어제에 이어 같은 주제로 미니프로젝트를 이어갔습니다.
진행
오늘은 실습 모델인 VGG16모델을 불러와서 실습을 진행하겠습니다. 그리고 추가적으로 어제 0.5에 고정되던 문제 해결 방안을 같이 서술하겠습니다.
문제 해결
모델링에 앞서 어제 포스팅에서 0.5로 계속해서 val_accuracy가 나오는 문제가 있었는데 해당 문제는 제가 이제 Data Augmentation을 진행할 때, 클레스를 따로 지정하지 않아서 문제가 발생한 것이었습니다. 그래서 다시 데이터 증강부터 실습을 진행해보겠습니다. 그런데 아직 test에서는 성적이 좋지는 않게 나왔습니다.. 데이터 부족이라고 위안 삼고 있긴 한데.. 뭔가 만족스럽지 않았습니다.
Data Augmentation
train_datagen = ImageDataGenerator(rotation_range=3, horizontal_flip=False, vertical_flip=False, rescale=1/255.0)
valid_datagen = ImageDataGenerator(rescale=1/255.0)
train_generator = train_datagen.flow_from_directory(
directory=train_path,
target_size=(280, 280),
classes=['normal', 'abnormal'],
class_mode='binary',
batch_size=64
)
valid_generator = valid_datagen.flow_from_directory(
directory=val_path,
target_size=(280, 280),
classes=['normal', 'abnormal'],
class_mode='binary',
batch_size=64
)어제와 다르게 .flow_from_directory()를 진행할 때 calasses를 따로 설정해주고 class_mode를 이진분류이기 때문에 binary로 설정했습니다.
모델링 시작
from tensorflow.keras.applications import VGG16
from tensorflow.python.keras.layers import Conv2D, MaxPooling2D, Flatten
from tensorflow.python.keras.layers import Dense, Dropout, Input
from tensorflow.python.keras.models import Model
# VGG16 모델 불러오기
input_tensor = Input(shape=(280,280,3))
basemodel = VGG16(weights='imagenet', include_top=False)
keras.backend.clear_session()
il = keras.layers.Input(shape=(280,280,3))
x = basemodel(il)
x = keras.layers.Flatten()(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Dropout(0.25)(x)
ol = keras.layers.Dense(1, activation = 'sigmoid')(x)
model = keras.models.Model(il, ol)
model.compile(loss=keras.losses.binary_crossentropy, optimizer=keras.optimizers.Adam(learning_rate=0.0001), metrics=['accuracy'])
# 모든 레이어들을 trainable로 설정
for layer in model.layers:
layer.trainable = TrueVGG16모델을 불러와서 사용했는데 VGG16모델이 어떤 구조이고 어떤 식으로 사용하면 좋은지에 대해서는 시간 부족으로는 찾아보지 못했습니다...
모델 학습
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', min_delta=0, patience=7, restore_best_weights=True, verbose=1)
hist = model.fit(train_generator, validation_data=valid_generator, callbacks=[es], epochs=20, verbose=1)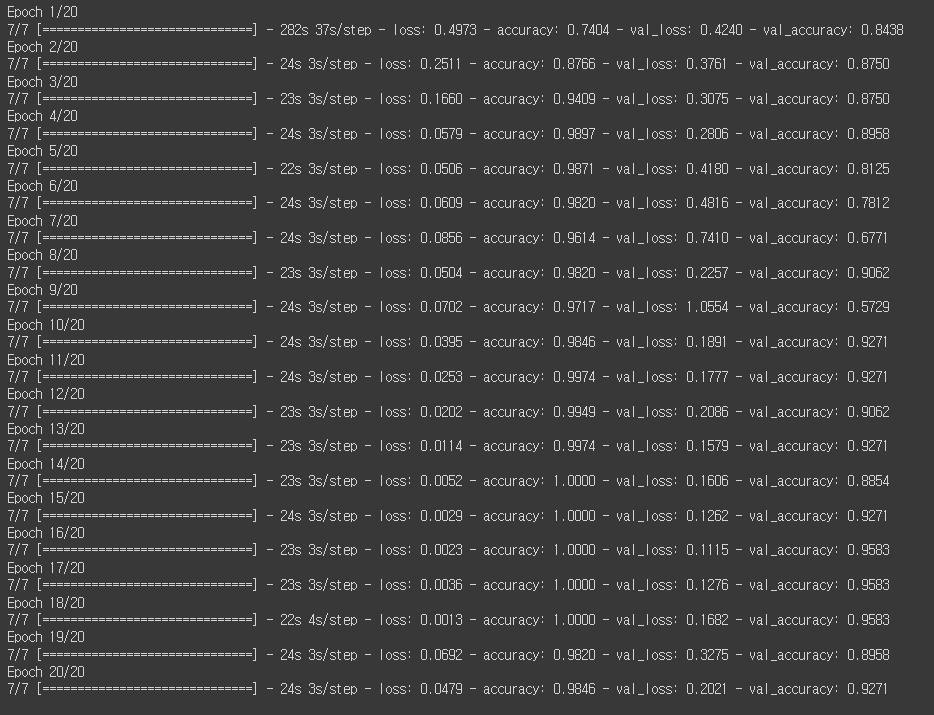
모델학습은 크게 달라진 것은 없습니다만 그래도 어제의 val_accuracy가 0.5로 고정되는 지옥에서 탈출하는 것을 확인할 수 있었습니다.
모델 학습을 2개로 진행할 예정입니다. 위 모델은 이제 Data Augmentation을 진행한 train_generator로 학습을 진행한 거고 다음 하나는 어제 만들어둔 x_train과 x_val로 모델학습을 진행하겠습니다.
from keras.callbacks import EarlyStopping
es = EarlyStopping(patience=10, verbose=1, min_delta=0, restore_best_weights=True, monitor='val_loss')
model.fit(x_train, y_train, callbacks=[es], epochs=5000, verbose=1, validation_data=(x_val, y_val), shuffle=True)모델 평가
모델 평가는 총 2가지의 방식으로 진행했습니다. 이번 모델 평가를 하면서 생긴 의문점과 같이 정리해보도록 하겠습니다.
▶Data Augmentation된 test데이터 셋으로 평가하기
먼저 test데이터셋으로 평가를 진행하겠습니다. 코드는 아래와 같습니다.
# Test set
test_datagen = ImageDataGenerator(rescale=1/255.0)
test_generator = test_datagen.flow_from_directory(
directory=test_path,
target_size=(280, 280),
classes=['normal', 'abnormal'],
class_mode='binary'
)
loss, accuracy = model.evaluate(test_generator)
print(f'정확도 => {accuracy*100:.2f}')해당 코드를 실행하면 아래와 같은 결과를 얻을 수 있습니다.

근데 문제는 아래의 코드를 그려 시각화를 진행하면 값이 이상하다는 것이 느껴집니다.
import matplotlib.pyplot as plt
# 트레인 결과값 그래프
plt.plot(hist.history['accuracy'], label='train')
plt.plot(hist.history['val_accuracy'], label='val')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 트레인 결과값 그래프
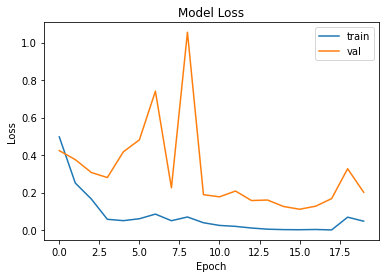
plt.plot(hist.history['loss'], label='train')
plt.plot(hist.history['val_loss'], label='val')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 테스트 결과값 그래프
plt.plot(test_generator.labels, label='true')
plt.plot(y_pred, label='pred')
plt.title('Model Prediction')
plt.xlabel('Sample')
plt.ylabel('Prediction')
plt.legend()
plt.show()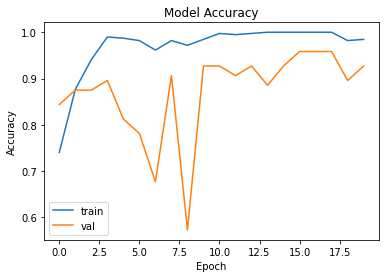
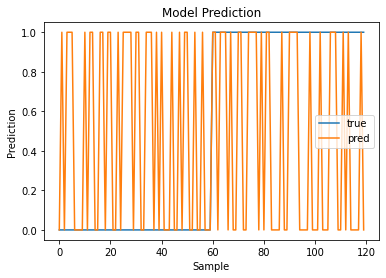
아무리봐도 정확도가 94.17이 나오는게 말이 안되는거 같습니다. 그래서 아래의 코드로 어제 만들어둔 y_test로 테스트를 진행해보면 아래와 같은 결과를 얻을 수 있습니다.
import numpy as np
# Test set
test_datagen = ImageDataGenerator(rescale=1/255.0)
test_generator = test_datagen.flow_from_directory(
directory=test_path,
target_size=(280, 280),
classes=['normal', 'abnormal'],
class_mode='binary'
)
# 모델로 예측 수행(test_Augmentation으로 데이터 평가)
y_pred = model.predict(test_generator)
y_pred = np.round(y_pred).astype(int)
from sklearn.metrics import *
acc_test = accuracy_score(y_test, y_pred)
print(f'테스트 점수는 => {acc_test*100:.2f}')
print()
print(confusion_matrix(y_test, y_pred))
print()
print(classification_report(y_test, y_pred))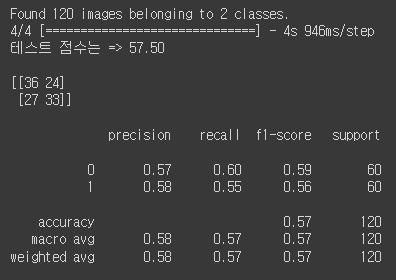
accuracy가 0.57로 val_accuracy보다 너무 낮아서 Data Augmentation 문제인가 싶어서 x_test로 다시 예측값을 만들어 모델을 학습 시켜보았습니다.
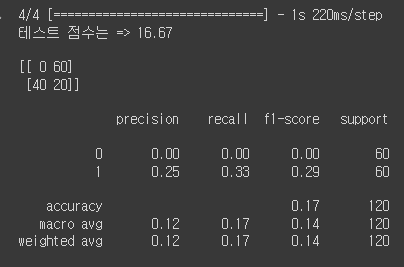
결과는 더 처참하게 나왔습니다. 따라서 다른 방법으로 학습을 해보고 진행해보고자 위에 x_train과 y_train으로 학습하는 모델을 새로 만들어 검증을 진행해보았습니다.
다만 학습이 조금 다른게 다른 에이블러님들의 발표를 보니 shuffle=True로 설정해주면 더 좋은 모델을 만들었다하여 이번에 추가해서 진행해보도록 하겠습니다.
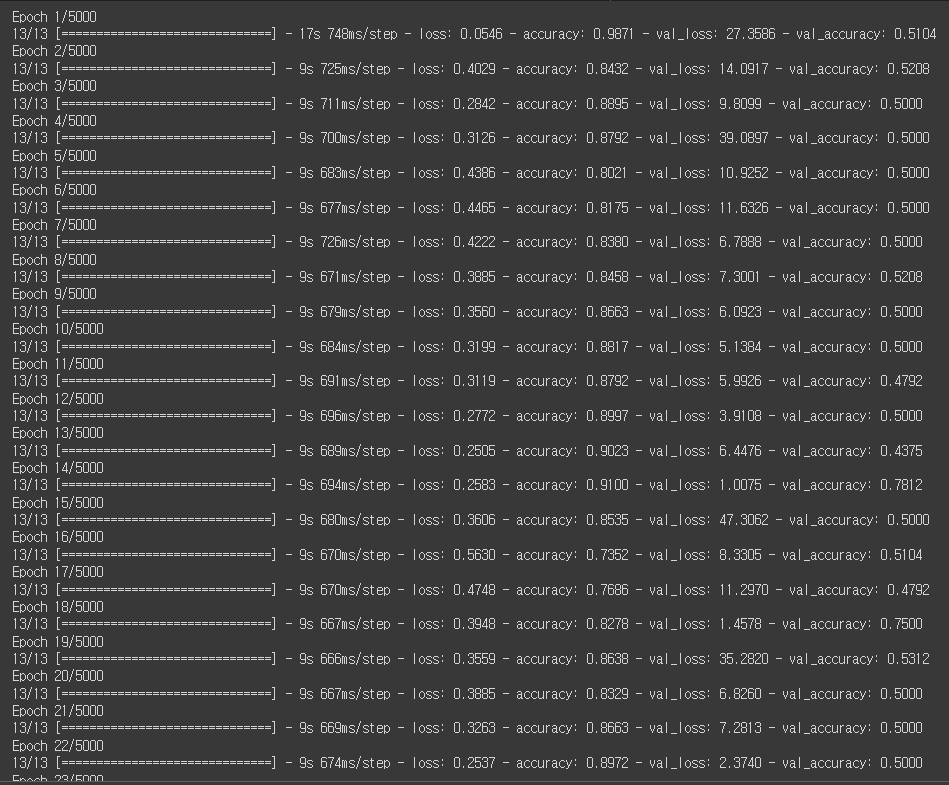
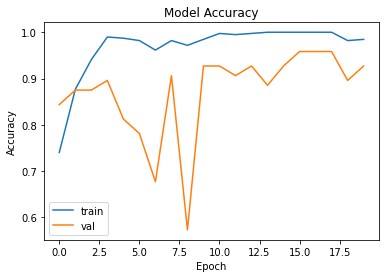
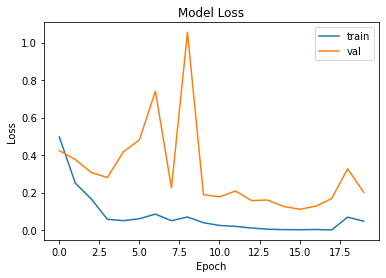
아까보다는 0.5로 수렴되는 것처럼 보이지만 그래도 어느정도 눈에 띄는 성능이 보입니다.
이제 학습을 다시 했으니 평가를 진행하겠습니다.
y_pred = model.predict(x_test)
y_pred = np.round(y_pred).astype(int)
acc_test = accuracy_score(y_test, y_pred)
print(f'테스트 점수는 => {acc_test*100:.2f}')
아까의 정확도 보다는 낮은 정확도를 확인할 수 있습니다.
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
해당 결과를 얻었는데 제일 중요한 거는 이제 평가중에 50%을 못 넘던 평가들을 다시한번 사용해보겠습니다. 코드는 같으니 생략하고 결과만 올리겠습니다.
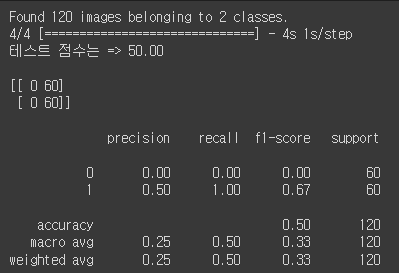


근데 여기서 좀 이상한 것은 평가 코드중에 y_pred = np.where(y_pred >= 0.5, 0, 1)해당 코드를 y_pred = np.round(y_pred).astype(int)로 바꾸어서 아래와 같은 코드로 완성을 하면
import numpy as np
# 모델로 예측 수행(x_test로 데이터 평가)
y_pred = model.predict(x_test)
#y_pred = np.where(y_pred >= 0.5, 0, 1)
y_pred = np.round(y_pred).astype(int)
from sklearn.metrics import *
acc_test = accuracy_score(y_test, y_pred)
print(f'테스트 점수는 => {acc_test*100:.2f}')
print()
print(confusion_matrix(y_test, y_pred))
print()
print(classification_report(y_test, y_pred))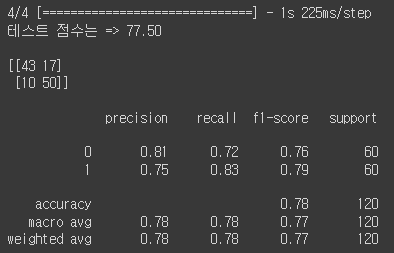
평가 결과는 높게 나오는데 막상 시각화를 진행해서 보면
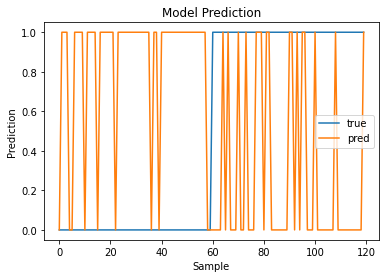
맞춘게 없어 보입니다... 일단 뭐가 문제인지 한번 튜터님들께 여쭤보고 하나씩 찾아서 수정해보겠습니다.
수정사항
일단 x_test와 y_test로 모델을 평가했을 때 시각코드는 아래와 같이 작성해주면
plt.plot(y_test, label='true')
plt.plot(y_pred, label='pred')
plt.title('Model Prediction')
plt.xlabel('Sample')
plt.ylabel('Prediction')
plt.legend()
plt.show()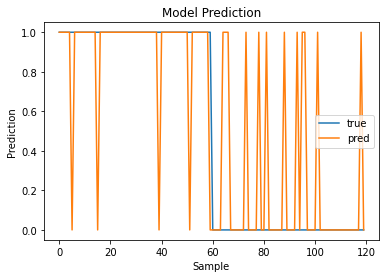
위와 같은 결과를 얻을 수 있었습니다.
평가 코드도 아래와 같이 수정해보니
import numpy as np
# 모델로 예측 수행(x_test로 데이터 평가)
y_pred = model.predict(x_test)
y_pred = np.where(y_pred >= 0.5, 1, 0)
#y_pred = np.round(y_pred).astype(int)
from sklearn.metrics import *
acc_test = accuracy_score(y_test, y_pred)
print(f'테스트 점수는 => {acc_test*100:.2f}')
print()
print(confusion_matrix(y_test, y_pred))
print()
print(classification_report(y_test, y_pred))위 코드에서 y_pred = np.where(y_pred >= 0.5, 1, 0)을 반대로 (y_pred >= 0.5, 0, 1)로 설정해서 반대로 평가해서 그랬던게 아닌가 싶다라는 의심이 들었습니다.
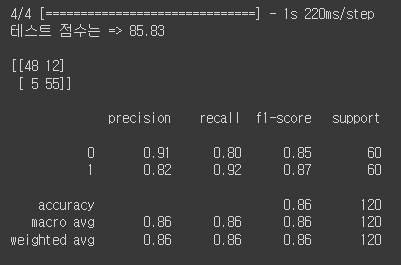
고쳐보니 평가 지표의 값과 시각화를 통해 얻은 것이 얼추 비슷한 것 같다라는 생각이 들었습니다.
그렇지만 아직까지는 Data Augmentation을 진행하면 너무 0.5로 한 값으로만 예측하는 문제점이 계속 발견됩니다..
0.5 저주를 탈출하니 평가 저주가 저를 괴롭히네요...
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
