오늘은 문자 분류와 임베딩에 대해서 배웠는데 하루가 정신없이 흘러간 것 같습니다.
Text Classification & Embedding
과거 테크닉으로 Bag of Word가 있습니다. raw 데이터를 가지고 모든 단어마다 인덱스를 할당하고 인덱스만큼의 공간을 확보하고 단어가 나온 횟수만큼 숫자를 주어주는 기술입니다. 문자를 숫자로 바꾸어 낸다는 것은 중요합니다. 다만 그렇게 되면 등장횟수로 중요도를 가지게 되는데 이게 맞는지에 대해 의문이 들게 됩니다. 따라서 Tf idf를 통해서 한 문장에서만 나오는 것은 가중치를 높게 주고 나머지는 문장에서도 반복해서 나오면 가중치를 낮게 주는 방법을 이용했습니다. 가중치뿐 아니라 문맥 순서도 중요한데 순서가 반영이 되지 않는 테크닉이라 문제가 많았습니다.
따라서 지금까지 배운 기술을 혼용해서 위에 발견된 문제를 해결하고자 발전하고 있습니다.
먼저 Bag of Word로 인덱싱을 합니다. Tokenizing은 내가 분석을 하기 위해서 의미있다고 생각하는 최소한의 단위로 만드는 것을 의미합니다. 다음으로 Test Sequence를 Index Sequence로 바꿔줍니다.변환했다면 문장 길이를 통일해줍니다. 만약 문장이 짧다면 Padding을 통해 모자른 부분을 0으로 채워주고 길다면 Trimming으로 문장을 잘라 줍니다. 하지만 여기서 생각할 것이 앞에 부분을 추가 혹은 자를지 아니면 뒤에 부분을 추가 혹은 자를지를 고민해봐야 합니다.
계산이 가능한 숫자로 바꾸는 것은 중요합니다. 인덱스가 아닌 의미 있는 숫자가 되어야하지 않을까 라는 생각을 가지고 단어 하나하나가 특징(Feature) 값들로 representation되게 해왔습니다. 이런 가중치는 사람이 직접 만드는 것이 아니라 딥러닝을 통해 가중치 학습을 통해서 만듭니다.
성능이 도움이 된다는 것은 분류에 있어서 의미가 있다는 것입니다. 목적, 예를들면 문장을 긍정/부정으로 분류하는 목적하에 의미가 있다는 것이고 의미분석은 가능성이 열렸다고 말할 수 있습니다. 왜 가능성만 열려있냐고 의문이 들텐데 이유는 어학적인 측면에서 분류가 되는 것이 아니라 긍정/부정으로만 분류가 가능하기 때문에 아직 부족한 점이 많다는 것입니다.
뼈대를 만들기 위해서 생각할 점이 여럿 있습니다. 첫 번째로 어떻게 tokenization을 할 것인지에 대해 생각해 보아야 합니다. 두 번째로 어학적으로 분리할 것인지 아니면 필요한 것만 남길지에 대해서 생각해 보아야 합니다. 세 번째로 이제 Padding/Trimming을 앞 혹은 뒤에 적용할지 말지에 대해서 생각해 봐야 합니다. 네 번째로 학습 가능하도록 parameterize를 해주고 고쳐야 합니다.
Text Classification 실습코드
먼저 데이터는 스팀에 리뷰 데이터를 사용했습니다.
▶Tokenizing & Text to Sequence
먼저 토큰화와 텍스트 시퀀스화를 진행하겠습니다.
x_train = train_data['reviews'].astype('str').tolist()
x_test = test_data['reviews'].astype('str').tolist()먼저 데이터를 문자열로 변환하고 리스트형태로 변환해주는 과정을 거칩니다.
※한국어 같은 경우 한국어 전처리가 있는데 나중에 한번 찾아볼 예정입니다.
y_train = train_data['label'].values
y_test = test_data['label'].values다음으로 y데이터를 만들어 줍니다.
이제부터 본격적인 Tokenizing을 시작합니다.
from tensorflow.keras.preprocessing.text import Tokenizer
max_word = 40000
tokenizer = Tokenizer(num_words = max_word, lower=False)상위 40000개의 단어만 사용하기 위해서 num_words=옵션에 40000을 넣어줬습니다. lower=옵션은 텍스트 데이터를 소문자로 변환하지 않는 옵션을 사용해준 것입니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
x_train = pad_sequences(x_train, maxlen=40)
x_test = pad_sequences(x_test, maxlen=40)
x_train = np.array(x_train)
x_test = np.array(x_test)토큰화가 끝났으므로 pad_sequences() 함수를 사용하여 x_train과 x_test의 sequence 데이터를 40의 고정 길이로 패딩하여 줍니다. 패딩된 sequence는 0으로 채워지며, maxlen 인자로 설정한 길이보다 긴 sequence는 잘리게 됩니다. 다음으로 넘파이 배열로 변환하여 저장해주는 과정을 거칩니다.
▶0으로 가득찬 데이터 대한 전처리
not0train_idx = x_train.sum(1) > 0
not0test_idx = x_test.sum(1) > 0
train_data = train_data.loc[not0train_idx].reset_index(drop=True)
test_data = test_data.loc[not0test_idx].reset_index(drop=True)
x_train = x_train[not0train_idx]
y_train = y_train[not0train_idx]
x_test = x_test[not0test_idx]
y_test = y_test[not0test_idx]▶모델링 시작
필요패키지를 불러옵니다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Flatten, Conv1D, MaxPool2D, Input
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, SimpleRNN, GRU
from tensorflow.keras.models import Model이제 본격적인 모델링을 시작합니다.
clear_session()
il = Input(shape=(40,))
x = Embedding(max_word, 128, input_length=40)(il)
x = Conv1D(filters=32, kernel_size=5, activation='swish')(x)
forward_LSTM = LSTM(32, return_sequences=True)
backward_LSTM = LSTM(32, return_sequences=True, go_backwards=True)
x = Bidirectional(layer=forward_LSTM, backward_layer=backward_LSTM)(x)
forward_GRU = GRU(32, return_sequences=True)
backward_RNN = SimpleRNN(16, return_sequences=True, go_backwards=True)
x = Bidirectional(layer=forward_GRU, backward_layer=backward_RNN)(x)
x = Conv1D(filters=32, kernel_size=5, activation='swish')(x)
x = MaxPooling1D(2)(x)
x = Flatten()(x)
x = Dense(1024, activation = 'swish')(x)
ol = Dense(1, activation='sigmoid')(x)
model = Model(il, ol)
model.compile(loss=keras.losses.binary_crossentropy, metrics=['accuracy'], optimizer='adam')위 모델의 구조를 보기위해 아래와 같이 summary를 사용해줍니다.
model.summary()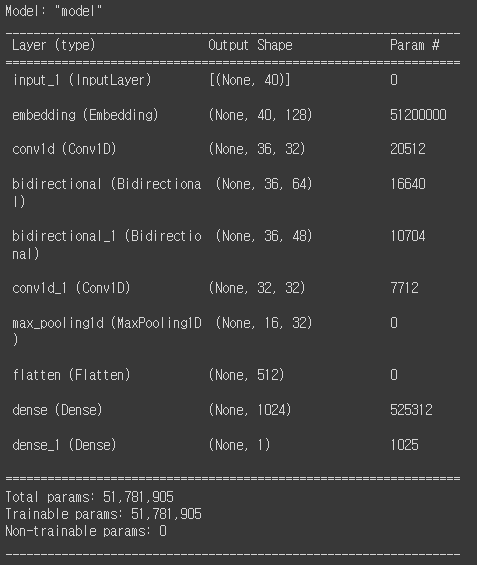
▶모델 학습시작(w. EarlyStopping)
모델 학습을 시작합니다.
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', verbose = 1, min_delta=0, patience=5, restore_best_weights=True)
model.fit(x_train, y_train, validation_split=0.2, verbose=1, epochs=1000, callbacks=[es])▶결과 확인
모델 학습이 끝나면 결과 확인을 위해 아래와 같이 작성해서 확인해줍니다.
review_idx = 77
temp = test_data.loc[review_idx]
docu = temp['reviews']
label = 'positive' if temp['label'] ==1 else 'Negative'
print(f"문서 번호 {review_idx}")
print(label, " : ", docu)
y_pred = model.predict(x_test[review_idx:review_idx+1])
label_pred = 'positive' if y_pred[0,0] >=0.5 else 'Negative'
print(f"모델의 예측 : {label_pred}, prob = {y_pred[0,0]*100:.2f}%")용어정리
Embedding은 단어, 토큰, 문서를 vector로 바꾸는 것을 의미합니다.
오늘은 엄청 폭풍이 지나간 것 같습니다. 이론도 많았고 실습도 많았던 하루였던 같습니다. 수업 자체는 너무 재밌는데 아직 부족한 부분이 눈에 많이 보이기 때문에 복습이 많이 필요해 보였습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
