Database 최적화하는 방법
1. WHERE 절을 사용하여 쿼리의 결과를 제한한다.
이것은 성능에 가장 영향을 미치는 것으로 클라이언트에게 모든 결과가 아니라 꼭 필요한 결과만 반환하도록 한다.
이렇게하면 쓸모없는 네트워크 트래픽을 감소시킬 수 있으며 쿼리 성능도 향상된다.
2. 테이블의 모든 컬림이 아닌 필요한 컬럼의 레코드만 반환한다.
역시 성능에 영향을 미치며 클라이언트에게 필요한 컬럼의 데이터만 반환하여 쓸모없는 트래픽을 감소시키고 쿼리 성능을 향상시킨다.
3. VIEW 또는 Stored procedure을 사용해본다.
긴 쿼리문을 네트워크로 전송하는것에 비해 view나 stored procedure는 그 이름만 전송하기 때문에(파라미터가 있다면 이것도 포함) 네트워크 트래픽을 감소시킬 수 있다. 게다가 보안관리까지 할 수 있기 때문에 사용자에게 숨겨야하는 컬럼의 액세스 제한을 할 수 있다.
4. SQL Server 커서의 사용을 피한다.
SQL Server 커서는 select문에 비해 성능상 좋지 않다.
행 단위의 처리가 필요하다면 상관질의나 유도된 테이블을 사용하도록 노력하는것이 좋다.
5. 테이블의 row 수를 알고 싶다면 select count(*) 대신 다른 방법을 사용한다.
select count(*) 의 경우 테이블을 스캔해서 전체 row를 반환하기 때문에 큰 테이블에서는 시간이 오래 걸린다.
이 경우 sysindexs 시스템 테이블을 사용한다. 이 테이블의 rows 컬럼은 각 테이블의 총 row개수를 값으로 가지고 있다.
따라서 select count(*) 대신 다음의 쿼리를 사용할 수 있다.
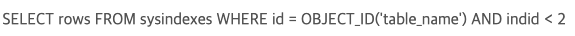
이 방법은 select count(*) 에 걸리는 시간을 단축시켜준다.
6. 트리거 대신 제약조건을 사용한다.
제약조건은 트리거보다 성능면에서 훨씬 효율적이다. 따라서 가능한 제약조건을 사용하는 것이 더 좋다.
7. 임시테이블 대신 테이블 변수를 사용한다.
테이블 변수는 임시테이블에 비해 잠금과 로깅 작업에 적은 리소스가 소모된다. 따라서 가능한 테이블 변수를 사용하는것이 좋다.
8. HAVING절의 사용을 피한다.
Having절은 GROUP BY에 의한 결과를 제한할때 사용한다.
GROUP BY에 Having절을 사용하였을 경우 GROUP BY에 의해서 결과들을 모두 집계한 다음 Having절에 명시한 조건으로 맞지 않는 결과를 버리게 된다.
대부분의 경우 Having절의 필요없이 GROUP BY와 WHERE절 만으로 원하는 결과를 얻을 수 있다.
9. DISTINCT 문의 사용을 피한다.
DISTINCT문을 사용할 경우 소트에 따른 성능 하락이 있기 때문에 꼭 필요한 경우에만 사용해야한다.
10. 결과에 적용된 행의 갯수를 표시하지 않아도 된다면 Procedure에 SET NOCOUNT ON을 추가한다.
몇개의 행이 적용되었는지가 전달되지 않기 때문에 네트워크 트래픽이 감소하게된다.
11. 처음 몇개의 행만 필요하다면 TOP나 SET ROWCOUNT문을 사용한다.
결과 전체가 아닌 일부분만 반환하기 때문에 네트워크 트래픽을 감소시킬 수 있다.
12. 몇개 로우의 빠른 반환이 필요하다면 FAST number_rows 힌트를 사용한다.
이를 사용하면 n row를 빠르게 얻을 수 있으며 이후 쿼리는 계속 실행되서 전체 결과를 만들어낸다.
13. UNION 대신에 UNION ALL 을 사용한다.
UNION ALL은 row의 중복검사를 하지 않는 반면에 UNION은 중복행이 없더라도 중복검사를 수행하기 때문에 UNION ALL의 처리가 더 빠르게 처리된다.
14. Query에 Optimizer Hint를 사용하지 않는다.
SQL Server의 query optimizer는 매우 뛰어나기 때문에 임의로 query에 optimizer hint를 사용할 경우 대부분의 경우 query성능에 안좋은 영항을 미친다.
