Maximum Likelihood Estimation(MLX)(최대 가능도 추정)
Maximum Likelihood Estimation(MLX)(최대 가능도 추정)이란
observation을 가장 잘 설명하는 θ를 찾아내는 것
예를 들어, 압정을 바닥에 던질 때 나올 수 있는 경우는 두가지가 있다.
case 1: 납작한 부분이 바닥에 떨어지는 경우!
case 2: 비스듬히 떨어지는 경우
경우의 수가 2가지만 있으므로 베르누이 분포를 사용한다.
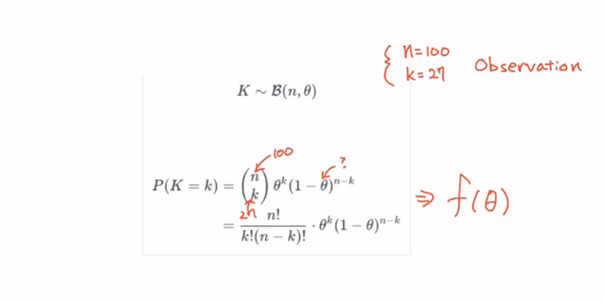
성공률 θ인 베르누이 실행을 n번 독립적으로 반복한 이항 분포에 대한 확률 함수 수식이다.
θ는 압정을 던졌을 때 납작한 부분이 떨어질 확률 p이다.
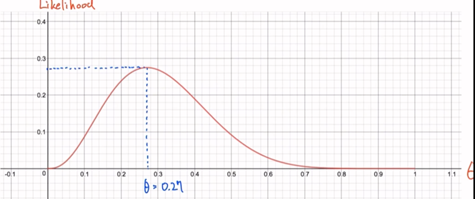
그래프로 나타내면 이와 같다
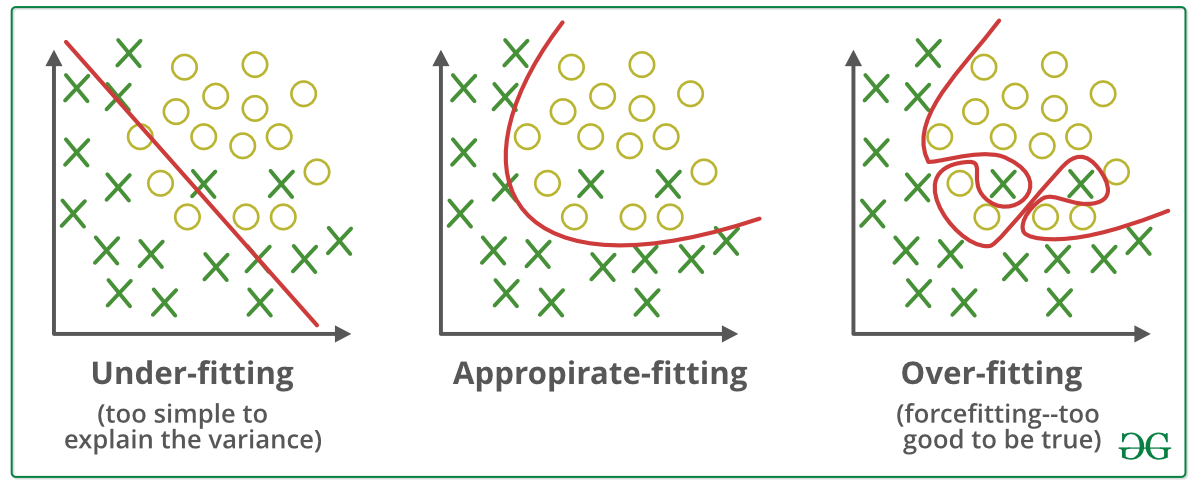
Overfitting(과적합)과 Regularization(정규화)
Overfiting(과적합) 이란
데이터를 과하게 학습한 것이다. 학습 데이터에 너무 최적화를 하다보니, 실제 데이터와 차이가 많이 발생하는 모델을 만들게 되는 현상을 의미한다.
Underfitting(과소적합) 이란
데이터를 덜 학습한 것이다.
Overfiting 을 막는방법
1. More Data(데이터양을 늘린다)
데이터를 적게 모을수록 실제 분포에서 편향된 데이터를 얻을 가능성이 높다. 데이터를 많이 모을수록 실제 분포에 가까운 데이터 set을 얻을 수 있다.
데이터 양이 적을 경우 의도적으로 기존 데이터를 조금씩 변형하고 추가하여 데이터의 양을 늘리기도 하는데 이를 데이터 증식 또는 증강(Data Augmentation)이라고 한다.
2. Less features (피쳐 수를 적게 사용한다)
3. Regularization(가중치 규제 적용)
- Early Stopping : validation Loss가 더이상 낮아지지 않을 때 멈춘다.
- Reducing Network Size
- Weight Decay : neural network weight 파라미터의 크기를 제한 한다.
- Dropout
- Batch Normalization

Towards the goal 👀