
})그리고 여기 코드문도 순간 당황 한거 같다.
# 3-2. 결과를 데이터프레임으로 만들고 출력하기
k_df = pd.DataFrame(k_results)
print(k_df)
# 3-3. k의 변화에 따른 학습/테스트 정확도를 같은 그래프에 선그래프로 그리세요
plt.plot(k_df['k'], k_df['train_accuracy'], marker='o', label='Train Accuracy')
plt.plot(k_df['k'], k_df['test_accuracy'], marker='s', label='Test Accuracy')# 3-4. 위 결과에서 테스트 정확도가 가장 높을 때의 최적의 k를 추출하세요
best_k_row = k_df.loc[k_df['test_accuracy'].idxmax()]
best_k = int(best_k_row['k'])| 개념 / 코드 | 설명 |
|---|---|
| k_df | 원본 데이터. 서로 다른 k 값별 훈련 정확도와 테스트 정확도가 모두 기록된 데이터프레임 |
| k_df['test_accuracy'] | 테스트 정확도만 모아둔 시리즈(Series) |
| .idxmax() | 최대값의 인덱스(Index) 레이블을 반환하는 함수 |
| k_df['test_accuracy'].idxmax() | 테스트 정확도 열에서 가장 큰 값(최고 정확도)을 가지는 행의 인덱스를 반환 |
| k_df.loc[...] | 해당 인덱스를 사용해 해당 행 전체를 추출 |
| best_k_row | 가장 높은 테스트 정확도를 가진 행(최적 k 값)을 저장한 변수 |
- 추출: 값만 정수로 변환
best_k = int(best_k_row['k'])