지도학습
- 출력값이 수치형인 경우 회귀 문제이다.
- 출력값이 범주형인 경우 분류 문제이다.
비지도학습 - 출력값이 없다.
- 비슷한 아이들끼리 뭉치거나(군집 찾기), 변수의 복잡성을 낮추기 위한 자원 축소 등이 포함된다.
- GAN등의 새로운 기법이 등장하고 있다.
Reinforcement Learning - 구체적인 행동에 대한 지시 없이 보상을 가장 많이 받는 방식을 스스로 찾아 학습하게 한다.
기타 - Transfer Learning : 기존에 학습된 모델을 끌고 와 새로운 모델을 만들기
- Semi supervised Learning : 적절히 섞기
Feature Engineering
원시 데이터를 다루고 있는 문제를 더 잘 표현할 수 있는 특징(feature)로 변환하는 과정으로 'more flexibility', 'simpler model','better results'가 특징이다.
머신러닝에서 오류의 종류
- 학습오류: 학습 데이터를 사용해 모델을 생성하고 측정한 오류
- 예측오류: 테스트 데이터를 모델에 적용해 측정한 오류
- 일반화오류: 우리는 현실에서 알기 힘든, 이상적인 '기본 데이터'를 모델에 적용할 때 예상되는 오류. 이건 알 수가 없어서 현실에서는 예측오류가 일반화 오류로 대체되고, 학습오류와 에측오류가 최소화 되는 것을 목표로 한다.
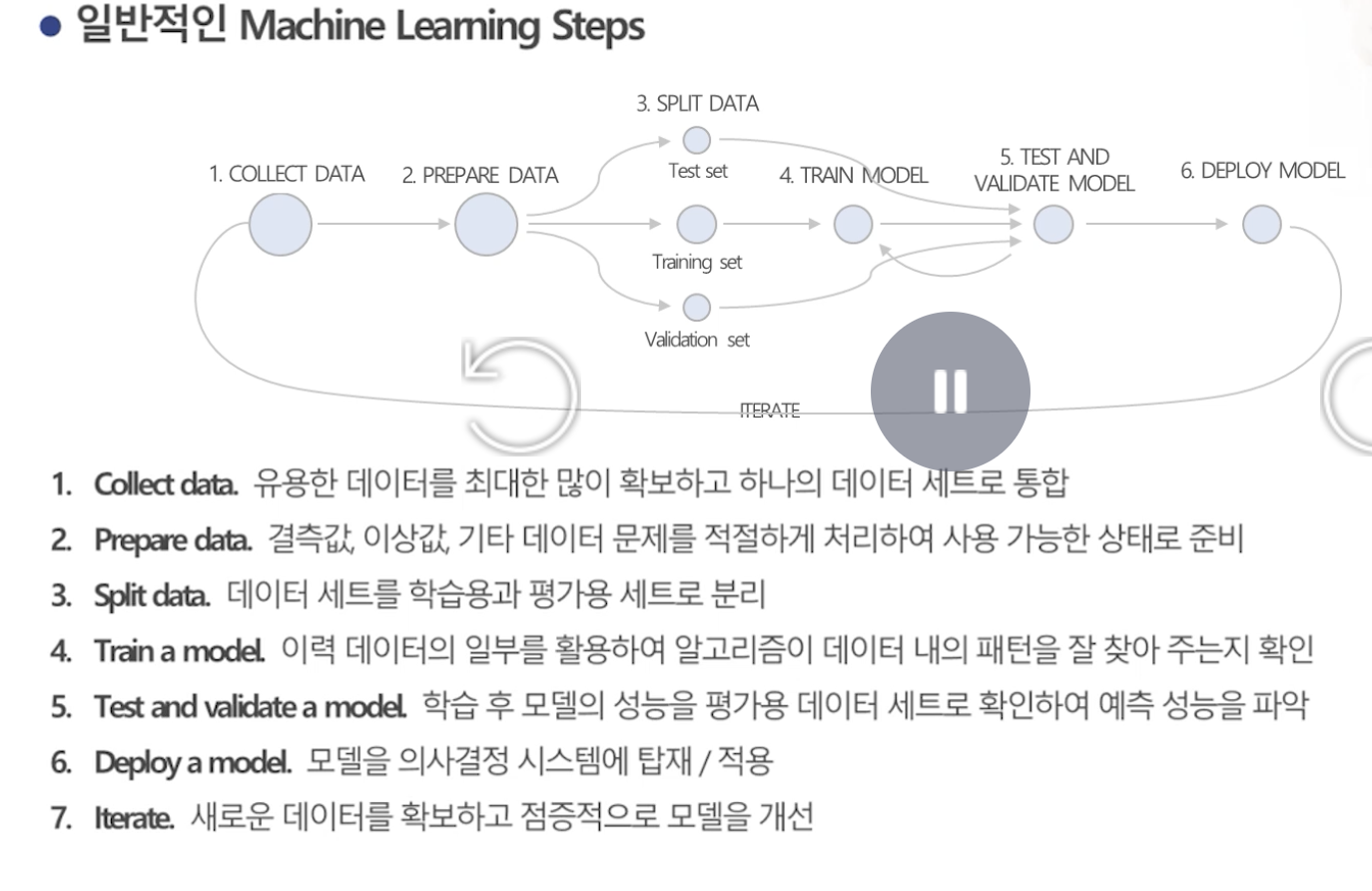
Data Split과 모델 검증
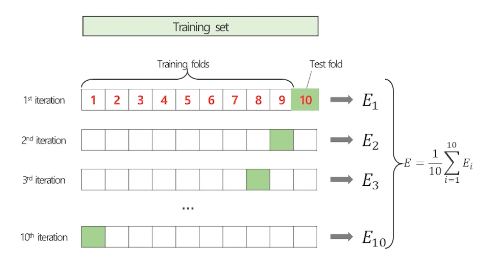
- Cross Validation(교차검증): k-fold라고도 함. 전체 데이터 세트를 임의로 k개 그룹으로 나누고, 그 가운데 하나의 그룹을 돌아가며 테스트 데이터 세트로, 나머지 k-1개 그룹은 학습용 데이터 세트로 사용하는 방법. '이 알고리즘이 우리 데이터에 적절한 선택인가?' 혹은 '이 모델에 적절한 hyperparameter는?'이란 질문에 답해준다.
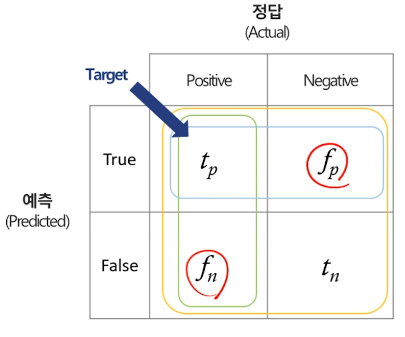
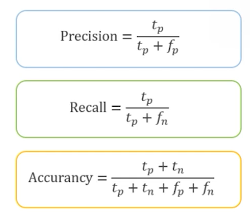
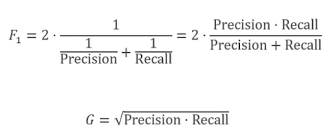
 분류모델에서 타겟으로 범주형 데이터가 들어올 경우 반드시 Confusion Matrix를 사용해야 한다. 기준은 나의 예측모델이다.
분류모델에서 타겟으로 범주형 데이터가 들어올 경우 반드시 Confusion Matrix를 사용해야 한다. 기준은 나의 예측모델이다.

삼성전자 C-Lab 21기 Creative Leader SW개발자 (쪼랩)