오늘은 MLflow에 대해 배웠습니다. MLflow는 사기입니다.
추가로 알아둬야할 것
사이킷런에서 MinMax 스케일링을 사용할려면 reshape 전에 스케일링을 하고 reshape를 해야합니다.
Mlflow
머신러닝을 진행하면 모델의 관리와 모델 배포에 대한 고민이 있습니다.
추적이란 중요한 정보를 기록하고 관리하는 것을 의미합니다. 따라서 추적에 대한 설정돠 추적에 대한 코드를 달아놔야합니다.
#mlflow 설정
mlflow_uri = "sqlite:///mlflow.db"
mlflow.set_tracking_uri(mlflow_uri)로컬 환경에서는 mlflow_uri = "sqlite:///mlflow.db" 로 url을 잡아줍니다.
▶ 모델링&Tracking
with mlflow.start_run(): # 추적 시작 지정
model = DecisionTreeClassifier()
model.fit(x_train, y_train)
pred = model.predict(x_val)
accuracy = accuracy_score(y_val, pred)
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(model, "model", registered_model_name="Test_Model")mlflow.log_metric는 성능을 기록하는 코드이고 mlflow.sklearn.log_model는 모델을 기록해주는 코드입니다. with문을 사용하면 들여쓰기가 끝나는 부분에서 mlflow.end_run()을 실행해줍니다. 블록 기반으로 코드를 관리한다고 생각하면 됩니다.
mlflow server --backend-store-uri sqlite:///mlflow.db --default-artifact-root ./artifacts코드를 터미널에서 실행해주면 추적을 보여주는 사이트(mlflows)가 보여줍니다.
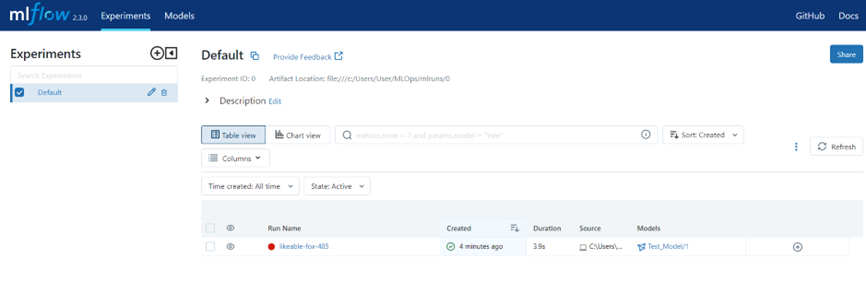
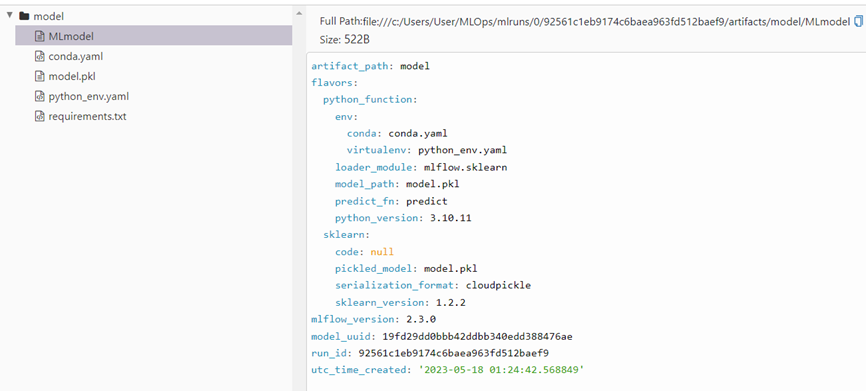
필요한 정보를 모두 저장합니다.
Mlflow 관리 단위
실험은 실행의 상위 단위로써 하나의 실험에는 여러 실행이 포함되어 있습니다. 모델은 모델이름을 관리해서 버전으로 구분할 수 있습니다.
실험관리
exp_id = mlflow.create_experiment("exp1")
exp_id해당 코드로 실험을 만들어서 관리할 수 있습니다.
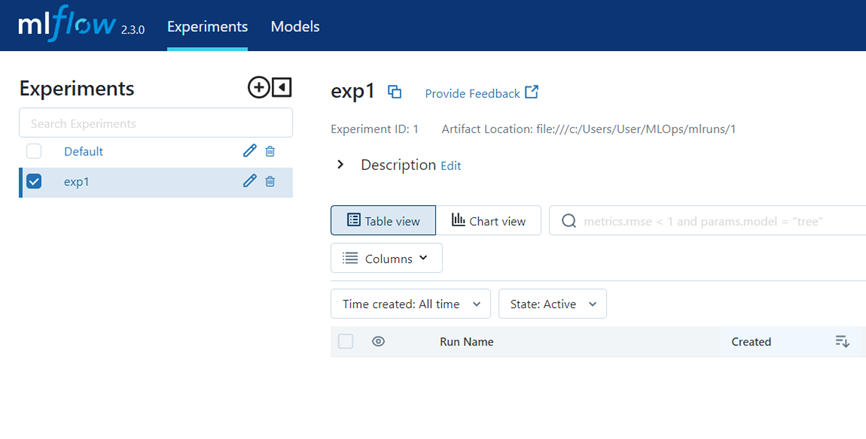
페이지를 새로고치하면 exp1이라는 실험이 생긴것을 확인할 수 있습니다.
from sklearn.ensemble import RandomForestRegressor
with mlflow.start_run(experiment_id = exp_id):
model = RandomForestRegressor()
model.fit(x_train, y_train)
pred = model.predict(x_val)
rmse = mean_squared_error(y_val, pred, squared=False)
mae = mean_absolute_error(y_val, pred)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(model, "model1", registered_model_name="CarSeat")이런식으로 해당 실험 아래에 코드를 '실행'할 수 있습니다. 추적하는 코드로는 mlflow.log_param을 해주면 하이퍼파라미터를 기록하고, mlflow.log_tag는 관리를 위해 필요한 정보를 기록합니다. mlflow.log_artificate는 그 외의 그래프와 같은 산출물을 저장할 수 있습니다. mlflow.sklearn.log_model는 모델을 저장하는 것인데 옵션으로 registered_model_name="CarSeat" 모델이름을 지정할 수 있습니다.

Mlflow_Autolog
파일을 자동으로 관리해주는 것입니다. 모델을 자동으로 로깅을 해주는 기능으로 fit() 메소드가 호출되면 학습 과정과 결과를 자동으로 로그를 남깁니다.
with mlflow.start_run(experiment_id=exp_id):
# autolog!
mlflow.sklearn.autolog()
model = RandomForestRegressor()
model.fit(x_train, y_train)
mlflow.sklearn.autolog(disable = True)사용방법은 위와 같습니다. mlflow.sklearn.autolog()로 시작하고 mlflow.sklearn.autolog(disable = True)으로 끝납니다.
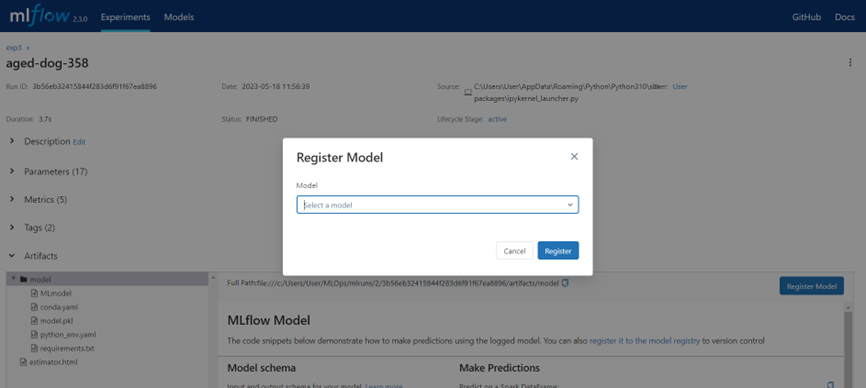
autolog로 생성하면 모델 이름이 생성되지 않아 Register Model버튼을 눌러 모델이름을 정해줘야합니다. (코드로 해주는 방법도 있습니다.)
▶ Autologing 하이퍼파라미터
GridSearch나 RandomSearch를 진행할 때 Autologging을 사용할 수 있습니다.
with mlflow.start_run(experiment_id=exp_id):
mlflow.sklearn.autolog()
params = {'n_estimators':range(20,201,20)}
model = GridSearchCV(RandomForestRegressor(), params, cv = 5)
model.fit(x_train, y_train)
# 자동기록되는 부분 : 하이퍼파리미터, 성능지표, 성능평가 결과(.cv_results_)
# 수동으로 등록해야 하는 부분 : 모델등록, 그래프, 추가적인 fitting 함수
result = pd.DataFrame(model.cv_results_)
plt.plot('param_n_estimators', 'mean_test_score', data = result, marker = '.' )
plt.title('RF GridSearch Tuning')
plt.ylabel('r2 score')
plt.xlabel('n_estimators')
plt.grid()
plt.savefig('RF_GridSearch_Tuning.png')
mlflow.log_artifact("RF_GridSearch_Tuning.png")
# best 모델 기록하기
mlflow.sklearn.log_model(model.best_estimator_, "model", registered_model_name="RF_Tuning")
mlflow.sklearn.autolog(disable = True)수동과 자동을 혼합해서 이렇게 사용할 수 있습니다.
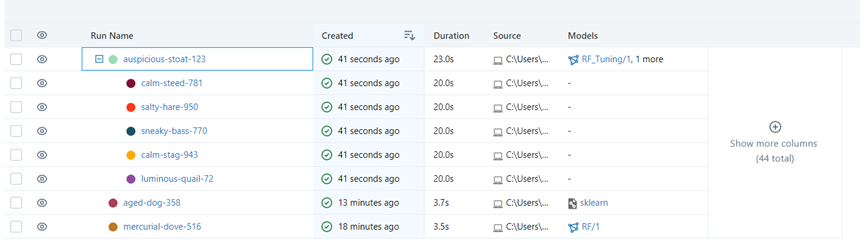
GridSearch로 상위 5등까지 저장했습니다.(코드가 아니라 mlflows에서 자종으로 이렇게 5등까지 저장해줍니다.)
▶딥러닝 모델의 자동관리
지금까지는 sklearn의 모델을 자동관리 했지만 딥러닝도 자동관리가 가능합니다.
딥러닝의 모델일 경우에는 mlflow.keras.autolog()처럼 sklaern부분을 keras로 바꿔주면 됩니다.
with mlflow.start_run(experiment_id=exp_id):
# autolog 시작
mlflow.keras.autolog()
# 모델 설계 및 컴파일
model = Sequential([ Dense(1, input_shape = (nfeatures,)) ])
model.compile(optimizer= Adam(learning_rate = 0.1), loss='mse')
# 학습
history = model.fit(x_train_s, y_train, epochs=30, validation_split=.2).history
# 모델등록
mlflow.keras.log_model(model, "keras-model", registered_model_name="DL")
# autolog 종료
mlflow.keras.autolog(disable = True)모델배포 관리
MLflow에서 모델의 라이프사이클을 4가지 단계로 관리합니다.
- None 모델을 처음 등록한 상태입니다.
- Staging은 대기,후보로 배포하기 전 단계입니다.
- Production은 서비스하고 있는 모델이 있는 단계입니다.
- Archived는 운영환경에서 더 이상 사용하지 않는 모델을 저장하는 단계입니다.
버전관리는 UI에서 관리합니다.
운영중인 모델 로딩하기
# 버전으로 가져오기
model_uri = "models:/CarSeat/1"
model1 = mlflow.sklearn.load_model(model_uri)
# 최신버전으로 가져오기
model_uri = "models:/CarSeat/latest"
model2 = mlflow.sklearn.load_model(model_uri)
# 운영중인 버전 가져오기
model_uri = "models:/CarSeat/production"
model3 = mlflow.sklearn.load_model(model_uri)위 코드와 같이 필요모델을 가져옵니다. 가장 최신 버전의 모델을 가져오거나 운영중인 모델을 편하게 가져와서 바로 사용할 수 있습니다.
오늘은 mlflows에 대해 배웠는데 정말 좋은 기능을 제공해주는 것 같습니다!!
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
