데이터 전처리의 필요성
- 데이터 품질이 높은 경우에도 전처리는 필요하다. 구조적 형태가 분석 목적에 적합하지 않을 수 있고, 사용하는 툴, 기법에서 요구하는 데이터 형태로 있어야하고, 데이터가 너무 많을 수도 있기 때문이다.
데이터 품질을 낮추는 요인 - 불완전(Incomplete): 데이터 필드가 비어있는 경우
- 잡음(Noise): 데이터에 오류가 포함된 경우
- 모순(Inconsistency): 데이터간 정합성, 일관성이 결여된 경우. (다른 데이터는 다 20인데, 한 곳은 스무살이라고 되어있음)
데이터 전처리의 주요 기법 - 정제(Clearing) :
결측값(Missing value)처리
-- 이상값 확인은 IQR기반 기법(Box plot)의 수치적 탐색 방법(Tukey, Carling)과
-- Liklihood(전체에서 정상인 확률, 전체에서 이상치인 확률), Variance(정규분포에서 97.5%이상에 위치한 값)등의 확률, 분포를 이용한 방법과
-- Nearest-neighbor(모든 데이터 쌍의 거리 계산), Density, Clustering등의 기계학습 기법을 이용하는 방법이 있다.(거리 기반)
-- Local Outlier Factor은 밀도도 낮고 편차가 큰 샘플을 감지한다.(거리+밀도)
기타 잡음(Noise)처리로 구간화, 회귀, 군집화를 한다.
-- 중복처리. (DB의 정규화)
-- 28, 스물여덟 같이 개체의 식별
-
통합(Integration) : 결합(Join)
-
축소(Reduction) : Filtering(필요한 데이터만 추출하는 법),Sampling(전수조사vs모집단을 대표하는 표본조사), 차원의 축소(차원의 저주 때문에), 연구 결과를 왜곡시키는 오차(by 조사자, 면접자, 응답자) 조심
-- Simple Random Sampling: 단순임의추출
-- Stratified Random Sampling: 층화추출. 데이터 내에서 지정한 그룹 별로 지정한 비율 만큼의 데이터를 임의로 선택
-- Systematic Sampling: 계통추출. k 번째 요소를 표본으로 선정. 패턴 가지고 있으면 모집단 반영 못한다.
-- Cluster Sampling : 군집추출, 집락추출. 군집간 동질성, 군집내 이질성인 경우 사용.
-- Training-Test Data Split -
변환(Transformation)
-- Pivot, Unpivot(wide form->long form)
-- 파생변수 : 새로운 변수를 만든다. 분석가의 주관성이 들어갈 수 있다. 논리적인 타당성을 갖춰야 한다. 주 구매 매장.
-- 요약변수 : 집계. 원 데이터를 분석 Needs에 맞게 종합한 변수. 총 구매 금액, 매장별 방문 횟수
-- Normalization : 데이터 속성 값을 -1~1.0으로 들도록 하는 기법. (Min-max scaling, Z-score 변환, Standard Scaling, Max Absolute Scaling, Robust Scaling...)
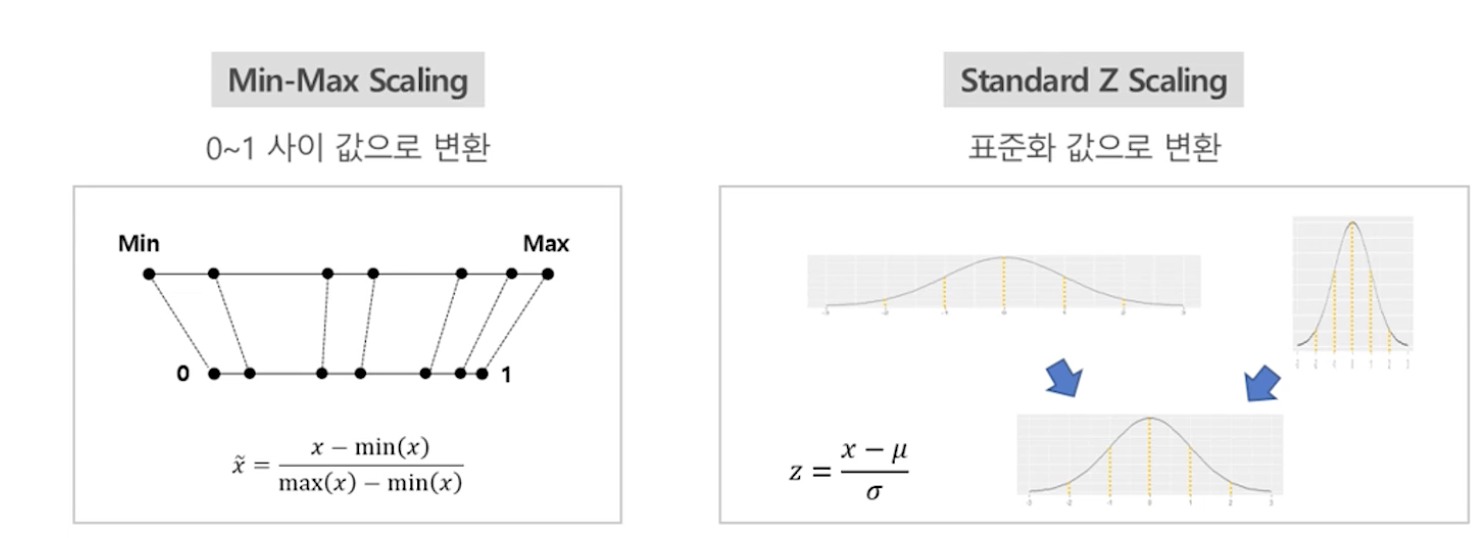

-- Positive Skewed는 sqrt(x)->log->1/x
-- Negatively Skewed는 sqrt(max(x+1)-x)->log(max(x+1)-x)->1/(max(x+1)-x)
