오늘부터 시각지능 딥러닝에 들어갔습니다.
딥러닝 복습
지난 딥러닝시간에 tensorflow의 keras를 가지고 딥러닝을 공부했었습니다. keras에는 두 가지의 모델을 배웠습니다. 딥러닝의 모델로는 Sequential API와 Funtional API를 배웠습니다. Sequential은 순차적으로 Layer을 쌓는 모델이엿고 Funtional을 Layer을 사슬처럼 또는 조절하면서 연결하는 모델을 배웠습니다. 또 Functional과 함께 Locally Connected도 배웠습니다.
딥러닝 복습 겸 추가 코드
이번 복습에는 BatchNorm, Dropout 레이어를 추가적으로 사용해주었습니다. 사용 데이터는 28*28 흑백사진입니다.
import tensorflow as tf
from tensorflow import keras
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape=(28,28,1)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(256, activation = 'relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(128, activation = 'relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy, metrics=['accuracy'], optimizer='adam')
model.summary()
Dropout은 과적합을 방지해주는 역할을 합니다. BatchNormalization의 batch는 학습하는 전체 데이터를 의미합니다. 미니 배치의 분포가 급격하게 바뀌는 현상을 convariate shift라고 하는데 이런 형상을 방지라고자 사용합니다.(미니 배치의 분포를 정규화 해줍니다.) 부가적인 기술 효과로는 히든레이어를 걸친 값들에 대해서 정규화를 걸쳐 성능 향상을 노린 기술입니다.
시각지능 딥러닝
Neural Network는 첫 히든레이어가 InputLayer로부터 생성된 간단한 특징으로부터 특징을 뽑아내고 다음 히든레이어는 그 뽑아낸 특징으로 부터 더 깊은 특징을 뽑아내는 구조를 가지고 있습니다. 딥러닝의 구조에는 엔지니어들의 의도가 담겨 있습니다.
컴퓨터가 이미지 데이터를 인식하기 어려운 이유에는 빛에 따라 경계선을 따기 힘들기 때문입니다. 이런 경계선을 제대로 따지 못하면 컴퓨터는 해당 이미지가 어떤 이미지인지 구별하기 힘듭니다.
CNN 베이직 (Convolutional Neural Network)
이미지 데이터를 차원을 바꾸는 것이 옳은지에 대한 의문을 가지게 되었고 이로 인해 CNN을 사용하게 되었습니다. 필터를 CNN이 스스로 학습을 합니다. fiter의 모양은 앞의 레이어에 따라 모양이 달라지며 필터의 사이즈가 작을수록 정보손실이 적습니다.
Convolution Layer
이미지 구조를 파괴하지 않고 fitter라는 것이 도입이 되서 이미지 데이터의 일부를 하나의 값으로 만들어줍니다. fitter는 일정한 간격으로 입력 데이터를 이동하면서 데이터를 훑으면서 하나의 작은 특징을 가진 이미지로 변환해줍니다. fitter의 크기는 개발자가 정할 수 있으며 데이터를 얼마나 세심하게 혹은 정밀하게 훑을지에 대해서는 Stride를 설정해주면 됩니다.
Stride
만약 77크기의 이미기자 있다고 가정했을때, 33크기의 필터로 데이터를 훑는다고 가정을 하면 다음 레이어의 크기는 55사이즈가 나옵니다. 스트라이드는 공식적으로 (1,1)의 기본상태를 가집니다. 만약 스프라이드에 2라는 값을 주게 되면 해당 결과는 33의 결과를 얻을 수 있습니다.(쉽게 이야기하면 중심점의 이동거리 혹은 설정해준 크기만큼 필터가 데이터를 훑는다라고 이해하면 됩니다.) 이미지 데이터 같은 경우 대체로 높이와 넓이가 같습니다.
공식은 ((N-F) / stride) +1 이 공식입니다.(다음 레이어의 크기를 구하는 공식)
※N은 이전 레이어의 크기이고 F는 필터의 크기를 의미합니다.
정보를 세밀하게 가져오기 위해서는 스트라이드를 작게 설정하면 됩니다. 스트라이드를 설정해주는 이유는 연상량을 줄이기 위해서 사용합니다.
Zero Pad
데이터를 필터를 통해 특징을 가진 데이터들로 추출할 때, 맨 왼쪽 위의 데이터는 한번 밖에 추출이 되지 않습니다. 이런 문제를 해결하고 zero pad를 사용함으로써 추출되는 횟수를 증가 시켜줍니다. 또한 외각의 정보를 더 반영해주는 것 뿐만 아니라 다음 레이어의 사이즈도 유지해주는 기능을 합니다.
padding을 해주는 이유는 외곽의 정보를 더 추출하고자함과 이미지 사이즈를 유지하고자하는 이유가 있습니다.
공식은 (입력 크기 - 커널 크기 + 2 x 패딩 크기) / 스트라이드 + 1 입니다.
padding=same은 입력과 출력의 크기를 동일하게 유지하기 위해 필요한 패딩의 양을 자동으로 계산해주는 옵션입니다.
POOL
MAX_POOLING은 약간의 위치정보가 약간 손실되더라도 가장 중요한 정보로 데이터를 축약합니다. POOLING은 depth에 관여하지 않습니다.
LeNet-5 해석
문서나 논문을 보고 모델의 구조를 해석할 수 있는 능력이 필요합니다.
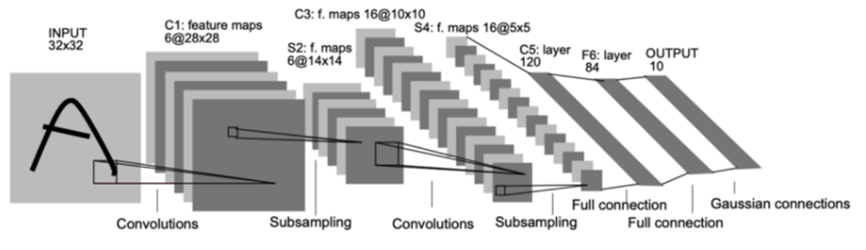
해당 모델은 손글씨 인식 분야에서 유명한 CNN 구조 중 하나입니다. 해당 구조를 분석하면
처음 Input Layer는 (32*32*1)의 구조를 가지고 있습니다. 즉 32*32크기의 데이터이며 흑백이기 때문에 1을 갖습니다. 다음 레이어는 28*28*6 크기를 갖고 해당 레이어 부터 5*5*16의 크기를 갖는 레이어까지 전부 Feture Map입니다. 첫 Input Layer에서 다음 Feture Map이 만들어지게 된 과정은 필터의 크기가 5*5이며 s =1인 필터가 적용이 되었습니다. 여기서 5*5는 필터의 크기를 뜻하고 s는 stride를 의미합니다. 여기서 padding은 사용하지 않아 크기가 줄어든 것을 확인할 수 있습니다. 하지만 여기서 크기 부분이 아닌 depth부분을 보게 되면 1이였던 부분이 6으로 변화된 것을 볼 수 있는데 이는 흑백이 컬러가 됐다 이런것이 아니라 개발자가 설정한 만들고자하는 feature map의 갯수를 의미합니다. 해당 depth는 앞의 레이어와 같은 값을 가져옵니다.
※Feture Map은 입력 이미지(이전 레이어)의 특정 부분과 필터 간의 연산을 통해 만들어진 출력 레이어를 뜻합니다.
실습
다음으로는 실습 코드를 통해 알아보겠습니다. 데이터 호출은 모두 진행했다고 가정하겠습니다.
▶전처리 먼저 x값에 대해서 전처리(정규화)를 진행해 주겠습니다.
from sklearn.preprocessing import MinMaxScaler
x_min = train_x.min()
x_max = train_x.max()
train_x = train_x - x_min / x_max - x_min
test_x = test_x - x_min / x_max - x_min다음으로는 흑백인지 컬러인지 차원을 명시해주겠습니다.
train_x = train_x.reshape(train_x.shape[0], train_x.shape[1], train_x.shape[2], 1)
test_x = test_x.reshape(test_x.shape[0], test_x.shape[1], test_x.shape[2], 1)
print(train_x.shape, train_y.shape, test_x.shape, test_y.shape)지금은 CNN 구조를 사용하기 때문에 Flatten으로 차원을 펴주는 것이 아니기 때문에 뭔저 reshape를 진행해줍니다.
다음으로는 원-핫 인코딩을 진행해야되는데 모델링 코드에 자동으로 진행해주는 코드가 있으므로 해당 코드로 대체하겠습니다.
▶모델링
# 세션클리어
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape=(28,28,1)))
model.add(keras.layers.Conv2D(filters=32, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(filters=32, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D(pool_size=(2,2)))
model.add(keras.layers.Dropout(0.25))
model.add(keras.layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D(pool_size=(2,2)))
model.add(keras.layers.Dropout(0.25))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(loss = keras.losses.sparse_categorical_crossentropy, metrics=['accuracy'], optimizer='adam')
model.summary()
<해당 코드에서 앞서 말한 원-핫 인코딩을 자동으로 해주는 코드는 모델 컴파일 부분에 loss를 보게 되면 keras.losses.sparse_categorical_crossentropy코드를 볼 수 있습니다. 해당 코드가 원-핫 인코딩을 자동으로 진행하는 코드입니다.
이제 자세히 코드를 보게 되면 먼저 Input Layer는 기존 딥러닝과 같지만 레이어를 쌓는 부분에서 차이를 볼 수 있습니다. 먼저 CNN을 활용하기 위해서는 keras.layers.Conv2D()를 사용해줍니다. 해당 코드의 옵션으로 filters = 필터 수를 의미합니다. kernel_size = ()는 필터의 크기를 지정해주는 옵션입니다. padding='same'은 패딩 방식을 지정해주는 옵션인데 방식을 same으로 설정해준 것입니다. 만약 same으로 설정을 해주게 되면 입력 이미지와 동일한 크기의 출력 레이어를 생성해줍니다.
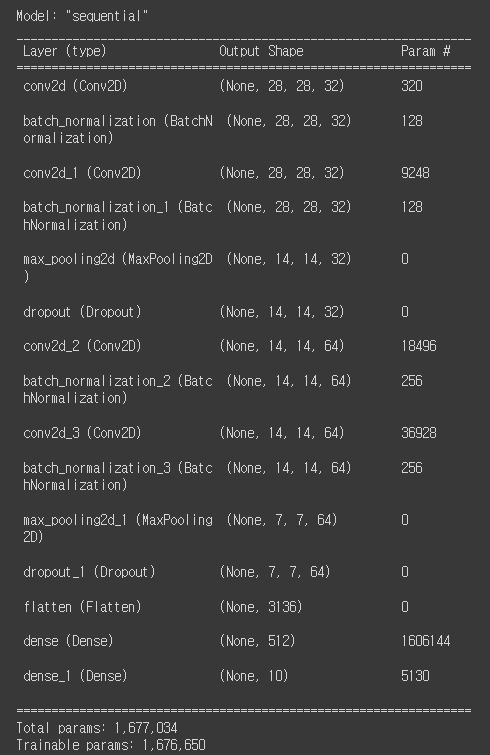
위 코드를 실행하면 이와 같은 모델의 요약본을 볼 수 있는데 이때 Output의 크기를 잘 살펴보면 위의 설명이 조금은 이해가 되는 것 같습니다.
오늘은 시각 딥러닝의 구조인 CNN에 대해서 배웠습니다. 이론이 다소 이해가 안되는 부분이 있는데 많이 복습해봐야겠습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
