오늘은 자연어처리의 여러가지 예제에 대해서 배웠습니다.
가사 예측하기
오늘 여러가지 자연어처리 예제에 대해 학습했습니다.
먼저 어제에 이은 예제라 한번에 오늘 포스팅에 작성하겠습니다. 가사를 가지고 다음 나올 가사를 예측하는 자연어 처리 예제입니다.
▶전처리 시작
먼저 gasa라는 데이터 변수에 가사를 작성했다고 가정하에 예제 진행하겠습니다.
from konlpy.tag import Okt
okt = Okt()
for idx, sentence in enumerate(gasa):
gasa[idx] = ' '.join(okt.morphs(sentence))해당 코드를 통해 gasa데이터 안에 있는 모든 문장에 형태소 사이 사이에 띄어쓰기를 적용해주는 코드입니다. 형태소 구별을 위해 okt.morphs를 사용해주었습니다.
이제 형태소를 기준으로 띄어쓰기가 완료되었다면 띄어쓰기를 기준으로 tokenize를 진행하고 index를 sequence로 바꾸어줍니다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(gasa)
gasa_seq = tokenizer.texts_to_sequences(gasa)
vocab_size = len(tokenizer.word_index)+1
원-핫 인코딩이 0부터 시작하게 때문에 인덱스 하나가 더 필요하므로 vocab_size = len(tokenizer.word_index)+1코드를 통해 하나 더 늘려줍니다.
다음으로 예측을 위해서 아래와 같이 작업을 해줍니다.
temp = []
for seq in gasa_seq:
for i in range(1, len(seq)):
temp.append(seq[:i+1])
gasa_seq = temp해당 코드를 사용하면 피라미드식으로 seq가 만들어 집니다.
이제 문장의 길이를 맞춰주기 위해 아래와 같이 코드를 작성합니다.
max_len = max([len(seq) for seq in gasa_seq])
gasa_seq = pad_sequences(gasa_seq, maxlen=max_len, padding='pre')여기서 padding='pre'를 사용해서 앞부분에 부족한 부분을 0으로 채워줍니다.
이제 y에 대해서 원-핫 인코딩을 진행합니다.
from tensorflow.keras.utils import to_categorical
y = to_categorical(y, num_classes= vocab_size)▶모델링 시작
이제 모든 전처리가 끝났으므로 모델링을 시작합니다.
keras.backend.clear_session()
model = keras.models.Sequential()
model.add( keras.layers.Embedding(input_dim = vocab_size,
output_dim = 32,
input_length = max_len-1 ))
model.add( GRU(32, return_sequences=True) )
model.add( GRU(48, return_sequences=True) )
model.add( GRU(64, return_sequences=False) )
model.add( Dense( vocab_size, activation='softmax' ))
model.compile( loss = 'categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()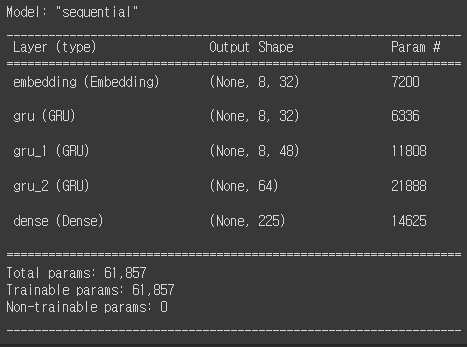
위 코드를 보게 되면 Embeding을 하는 코드가 있습니다. 해당 코드로 인해서 주어진 문장을 백터화해줄 수 있습니다. 모니터링 지표로는 accuracy를 사용해주었습니다.
▶모델 학습
model.fit(x, y, epochs=1000, verbose=1, batch_size=64)모델을 학습 시켜줍니다.
▶모델 예측 예제
이제 모델 학습까지 끝났으면 해당 모델을 가지고 여러가지 예제를 진행합니다.
첫번째 예제로 '나'라는 가사 뒤에 어떤 가사 나올지에 대한 예측 확률이 제일 높은 단어 3개를 출하는 코드를 보겠습니다.
first_word = ['나']
seq = tokenizer.texts_to_sequences(first_word)
seq = pad_sequences(seq, maxlen=max_len-1, padding='pre')
y_pred = model.predict(seq)
top3_idx = np.argsort(y_pred[0])[::-1][:3]
top3_probs = np.array(y_pred[0])[top3_idx]
print(f"다음에 올 단어 후보:")
for i, idx in enumerate(top3_idx):
word = tokenizer.index_word[idx]
prob = top3_probs[i]
print(f"{word} : {prob*100:.2f}%")
다음으로 문장을 구성해서 다음으로 올 단어를 예측하는 코드는 아래와 같습니다.
# 첫 단어로 '나 추억'을 사용
first_word = ['나 추억']
# 입력 문장 전처리
seq = tokenizer.texts_to_sequences(first_word)
seq = pad_sequences(seq, maxlen=max_len-1, padding='pre')
# 모델 예측
y_pred = model.predict(seq)
# 두 번째로 확률이 높은 단어
second_word_idx = np.argsort(y_pred[0])[-2]
# 두 번째 단어 추가
words = first_word + [tokenizer.index_word[second_word_idx]]
# 입력 문장 전처리
seq = tokenizer.texts_to_sequences(words)
seq = pad_sequences(seq, maxlen=max_len-1, padding='pre')
# 모델 예측
y_pred = model.predict(seq)
# 다음에 올 단어로 가장 확률이 높은 3 단어
top3_idx = np.argsort(y_pred[0])[-3:]
# 가장 확률이 높은 단어와 확률 출력
for idx in top3_idx:
word = tokenizer.index_word[idx]
prob = y_pred[0][idx]
print(f"{word} : {prob*100:.2f}%")다음으로 첫 단어를 주어주고 원하는 단어 갯수를 입력하면 출력해주는 코드는 아래와 같습니다.
def generate_sentence(start_word, num_predictions):
# 입력 단어를 시퀀스로 변환 및 패딩
seq = tokenizer.texts_to_sequences([start_word])
seq = pad_sequences(seq, maxlen=max_len-1, padding='pre')
sentence = start_word # 최종 문장을 저장할 변수
for i in range(num_predictions):
# 현재 시퀀스에 대한 다음 단어 예측
y_pred = model.predict(seq)
next_word_idx = np.argmax(y_pred, axis=-1)
# 다음 단어를 문장에 추가하고, 시퀀스를 업데이트
next_word = tokenizer.index_word[next_word_idx[0]]
sentence += " " + next_word
seq = np.roll(seq, -1, axis=-1)
seq[0][-1] = next_word_idx[0]
return sentence
generate_sentence("나", 4)
seq2seq
sequence를 입력받아서 sequence를 출력하는 방법입니다. 문장의 길이가 길면 첫 단어에 대한 기억이 소실된다는 점이 있는데 seq2seq는 인코더를 통해 문장에 대해서 의미가 있는(representation) 맥락으로 만듭니다. 다음으로 인코더된 맥락을 디코딩을 진행하는데 이때 디코더는 인코더를 받는 히든스테이트가 하나 필요합니다.
sos는 start of speech의 약자이고 eos는 end of speech의 약자입니다. sos와 eos를 사용해주는 이유 첫 번째는 LSTM의 히든 스테이트를 가지고 멀티클레스 분류기에 의해서 얻은 단어를 넣습니다. 분류기는 같은 가중치를 가진 분류기 입니다. 이때 sos와 eos가 있는 이유는 모델에게 번역의 시작과 끝을 알려주는 명령으로 사용하기 위해서 넣어줍니다. 즉, sos는 지시용 token으로 문장 앞에 <sos>를 붙여주는 전처리가 필요하고 eos도 마찬가지로 모델이 사람한테 번역이 끝났다고 알려주는 token으로 <eos>도 마찬가지로 문장 뒤에 추가해주는 전처리가 필요합니다.
teaching forcing은 교사 강요로 번역의 일부분을 주고 그 다음 단어를 해석하게 하는 기술입니다.
seq2seq 실습
한국어를 영어로 번역해주는 모델을 만들어 보겠습니다.
▶전처리 시작
먼저 전처리로 단어와 구두점 사이에 공백을 만들어줍니다.
import unicodedata
import re
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def eng_preprocessor(sent):
# 위에서 구현한 함수를 내부적으로 호출
sent = unicode_to_ascii(sent.lower())
# 단어와 구두점 사이에 공백을 만듭니다.
# Ex) "he is a boy." => "he is a boy ."
sent = re.sub(r"([?.!,'¿])", r" \1 ", sent)
# (a-z, A-Z, ".", "?", "!", ",") 이들을 제외하고는 전부 공백으로 변환합니다.
sent = re.sub(r"[^a-zA-Z!.?']+", r" ", sent)
sent = re.sub(r"\s+", " ", sent)
return sent
def kor_preprocessor(sent):
# 위에서 구현한 함수를 내부적으로 호출
sent = unicode_to_ascii(sent.lower())
# 단어와 구두점 사이에 공백을 만듭니다.
# Ex) "he is a boy." => "he is a boy ."
sent = re.sub(r"([?.!,'¿])", r" \1 ", sent)
sent = re.sub(r"\s+", " ", sent)
return sent전처리 함수를 만들어주면 아래와 같이 함수를 이용해 전처리를 진행해줍니다.
eng_sent = [ eng_preprocessor(sent) for sent in eng_sent ]
kor_sent = [ kor_preprocessor(sent) for sent in kor_sent ]▶sos와 eos 넣어주기
이제 번역하고자 하는 언어의 문장에 <sos>와 <eos>를 넣어줍니다.
eng_sent = [f'<sos> {eng} <eos>'for eng in eng_sent]▶Tokenizing, seq, padding 진행
seq2seq에 앞서 문장에 대한 전처리를 진행해줍니다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
eng_seq = tokenizer_en.texts_to_sequences(eng_sent)
kor_seq = tokenizer_kr.texts_to_sequences(kor_sent)
print(eng_seq[1000])
print(kor_seq[1000])
eng_pad = pad_sequences(eng_seq)
kor_pad = pad_sequences(kor_seq)
print(eng_pad.shape)
print(kor_pad.shape)
eng_vocab_size = len(tokenizer_en.word_index) + 1
kor_vocab_size = len(tokenizer_kr.word_index) + 1해당 코드를 보게 되면 pad_sequence에서 pad의 의미로 0을 사용하고 있어서, 전체 사이즈를 구할 때, +1을 해서 처리해주어야 합니다.
▶모델링 시작
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, GRU
# 혹시 이미 그려둔 그래프가 있다면 날려줘!
tf.keras.backend.clear_session()
# 한국어 단어 집합의 크기 : 5551, (50000, 95)
# 영어 단어 집합의 크기 : 2484, (50000, 104)
# Encoder
enc_X = tf.keras.layers.Input(shape=[kor_pad.shape[1]])
enc_E = tf.keras.layers.Embedding(kor_vocab_size, 64)(enc_X) # 토큰수, 차원수
enc_S_full, enc_S = tf.keras.layers.GRU(256, return_sequences=True, return_state=True)(enc_E)
# Decoder
dec_X = tf.keras.layers.Input(shape=[eng_pad.shape[1]-1])
dec_E = tf.keras.layers.Embedding(eng_vocab_size, 64)(dec_X) # 토큰수, 차원수
dec_H = tf.keras.layers.GRU(256, return_sequences=True)(dec_E, initial_state=enc_S)
dec_H = tf.keras.layers.Dense(256, activation="swish")(dec_H) # 없어도 상관은 없는 부분.
dec_Y = tf.keras.layers.Dense(eng_vocab_size, activation="softmax")(dec_H) # 매시점에서, 어떤 단어가 타당할지 분류 문제로 푸는 것
# Model
model = tf.keras.models.Model([enc_X, dec_X], dec_Y)
# 텍스트는 index이고(원핫인코딩을 안했고)
# 아웃풋레이어는 분류문제 처럼 노드가 준비되어 있다면
# sparse categorical crossentropy
model.compile(loss='sparse_categorical_crossentropy',
optimizer = 'rmsprop',
metrics=['accuracy'])
model.summary()▶모델 학습
model.fit([kor_pad, eng_pad[:, :-1]], eng_pad[:, 1:], shuffle=True,
batch_size=128, epochs=10)▶번역 결과 확인
import numpy as np
# 한국어 단어 집합의 크기 : 5551, (50000, 95)
# 영어 단어 집합의 크기 : 2484, (50000, 104)
def translate(kor):
# eng => index => pad
kor_seq = tokenizer_kr.texts_to_sequences([kor])
kor_pad = tf.keras.preprocessing.sequence.pad_sequences(kor_seq, maxlen=95)
eng = []
for n in range(104-1):
# kor => index => pad
eng_seq = tokenizer_en.texts_to_sequences([['<sos>'] + eng])
eng_pad = tf.keras.preprocessing.sequence.pad_sequences(eng_seq, maxlen=104-1)
eng_next = model.predict([kor_pad, eng_pad])
# onehot -> index -> word
eng = [tokenizer_en.index_word[i] for i in np.argmax(eng_next[0], axis=1) if i != 0]
# 번역된 word 선택
eng = eng[:n+1]
if eng[-1] == '<eos>':
break
return eng
함수를 만들어주고 아래와 같이 결과를 확인할 수 있습니다.
import random
# 랜덤 10개
indices = list(range(3648))
random.shuffle(indices)
for n in indices[:10]:
print(f"한국어: {kor_sent[n]}\n영어: {eng_sent[n]}")
print(f"번역: {' '.join(translate(kor_sent[n])[:-1])}")
print()▶모델링의 전체적인 흐름
모델링의 전체적인 흐름을 한번 더 정리해보겠습니다.
디코더는 인코더로부터 온 맥락을 히든스테이트로 받습니다. 후에 LSTM을 걸쳐 멀티 클레스 분류기를 걸치게 됩니다.
번역의 첫 단어에 번역의 첫 단어를 줄 수 없으므로 번역을 시작하라는 명령을 주기 위해 <sos>를 넣어줍니다. 그리고 번역이 다 끝났음을 알려주기 위해 <eos>를 넣어줍니다. 따라서 모델링 시작 전에 <sos>와 <eos>를 넣어주는 전처리를 해줍니다.
다음으로 문장 길이를 통일해 줍니다. 문장의 길이를 통일해주는 이유는 코딩이 편해지기 때문에 뮨정의 길이를 통일해줍니다. 인코더 쪽에서는 앞을 채우고 디코더에서는 뒤를 짜르는 현상이 발생합니다. 이유는 서로 맥락을 넘기고 번역을 시작하면서 헛정보를 없애기 위함입니다.
모델링부분을 보게되면 encorder부분을 만들어주었습니다. 그다음 decorder를 만들어서 연결해주었습니다. 모델을 보게되면 model = tf.keras.models.Model([enc_X, dec_X], dec_Y) 인코더x와 디코더x가 있습니다. dec_Y는 번역의 결과물입니다.
코드 리뷰도 해야되고 이론 공부도 다시해야되고...전처리가 난 밉다..
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
