오늘은 코드 구조 분석과 Bidirectional에 대해 배웠습니다.
LSTM 과 GRU 실습
먼저 LSTM 실습코드 부터 보겠습니다.
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape=(20,6)))
model.add(keras.layers.LSTM(16, return_sequences=True))
model.add(keras.layers.GRU(32, return_sequences=True))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='swish'))
model.add(keras.layers.Dense(1))
model.compile(loss='mse', optimizer='adam')
model.summary()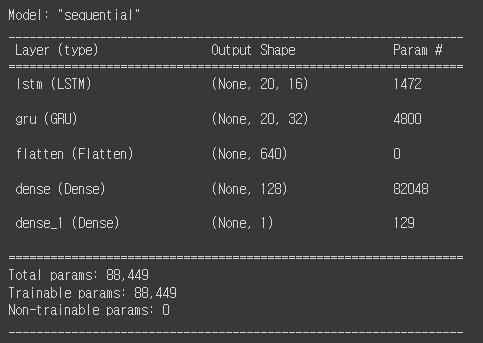
코드를 실행하면 아래와 같은 모델 구조를 확인할 수 있습니다. 파라미터수를 보게 되면 RNN과 차이가 있는데 어제 설명 드린거와 같이 LSTM은 RNN보다 4배 더 무겁기 때문에 계산을 해보면 첫번째 LSTM은 (6+16+1)*16*4를 해주어 계산해야됩니다. 그럼 다음으로 GRU는 RNN보다 3배 무겁기 때문에 계산을 (16+32+1)*32*3
전체적인 사용방법은 RNN과 같습니다. 히든스테이트를 옵션으로 주고 return_sequences와 같은 여러 옵션을 적절하게 사용해주면 됩니다.
추가 해설
카운팅을 진행했을 때, 맨 왼쪽에 있는 시점은 이전 시점이 없는데 어떻게 카운팅에 포함되고 가중치 계산이 되는지 궁금했습니다. 첫 시점에 대해서는 이전 시점에 대한 가중치가 없지만 이전 시점으로 가중치 계산이 되어야된다는 딜레마에 빠지게 됩니다. Pytoch나 keras는 과거가 없다는 식으로 0을 채워 이전 시점을 만들어 계산을 하지만 다른 의견으로 학습 가능한 가중치를 넣거나 의미 있는 값을 찾아서 넣자라는 의견이 있습니다.
Bidirectional Layer
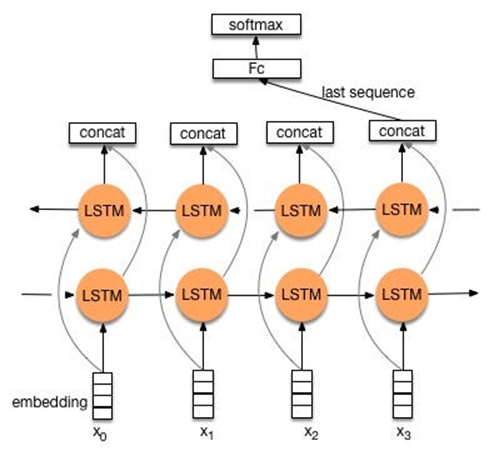
사진출처 : https://ws-choi.github.io/blog-kor/bidirectional-rnn-in-pytorch/
위 사진을 보게되면 맨 아래의 LSTM은 정방향이고 그 위의 LSTM은 역방향입니다. 정방향은 첫번째 기억을 가지고 있고 역방향은 첫기억과 함께 이전 기억(과거 기억)도 반영되어 있습니다. 여기서 역방향의 과거 기억이라 하면 미래 기억을 의미합니다.
Bidirectional의 구조를 보면 concat을 통해 정방향의 노드와 역방향의 노드를 모두 합쳐서 사용합니다. 이러면 최신정보를 과거의 맥락을 고려하여 반영하게 됩니다. 여기서 x는 최신정보를 의미. 앞의 히든스테이트는 과거의 맥락을 의미합니다. 역방향인 LSTM이 첫시점의 정보와 과거의 맥락을 고려해서 방영한거 입니다.
Bidirectional Layer를 사용하면 모든 시점의 정보를 잘 볼 수 있다는 장점이 생기게 됩니다.
Conv1D & MaxPool1D
Conv1D는 2D와 다르게 방향이 한방향이므로 kernel_size에 예를들어 3이라는 값을 주게되면 하번에 3개를 훑어서 새로운 특징을 추출합니다.
1D에서도 마찬가지로 데이터 손실을 방지하기 위해서 MaxPool을 사용합니다. 만약 MaxPool1D(2)라는 값을 주게 되면 하번에 관찰할 시점수를 2로 설정하고 stride도 2로 설정이 됩니다.
LSTM은 모든 시점을 전부 고려한다면 Conv1D는 시점을 동시에 동등하게 고려한다는 점이 차이가 있습니다.
시점을 축소하게 되면 금붕어도 기억할 수 있을 정도로 시점이 줄어서 감당가능하게 데이터를 축소합니다.
Bidirectional Layer 실습
clear_session()
il = Input(shape=(50,6))
x = Conv1D(filters=32, kernel_size=10, activation='swish', padding='same')(il)
x = MaxPool1D(2)(x)
forwardLSTM = LSTM(24, return_sequences=True)
backwardGRU = GRU(16, return_sequences=True, go_backwards=True)
br = Bidirectional(layer=forwardLSTM, backward_layer=(backwardGRU))(x)
forwardLSTM2 = LSTM(24, return_sequences=True)
backwardGRU2 = GRU(24, return_sequences=True, go_backwards=True)
br = Bidirectional(layer=forwardLSTM2, backward_layer=backwardGRU2)(br)
fl = Flatten()(br)
x = Dense(256, activation='swish')(fl)
ol = Dense(1)(x)
model = Model(il, ol)
model.compile(loss='mse', optimizer='adam')
model.summary()
위 코드를 해석해보겠습니다.
Conv1D와 MaxPool1D를 통해 차원을 축소해줍니다. 실질적으로 MaxPool1D로 인해 차원축소가 이루어집니다. 이렇게 Conv1D와 MaxPool1D로 먼저 차원을 축소해줍니다.
그리고 정방향과 역방향을 사용하는 Bidirectional 구조를 만들기 위해 layer=와 역방향의 backward_layer=옵션을 사용합니다. shape의 히든스테이트를 보면 정방향의 히든스테이트 수와 역방향의 히든스테이트 수를 더한 shape가 완성되는 것을 확인할 수 있습니다.
추가 알아둘 것
relu를 사용하면 0~1의 값이 나오기 때문에 만약 0보다 작은 값이 필요한 경우에는 relu를 outputlayer에서 사용하지 않습니다.
금붕어 모델(RNN, LSTM, GRU)를 해결하기 위한 여러 방안을 배운 하루입니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
